Verwenden des vordefinierten Texterkennungsmodells in Power Automate
Das vorgefertigte Texterkennungsmodell AI Builder extrahiert gedruckten und handgeschriebenen Text aus Bildern und Dokumenten. Mithilfe dieses Modells Power Automate können Sie Workflows erstellen, die Text aus gescannten Dokumenten, Fotos und PDFs automatisch verarbeiten und so eine effiziente Datenverarbeitung und Integration in andere Anwendungen ermöglichen.
Dieses Dokument enthält eine Anleitung zur Verwendung des vordefinierten Texterkennungsmodells Power Automate.
Initialisieren des Power Automate-Flows
Die Initialisierung des Power Automate Flows ist der erste Schritt beim Einrichten des automatisierten Prozesses. In diesem Schritt können Sie den Trigger und die anfänglichen Eingabeparameter für Ihren Flow definieren. Bei der Initialisierung können Sie sicherstellen, dass der Flow ordnungsgemäß gestartet wird und über die erforderlichen Informationen verfügt, um die Texterkennungsaufgaben effizient zu verarbeiten.
Führen Sie diese Schritte aus, um Ihren Flow zu initialisieren:
Melden Sie sich bei Power Automate an.
Wählen Sie im linken Navigationsmenü die Option Meine Flows und dann Neuer Flow>Sofortiger Cloud-Flow aus.
Benennen Sie den Flow. Wählen Sie unter Auslöser für diesen Flow auswählen die Option Flow manuell auslösen und dann Erstellen aus.
Erweitern Sie Flow manuell auslösen, und wählen Sie dann +Eingabe hinzufügen>Datei als Eingabetyp aus.
Wählen Sie +Neuer Schritt>AI Builder und dann Text in einem Bild oder einem PDF-Dokument erkennen in der Aktionsliste.
Wählen Sie die Eingabe Bild und dann Dateiinhalt in der Liste Dynamischer Inhalt aus:
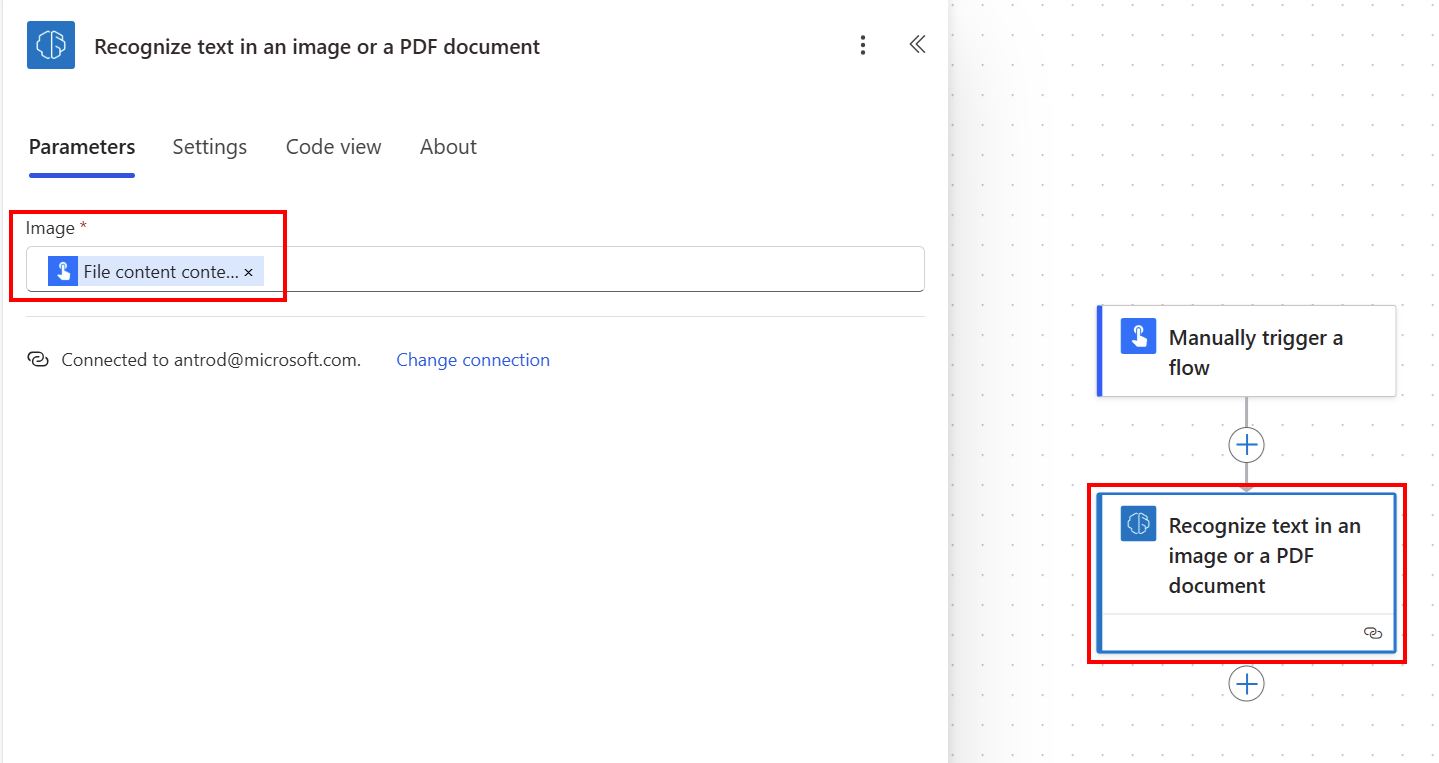
Um die Ergebnisse zu verarbeiten, können Sie entweder den vollständigen Dokumenttext, einen Seitentext oder den Dokumenttext zeilenweise verwenden.
Den vollständigen Dokumenttext oder einen ganzseitigen Text abrufen
Wenn Sie eine Aktion für den gesamten Dokumenttext oder für einen bestimmten Seitentext ausführen müssen, ist diese Option nützlich. Ein Beispiel für die Verwendung von Seitentext ist, wenn Sie nach einer Teilzeichenfolge suchen oder sie an eine nachgelagerte Aktion übergeben möchten.
Sie können den gesamten extrahierten Text in einem Teams-Kanal veröffentlichen, indem Sie Volltext des Dokuments aus der Liste dynamische Inhalte verwenden.
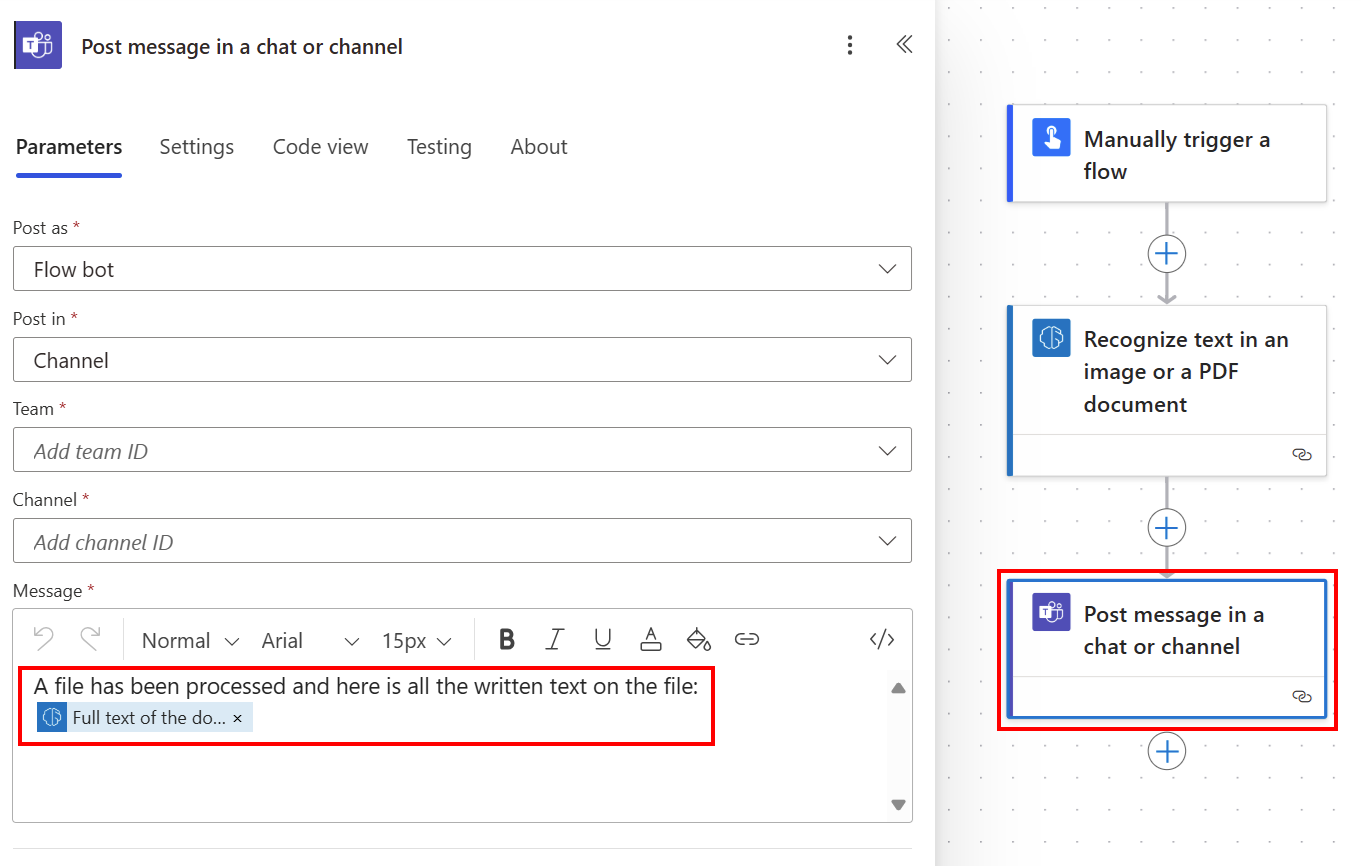
Den Dokumenttext zeilenweise abrufen
Das zeilenweise Abrufen des Dokumenttextes kann nützlich sein, wenn Sie eine bestimmte Textzeile isolieren oder den Text nach Belieben neu formatieren müssen.
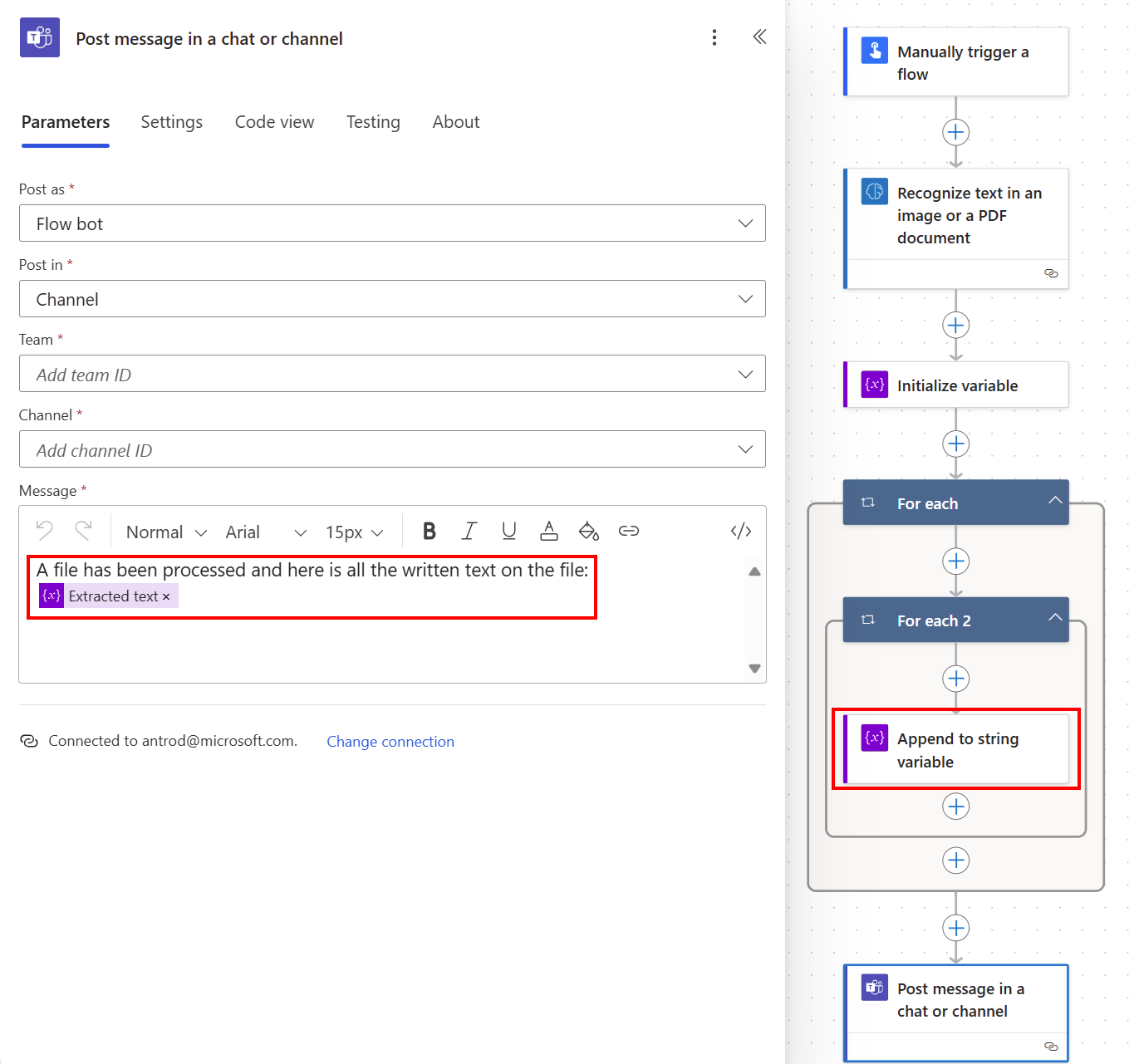
Um eine Zeichenfolgenvariable zu erstellen, wählen Sie +Neuer Schritt>Steuerelement und dann Variable initialisieren aus.
Nennen Sie es zum Beispiel Extrahierten Text .
Wählen Sie +Neuer Schritt>Steuerelement und dann An Zeichenfolgenvariable anfügen aus.
Wählen Sie im Feld Wert die Option Text aus der Liste des dynamischen Inhalts aus.
Es generiert automatisch zwei "Auf alle anwenden"-Aktionen, da es eine Liste von Zeilentext in einer Liste von Seiten liest. Anschließend können Sie den gesamten extrahierten Text in einem Teams-Kanal veröffentlichen.
Herzlichen Glückwunsch! Sie haben einen Flow erstellt, der ein Texterkennungsmodell nutzt. Sie können diesen Flow weiterentwickeln, bis er Ihren Anforderungen entspricht. Wählen Sie Speichern oben rechts, und wählen Sie dann Test, um Ihren Flow auszuprobieren.
Parameter
Das vordefinierte Texterkennungsmodell in AI Builder enthält die folgenden Ein- und Ausgabeparameter.
Eingabe
| Name | Erforderlich | typ | Eigenschaft |
|---|---|---|---|
| Bild | Ja | file | Zu analysierendes Bild |
Ausgabe
Der erkannte Text wird in der Unterliste Zeilen der Liste Ergebnisse eingebettet. Sie müssen zuerst die Spalte Zeilen aus einer Aktion auf jede auswählen, um alle folgenden Spalten anzuzeigen.
| Name | Art | Beschreibung |
|---|---|---|
| Text | Zeichenfolge | Zeichenfolgen, welche die erkannten Textzeilen enthalten |
| Seitenzahl | string | Seitenzahl des erkannten Texts |
| Koordinaten | Gleitkomma | Koordinaten des erkannten Texts |
| Vollständiger Text des Dokuments | string | Volltext erkannt |
| Vollständiger Text der Seite | string | Vollständiger Seitentext erkannt |