Quorum vote configuration check in AlwaysOn Availability Group Wizards (Andy Jing)
Quorum vote configuration check in AlwaysOn Availability Group Wizards
By Andy Jing
In this blog, I try to delve deeper into the guidelines of adjusting the quorum voting in the Windows Server Failover Cluster (WSFC) for the availability groups and explain the reasons behind them with a specific example. For simplification, I will use “a cluster” instead of its full name in the following parts.
The blog consists of three parts: introduction, the availability of a cluster, and the availability and performance of an availability group. The introduction explains briefly the quorum vote configuration check in the Availability Group Wizards and gives a specific example for the following discussion.
As an availability group is a set of resources of the underlying cluster, the availability of a cluster affects the availability of the resources, I will first discuss the impact of the vote configuration on the availability of a cluster. Then, the availability and performance of an availability group is discussed.
- 1. Introduction
In the Results page of the Creating Availability Group and Failover wizards, the summary list has an item named Validating WSFC quorum vote configuration (see Figure 1).
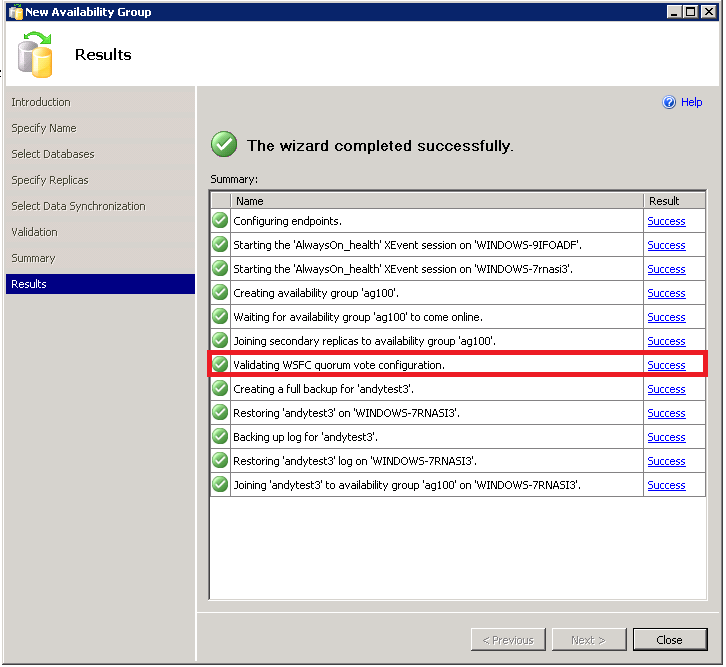
Figure 1: The Results page of the Creating Availability Group wizard
This item checks the vote configuration of the cluster nodes, which host the SQL server instances of an availability group. In some cases, the validation result could be shown with Warning. When you click its result link, a message box pops up with the following message:
“The current WSFC cluster quorum vote configuration is not recommended for this availability group. For more information, see the following topic in SQL Server Books Online: https://go.microsoft.com/fwlink/?LinkId=224159.”
After navigating to the web page with the provided link, you will see the section, Recommended Adjustments to Quorum Voting in the WSFC Quorum Modes and Voting Configuration (SQL Server), has several guidelines for adjusting the quorum vote.
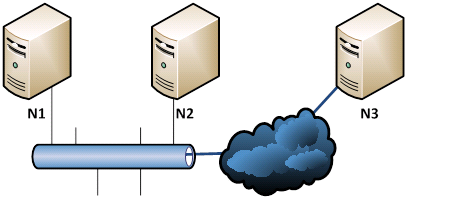
The example used in this bog has a cluster containing three nodes (N1, N2, and N3). N1 and N2 are connected in a LAN. N3 is connected to two other nodes through a WAN. The purpose of this setup is that N1 and N2 are for high availability and N3 for disaster recovery when the site of N1 and N2 is down. Figure 2 is the topology of the cluster.
{kind=link}
{kind=link}
Figure 2: The topology of cluster nodes
- 2. The availability of a cluster
The cluster provides several quorum models to handle node failures and network partitioning (or “split-brain” scenario). For detailed explanation of quorum models and configuring the quorum in a cluster, please refer to the following links:
1) Failover Cluster Step-by-Step Guide: Configuring the Quorum in a Failover Cluster
2) Introduction to the Cluster Quorum Model
The cluster in the example has the odd number of nodes. We can use the Node Majority quorum model so that each node has one vote in the quorum. In this setting, the cluster tolerates both one node failure and the “split-brain” scenario because the WAN usually is the location of network partition. Till now, the Node Majority seems OK. However, let us consider another scenario of upgrading. For example, to upgrade the node N1, we first shut it down then do upgrade. What if the network partition occurs during the upgrading period? In this case, the cluster will be down because each partition has no enough votes to meet the quorum.
The above problem can be solved by configuring the quorum votes of the cluster nodes. To modify a node quorum vote (or NodeWeight), a patch needs to be installed. The patch and how to change the quorum vote can be found here.
Figure 3 shows the quorum vote configuration after modifying the NodeWeights of the cluster nodes. In this setting, a disk witness is added and the quorum model is changed into Node and Disk Majority. In addition, the N3’s NodeWeight is set to 0.
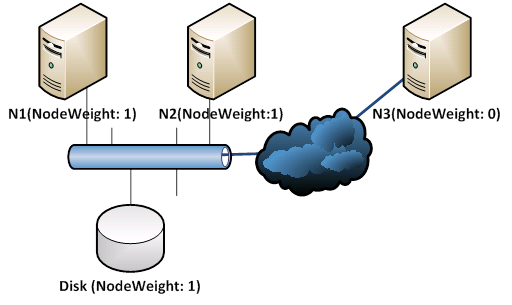
Figure 3: The cluster NodeWeight setting
This configuration solves the above upgrading problem because the partition containing the node N2 and Disk witness has the majority of votes so the cluster will remain up when the network partition happens during the upgrading.
- 3. The availability and performance of an availability group
In this part, I will explain how the configurations of an availability group affect its availability and performance.
Suppose an availability group includes three SQL server instances, INST1, INST2, and INST3. INST1 and INST2 are used for high availability and INST3 is for disaster recovery. In addition, INST1 is a primary replica and all other instances are secondary replicas. To satisfy this requirement, the failover types of INST1 and INST2 are set to Automatic Failover, which requires their Availability Modes to be set to Synchronous Commit. The failover type and availability node of INST3 are Manual Failover and Asynchronous Commit, respectively. For more info on the availability mode and failover type of the availability groups, see Overview of AlwaysOn Availability Groups (SQL Server) .
When creating the above availability group, we need to determine which cluster nodes host the SQL instances. Table 1 shows all possible combinations between the SQL instances and the Cluster nodes.
|
SQL instance |
Cluster Node |
|||||
|
INST1 |
N3 |
N3 |
N2 |
N2 |
N1 |
N1 |
|
INST2 |
N1 |
N2 |
N3 |
N1 |
N2 |
N3 |
|
INST3 |
N2 |
N1 |
N1 |
N3 |
N3 |
N2 |
Table 1: the relationship between SQL instances and Cluster nodes
These combinations can be classified into two categories: either INST1 or INST2 is hosted in the N3 without the quorum vote and INST1 and INST2 resides in N1 or N2 with the quorum vote (shaded two columns in Table 1).
Let us take a look on the drawbacks of the configurations in the first category. The availability modes of INST1 and INST2 are Synchronous Commit. It means, for each transaction commit, a distributed commit protocol is used to reach the commit consensus between INST1 and INST2. However, these two instances are hosted in the cluster nodes, which are connected through WAN. The network latency would become the dominant factor of the transaction throughput. Thus, the performance of the availability group is decreased. Secondly, the upgrading problem mentioned before could still exist. Suppose that INST1 and INST3 are on the nodes N1 and N2, respectively. When N1 is upgrading and the network partition happens, as the data in INST3 is not synchronized and its failover type is Manual Failover, the availability group is not available because the INST3 cannot become a primary replica even if the underlying cluster is up. Finally, when the primary replica INST1 is hosted in N3, the failover may happen frequently because the network partition is almost a normal case in the WAN.
However, the configurations in the second category do not have such drawbacks in comparison to those in the first one. One common characteristic of these two configurations in the second category is that SQL Server instance hosting replicas that are more highly-available (synchronous commit and automatic failover), such as INST1 and INST2, of an availability group are hosted by cluster nodes that are more highly-available , such as N1 and N2, of a cluster, which usually have the quorum vote.
Comments
- Anonymous
July 24, 2012
I was receiving the warning about the quorum configuration, then I installed the hotfix and configured each node to have a NodeWeight of 1. I have a 3 node WSFC. I also updated to SQL 2012 CU2. When I configure two synchronous auto-failover nodes I get no warning. When I add a third synchronous replica I get no warning. When I make the third node asynchronous, I get the warning.