Erstellen eines benutzerdefinierten Bildanalysemodells
Wichtig
Dieses Feature ist jetzt veraltet. Am 10. Januar 2025 wird die Vorschau-API für Azure KI-Bildanalyse 4.0 für benutzerdefinierte Bildklassifizierung, benutzerdefinierte Objekterkennung und Produkterkennung eingestellt. Nach diesem Datum schlagen API-Aufrufe für diese Dienste fehl.
Um einen reibungslosen Betrieb Ihrer Modelle zu gewährleisten, wechseln Sie zu Azure KI Custom Vision (jetzt allgemein verfügbar). Custom Vision bietet ähnliche Funktionen wie die eingestellten Features.
Mit Bildanalyse 4.0 können Sie ein benutzerdefiniertes Modell mit Ihren eigenen Trainingsbildern trainieren. Durch manuelles Beschriften Ihrer Bilder können Sie ein Modell trainieren, um benutzerdefinierte Tags auf die Bilder anzuwenden (Bildklassifizierung) oder benutzerdefinierte Objekte zu erkennen (Objekterkennung). Modelle von Bildanalyse 4.0 eignen sich besonders für Few-Shot-Lernen, sodass Sie genaue Modelle mit weniger Trainingsdaten erhalten können.
In diesem Leitfaden erfahren Sie, wie Sie ein benutzerdefiniertes Bildklassifizierungsmodell erstellen und trainieren. Die wenigen Unterschiede zwischen dem Trainieren eines Bildklassifizierungsmodells und eines Objekterkennungsmodells sind bekannt.
Hinweis
Die Modellanpassung ist über die REST-API und Vision Studio, aber nicht über die Clientsprachen-SDKs verfügbar.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Sobald Sie über Ihr Azure-Abonnement verfügen, erstellen Sie eine Vision-Ressource im Azure-Portal, um Ihren Schlüssel und Endpunkt abzurufen. Wenn Sie diesen Leitfaden über Vision Studio verfolgen, müssen Sie Ihre Ressource in der Region „USA, Osten“ erstellen. Wählen Sie nach Abschluss der Bereitstellung Zu Ressource wechseln aus. Kopieren Sie Schlüssel und Endpunkt für die spätere Verwendung an einen temporären Speicherort.
- Eine Azure Storage-Ressource. Erstellen Sie eine Storage-Ressource.
- Eine Reihe von Bildern, die Sie zum Training Ihrer Klassifizierung nutzen. Sie können den Satz von Beispielbildern auf GitHub verwenden. Sie können ebenfalls Ihre eigenen Bilder verwenden. Sie benötigen nur etwa 3–5 Bilder pro Klassifizierung.
Hinweis
Aufgrund einer potenziell hohen Wartezeit wird nicht empfohlen, benutzerdefinierte Modelle für unternehmenskritische Umgebungen zu verwenden. Wenn Kunden benutzerdefinierte Modelle in Vision Studio trainieren, gehören diese Modelle zu der Vision-Ressource, mit der sie trainiert wurden. Der Kunde kann diese Modelle mithilfe der Bildanalyse-API aufrufen. Werden diese Aufrufe ausgeführt, wird das benutzerdefinierte Modell in den Arbeitsspeicher geladen und die Vorhersageinfrastruktur initialisiert. In dieser Phase kann es bei Kunden zu einer unerwarteten höheren Latenz bei der Abfrage von Vorhersageergebnissen kommen.
Ein neues benutzerdefiniertes Modell erstellen
Wechseln Sie zunächst zu Vision Studio, und wählen Sie die Registerkarte Bildanalyse aus. Wählen Sie dann die Kachel Modelle anpassen aus.
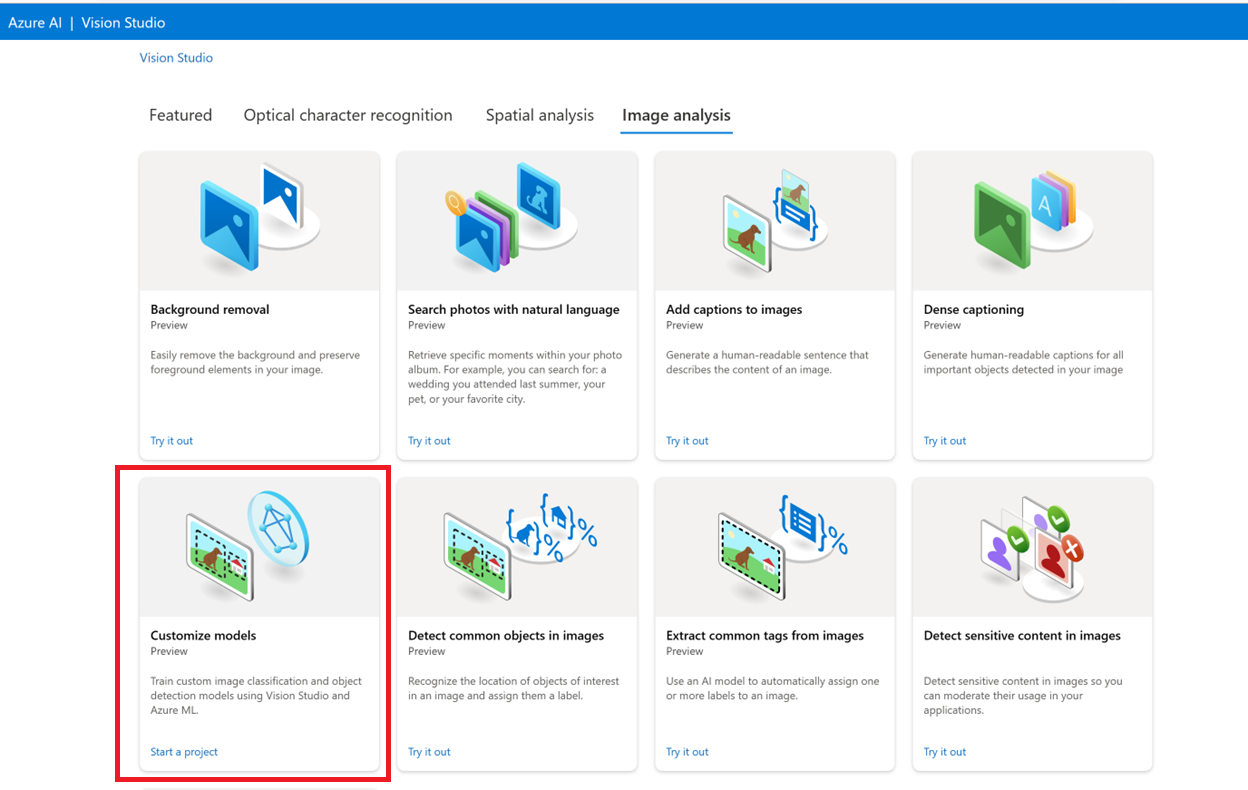
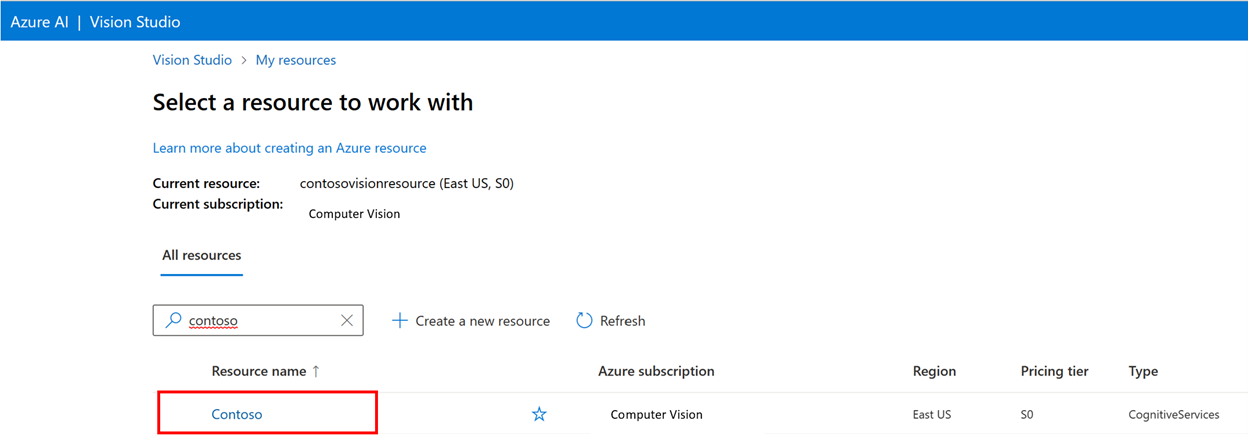
Melden Sie sich dann mit Ihrem Azure-Konto an, und wählen Sie Ihre Vision-Ressource aus. Sollten Sie nicht über ein Konto verfügen, können Sie auf diesem Bildschirm ein Konto erstellen.
Vorbereiten von Trainingsbildern
Sie müssen die Trainingsbilder in einen Azure Blob Storage-Container hochladen. Navigieren Sie im Azure-Portal zu Ihrer Speicherressource und zur Registerkarte Speicherbrowser. Hier können Sie einen Blobcontainer erstellen und Ihre Bilder hochladen. Platzieren Sie sie alle im Stammverzeichnis des Containers.
Hinzufügen eines Datasets
Um ein benutzerdefiniertes Modell zu trainieren, müssen Sie es einem Dataset zuordnen, in dem Sie Bilder und deren Beschriftungsinformationen als Trainingsdaten bereitstellen. Wählen Sie in Vision Studio die Registerkarte Datasets aus, um Ihre Datasets anzuzeigen.
Wählen Sie Neues Dataset hinzufügen aus, um ein neues Dataset zu erstellen. Geben Sie in dem Popup-Fenster einen Namen ein und wählen Sie einen Dataset-Typ für Ihren Anwendungsfall. Modelle zur Bildklassifizierung wenden Inhaltsbezeichnungen auf das gesamte Bild an, während Modelle zur Objekterkennung Objektbezeichnungen auf bestimmte Stellen im Bild anwenden. Produkterkennungsmodelle sind eine Unterkategorie von Objekterkennungsmodellen, die für die Erkennung von Einzelhandelsprodukten optimiert sind.
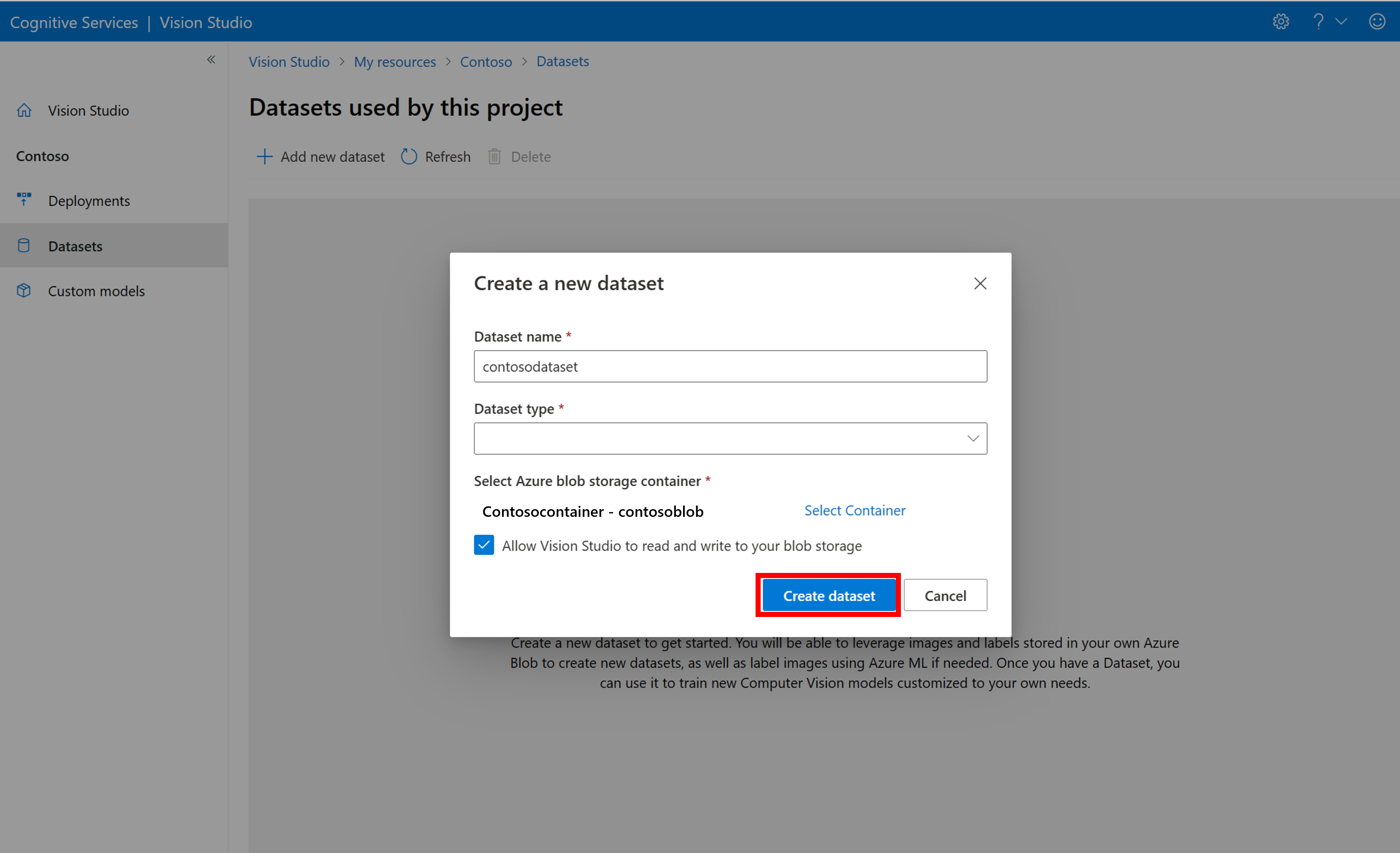
Wählen Sie dann den Container des Azure Blob Storage-Kontos aus, in dem Sie die Trainingsbilder gespeichert haben. Aktivieren Sie das Kontrollkästchen, damit Vision Studio im Blobspeicher-Container lesen und schreiben kann. Dies ist ein erforderlicher Schritt für den Import beschrifteter Daten. Erstellen Sie das Dataset.
Erstellen eines Azure Machine Learning-Beschriftungsprojekts
Sie benötigen eine COCO-Datei, um die Beschriftungsinformationen zu übermitteln. Eine einfache Möglichkeit zum Generieren einer COCO-Datei besteht darin, ein Azure Machine Learning-Projekt zu erstellen, das einen Datenbeschriftungsworkflow enthält.
Wählen Sie auf der Seite mit den Details des Datasets die Option Neues Datenbeschriftungsprojekt hinzufügen aus. Benennen Sie es und wählen Sie Neuen Arbeitsbereich erstellen aus. Dadurch wird eine neue Registerkarte des Azure-Portals geöffnet, auf der Sie das Azure Machine Learning-Projekt erstellen können.
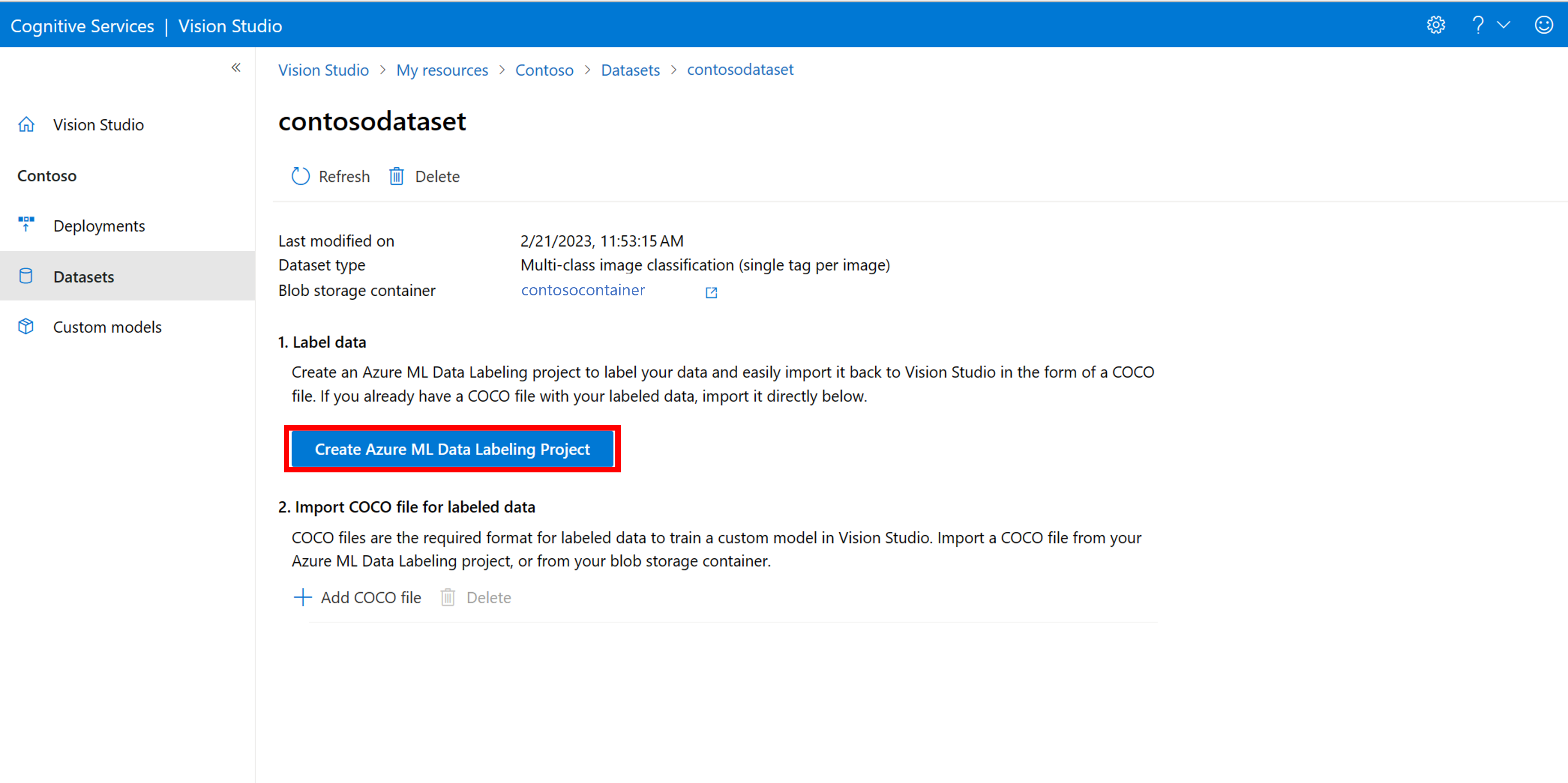
Nachdem das Azure Machine Learning-Projekt erstellt wurde, kehren Sie zur Registerkarte von Vision Studio zurück, und wählen Sie es unter Arbeitsbereich aus. Das Azure Machine Learning-Portal wird dann auf einer neuen Browserregisterkarte geöffnet.
Erstellen von Bezeichnungen
Um mit der Beschriftung zu beginnen, folgen Sie der Aufforderung Beschriftungsklassen hinzufügen, um Beschriftungsklassen hinzuzufügen.
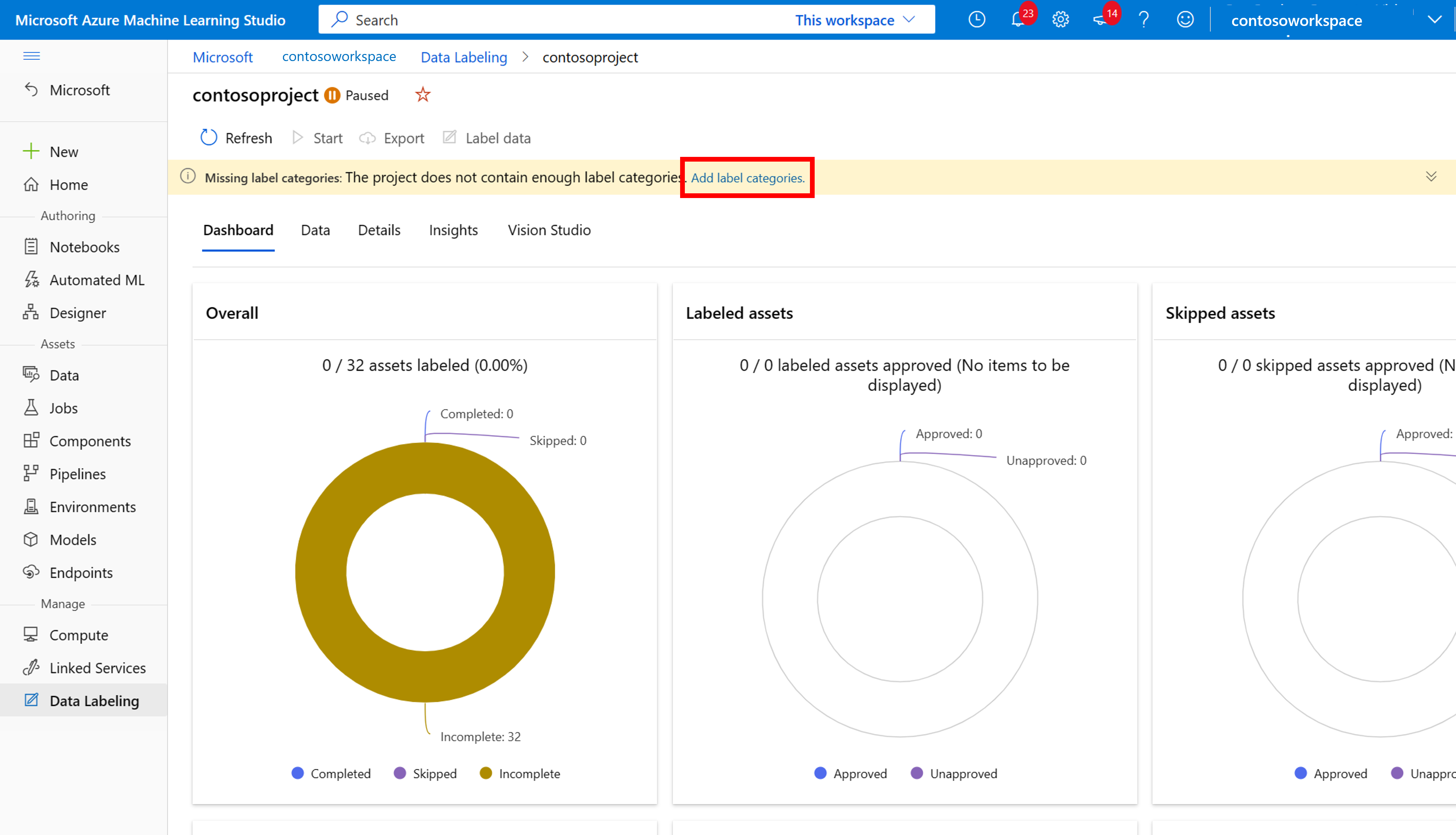
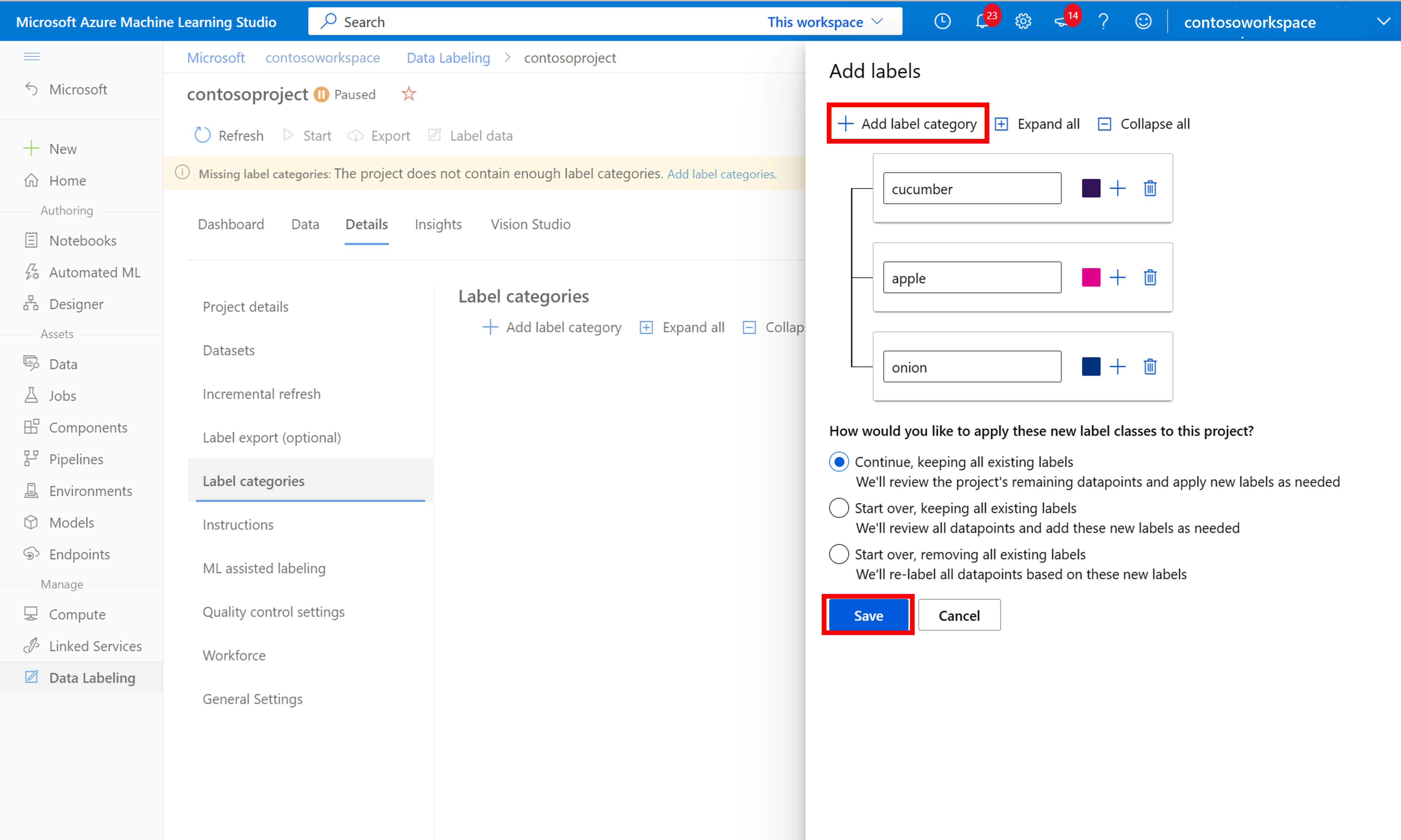
Nachdem Sie alle Klassenbeschriftungen hinzugefügt haben, speichern Sie sie, und wählen Sie Start für das Projekt und dann oben Daten beschriften aus.
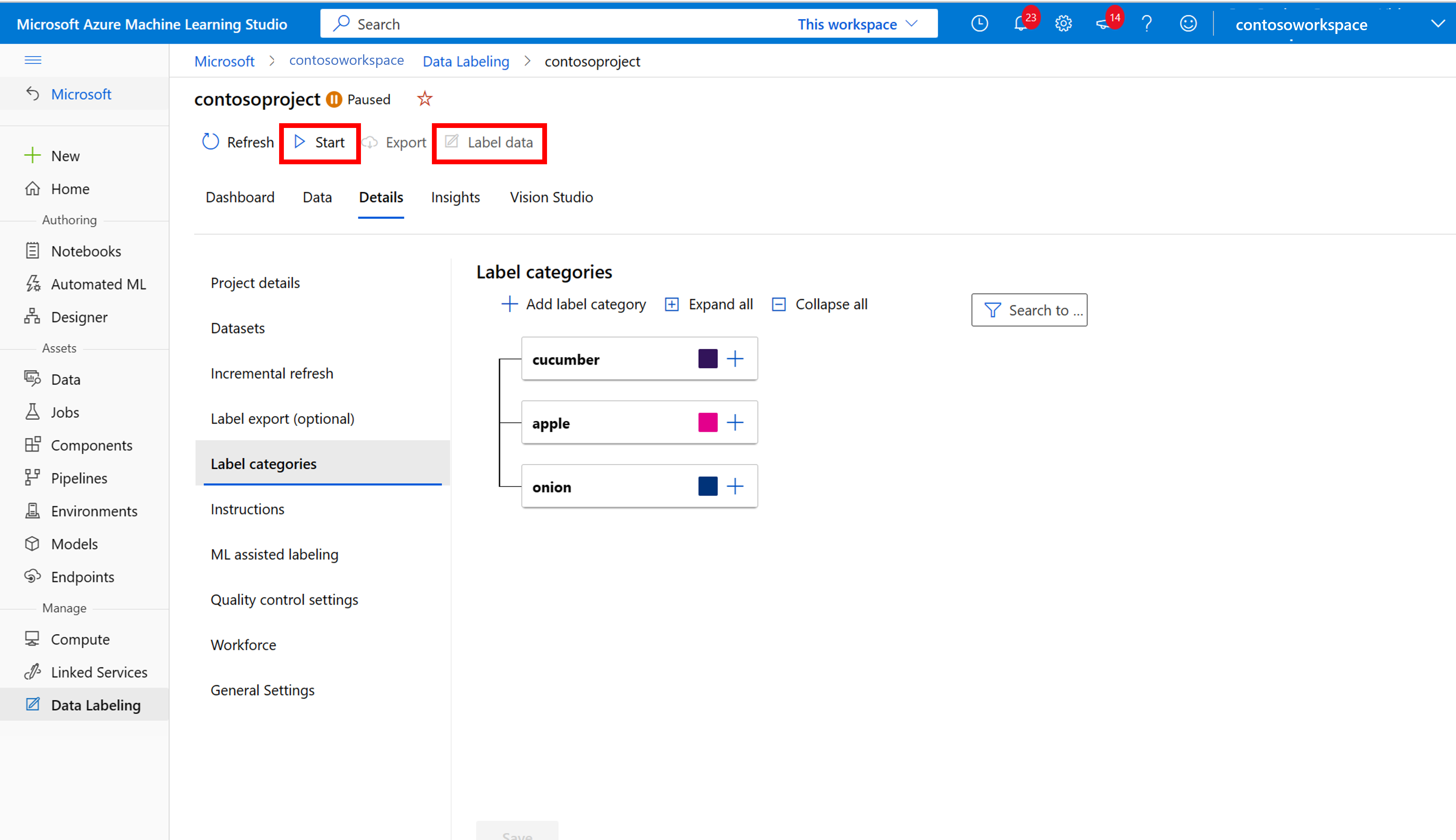
Manuelles Beschriften von Trainingsdaten
Wählen Sie Beschriftung starten aus und folgen Sie den Anweisungen, um alle Ihre Bilder zu beschriften. Wenn Sie fertig sind, kehren Sie zur Registerkarte von Vision Studio in Ihrem Browser zurück.
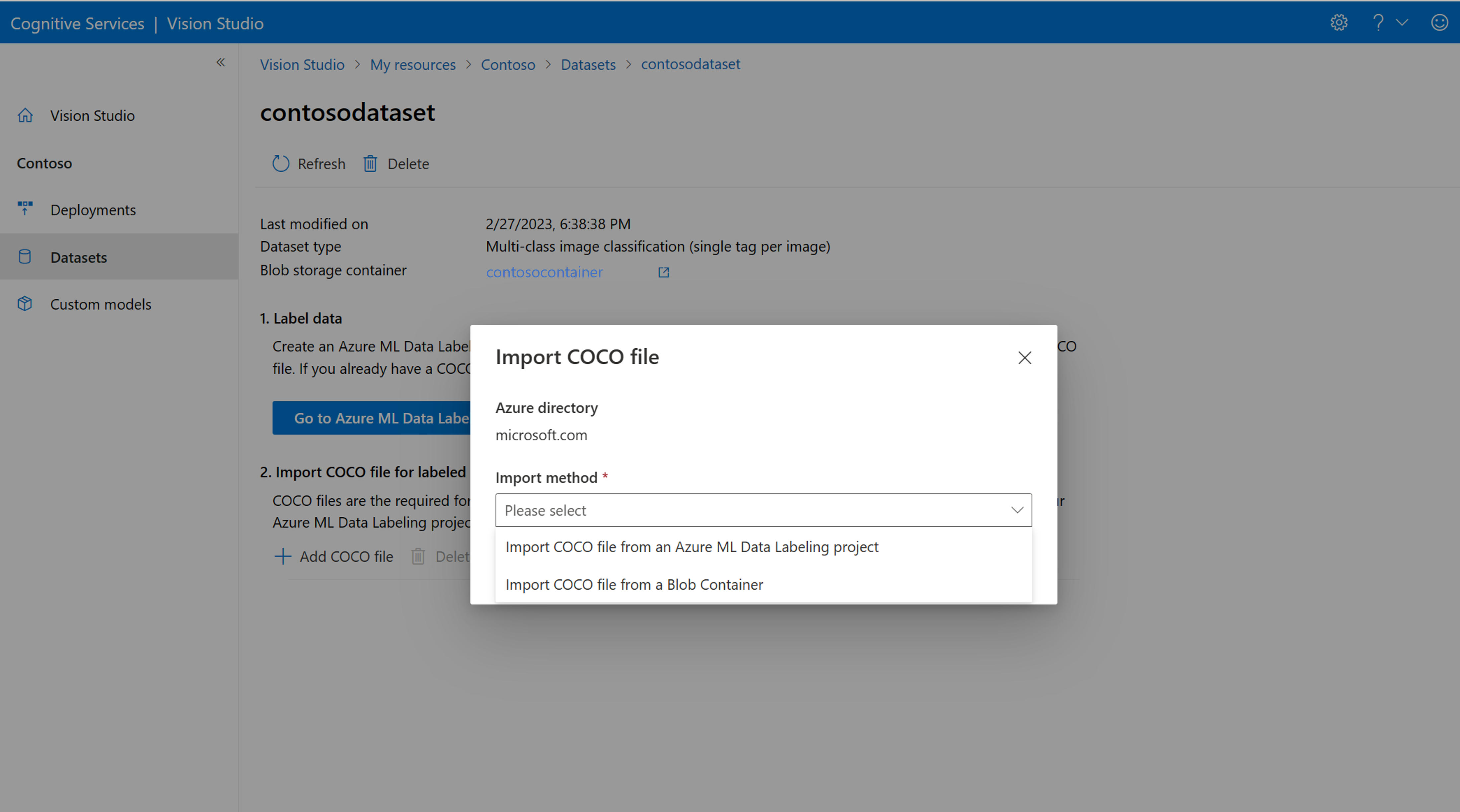
Wählen Sie nun COCO-Datei hinzufügen und dann COCO-Datei aus einem Azure ML-Datenbeschriftungsprojekt importieren aus. Dadurch werden die gekennzeichneten Daten aus Azure Machine Learning importiert.
Die erstellte COCO-Datei wird jetzt in dem Azure Storage-Container gespeichert, den Sie mit diesem Projekt verknüpft haben. Sie können sie jetzt in den Workflow zur Modellanpassung importieren. Wählen Sie sie in der Dropdownliste aus. Nachdem die COCO-Datei in das Dataset importiert wurde, kann das Dataset zum Trainieren eines Modells verwendet werden.
Hinweis
Wenn Sie über eine vorgefertigte COCO-Datei verfügen, die Sie importieren möchten, wechseln Sie zur Registerkarte Datasets, und wählen Sie COCO-Dateien zu diesem Dataset hinzufügen aus. Sie können eine bestimmte COCO-Datei aus einem Blobspeicherkonto hinzufügen oder aus dem Azure Machine Learning-Beschriftungsprojekt importieren.
Derzeit behandelt Microsoft ein Problem, welches dazu führt, dass der COCO-Dateiimport bei großen Datasets fehlschlägt, wenn er in Vision Studio initiiert wird. Um mit einem großen Dataset zu trainieren, empfiehlt es sich, stattdessen die REST-API zu verwenden.
Informationen zu COCO-Dateien
COCO-Dateien sind JSON-Dateien mit bestimmten erforderlichen Feldern: "images", "annotations" und "categories". Eine COCO-Datei sieht beispielhaft wie folgt aus:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Feldreferenz für COCO-Datei
Wenn Sie Ihre eigene COCO-Datei von Grund auf neu generieren, stellen Sie sicher, dass alle erforderlichen Felder mit den richtigen Details gefüllt sind. In den folgenden Tabellen werden die einzelnen Felder in einer COCO-Datei beschrieben:
"images"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | Eindeutige Bild-ID, beginnend bei 1 | Ja |
width |
integer | Breite des Bilds in Pixeln | Ja |
height |
integer | Höhe des Bilds in Pixeln | Ja |
file_name |
Zeichenfolge | Eindeutiger Name für das Bild | Ja |
absolute_url oder coco_url |
Zeichenfolge | Pfad zum Bild als absoluter URI zu einem Blob in einem Blobcontainer. Die Vision-Ressource muss über die Berechtigung zum Lesen der Anmerkungsdateien und aller Bilddateien verfügen, auf die verwiesen wird. | Ja |
Den Wert für absolute_url finden Sie in den Eigenschaften Ihres Blobcontainers:
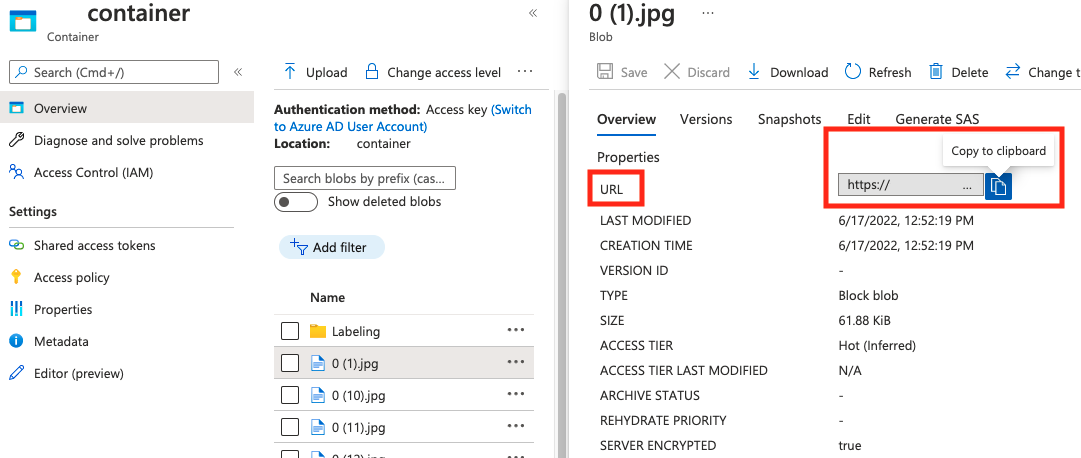
"annotations"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | ID der Anmerkung | Ja |
category_id |
integer | ID der im Abschnitt categories definierten Kategorie |
Ja |
image_id |
integer | ID des Bilds | Ja |
area |
integer | Wert von „Breite“ x „Höhe“ (dritter und vierter Wert von bbox) |
No |
bbox |
list[float] | Relative Koordinaten des Begrenzungsrahmens (0 bis 1), in der Reihenfolge „Links“, „Oben“, „Breite“, „Höhe“ | Yes |
"categories"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | Eindeutige ID jeder Kategorie (Beschriftungsklassifikation). Diese sollten im Abschnitt annotations vorhanden sein. |
Ja |
name |
Zeichenfolge | Name der Kategorie (Beschriftungsklassifikation) | Yes |
Überprüfung der COCO-Datei
Sie können unseren Python-Beispielcode verwenden, um das Format einer COCO-Datei zu überprüfen.
Trainieren eines benutzerdefinierten Modells
Um das Training eines Modells mit Ihrer COCO-Datei zu beginnen, wechseln Sie zur Registerkarte Benutzerdefinierte Modelle und wählen Sie Neues Modell hinzufügen aus. Geben Sie einen Namen für das Modell ein und wählen Sie Image classification oder Object detection als Modelltyp aus.
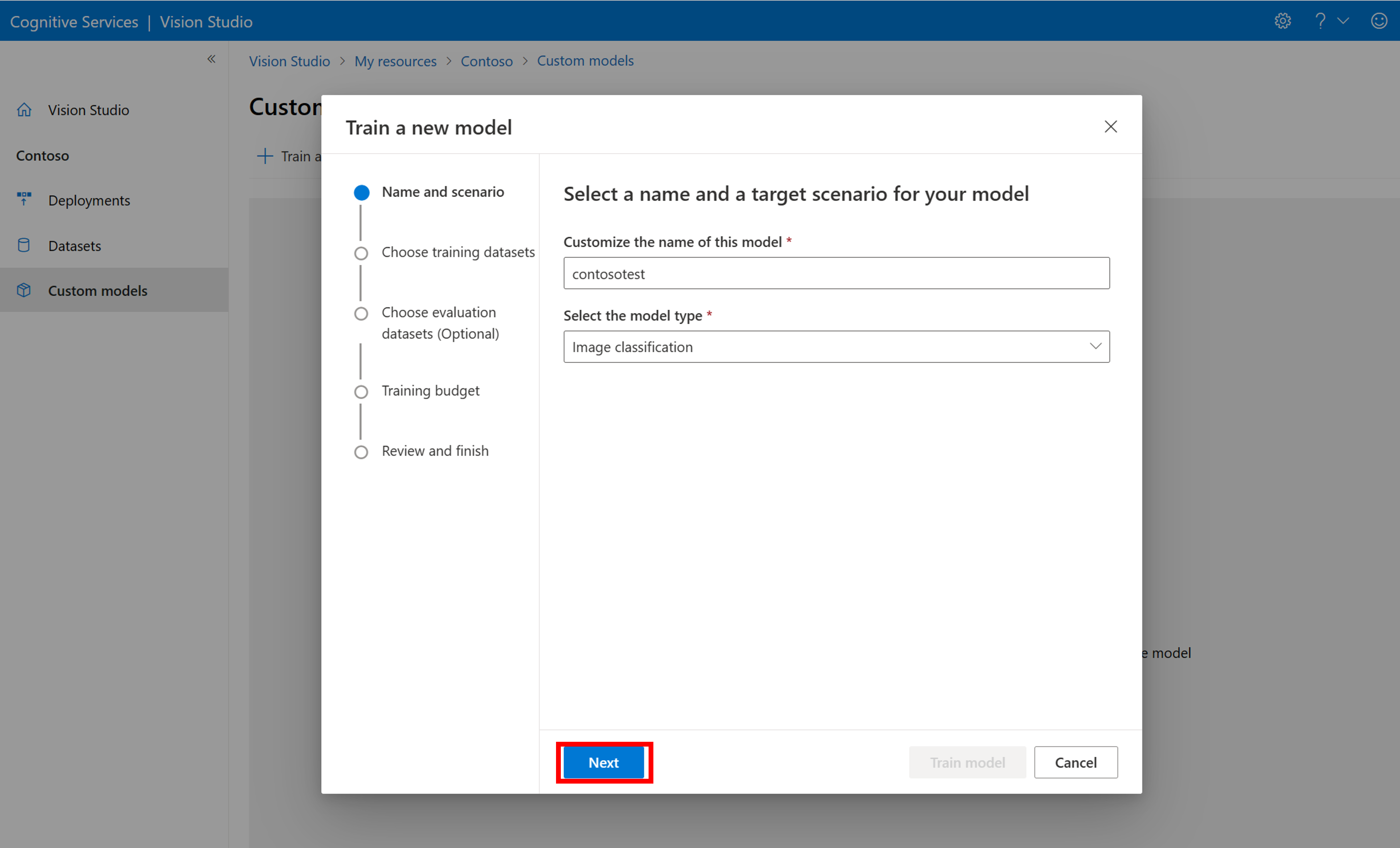
Wählen Sie Ihr Dataset aus, das nun der COCO-Datei zugeordnet ist, die die Beschriftungsinformationen enthält.
Wählen Sie dann ein Zeitbudget aus und trainieren Sie das Modell. Für kleine Beispiele können Sie ein 1 hour-Budget verwenden.
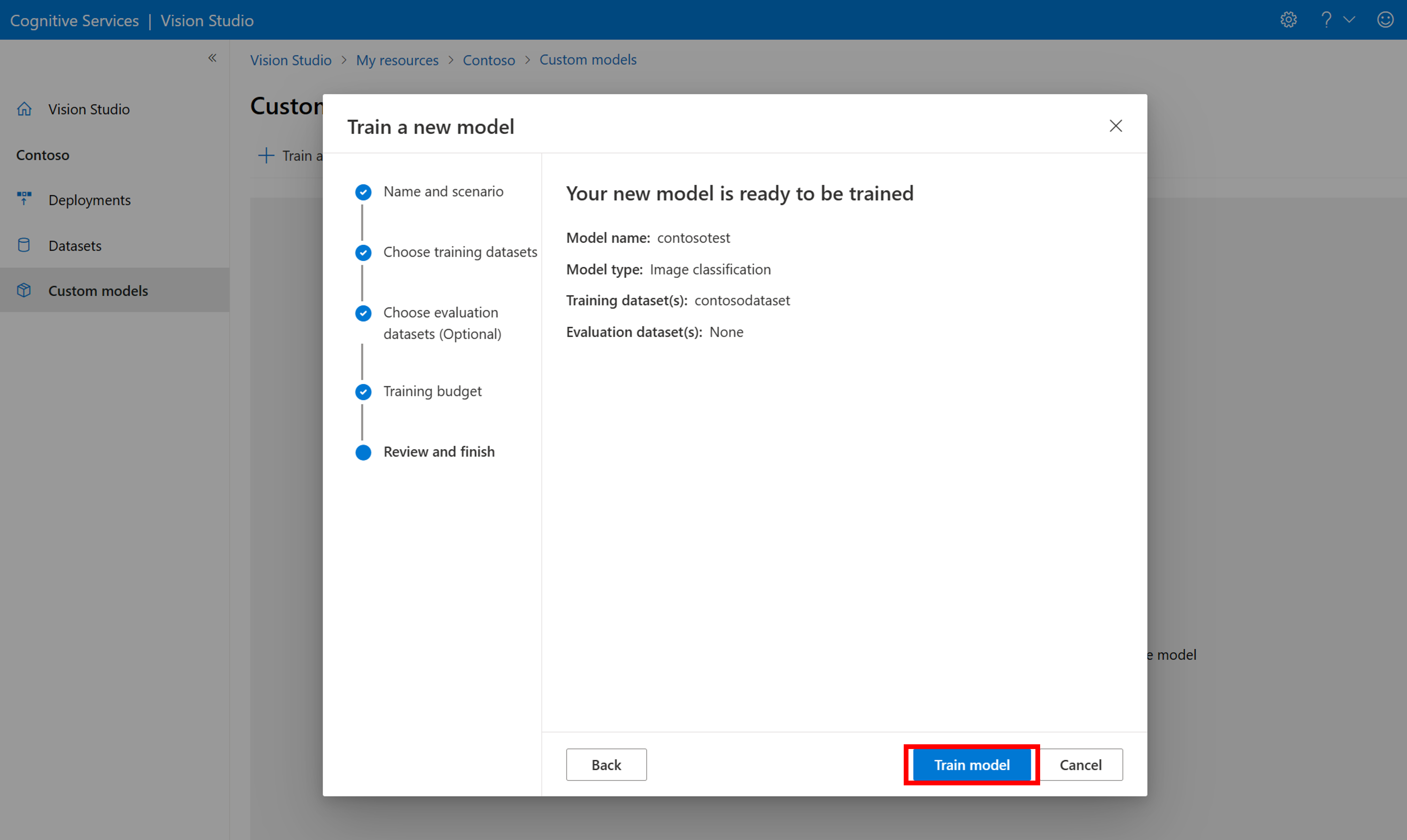
Das Training des Modells kann einige Zeit dauern. Modelle von Bildanalyse 4.0 können auch mit nur einem kleinen Satz von Trainingsdaten genau sein, aber das Training dauert länger als bei vorherigen Modellen.
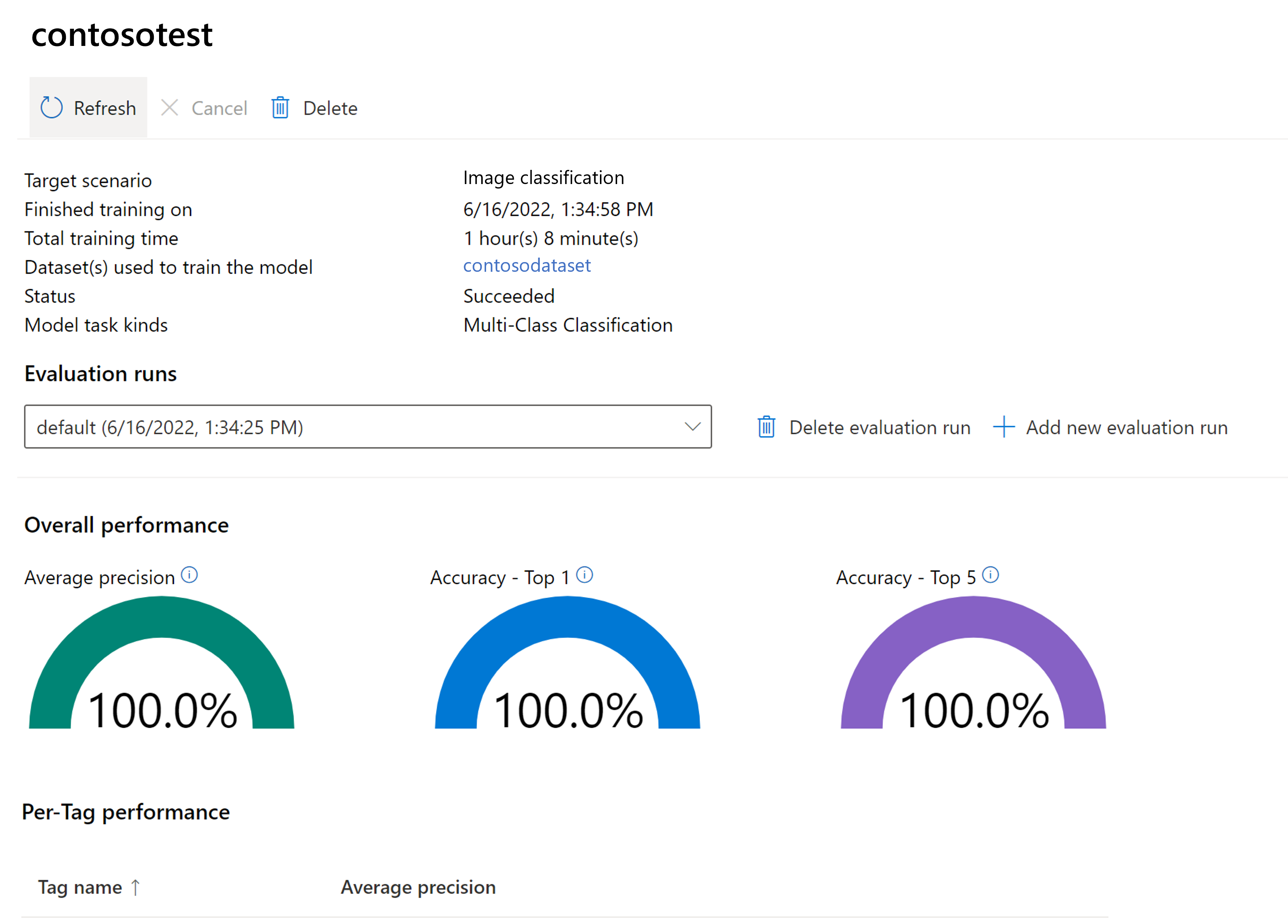
Auswerten des trainierten Modells
Nach Abschluss des Trainings können Sie die Leistungsauswertung des Modells anzeigen. Es werden die folgenden Metriken verwendet:
- Bildklassifizierung: Durchschnittliche Genauigkeit, Genauigkeit Top 1, Genauigkeit Top 5
- Objekterkennung: Mittlere Durchschnittliche Genauigkeit @ 30, Mittlere Durchschnittliche Genauigkeit @ 50, Mittlere Durchschnittliche Genauigkeit @ 75
Wenn beim Trainieren des Modells kein Auswertungssatz bereitgestellt wird, wird die gemeldete Leistung auf der Grundlage eines Teils des Trainingssatzes geschätzt. Es wird dringend empfohlen, ein Auswertungsdataset (mit demselben Prozess wie oben) zu verwenden, um eine zuverlässige Schätzung der Modellleistung zu erhalten.
Testen des benutzerdefinierten Modells in Vision Studio
Nachdem Sie ein benutzerdefiniertes Modell erstellt haben, können Sie testen, indem Sie auf dem Bildschirm „Modellauswertung“ die Schaltfläche Ausprobieren auswählen.
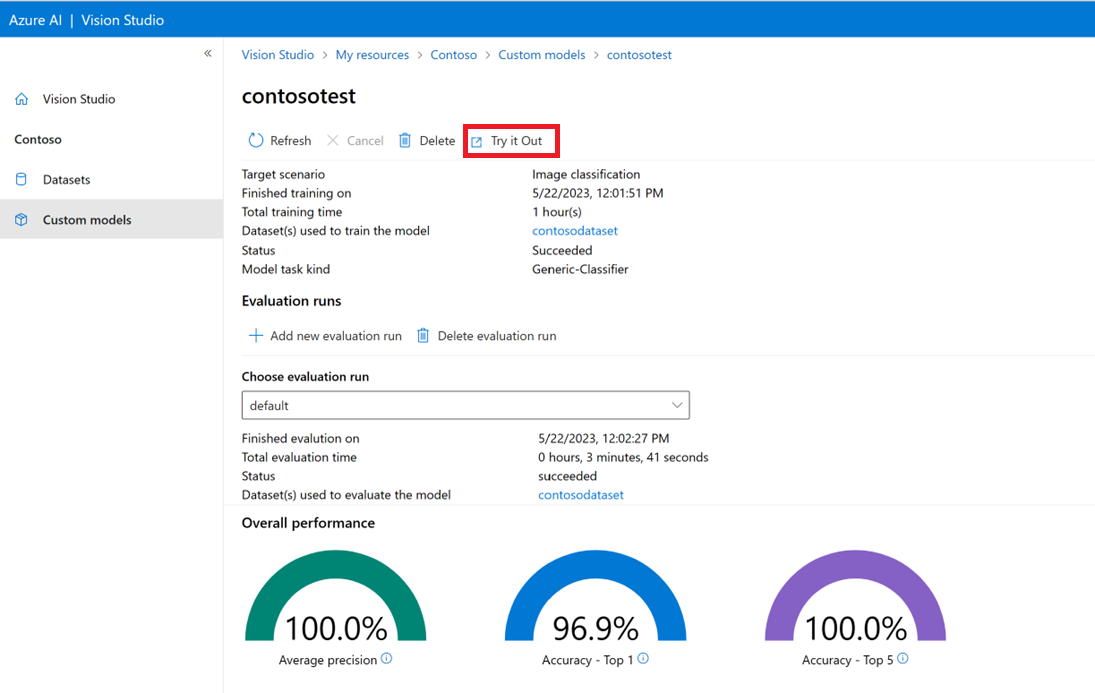
Dadurch gelangen Sie zur Seite Häufig verwendete Tags aus Bildern extrahieren. Wählen Sie im Dropdownmenü Ihr benutzerdefiniertes Modell aus, und laden Sie ein Testbild hoch.
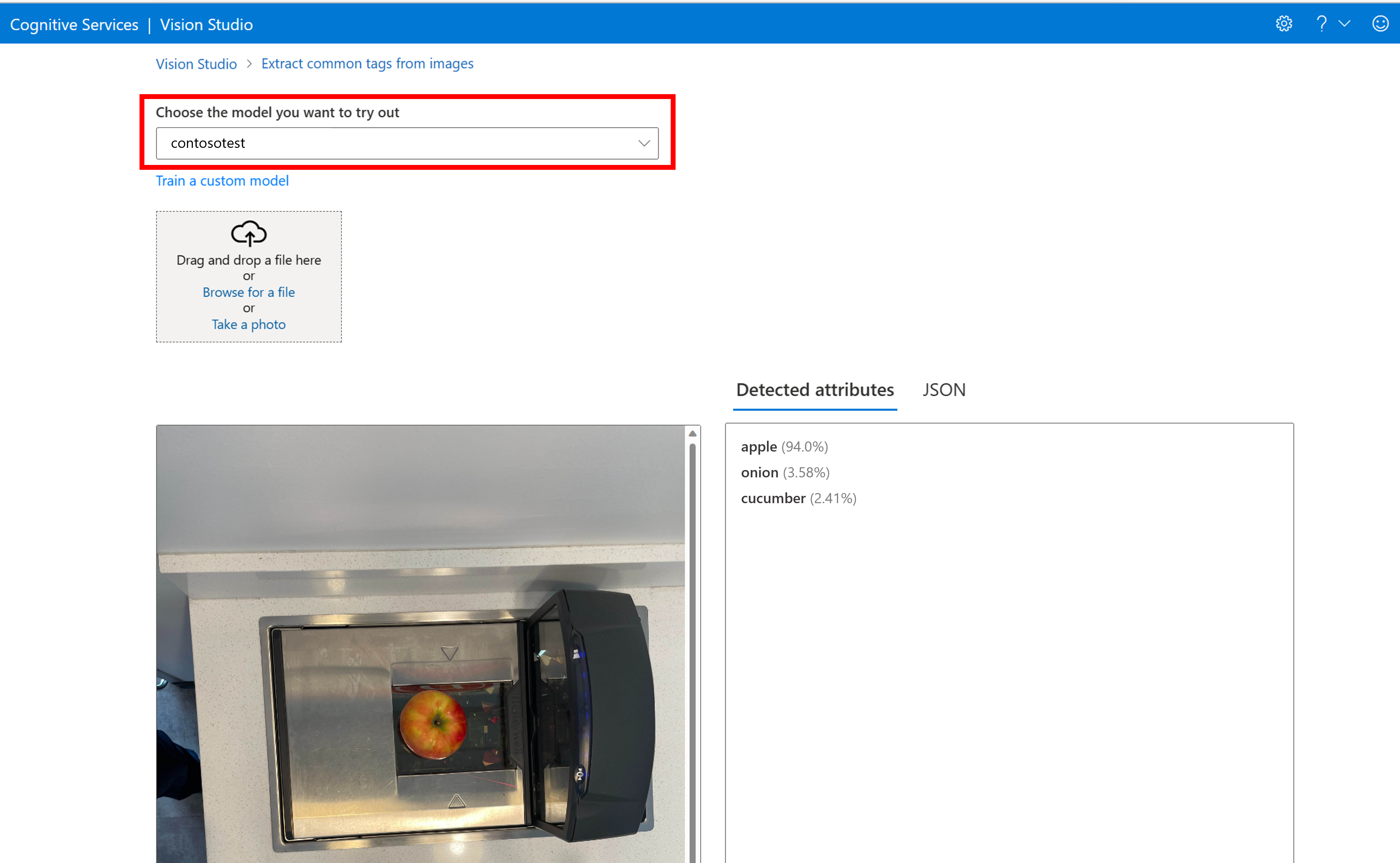
Die Vorhersageergebnisse werden in der rechten Spalte angezeigt.
Zugehöriger Inhalt
Im Rahmen dieses Leitfadens haben Sie mithilfe der Bildanalyse ein benutzerdefiniertes Bildklassifizierungsmodell erstellt und trainiert. Als Nächstes erfahren Sie mehr über die Analyze Image 4.0-API, damit Sie Ihr benutzerdefiniertes Modell mithilfe von REST aus einer Anwendung aufrufen können.