Verwenden der automatischen Bezeichnung für die benutzerdefinierte benannte Entitätserkennung
Der Bezeichnungsprozess ist ein wichtiger Bestandteil beim Vorbereiten ihres Datasets. Da dieser Prozess viel Zeit und Aufwand erfordert, können Sie die automatischen Bezeichnungsfunktion verwenden, um Ihre Entitäten automatisch zu bezeichnen. Sie können automatischen Bezeichnungsaufträge basierend auf einem Modell starten, das Sie zuvor trainiert haben, oder Sie können GPT-Modelle verwenden. Mit der automatischen Bezeichnung basierend auf einem Modell, das Sie zuvor trainiert haben, können Sie mit der Bezeichnung einiger Ihrer Dokumente beginnen, ein Modell trainieren und dann einen automatischen Bezeichnungsauftrag erstellen, um Entitätsbezeichnungen für andere Dokumente basierend auf diesem Modell zu erstellen. Bei der automatischen Bezeichnung mit GPT können Sie ohne vorheriges Modelltraining sofort einen automatischen Bezeichnungsauftrag auslösen. Mit diesem Feature können Sie Zeit und Aufwand im Vergleich zum manuellen Bezeichnen Ihrer Entitäten sparen.
Voraussetzungen
- Automatische Bezeichnung basierend auf einem Modell, das Sie trainiert haben
- Automatische Bezeichnung mit GPT
Bevor Sie die automatische Bezeichnung basierend auf einem von Ihnen trainierten Modell verwenden können, benötigen Sie Folgendes:
- Ein erfolgreich erstelltes Projekt mit einem konfigurierten Azure Blob Storage-Konto
- Textdaten, die in Ihr Speicherkonto hochgeladen wurden
- Gekennzeichnete Daten
- Ein erfolgreich trainiertes Modell
Auslösen eines automatischen Bezeichnungsauftrags
- Automatische Bezeichnung basierend auf einem Modell, das Sie trainiert haben
- Automatische Bezeichnung mit GPT
Wenn Sie einen automatischen Bezeichnungsauftrag basierend auf dem von Ihnen trainierten Modell auslösen, gibt es einen monatlicher Grenzwert von 5000 Textdatensätzen pro Monat und Ressource. Dies bedeutet, dass derselbe Grenzwert für alle Projekte innerhalb derselben Ressource gilt.
Tipp
Ein Textdatensatz wird als Obergrenze berechnet (Anzahl der Zeichen in einem Dokument geteilt durch 1.000). Wenn ein Dokument beispielsweise 8921 Zeichen enthält, beträgt die Anzahl der Textdatensätze:
ceil(8921/1000) = ceil(8.921), also 9 Texteinträge.
Wählen Sie im linken Navigationsmenü Datenbeschriftung aus.
Wählen Sie im Bereich „Aktivität“ rechts neben der Seite die Schaltfläche Automatische Bezeichnung aus.

Wählen Sie Autolabel basierend auf einem Modell aus, das Sie trainiert haben, und klicken Sie auf Weiter.

Wählen Sie ein trainiertes Modell aus. Es wird empfohlen, die Leistung des Modells zu überprüfen, bevor Sie es für die automatische Bezeichnung verwenden.

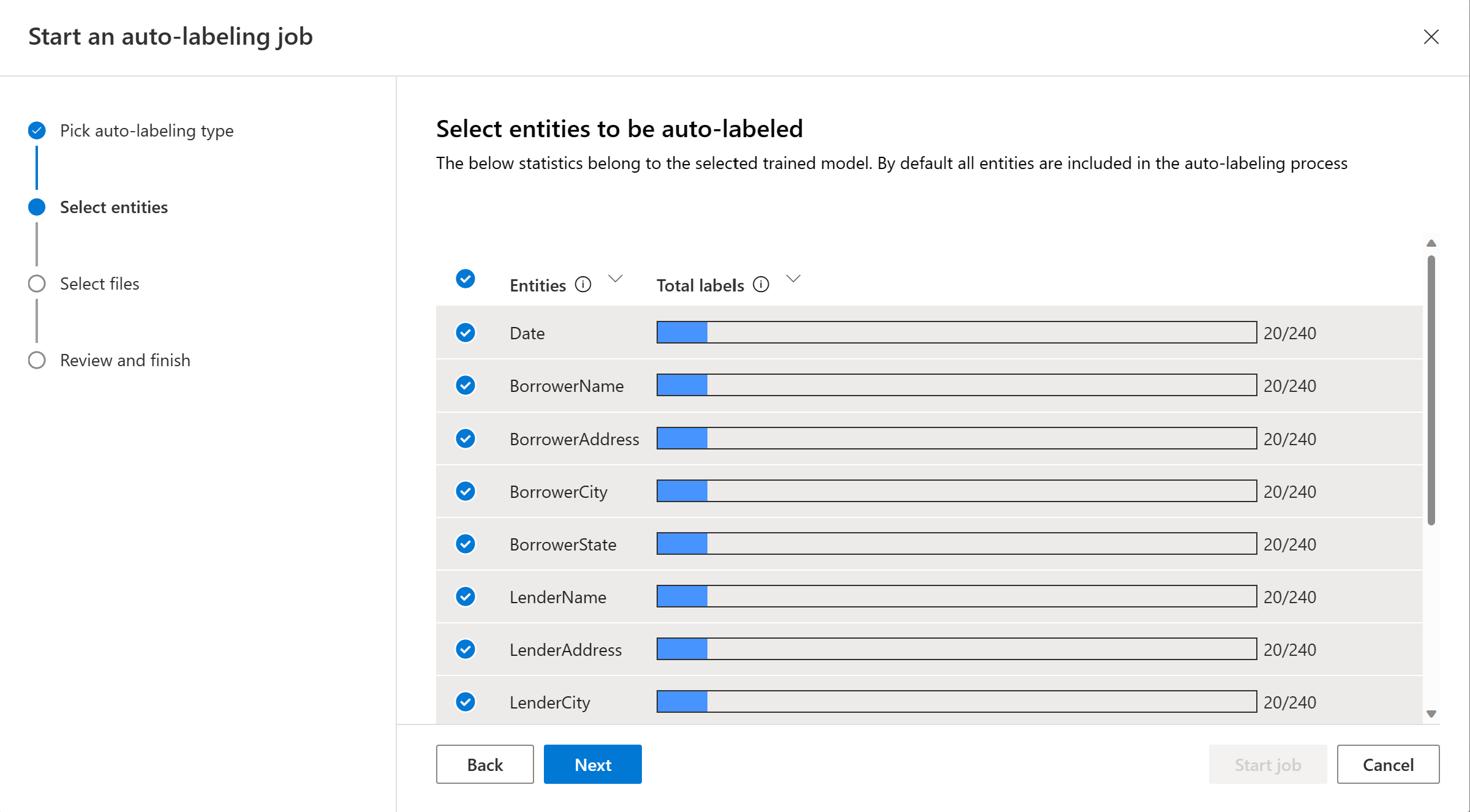
Wählen Sie die Entitäten aus, die Sie in den automatischen Bezeichnungsauftrag einbeziehen möchten. Standardmäßig sind alle Entitäten ausgewählt. Sie können alle Bezeichnungen, die Genauigkeit und den Abruf jeder Entität einsehen. Es wird empfohlen, Entitäten mit guter Leistung einzuschließen, um die Qualität der automatisch bezeichneten Entitäten sicherzustellen.
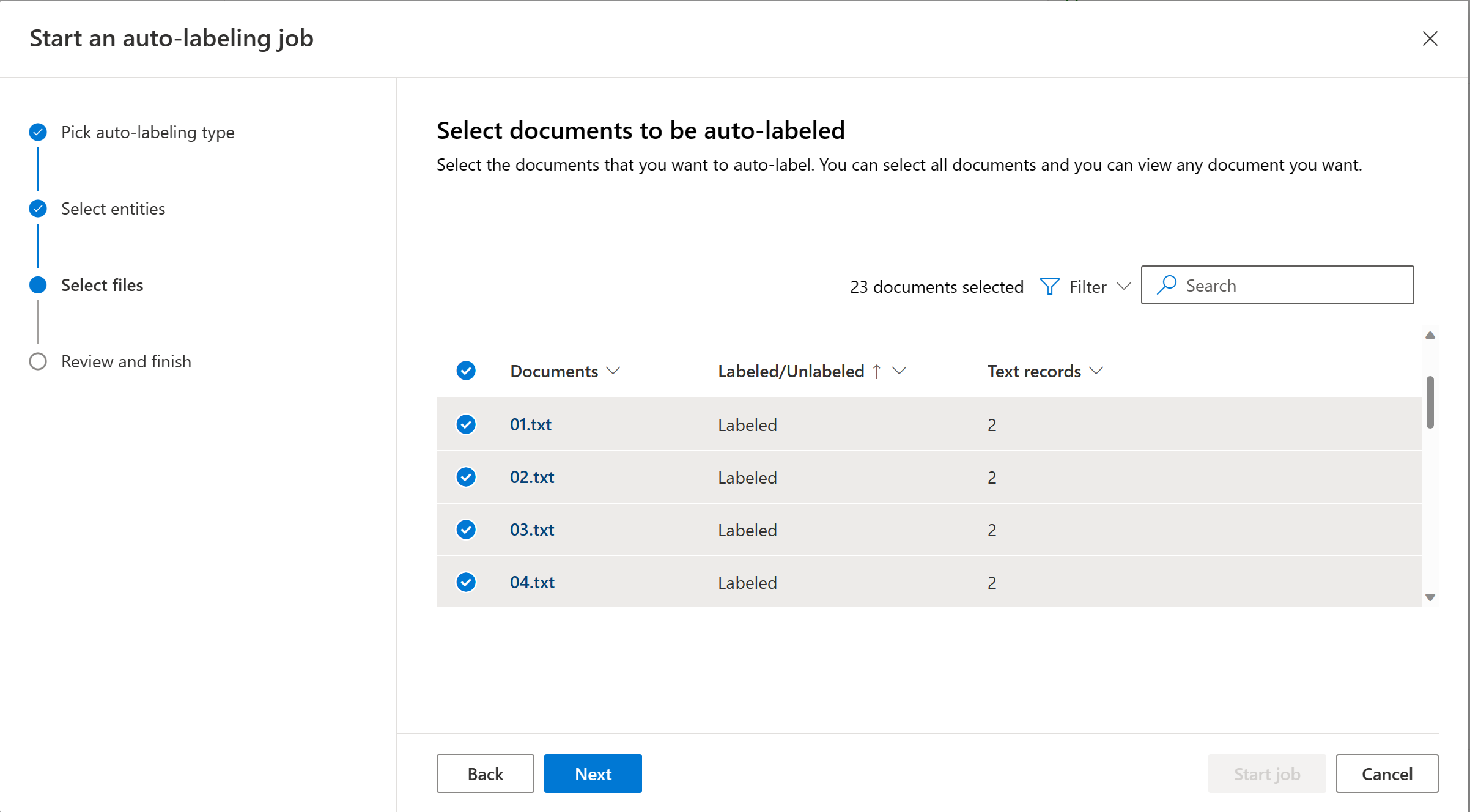
Wählen Sie die Dokumente aus, die automatisch bezeichnet werden sollen. Die Anzahl der Textdatensätze jedes Dokuments wird angezeigt. Wenn Sie ein oder mehrere Dokumente auswählen, sollte die Anzahl der ausgewählten Textdatensätze angezeigt werden. Es wird empfohlen, die nicht bezeichneten Dokumente aus dem Filter auszuwählen.
Hinweis
- Wenn eine Entität automatisch bezeichnet wurde, aber über eine benutzerdefinierte Bezeichnung verfügt, wird nur die benutzerdefinierte Bezeichnung verwendet und ist sichtbar.
- Sie können die Dokumente anzeigen, indem Sie auf den Namen des Dokuments klicken.
Wählen Sie Automatische Bezeichnung aus, um den automatischen Bezeichnungsauftrag auszulösen. Sie sollten das verwendete Modell, die Anzahl der im automatischen Bezeichnungsauftrag enthaltenen Dokumente und die Anzahl der automatisch zu bezeichnenden Textdatensätze und Entitäten sehen. Automatische Bezeichnungsaufträge können zwischen einigen Sekunden und einigen Minuten dauern, abhängig von der Anzahl der von Ihnen eingeschlossenen Dokumente.








Überprüfen der automatisch bezeichneten Dokumente
Wenn der automatische Bezeichnungsauftrag abgeschlossen ist, werden die Ausgabedokumente auf der Seite Datenbeschriftung von Language Studio angezeigt. Wählen Sie Dokumente mit automatischer Bezeichnung überprüfen aus, um die Dokumente mit dem angewendeten Filter Automatische Bezeichnung anzuzeigen.

Entitäten, die automatisch bezeichnet wurden, erscheinen mit einer gepunkteten Linie. Diese Entitäten verfügen über zwei Selektoren (ein Häkchen und ein „X“), mit denen Sie die automatische Bezeichnung annehmen oder ablehnen können.
Sobald eine Bezeichnung akzeptiert wurde, ändert sich die gepunktete Linie in eine durchgezogene, und die Bezeichnung wird in alle weiteren Modelltrainings einbezogen und wird zu einer benutzerdefinierten Bezeichnung.
Alternativ können Sie alle automatisch bezeichneten Entitäten in dem Dokument akzeptieren oder ablehnen, indem Sie Alle annehmen oder Alle ablehnen in der rechten oberen Ecke des Bildschirms verwenden.
Nachdem Sie die bezeichneten Entitäten akzeptiert oder abgelehnt haben, wählen Sie Bezeichnungen speichern aus, um die Änderungen anzuwenden.
Hinweis
- Es wird empfohlen, automatisch bezeichnete Entitäten zu überprüfen, bevor Sie sie annehmen.
- Alle nicht angenommenen Bezeichnungen werden gelöscht, wenn Sie Ihr Modell trainieren.

Nächste Schritte
- Weitere Informationen zum Bezeichnen Ihrer Daten.