Dieser Artikel beschreibt Best Practices für die Überwachung einer Microservicesanwendung, die auf Azure Kubernetes Service (AKS) ausgeführt wird. Zu den speziellen Themen gehören Erfassung von Telemetriedaten, Überwachung des Status eines Clusters, Metriken, Protokollierung, strukturierte Protokollierung und verteilte Ablaufverfolgung. Letzteres wird in diesem Diagramm veranschaulicht:

Laden Sie eine Visio-Datei dieser Architektur herunter.
Erfassung von Telemetriedaten
In jeder komplexen Anwendung geht irgendwann etwas schief. In einer Microserviceanwendung ist es erforderlich, dass Sie nachverfolgen, was für Dutzende oder sogar Hunderte von Diensten passiert. Damit ermittelt werden kann, was vor sich geht, müssen Sie Telemetriedaten aus der Anwendung erfassen. Telemetriedaten lassen sich in diese Kategorien unterteilen: Protokolle, Ablaufverfolgungen und Metriken.
Protokolle sind textbasierte Datensätze mit Ereignissen, die eintreten, während eine Anwendung ausgeführt wird. Sie enthalten Dinge wie Anwendungsprotokolle (Überwachungsanweisungen) und Webserverprotokolle. Protokolle sind hauptsächlich für forensische Zwecke und die Analyse der Grundursache hilfreich.
Ablaufverfolgungen werden auch als Vorgänge bezeichnet. Sie verbinden die Schritte einer einzelnen Anforderung über mehrere Aufrufe hinweg – sowohl innerhalb von Microservices als auch über Microservices hinweg. Sie können einen strukturierten Einblick in die Interaktionen von Systemkomponenten bieten. Ablaufverfolgungen können früh im Anforderungsprozess beginnen (etwa auf der Benutzeroberfläche einer Anwendung) und über Netzwerkdienste auf ein Netzwerk von Microservices verteilt werden, von denen die Anforderung verarbeitet wird.
- Spannen sind Arbeitseinheiten innerhalb einer Ablaufverfolgung. Jede Spanne ist mit einer einzelnen Ablaufverfolgung verbunden und kann mit anderen Spannen geschachtelt werden. Sie entsprechen häufig einzelnen Anforderungen in einem dienstübergreifenden Vorgang, können aber auch Arbeiten in einzelnen Komponenten innerhalb eines Diensts definieren. Mit Spans werden darüber hinaus ausgehende Aufrufe von einem Dienst an einen anderen nachverfolgt. (Manchmal werden Spans als Abhängigkeitsdatensätze bezeichnet.)
Metriken sind numerische Werte, die analysiert werden können. Sie können sie verwenden, um ein System in Echtzeit (bzw. nahezu in Echtzeit) zu beobachten oder Leistungstrends im Zeitverlauf zu analysieren. Um ein System ganzheitlich zu verstehen, müssen Sie von der physischen Infrastruktur bis zur Anwendung Metriken auf verschiedenen Ebenen der Architektur sammeln, einschließlich:
Metriken auf Knotenebene, z.B. Auslastung von CPU, Arbeitsspeicher, Netzwerk, Datenträger und Dateisystem. Systemmetriken fördern das Verständnis der Ressourcenzuteilung für die einzelnen Knoten im Cluster und ermöglichen die Problembehandlung bei Ausreißern.
Containermetriken Für Anwendungen in Containern müssen Sie auch auf der Containerebene Metriken sammeln, nicht nur auf der VM-Ebene.
Anwendungsmetriken. Diese Metriken sind für das Verständnis des Verhaltens eines Diensts relevant. Beispiele hierfür sind die Anzahl von in die Warteschlange eingereihten eingehenden HTTP-Anforderungen, die Anforderungswartezeit und die Länge der Nachrichtenwarteschlange. Anwendungen können auch benutzerdefinierte Metriken für die jeweilige Domäne verwenden, wie z.B. die Anzahl der pro Minute verarbeiteten Geschäftstransaktionen.
Metriken abhängiger Dienste. Dienste rufen zuweilen externe Dienste oder Endpunkte auf, wie z. B. verwaltete PaaS- oder SaaS-Dienste. Drittanbieterdienste bieten möglicherweise keine Metriken. Falls sie das nicht tun, müssen Sie Ihre eigenen Anwendungsmetriken verwenden, um Statistiken in Bezug auf die Wartezeit und Fehlerrate nachzuverfolgen.
Überwachen des Clusterstatus
Überwachen Sie den Zustand Ihrer Cluster mit Azure Monitor. Der folgende Screenshot zeigt einen Cluster mit kritischen Fehlern in vom Benutzer bereitgestellten Pods:

Von hier aus können Sie weiter vordringen, um das Problem zu finden. Wenn der Podstatus beispielsweise ImagePullBackoff lautet, konnte Kubernetes das Containerimage nicht aus der Registrierung pullen. Ein ungültiges Containertag oder ein Authentifizierungsfehler während des Pullens aus der Registrierung könnte die Ursache dieses Problems sein.
Wenn ein Container abstürzt, wird der Container State zum Waiting mit einem Reason von CrashLoopBackOff. In einem typischen Szenario, in dem ein Pod Teil einer Replikatgruppe ist und die Wiederholungsrichtlinie Always lautet, wird dieses Problem nicht als Fehler im Clusterstatus angezeigt. Sie können jedoch Abfragen ausführen oder Warnungen für diese Bedingung einrichten. Weitere Informationen finden Sie unter Verstehen der Leistung von AKS-Clustern mithilfe von Azure Monitor-Containererkenntnissen.
Im Arbeitsmappenbereich einer AKS-Ressource sind mehrere containerspezifische Arbeitsmappen verfügbar. Sie können diese Arbeitsmappen für eine schnelle Übersicht, Problembehandlung, Verwaltung und Erkenntnisse verwenden. Der folgende Screenshot zeigt eine Liste der Arbeitsmappen, die standardmäßig für AKS-Workloads verfügbar sind:

Metrics
Sie sollten Monitor verwenden, um Metriken für Ihre AKS-Cluster und alle anderen abhängigen Azure-Dienste zu sammeln und anzuzeigen.
Aktivieren Sie für Cluster- und Containermetriken Azure Monitor- Containererkenntnisse. Wenn dieses Feature aktiviert ist, sammelt Monitor mit der Metriken-API in Kubernetes Speicher- und Prozessormetriken von Controllern, Knoten und Containern. Weitere Informationen zu den Metriken, die über Containererkenntnisse verfügbar sind, finden Sie unter Verstehen der Leistung von AKS-Clustern mithilfe von Azure Monitor-Containererkenntnissen.
Sammeln Sie Anwendungsmetriken mithilfe von Application Insights. Application Insights ist ein erweiterbarer Dienst zur Verwaltung der Anwendungsleistung (Application Performance Management, APM). Für die Nutzung von Application Insights installieren Sie in Ihrer Anwendung ein Instrumentierungspaket. Dieses Paket überwacht die App und sendet Telemetriedaten an Application Insights. Außerdem können hiermit per Pullvorgang Telemetriedaten aus der Hostumgebung abgerufen werden. Die Daten werden dann an Monitor gesendet. Application Insights verfügt darüber hinaus über eine integrierte Korrelations- und Abhängigkeitsnachverfolgung. (Siehe Verteilte Ablaufverfolgung weiter unten in diesem Artikel.)
Application Insights hat einen in Ereignissen pro Sekunde gemessenen maximalen Durchsatz und drosselt die Telemetrie, wenn die Datenrate den Grenzwert überschreitet. Weitere Informationen finden Sie unter Application Insights-Grenzwerte. Erstellen Sie verschiedene Application Insights-Instanzen für jede Umgebung, sodass Entwicklungs-/Testumgebungen nicht mit der Produktionstelemetrie um Kontingente konkurrieren.
Da ein einzelner Vorgang mehrere Telemetrieereignisse generieren kann, wird die zugehörige Telemetriedatenerfassung wahrscheinlich gedrosselt, wenn die Menge an Datenverkehr für eine Anwendung sehr hoch ist. Zur Lösung dieses Problems können Sie den Telemetriedatenverkehr durch die Erstellung von Stichproben reduzieren. Der Nachteil hierbei ist, dass Ihre Metriken weniger genau sind, es sei denn, die Instrumentierung unterstützt Vorabaggregation. In diesem Fall gibt es weniger Ablaufverfolgungsbeispiele für die Problembehandlung, aber die Metriken behalten ihre Genauigkeit. Weitere Informationen finden Sie unter Erstellen von Stichproben in Application Insights. Sie können das Datenvolumen auch reduzieren, indem Sie Metriken vorab aggregieren. Das heißt, Sie können statistische Werte wie die Durchschnitts- und Standardabweichung berechnen und diese Werte anstelle der rohen Telemetriedaten senden. In diesem Blogbeitrag wird ein Ansatz für die bedarfsabhängige Nutzung von Application Insights beschrieben: Bedarfsabhängige Nutzung der Azure-Überwachung und von Analytics.
Wenn Ihre Datenrate hoch genug ist, um eine Drosselung auszulösen, und Sampling oder Aggregation nicht akzeptabel sind, können Sie Metriken ggf. in eine im Cluster ausgeführte Zeitreihendatenbank wie Azure Data Explorer, Prometheus oder InfluxDB exportieren.
Azure Data Explorer ist ein Azure-nativer und hochgradig skalierbarer Dienst zur Untersuchung von Protokoll- und Telemetriedaten. Von ihm werden mehrere Datenformate, eine umfassende Abfragesprache sowie Verbindungen zur Nutzung von Daten in gängigen Tools wie Jupyter Notebook und Grafana unterstützt. Azure Data Explorer verfügt über integrierte Connectors zum Erfassen von Protokoll- und Metrikdaten über Azure Event Hubs. Weitere Informationen finden Sie unter Tutorial: Erfassen und Abfragen von Überwachungsdaten in Azure Data Explorer.
InfluxDB ist ein Push-basiertes System. Die Metriken müssen von einem Agent per Pushvorgang übertragen werden. Sie können TICK Stack verwenden, um die Überwachung von Kubernetes einzurichten. Als Nächstes können Sie Metriken in InfluxDB pushen, indem Sie Telegraf verwenden, wobei es sich um einen Agent zum Erfassen und Melden von Metriken handelt. InfluxDB kann für unregelmäßige Ereignisse und Zeichenfolgen-Datentypen verwendet werden.
Prometheus ist ein Pull-basiertes System. Hierbei werden Metriken per „Scraping“ regelmäßig von konfigurierten Speicherorten abgerufen. Prometheus ermöglicht die Erfassung von Metriken, die von Azure Monitor generiert wurden, sowie von Metriken, die von kube-state-metrics generiert wurden. kube-state-metrics ist ein Dienst, mit dem Metriken vom Kubernetes-API-Server gesammelt und für Prometheus (oder einen Scraper, der mit einem Prometheus-Clientendpunkt kompatibel ist) zur Verfügung gestellt werden. Verwenden Sie für Systemmetriken den Knoten-Exporter. Dies ist ein Prometheus-Exportprogramm für Systemmetriken. Prometheus unterstützt Gleitkommadaten, aber keine Zeichenfolgendaten, und ist daher nicht für Protokolle geeignet, sondern nur für Systemmetriken. Kubernetes Metrics Server ist ein clusterweiter Aggregator zum Zusammenfassen der Daten zur Ressourcenverwendung.
Protokollierung
Zu einigen der allgemeinen Herausforderungen bei der Protokollierung in einer Microservicesanwendung zählen:
- Verstehen der End-to-End-Verarbeitung einer Clientanforderung, bei der mehrere Dienste aufgerufen werden könnten, um eine einzelne Anforderung zu bearbeiten.
- Konsolidierung von Protokollen aus mehreren Diensten in einer einzigen aggregierten Ansicht.
- Analysieren von Protokollen, die aus mehreren Quellen stammen, die eigene Protokollschemata verwenden oder kein bestimmtes Schema haben. Protokolle können von Drittanbieterkomponenten generiert werden, die Sie nicht steuern.
- Microservicesarchitekturen erzeugen oft ein größeres Volumen an Protokollen als herkömmliche Monolithe, da es mehr Dienste, Netzwerkaufrufe und Schritte in einer Transaktion gibt. Das bedeutet, dass die Protokollierung selbst ein Leistungs- oder Ressourcenengpass für die Anwendung sein kann.
Es gibt einige zusätzlichen Herausforderungen für Kubernetes-basierte Architekturen:
- Container können verschoben und neu geplant werden.
- Kubernetes ist eine Netzwerkabstraktion, die virtuelle IP-Adressen und Portzuordnungen verwendet.
In Kubernetes ist der Standardansatz für die Protokollierung, dass ein Container Protokolle in „stdout“ und „stderr“ schreibt. Das Containermodul leitet diese Streams an einen Protokollierungstreiber weiter. Um Abfragen zu erleichtern und den möglichen Verlust von Protokolldaten zu vermeiden, wenn ein Knoten nicht mehr reagiert, ist es üblich, die Protokolle von jedem Knoten zu sammeln und an einen zentralen Speicherort zu senden.
Die Integration von Azure Monitor in AKS unterstützt diesen Ansatz. Monitor sammelt Containerprotokolle und sendet sie an den Log Analytics-Arbeitsbereich. Von dort aus können Sie mit der Kusto-Abfragesprache auf die aggregierten Protokolle bezogene Abfragen schreiben. Dieses Beispiel einer Kusto-Abfrage ruft die Anzeige der Containerprotokolle für einen bestimmten Pod ab:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure Monitor ist ein verwalteter Dienst, und die Konfiguration eines AKS-Clusters zur Verwendung von Monitor ist eine einfache Konfigurationsänderung in der CLI- oder Azure Resource Manager-Vorlage. (Weitere Informationen finden Sie unter Aktivieren von Azure Monitor Container Insights.) Ein weiterer Vorteil der Verwendung von Azure Monitor ist die Konsolidierung Ihrer AKS-Protokolle mit anderen Protokollen der Azure-Plattform, sodass eine einheitliche Überwachungserfahrung entsteht.
Die Abrechnung von Azure Monitor erfolgt pro GB an Daten, die im Dienst erfasst werden. (Siehe Azure Monitor-Preise.) Bei hohen Volumina können die Kosten zu einer Überlegung werden. Für das Kubernetes-Ökosystem gibt es viele Open-Source-Alternativen. Viele Organisationen verwenden z.B. Fluentd mit Elasticsearch. Fluentd ist ein Open-Source-Datensammler, und Elasticsearch ist eine Dokumentdatenbank für die Suche. Eine Herausforderung bei diesen Optionen ist, dass sie zusätzliche Konfiguration und Verwaltung des Clusters erfordern. Für eine Produktionsworkload müssen Sie möglicherweise mit Konfigurationseinstellungen experimentieren. Sie müssen auch die Leistung der Protokollierungsinfrastruktur überwachen.
OpenTelemetry
OpenTelemetry ist eine branchenübergreifende Bestrebung zur Verbesserung der Ablaufverfolgung durch Standardisierung der Schnittstelle zwischen Anwendungen, Bibliotheken, Telemetriedaten und Datensammlern. Wenn Sie eine mit OpenTelemetry instrumentierte Bibliothek und ein entsprechendes Framework verwenden, wird der Großteil der Ablaufverfolgung (üblicherweise für Systemvorgänge) von den zugrunde liegenden Bibliotheken übernommen. Gängige Szenarien hierfür wären etwa:
- Protokollierung grundlegender Anforderungsvorgänge wie Startzeit, Beendigungszeit und Dauer
- Ausgelöste Ausnahmen
- Kontextpropagierung (beispielsweise Senden einer Korrelations-ID über HTTP-Aufrufgrenzen hinweg)
Stattdessen erstellen die Basisbibliotheken und -frameworks, von denen diese Vorgänge verarbeitet werden, umfangreiche zusammenhängende Spannen- und Ablaufverfolgungsdatenstrukturen und geben sie kontextübergreifend weiter. Vor OpenTelemetry wurden sie in der Regel nur als spezielle Protokollmeldungen oder als proprietäre Datenstrukturen eingefügt, die spezifisch für den Anbieter waren, von dem die Überwachungstools erstellt wurden. OpenTelemetry treibt auch die Nutzung eines umfassenderen Instrumentierungsdatenmodells (im Vergleich zum herkömmlichen protokollierungsfokussierten Ansatz) voran, und die Protokolle werden nützlicher, da die Protokollmeldungen mit den Ablaufverfolgungen und Spannen ihrer Generierung verknüpft sind. Dadurch können Protokolle, die mit einem bestimmten Vorgang oder einer bestimmten Anforderung zusammenhängen, oftmals einfach gefunden werden.
Viele der Azure SDKs wurden mit OpenTelemetry instrumentiert oder befinden sich in der Implementierungsphase.
Mithilfe der OpenTelemetry SDKs können Anwendungsentwickler eine manuelle Instrumentierung für folgende Aktivitäten hinzufügen:
- Hinzufügen einer Instrumentierung, wenn sie von einer zugrunde liegenden Bibliothek nicht bereitgestellt wird.
- Anreichern des Ablaufverfolgungskontexts durch Hinzufügen von Spannen, um anwendungsspezifische Arbeitseinheiten verfügbar zu machen (beispielsweise eine Auftragsschleife, die eine Spanne für die Verarbeitung der einzelnen Auftragspositionen erstellt).
- Erweitern Sie vorhandene Spannen mit Entitätsschlüsseln, um eine einfachere Ablaufverfolgung zu ermöglichen. (Fügen Sie der Anforderung beispielsweise einen OrderID-Schlüssel/-Wert hinzu, mit dem der betreffende Auftrag verarbeitet wird.) Diese Schlüssel werden von den Überwachungstools als strukturierte Werte zum Abfragen, Filtern und Aggregieren verfügbar gemacht, ohne jedoch Protokollmeldungszeichenfolgen zu analysieren oder nach Kombinationen von Protokollmeldungssequenzen zu suchen, wie es bei einem protokollierungsfokussierten Ansatz üblich war.
- Geben Sie den Ablaufverfolgungskontext weiter, indem Sie auf Ablaufverfolgungs- und Span-Attribute zugreifen, traceIds in Antworten und Nutzlasten injizieren und/oder traceIds aus eingehenden Nachrichten lesen, um Anforderungen und Spannen zu erstellen.
Weitere Informationen zur Instrumentierung und zu den OpenTelemetry SDKs finden Sie in der Dokumentation zu OpenTelemetry.
Application Insights
Application Insights sammelt umfangreiche Daten aus OpenTelemetry und den zugehörigen Instrumentierungsbibliotheken und erfasst sie in einem effizienten Datenspeicher, um umfassende Visualisierungs- und Abfrageunterstützung zu bieten. Dank der OpenTelemetry-basierten Instrumentierungsbibliotheken von Application Insights für Sprachen wie .NET, Java, Node.js und Python können Telemetriedaten ganz einfach an Application Insights gesendet werden.
Bei Verwendung von .NET Core sollten Sie sich auch die Bibliothek Application Insights for Kubernetes ansehen. Diese Bibliothek erweitert Application Insights-Ablaufverfolgungen um zusätzliche Informationen wie Container, Knoten, Pod, Bezeichnungen und Replikatgruppe.
Application Insights ordnet den OpenTelemetry-Kontext seinem internen Datenmodell zu:
- Ablaufverfolgung > Vorgang
- Ablaufverfolgungs-ID > Vorgangs-ID
- Spanne > Anforderung oder Abhängigkeit
Berücksichtigen Sie die folgenden Aspekte:
- Application Insights drosselt die Telemetrie, wenn die Datenrate einen bestimmten Grenzwert überschreitet. Weitere Informationen finden Sie unter Application Insights-Grenzwerte. Ein einzelner Vorgang kann mehrere Telemetrieereignisse generieren, sodass eine Anwendung wahrscheinlich gedrosselt wird, wenn die Menge an Datenverkehr sehr hoch ist.
- Da Application Insights Daten in Batches zusammenfasst, kann ein Batch verloren gehen, wenn ein Prozess mit einem Ausnahmefehler fehlschlägt.
- Application Insights wird auf Basis des Datenvolumens abgerechnet. Weitere Informationen finden Sie unter Verwalten von Preisen und Datenvolumen in Application Insights.
Strukturierte Protokollierung
Um die Analyse von Protokollen zu erleichtern, verwenden Sie nach Möglichkeit die strukturierte Protokollierung. Wenn Sie mit der strukturierten Protokollierung arbeiten, schreibt die Anwendung Protokolle in einem strukturierten Format wie z. B. JSON, anstatt unstrukturierte Textelemente auszugeben. Es sind viele Bibliotheken zur strukturierten Protokollierung verfügbar. Diese Protokollierungsanweisung verwendet z. B. die Serilog-Bibliothek für .NET Core :
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
Hier enthält der Aufruf von LogInformation einen Id- und einen DeliveryInfo-Parameter. Mit der strukturierten Protokollierung werden diese Werte nicht in die Meldungszeichenfolge interpoliert. Stattdessen sieht die Protokollausgabe in etwa wie folgt aus:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
In dieser JSON-Zeichenfolge ist das @t-Feld ein Zeitstempel, @mt die Meldungszeichenfolge und die restlichen Schlüssel/Wert-Paare sind die Parameter. Die Ausgabe im JSON-Format erleichtert die strukturierte Abfrage der Daten. Die in der Kusto-Abfragesprache geschriebene folgende Log Analytics-Abfrage sucht beispielsweise nach Instanzen dieser bestimmten Nachricht aus allen Containern mit dem Namen fabrikam-delivery:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Wenn Sie das Ergebnis im Azure-Portal anzeigen, sehe Sie, dass DeliveryInfo ein strukturierter Datensatz ist, der die serialisierte Darstellung des DeliveryInfo-Modells enthält:

Dies ist der JSON-Code dieses Beispiels:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Viele Protokollmeldungen stellen den Beginn oder das Ende einer Arbeitseinheit dar oder verbinden eine Geschäftsentität mit einer Reihe von Nachrichten und Vorgängen für die Nachverfolgung. In vielen Fällen ist die Anreicherung von Spannen- und Anforderungsobjekten von OpenTelemetry ein besserer Ansatz, als nur den Anfang und das Ende des Vorgangs zu protokollieren. Dadurch wird der Kontext allen verbundenen Ablaufverfolgungen und untergeordneten Vorgängen hinzufügt, und die Informationen werden im Bereich des vollständigen Vorgangs platziert. Die OpenTelemetry SDKs für verschiedene Sprachen unterstützen das Erstellen von Spannen sowie das Hinzufügen benutzerdefinierter Attribute für Spannen. Im folgenden Code wird beispielsweise das Java OpenTelemetry SDK verwendet, das von Application Insights unterstützt wird. Eine vorhandene übergeordnete Span (beispielsweise eine Anforderungs-Span, die einem REST-Controlleraufruf zugeordnet ist und vom verwendeten Webframework erstellt wurde) kann mit einer ihr zugeordneten Entitäts-ID angereichert werden:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Durch diesen Code wird ein Schlüssel oder Wert für die aktuelle Spanne festgelegt, die mit Vorgängen und Protokollmeldungen verbunden ist, die unter dieser Spanne auftreten. Der Wert wird im Application Insights-Anforderungsobjekt angezeigt, wie hier zu sehen:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Durch die Verwendung mit Protokollen und Filtern sowie durch das Kommentieren von Protokollablaufverfolgungen mit Span-Kontext können Sie, wie hier zu sehen, den Nutzen dieser Technik noch weiter erhöhen:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Wenn Sie eine Bibliothek oder ein Framework verwenden, die bzw. das bereits mit OpenTelemetry instrumentiert ist, wird die Erstellung von Spannen und Anforderungen zwar von OpenTelemetry übernommen, vom Anwendungscode werden jedoch möglicherweise auch Arbeitseinheiten erstellt. So kann beispielsweise eine Methode, die ein Array von Entitäten durchläuft und Aktionen für die einzelnen Entitäten ausführt, ggf. eine Spanne für jede Iteration der Verarbeitungsschleife erstellen. Informationen zum Hinzufügen von Instrumentierung zu Anwendungs- und Bibliothekscode finden Sie in der Dokumentation zur OpenTelemery-Instrumentierung.
Verteilte Ablaufverfolgung
Eine der Herausforderungen der Verwendung von Microservices besteht darin, den Fluss der Ereignisse über Dienste hinweg zu verstehen. Eine einzelne Transaktion kann Aufrufe mehrerer Dienste umfassen.
Beispiel zur verteilten Ablaufverfolgung
In diesem Beispiel wird der Pfad einer verteilten Transaktion durch eine Reihe von Microservices beschrieben. Das Beispiel basiert auf einer Drohnenlieferungsanwendung.
In diesem Szenario beinhaltet die verteilte Transaktion diese Schritte:
- Der Ingestion-Dienst platziert eine Nachricht in einer Azur Service Bus-Warteschlange.
- Der Workflow-Dienst pullt die Nachricht aus der Warteschlange.
- Der Workflow-Dienst ruft drei Back-End-Dienste (Drone Scheduler, Package und Delivery) zur Verarbeitung der Anforderung auf.
Der folgende Screenshot zeigt die Anwendungsübersicht für die Drohnenlieferungsanwendung. Diese Karte zeigt Aufrufe des öffentlichen API-Endpunkts, die zu einem Workflow mit fünf Microservices führen.
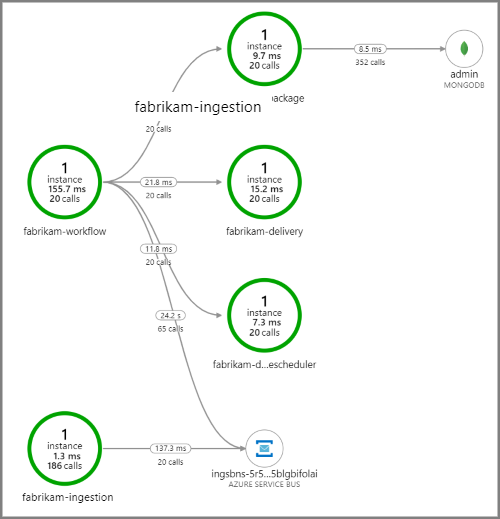
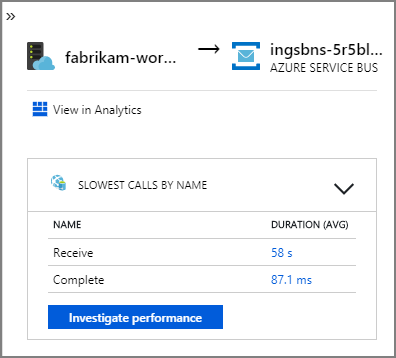
Die auf eine Service Bus-Warteschlange weisenden Pfeile von fabrikam-workflow und fabrikam-ingestion zeigen, wo die Nachrichten gesendet und empfangen werden. Sie können im Diagramm nicht erkennen, welcher Dienst Nachrichten sendet und welcher Nachrichten empfängt. Die Pfeile zeigen nur an, dass beide Dienste Service Bus aufrufen. Informationen darüber, welcher Dienst gesendet wird und welcher empfängt, finden Sie in den Details:
Da jeder Aufruf eine Vorgangs-ID enthält, können Sie auch die End-to-End-Schritte einer einzelnen Transaktion einschließlich Informationen zum Timing und der HTTP-Aufrufe bei jedem Schritt anzeigen. Hier sehen Sie die Visualisierung einer solchen Transaktion:

Diese Visualisierung zeigt die Schritte vom Ingestion-Dienst zur Warteschlange, von der Warteschlange zum Workflow-Dienst und vom Workflow-Dienst zu den anderen Back-End-Diensten. Im letzten Schritt markiert der Workflow-Dienst die Service Bus-Nachricht als abgeschlossen.
Dieses Beispiel zeigt Aufrufe eines Back-End-Diensts, die fehlschlagen:
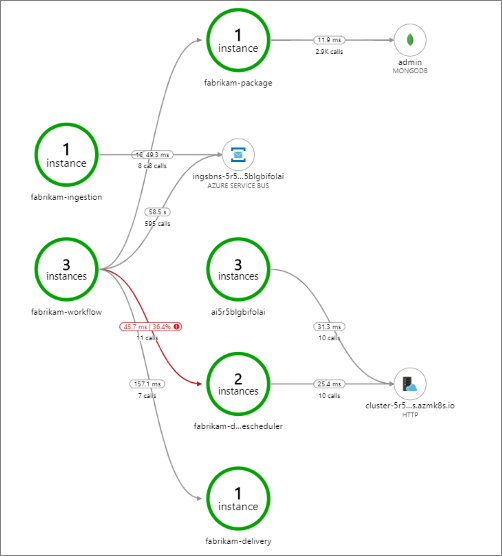
Diese Karte zeigt, dass während des Abfragezeitraums bei einem großen Teil (36%) der Aufrufe des Drone Scheduler-Diensts Fehler aufgetreten sind. Die End-to-End-Transaktionsansicht zeigt, dass beim Senden einer HTTP-PUT-Anfrage an den Dienst ein Ausnahmefehler aufgetreten ist.

Wenn Sie einen weiteren Drilldown ausführen, können Sie sehen, dass es sich bei der Ausnahme um eine Socket-Ausnahme handelt: „Kein solches Gerät bzw. keine solche Adresse.“
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Diese Ausnahme legt nahe, dass der Back-End-Dienst nicht erreichbar ist. An diesem Punkt könnten Sie „kubectl“ verwenden, um die Bereitstellungskonfiguration anzuzeigen. In diesem Beispiel wird der Diensthostname aufgrund eines Fehlers in den Kubernetes-Konfigurationsdateien nicht aufgelöst. Der Artikel Debuggen von Diensten in der Kubernetes-Dokumentation enthält Tipps zum Diagnostizieren dieser Art von Fehlern.
Im Folgenden finden Sie einige häufige Fehlerursachen:
- Fehler im Code. Diese Fehler können wie folgt aussehen:
- Ausnahmen. Untersuchen Sie die Details der Ausnahme in den Application Insights-Protokollen.
- Fehler bei einem Prozess. Sehen Sie sich den Status von Containern und Pods an, und untersuchen Sie Containerprotokolle oder Application Insights-Ablaufverfolgungen.
- HTTP 5xx-Fehler.
- Ressourcenauslastung:
- Achten Sie auf Drosselung (HTTP 429) oder Timeoutanforderungen.
- Überprüfen Sie die Containermetriken für CPU, Arbeitsspeicher und Datenträger.
- Achten Sie auf die Konfigurationen für Container- und Podressourcenlimits.
- Dienstermittlung: Überprüfen Sie die Kubernetes-Dienstkonfiguration und Portzuordnungen.
- API-Konflikt. Suchen Sie nach HTTP 400-Fehlern. Wenn die Versionen der APIs angegeben sind, überprüfen Sie, welche Version aufgerufen wird.
- Fehler beim Pullen eines Containerimage. Sehen Sie sich die Podspezifikation an. Stellen Sie außerdem sicher, dass der Cluster zum Pullen aus der Containerregistrierung autorisiert ist.
- RBAC-Probleme.
Nächste Schritte
Weitere Informationen zu den Features in Azure Monitor, die die Überwachung von Anwendungen in AKS unterstützen, finden Sie hier:
- Übersicht über Azure Monitor-Containererkenntnisse
- Verstehen der Leistung von AKS-Clustern mithilfe von Azure Monitor Container Insights