Diese Referenzarchitektur zeigt eine serverlose, ereignisgesteuerte Architektur, die einen Datenstrom erfasst, die Daten verarbeitet und die Ergebnisse in eine Back-End-Datenbank schreibt.
Aufbau
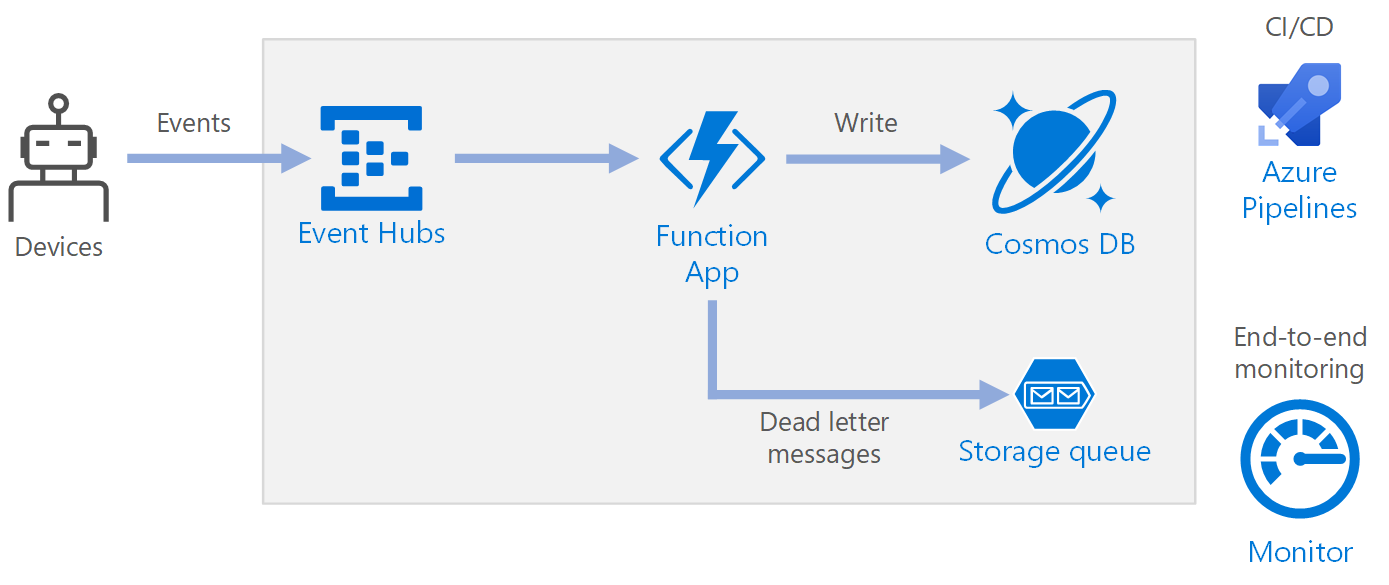
Workflow
- Ereignisse treffen auf Azure Event Hubs ein.
- Eine Funktions-App wird ausgelöst, um das Ereignis zu bearbeiten.
- Das Ereignis wird in einer Azure Cosmos DB-Datenbank gespeichert.
- Wenn die Funktions-App das Ereignis nicht erfolgreich speichern kann, wird das Ereignis in einer Speicherwarteschlange für die spätere Verarbeitung gespeichert.
Komponenten
Der Datenstrom wird mit Event Hubs erfasst. Event Hubs ist für Datenstromszenarien mit hohem Durchsatz konzipiert.
Hinweis
Für Internet der Dinge (IoT)-Szenarien empfehlen wir Azure IoT Hub. IoT Hub verfügt über einen integrierten Endpunkt, der mit der Azure Event Hubs-API kompatibel ist, sodass Sie beide Dienste in dieser Architektur ohne größere Änderungen bei der Back-End-Verarbeitung nutzen können. Weitere Informationen finden Sie unter Verbinden von IoT-Geräten mit Azure: IoT Hub und Event Hubs.
Funktions-App. Azure Functions ist eine serverlose Computeoption. Es wird ein ereignisgesteuertes Modell verwendet, bei dem ein Codeabschnitt (eine Funktion) durch einen Trigger aufgerufen wird. Wenn in dieser Architektur Ergebnisse auf einer Event Hubs-Instanz eingehen, lösen sie eine Funktion aus, mit der die Ereignisse verarbeitet und die Ergebnisse in den Speicher geschrieben werden.
Funktions-Apps sind für die Verarbeitung einzelner Datensätze von Event Hubs geeignet. Für komplexere Szenarien zur Verarbeitung von Datenströmen können Sie erwägen, Apache Spark mit Azure Databricks oder Azure Stream Analytics zu verwenden.
Azure Cosmos DB. Azure Cosmos DB ist ein Datenbankdienst mit mehreren Modellen, der in einem serverlosen, verbrauchsbasierten Modus verfügbar ist. Für dieses Szenario speichert die Funktion für die Ereignisverarbeitung JSON-Datensätze mithilfe von Azure Cosmos DB for NoSQL.
Warteschlangenspeicher. Warteschlangenspeicher wird für unzustellbare Nachrichten verwendet. Wenn bei der Verarbeitung eines Ereignisses ein Fehler auftritt, speichert die Funktion die Ereignisdaten in einer Warteschlange für unzustellbare Nachrichten zur späteren Verarbeitung. Weitere Informationen finden Sie im Abschnitt „Resilienz“ weiter unten in diesem Artikel.
Azure Monitor: Monitor erfasst Leistungsmetriken zu den in der Lösung bereitgestellten Azure-Diensten. Durch die Visualisierung dieser Metriken in einem Dashboard können Sie einen Einblick in die Integrität der Lösung gewinnen.
Azure Pipelines. Pipelines ist ein CI-/CD-Dienst (Continuous Integration/Continuous Delivery), mit dem die Anwendung erstellt, getestet und bereitgestellt wird.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Verfügbarkeit
Die hier dargestellte Bereitstellung befindet sich in nur einer Azure-Region. Nutzen Sie die Features für die geografische Verteilung in den verschiedenen Diensten, um einen stabileren Ansatz für die Notfallwiederherstellung zu erzielen:
- Event Hubs. Erstellen Sie zwei Event Hubs-Namespaces: einen primären (aktiven) Namespace und einen sekundären (passiven) Namespace. Nachrichten werden automatisch an den aktiven Namespace weitergeleitet, sofern Sie kein Failover zum sekundären Namespace ausführen. Weitere Informationen finden Sie unter Georedundante Notfallwiederherstellung in Azure Event Hubs.
- Funktions-App. Stellen Sie eine zweite Funktions-App bereit, die darauf wartet, vom sekundären Event Hubs-Namespace zu lesen. Mit dieser Funktion werden Daten in ein sekundäres Speicherkonto für die Warteschlange für unzustellbare Nachrichten geschrieben.
- Azure Cosmos DB. Azure Cosmos DB unterstützt mehrere Schreibregionen, sodass Schreibvorgänge in alle Regionen möglich sind, die Sie Ihrem Azure Cosmos DB-Konto hinzufügen. Wenn Sie die Funktion für mehrere Schreibvorgänge nicht aktivieren, können Sie trotzdem ein Failover auf die primäre Schreibregion ausführen. Die Azure Cosmos DB-Client-SDKs und die Azure Function-Bindungen verarbeiten das Failover automatisch, sodass Sie keine Einstellungen für die Anwendungskonfiguration aktualisieren müssen.
- Azure Storage. Verwenden Sie RA-GRS-Speicher für die Warteschlange für unzustellbare Nachrichten. Hierdurch wird ein schreibgeschütztes Replikat in einer anderen Region erstellt. Wenn die primäre Region ausfällt, können Sie die derzeit in der Warteschlange befindlichen Elemente lesen. Stellen Sie darüber hinaus ein weiteres Speicherkonto in der sekundären Region bereit, in das die Funktion nach einem Failover schreiben kann.
Skalierbarkeit
Event Hubs
Die Durchsatzkapazität von Event Hubs wird in Durchsatzeinheiten gemessen. Sie können einen Event Hub automatisch skalieren, indem Sie die Funktion für automatische Vergrößerung aktivieren. Dadurch werden die Durchsatzeinheiten basierend auf dem Datenverkehr automatisch bis zu einem konfigurierten Höchstwert hochskaliert.
Der Event Hubs-Trigger in der Funktions-App wird gemäß der Anzahl von Partitionen im Event Hub skaliert. Jeder Partition wird jeweils eine Funktionsinstanz zugewiesen. Zur Erhöhung des Durchsatzes empfangen Sie die Ereignisse nicht einzeln nacheinander, sondern als Batch.
Azure Cosmos DB
Azure Cosmos DB ist in zwei verschiedenen Kapazitätsmodi verfügbar:
- Serverlos, für Workloads mit zeitweiligem oder unvorhersehbarem Datenverkehr und einem geringen Verhältnis zwischen durchschnittlichem und hohem Datenverkehrsaufkommen.
- Bereitgestellter Durchsatz für Workloads mit anhaltendem Datenverkehr, die vorhersagbare Leistung erfordern.
Um sicherzustellen, dass Ihre Workload skalierbar ist, ist es wichtig, beim Erstellen Ihres Azure Cosmos DB-Containers einen geeigneten Partitionsschlüssel auszuwählen. Hier sind einige Merkmale eines gut geeigneten Partitionsschlüssels aufgeführt:
- Der Schlüsselwertbereich ist ausreichend groß.
- Es erfolgt eine gleichmäßige Verteilung von Lese- und Schreibvorgängen pro Schlüsselwert, um eine Überlastung von Schlüsseln zu vermeiden.
- Die maximale Datenmenge, die für einen Schlüsselwert gespeichert wird, übersteigt niemals die maximale Größe der physischen Partition (20 GB).
- Der Partitionsschlüssel für ein Dokument ändert sich nicht. Sie können den Partitionsschlüssel für ein vorhandenes Dokument nicht aktualisieren.
Im Szenario für diese Referenzarchitektur speichert die Funktion genau ein Dokument pro Gerät, das Daten sendet. Die Funktion aktualisiert die Dokumente laufend mit dem aktuellen Gerätestatus, indem ein Upsert-Vorgang verwendet wird. Die Geräte-ID ist ein guter Partitionsschlüssel für dieses Szenario, da Schreibvorgänge gleichmäßig auf die Schlüssel verteilt werden. Außerdem ist die Größe jeder Partition streng begrenzt, weil ein einzelnes Dokument für jeden Schlüsselwert vorhanden ist. Weitere Informationen zu Partitionsschlüsseln finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.
Resilienz
Beim Verwenden des Event Hubs-Triggers mit Functions ist es ratsam, Ausnahmen in Ihrer Verarbeitungsschleife abzufangen. Wenn ein Ausnahmefehler auftritt, führt die Functions-Runtime keinen Wiederholungsversuch für die Nachrichten durch. Wenn eine Nachricht nicht verarbeitet werden kann, sollte sie in eine Warteschlange für unzustellbare Nachrichten eingereiht werden. Verwenden Sie einen Out-of-band-Prozess, um die Nachrichten zu untersuchen und die Korrekturmaßnahmen zu bestimmen.
Mit dem folgenden Code wird veranschaulicht, wie die Erfassungsfunktion Ausnahmen abfängt und nicht verarbeitete Nachrichten in eine Warteschlange für unzustellbare Nachrichten einreiht.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
Mit dem Code werden Ausnahmen auch in Application Insights protokolliert. Sie können den Partitionsschlüssel und die Sequenznummer auch verwenden, um unzustellbare Nachrichten mit den Ausnahmen in den Protokollen zu korrelieren.
Nachrichten in der Warteschlange für unzustellbare Nachrichten sollten über genügend Informationen verfügen, damit Sie den Kontext des Fehlers verstehen können. In diesem Beispiel enthält die Klasse DeadLetterMessage die Ausnahmenachricht, die ursprünglichen Ereignistextdaten und die deserialisierte Ereignisnachricht (falls verfügbar).
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Nutzen Sie Azure Monitor, um den Event Hub zu überwachen. Wenn eine Eingabe vorhanden ist, aber keine Ausgabe, bedeutet dies, dass Nachrichten nicht verarbeitet werden. Navigieren Sie in diesem Fall zu Log Analytics, und suchen Sie nach Ausnahmen oder anderen Fehlern.
DevOps
Verwenden Sie nach Möglichkeit Infrastruktur als Code (Infrastructure as Code, IaC). Mit IaC werden die Infrastruktur, die Anwendung und Speicherressourcen mit einem deklarativen Ansatz wie z. B. Azure Resource Manager verwaltet. Dies hilft bei der Automatisierung der Bereitstellung mithilfe von DevOps als CI/CD-Lösung (Continuous Integration und Continuous Delivery). Vorlagen sollten eine Versionsangabe aufweisen und einen Teil der Releasepipeline darstellen.
Wenn Sie Vorlagen erstellen, gruppieren Sie Ressourcen, um sie pro Workload zu organisieren und zu isolieren. Eine gängige Methode der Berücksichtigung einer Workload ist eine einzelne serverlose Anwendung oder ein virtuelles Netzwerk. Die Workloadisolierung dient dazu, die Ressourcen einem Team zuzuordnen, damit das DevOps-Team alle Aspekte dieser Ressourcen unabhängig verwalten und CI/CD durchführen kann.
Wenn Sie Ihre Dienste bereitstellen, müssen Sie sie überwachen. Sie können Application Insights verwenden, damit Entwickler die Leistung überwachen und Probleme erkennen können.
Notfallwiederherstellung
Die hier dargestellte Bereitstellung befindet sich in nur einer Azure-Region. Nutzen Sie die Features für die geografische Verteilung in den verschiedenen Diensten, um einen stabileren Ansatz für die Notfallwiederherstellung zu erzielen:
Event Hubs. Erstellen Sie zwei Event Hubs-Namespaces: einen primären (aktiven) Namespace und einen sekundären (passiven) Namespace. Nachrichten werden automatisch an den aktiven Namespace weitergeleitet, sofern Sie kein Failover zum sekundären Namespace ausführen. Weitere Informationen finden Sie unter Georedundante Notfallwiederherstellung in Azure Event Hubs.
Funktions-App. Stellen Sie eine zweite Funktions-App bereit, die darauf wartet, vom sekundären Event Hubs-Namespace zu lesen. Mit dieser Funktion werden Daten in ein sekundäres Speicherkonto für die Warteschlange für unzustellbare Nachrichten geschrieben.
Azure Cosmos DB. Azure Cosmos DB unterstützt mehrere Schreibregionen, sodass Schreibvorgänge in alle Regionen möglich sind, die Sie Ihrem Azure Cosmos DB-Konto hinzufügen. Wenn Sie die Funktion für mehrere Schreibvorgänge nicht aktivieren, können Sie trotzdem ein Failover auf die primäre Schreibregion ausführen. Die Azure Cosmos DB-Client-SDKs und die Azure Function-Bindungen verarbeiten das Failover automatisch, sodass Sie keine Einstellungen für die Anwendungskonfiguration aktualisieren müssen.
Azure Storage. Verwenden Sie RA-GRS-Speicher für die Warteschlange für unzustellbare Nachrichten. Hierdurch wird ein schreibgeschütztes Replikat in einer anderen Region erstellt. Wenn die primäre Region ausfällt, können Sie die derzeit in der Warteschlange befindlichen Elemente lesen. Stellen Sie darüber hinaus ein weiteres Speicherkonto in der sekundären Region bereit, in das die Funktion nach einem Failover schreiben kann.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Verwenden Sie den Azure-Preisrechner, um die Kosten zu ermitteln. Hier sind einige weitere Überlegungen für Azure Functions und Azure Cosmos DB.
Azure-Funktionen
Azure Functions unterstützt zwei Hostingmodelle:
- Verbrauchsplan. Computeleistung wird automatisch zugeordnet, wenn Ihr Code ausgeführt wird.
- App Service-Plan. Für Ihren Code wird eine Gruppe mit virtuellen Computern (VMs) zugeordnet. Mit dem App Service-Plan wird die Anzahl von VMs und die VM-Größe definiert.
Bei dieser Architektur lösen alle Ereignisse, die auf Event Hubs eintreffen, eine Funktion aus, die das Ereignis verarbeitet. Aus Kostensicht lautet die Empfehlung, den Verbrauchstarif zu nutzen, da Sie hierbei nur für die verbrauchten Computeressourcen zahlen.
Azure Cosmos DB
Mit Azure Cosmos DB zahlen Sie für die Vorgänge, die Sie für die Datenbank ausführen, und für den von Ihren Daten genutzten Speicher.
- Datenbankvorgänge. Die Art und Weise, wie Ihre Datenbankvorgänge abgerechnet werden, hängt vom Typ des Azure Cosmos DB-Kontos ab, das Sie verwenden.
- Im serverlosen Modus müssen Sie beim Erstellen von Ressourcen in Ihrem Azure Cosmos DB-Konto keinen Durchsatz bereitstellen. Am Ende des Abrechnungszeitraums wird Ihnen die Anzahl der Anforderungseinheiten in Rechnung gestellt, die von den Datenbankvorgängen genutzt wurden.
- Im Modus mit bereitgestelltem Durchsatz geben Sie den benötigten Durchsatz in Anforderungseinheiten pro Sekunde (RU/s) an, und Ihnen wird stündlich der maximal bereitgestellte Durchsatz für eine bestimmte Stunde abgerechnet. Hinweis: Da das Modell mit bereitgestelltem Durchsatz Ressourcen dediziert für Ihren Container oder Ihre Datenbank bereitstellt, wird Ihnen der Durchsatz, den Sie bereitgestellt haben, auch dann in Rechnung gestellt, wenn Sie keine Workloads ausführen.
- Speicher Für die Gesamtmenge des Speichers (in GB), der für Daten und Indizes für eine angegebene Stunde genutzt wird, wird eine Pauschale berechnet.
Bei dieser Referenzarchitektur speichert die Funktion genau ein Dokument pro Gerät, das Daten sendet. Die Funktion aktualisiert die Dokumente fortlaufend mit dem aktuellen Gerätestatus, indem ein upsert-Vorgang verwendet wird. Dies ist in Bezug auf den verbrauchten Speicher kostengünstig. Weitere Informationen finden Sie unter Azure Cosmos DB – Preismodell.
Verwenden Sie den Kapazitätsrechner von Azure Cosmos DB, um eine schnelle Schätzung der Workloadkosten zu erhalten.
Bereitstellen dieses Szenarios
 Eine Referenzimplementierung dieser Architektur ist auf GitHub verfügbar.
Eine Referenzimplementierung dieser Architektur ist auf GitHub verfügbar.
Nächste Schritte
- Einführung in Azure Functions
- Willkommen bei Azure Cosmos DB
- Was ist Azure Queue Storage?
- Azure Monitor – Übersicht
- Dokumentation zu Azure Pipelines