Bereitstellen eines Azure SQL Edge-Containers in Kubernetes
Wichtig
Azure SQL Edge wird am 30. September 2025 eingestellt. Weitere Informationen und Migrationsoptionen finden Sie im Einstellungshinweis.
Hinweis
Azure SQL Edge unterstützt die ARM64-Plattform nicht mehr.
Azure SQL Edge kann in einem Kubernetes-Cluster sowohl über eine auf Kubernetes ausgeführte Azure IoT Edge-Instanz als IoT Edge-Modul als auch als eigenständiger Containerpod bereitgestellt werden. Im restlichen Teil dieses Artikels konzentrieren wir uns auf die eigenständige Containerbereitstellung in einem Kubernetes-Cluster. Weitere Informationen zum Bereitstellen von Azure IoT Edge auf Kubernetes finden Sie unter Deploy Azure IoT Edge on Kubernetes (preview) (Bereitstellen von Azure IOT Edge auf Kubernetes (Vorschau)).
In diesem Tutorial wird veranschaulicht, wie eine hochverfügbare Azure SQL Edge-Instanz in einem Container auf einem Kubernetes-Cluster konfiguriert wird.
- Erstellen eines Systemadministratorkennworts
- Erstellen des Speichers
- Erstellen der Bereitstellung
- Herstellen einer Verbindung mit SSMS (SQL Server Management Studio)
- Überprüfen von Fehlern und der Wiederherstellung
Kubernetes 1.6 und höher unterstützt Speicherklassen, PersistentVolumeClaims und den Volumetyp Azure-Datenträger. Sie können Ihre Azure SQL Edge-Instanzen nativ in Kubernetes erstellen und verwalten. Das in diesem Artikel enthaltene Beispiel veranschaulicht die Erstellung einer Bereitstellung, um eine Hochverfügbarkeitskonfiguration ähnlich einer Failoverclusterinstanz auf einem freigegebenen Datenträger zu erstellen. In dieser Konfiguration spielt Kubernetes die Rolle des Clusterorchestrators. Wenn bei einer Azure SQL Edge-Instanz in einem Container ein Fehler auftritt, startet der Orchestrator eine neue Instanz des Containers, die demselben persistenten Speicher angefügt wird.
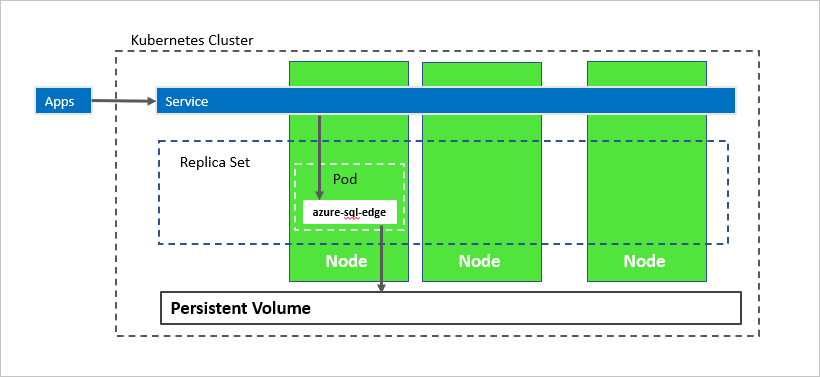
Im obigen Diagramm ist azure-sql-edge ein Container in einem Pod. Kubernetes orchestriert die Ressourcen im Cluster. Eine Replikatgruppe stellt sicher, dass der Pod nach dem Ausfall eines Knotens automatisch wiederhergestellt wird. Anwendungen stellen eine Verbindung zum Dienst her. In diesem Fall stellt der Dienst einen Lastenausgleich dar, der eine IP-Adresse hostet, die sich nach dem Ausfall von azure-sql-edge nicht ändert.
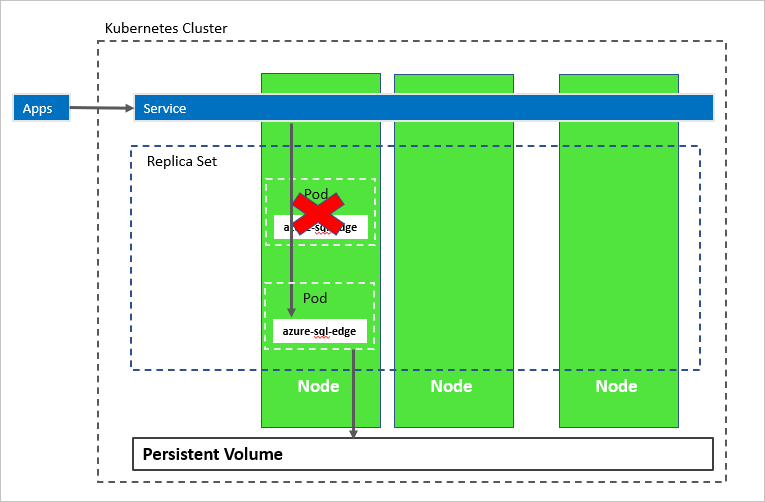
Im folgenden Diagramm ist der azure-sql-edge-Container fehlgeschlagen. Als Orchestrator garantiert Kubernetes die richtige Anzahl fehlerfreier Instanzen in der Replikatgruppe und startet gemäß der Konfiguration einen neuen Container. Der Orchestrator startet einen neuen Pod auf demselben Knoten, und azure-sql-edge stellt erneut eine Verbindung mit demselben persistenten Speicher her. Der Dienst stellt eine Verbindung zur neu erstellen azure-sql-edge-Instanz her.
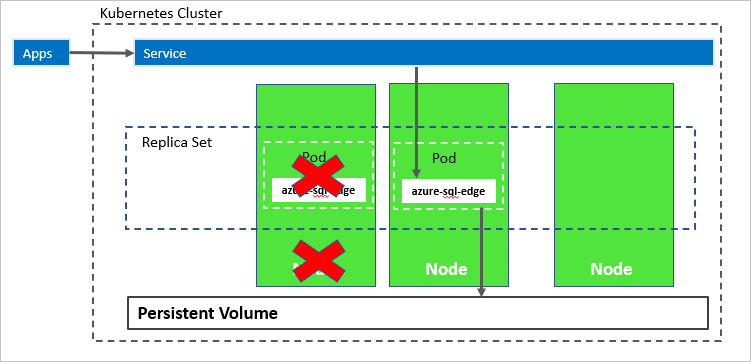
Im folgenden Diagramm ist der Knoten fehlgeschlagen, der den azure-sql-edge-Container hostet. Der Orchestrator startet den neuen Pod auf einem anderen Knoten, und azure-sql-edge stellt erneut eine Verbindung mit demselben persistenten Speicher her. Der Dienst stellt eine Verbindung zur neu erstellen azure-sql-edge-Instanz her.
Voraussetzungen
Kubernetes-Cluster
Für das Tutorial ist ein Kubernetes-Cluster erforderlich. In den Schritten wird kubectl zum Verwalten des Clusters verwendet.
Im Rahmen dieses Tutorials verwenden wir Azure Kubernetes Service zum Bereitstellen von Azure SQL Edge. Unter Bereitstellen eines Azure Kubernetes Service-Clusters (AKS) erfahren Sie, wie Sie einen Kubernetes-Cluster mit einem einzelnen Knoten mithilfe von
kubectlin AKS erstellen und eine Verbindung mit diesem herstellen.
Hinweis
Ein Kubernetes-Cluster benötigt mehrere Knoten zum Schutz vor Knotenausfällen.
Azure-Befehlszeilenschnittstelle
- Die Anweisungen in diesem Tutorial wurden für die Azure CLI 2.10.1 überprüft.
Erstellen eines Kubernetes-Namespace für die SQL Edge-Bereitstellung
Erstellen Sie im Kubernetes-Cluster einen neuen Namespace. Dieser Namespace wird verwendet, um SQL Edge und alle erforderlichen Artefakte bereitzustellen. Weitere Informationen zu Kubernetes-Namespaces finden Sie unter Namespaces.
kubectl create namespace <namespace name>
Erstellen eines Systemadministratorkennworts
Erstellen Sie ein Systemadministratorkennwort im Kubernetes-Cluster. Kubernetes kann vertrauliche Konfigurationsinformationen wie Kennwörter als Geheimnisse verwalten.
Mit dem folgenden Befehl wird ein Kennwort für das Systemadministratorkonto erstellt:
kubectl create secret generic mssql --from-literal=MSQL_SA_PASSWORD="<password>" -n <namespace name>
Ersetzen Sie MyC0m9l&xP@ssw0rd durch ein komplexes Kennwort.
Erstellen des Speichers
Konfigurieren Sie ein persistentes Volume und einen Anspruch auf ein persistentes Volume im Kubernetes-Cluster. Führen Sie die folgenden Schritte aus:
Erstellen Sie ein Manifest, um die Speicherklasse und den Anspruch auf ein persistentes Volume zu definieren. Mit dem Manifest werden der Speicheranbieter, die Parameter und die reclaim policy (Rückforderungsrichtlinie) festgelegt. Der Kubernetes-Cluster verwendet dieses Manifest, um den persistenten Speicher zu erstellen.
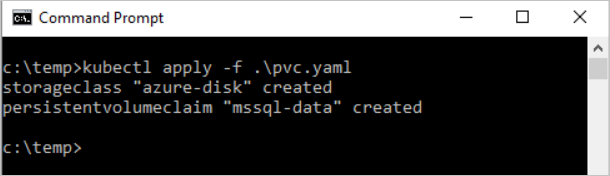
Im folgenden YAML-Beispiel werden eine Speicherklasse und ein Anspruch auf persistente Volumes definiert. Der Speicherklassenanbieter lautet
azure-disk, weil sich dieser Kubernetes-Cluster in Azure befindet. Der Speicherkontotyp lautetStandard_LRS. Der Anspruch auf persistente Volumes heißtmssql-data. Die Metadaten des Anspruchs auf persistente Volumes enthalten eine Anmerkung, durch die sie auf die Speicherklasse zurückgeführt werden können.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azure-disk provisioner: kubernetes.io/azure-disk parameters: storageaccounttype: Standard_LRS kind: managed --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: mssql-data annotations: volume.beta.kubernetes.io/storage-class: azure-disk spec: accessModes: - ReadWriteOnce resources: requests: storage: 8GiSpeichern Sie die Datei (z. B. pvc.yaml).
Erstellen Sie einen Anspruch auf ein permanentes Volume in Kubernetes.
kubectl apply -f <Path to pvc.yaml file> -n <namespace name><Path to pvc.yaml file>entspricht dem Speicherort, an dem Sie die Datei gespeichert haben.Das persistente Volume wird automatisch als Azure-Speicherkonto erstellt und an den Anspruch auf ein persistentes Volume gebunden.
Überprüfen Sie den Anspruch auf persistente Volumes.
kubectl describe pvc <PersistentVolumeClaim> -n <name of the namespace><PersistentVolumeClaim>ist der Name des Anspruchs auf persistente Volumes.Im vorherigen Schritt wurde der Anspruch auf persistente Volumes
mssql-datagenannt. Führen Sie den folgenden Befehl aus, um die Metadaten über den Anspruch auf permanente Volumes anzuzeigen:kubectl describe pvc mssql-data -n <namespace name>Die zurückgegebenen Metadaten enthalten einen Wert namens
Volume. Dieser Wert wird dem Namen des Blobs zugeordnet.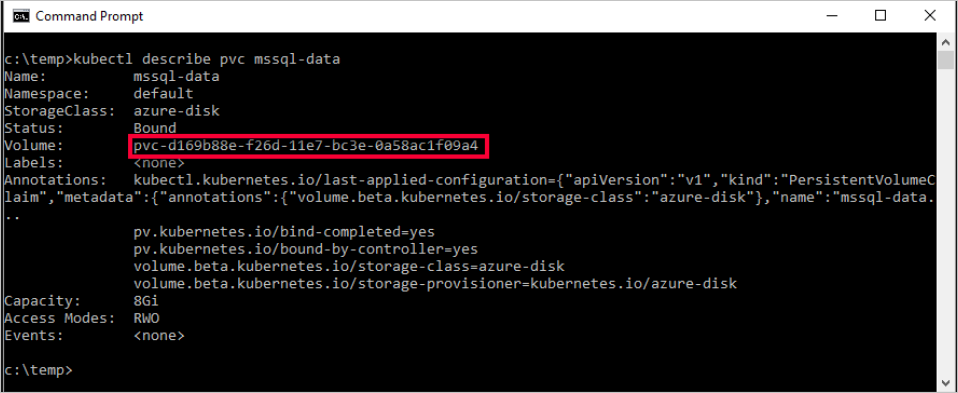
Überprüfen Sie das persistente Volume.
kubectl describe pv -n <namespace name>kubectlgibt Metadaten zum persistenten Volume zurück, die automatisch generiert und an den Anspruch für das persistente Volume gebunden wurden.
Erstellen der Bereitstellung
In diesem Beispiel wird der Container, der die Azure SQL Edge-Instanz hostet, als Kubernetes-Bereitstellungsobjekt bezeichnet. Die Bereitstellung erstellt eine Replikatgruppe. Die Replikatgruppe erstellt einen Pod.
In diesem Schritt erstellen Sie ein Manifest, um den Container zu beschreiben, der auf dem Azure SQL Edge Docker-Image basiert. Das Manifest referenziert den mssql-data-Anspruch auf das persistente Volume und das mssql-Geheimnis, das Sie bereits auf den Kubernetes-Cluster angewendet haben. Das Manifest beschreibt außerdem einen Dienst. Bei diesem Dienst handelt es sich um einen Lastenausgleich. Der Lastenausgleich garantiert, dass die IP-Adresse beibehalten wird, nachdem die Azure SQL Server-Instanz wiederhergestellt wurde.
Erstellen Sie ein Manifest (eine YAML-Datei), um die Bereitstellung zu beschreiben. Im folgenden Beispiel wird eine Bereitstellung beschrieben, die einen Container enthält, der auf dem Azure SQL Edge-Containerimage basiert.
apiVersion: apps/v1 kind: Deployment metadata: name: sqledge-deployment spec: replicas: 1 selector: matchLabels: app: sqledge template: metadata: labels: app: sqledge spec: volumes: - name: sqldata persistentVolumeClaim: claimName: mssql-data containers: - name: azuresqledge image: mcr.microsoft.com/azure-sql-edge:latest ports: - containerPort: 1433 volumeMounts: - name: sqldata mountPath: /var/opt/mssql env: - name: MSSQL_PID value: "Developer" - name: ACCEPT_EULA value: "Y" - name: MSSQL_SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: MSSQL_SA_PASSWORD - name: MSSQL_AGENT_ENABLED value: "TRUE" - name: MSSQL_COLLATION value: "SQL_Latin1_General_CP1_CI_AS" - name: MSSQL_LCID value: "1033" terminationGracePeriodSeconds: 30 securityContext: fsGroup: 10001 --- apiVersion: v1 kind: Service metadata: name: sqledge-deployment spec: selector: app: sqledge ports: - protocol: TCP port: 1433 targetPort: 1433 name: sql type: LoadBalancerKopieren Sie den obigen Code in eine neue Datei namens
sqldeployment.yaml. Ändern Sie die folgenden Werte:MSSQL_PID
value: "Developer": Hiermit wird festgelegt, dass der Container die Azure SQL Edge Developer-Edition ausführt. Die Developer-Edition ist nicht für Produktionsdaten lizenziert. Wenn die Bereitstellung für die Produktion vorgesehen ist, legen Sie die Edition aufPremiumfest.Hinweis
Weitere Informationen finden Sie unter Azure SQL Edge – Preise.
persistentVolumeClaim: Dieser Wert erfordert einen Eintrag fürclaimName:, der den verwendeten Namen dem Anspruch für das persistente Volume zuordnet. In diesem Tutorial wirdmssql-dataverwendet.name: MSSQL_SA_PASSWORD: Konfiguriert das Containerimage, um das Systemadministratorkennwort wie in diesem Abschnitt beschrieben festzulegen.valueFrom: secretKeyRef: name: mssql key: MSSQL_SA_PASSWORDWenn Kubernetes den Container bereitstellt, verweist auf das Geheimnis namens
mssql, um den Wert für das Kennwort abzurufen.
Hinweis
Mithilfe des Diensttyps
LoadBalancerwird der Remotezugriff auf die Azure SQL Edge-Instanz (über das Internet) über Port 1433 ermöglicht.Speichern Sie die Datei (z. B.
sqledgedeploy.yaml).Erstellen Sie die Bereitstellung.
kubectl apply -f <Path to sqledgedeploy.yaml file> -n <namespace name><Path to sqldeployment.yaml file>entspricht dem Speicherort, an dem Sie die Datei gespeichert haben.
Die Bereitstellung und der Dienst werden erstellt. Die Azure SQL Edge-Instanz befindet sich in einem Container, der mit dem persistenten Speicher verbunden ist.
Geben Sie
kubectl get pod -n <namespace name>ein, um den Status des Pods anzuzeigen.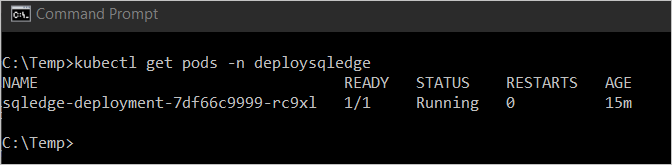
In der vorangehenden Abbildung weist der Pod den Status
Runningauf. Dieser Status gibt an, dass der Container bereit ist. Dieser Vorgang kann einige Minuten dauern.Hinweis
Nachdem die Bereitstellung erstellt wurde, kann es einige Minuten dauern, bis der Pod sichtbar ist. Die Verzögerung liegt daran, dass der Cluster das Azure SQL Edge-Containerimage aus dem Docker-Hub abruft. Nachdem das Image zum ersten Mal per Pull abgerufen wurde, können nachfolgende Bereitstellungen schneller sein, wenn die Bereitstellung einen Knoten nutzt, auf dem bereits ein Image zwischengespeichert wurde.
Überprüfen Sie, ob die Dienste ausgeführt werden. Führen Sie den folgenden Befehl aus:
kubectl get services -n <namespace name>Dieser Befehl gibt alle Dienste, die ausgeführt werden, und die internen sowie externen IP-Adressen der Dienste zurück. Beachten Sie die externe IP-Adresse für den
mssql-deployment-Dienst. Verwenden Sie diese IP-Adresse, um eine Verbindung mit Azure SQL Edge herzustellen.
Führen Sie den folgenden Befehl aus, um weitere Informationen zum Status der Objekte im Kubernetes-Cluster zu erhalten:
az aks browse --resource-group <MyResourceGroup> --name <MyKubernetesClustername>
Sie stellen eine Verbindung mit der Azure SQL Edge-Instanz her.
Wenn Sie den Container gemäß der Beschreibung konfiguriert haben, können Sie eine Verbindung mit einer Anwendung außerhalb des virtuellen Azure-Netzwerks herstellen. Verwenden Sie das sa-Konto und die externe IP-Adresse für den Dienst. Verwenden Sie das Kennwort, das Sie als Kubernetes-Geheimnis konfiguriert haben. Weitere Informationen über das Herstellen einer Verbindung mit einer Azure SQL Edge-Instanz finden Sie unter Herstellen einer Verbindung mit und Abfragen von Azure SQL Edge (Vorschau).
Überprüfen von Fehlern und der Wiederherstellung
Sie können den Pod löschen, um die Fehler und Wiederherstellung zu überprüfen. Führen Sie die folgenden Schritte aus:
Listen Sie den Pod auf, auf dem Azure SQL Edge ausgeführt wird.
kubectl get pods -n <namespace name>Notieren Sie sich den Namen des Pods, der Azure SQL Edge ausführt.
Löschen Sie den Pod.
kubectl delete pod sqledge-deployment-7df66c9999-rc9xlsqledge-deployment-7df66c9999-rc9xlist der Wert, der im vorherigen Schritt als Name des Pods zurückgegeben wurde.
Kubernetes erstellt den Pod automatisch neu, um die Azure SQL Edge-Instanz wiederherzustellen und eine Verbindung mit dem beständigen Speicher herzustellen. Verwenden Sie kubectl get pods, um zu überprüfen, dass ein neuer Pod bereitgestellt wurde. Verwenden Sie kubectl get services, um zu überprüfen, ob die IP-Adresse für den neuen Container gleich ist.
Zusammenfassung
In diesem Tutorial haben Sie gelernt, wie Sie Azure SQL Edge-Container in einem Kubernetes-Cluster für Hochverfügbarkeit bereitstellen.
- Erstellen eines Systemadministratorkennworts
- Erstellen des Speichers
- Erstellen der Bereitstellung
- Herstellen einer Verbindung mit Azure SQL Edge Management Studios (SSMS)
- Überprüfen von Fehlern und der Wiederherstellung