Pools für elastische Datenbanken als Hilfe beim Verwalten und Skalieren vieler Datenbanken in Azure SQL-Datenbank
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Pools für elastische Azure SQL-Datenbank-Instanzen sind eine einfache, kostengünstige Lösung zum Verwalten und Skalieren einer großen Zahl von Datenbanken mit variierenden und unvorhersehbaren Nutzungsanforderungen. Die Datenbanken in einem Pool für elastische Datenbanken befinden sich auf einem einzelnen Server und nutzen gemeinsam eine festgelegte Anzahl von Ressourcen zu einem festen Preis. Mithilfe von Pools für elastische Datenbanken in SQL-Datenbank kann bei der SaaS-Entwicklung (Software-as-a-Service) das Preis-Leistungs-Verhältnis für eine Gruppe von Datenbanken im Rahmen eines vorgegebenen Budgets optimiert und gleichzeitig eine flexible Leistung für jede Datenbank sichergestellt werden.
Was sind Pools für elastische SQL-Datenbanken?
Bei der SaaS-Entwicklung werden Anwendungen erstellt, die auf der obersten von umfangreichen Datenschichten aufsetzen, die wiederum aus zahlreichen Datenbanken bestehen können. Ein typisches Anwendungsmuster ist die Bereitstellung einer einzigen Datenbank für jeden Kunden. Verschiedene Kunden haben jedoch häufig unterschiedliche und unvorhersehbare Nutzungsmuster, und es ist schwierig, den Ressourcenbedarf jedes Datenbankbenutzers vorherzusagen. Bisher hatten Sie zwei Optionen:
- Überprovisionierung von Ressourcen auf der Grundlage von Nutzungsspitzen und Überbezahlung.
- Unterdimensionierte Bereitstellung zum Einsparen von Kosten, zu Lasten von Leistung und Kundenzufriedenheit während der Spitzenzeiten.
Pools für elastische Datenbanken lösen dieses Problem, indem sie sicherstellen, dass die Datenbanken die Leistungsressourcen erhalten, die sie benötigen, und zwar genau zu dem Zeitpunkt, zu dem sie sie benötigen. Sie stellen einen einfachen Ressourcenzuordnungsmechanismus innerhalb eines vorhersagbaren Budgets bereit. Weitere Informationen zu Entwurfsmustern für SaaS-Anwendungen mit Pools für elastische Datenbanken finden Sie unter Entwurfsmuster für mehrinstanzenfähige SaaS-Anwendungen mit SQL-Datenbank.
Wichtig
Bei Pools für elastische Datenbanken erfolgt keine Abrechnung pro Datenbank. Die Abrechnung erfolgt pro Stunde, die ein Pool mit dem höchsten eDTU- oder vCore-Wert vorhanden ist, unabhängig von der Nutzung oder davon, ob der Pool für weniger als eine Stunde aktiv war.
Mit Pools für elastische Datenbanken können Sie Ressourcen für einen Pool erwerben, der von mehreren Datenbanken gemeinsam genutzt wird, um unvorhersehbare Auslastungsspitzen einzelner Datenbanken abzufedern. Sie können Ressourcen für den Pool entweder basierend auf dem DTU-basierten Kaufmodell oder dem vCore-basierten Kaufmodell konfigurieren. Die Ressourcenanforderungen eines Pools werden anhand der aggregierten Nutzung der hierin befindlichen Datenbanken ermittelt.
Die Anzahl der für den Pool verfügbaren Ressourcen wird über Ihr Budget gesteuert. Sie müssen lediglich folgende Aufgaben ausführen:
- Fügen Sie dem Pool Datenbanken hinzu.
- Legen Sie optional die minimalen und maximalen Ressourcen für die Datenbanken fest, und zwar im Kaufmodell für DTU oder für virtuelle Kerne.
- Legen Sie die Ressourcen des Pools basierend auf Ihrem Budget fest.
Sie können Pools nutzen, um Ihren Dienst nahtlos von einem kleinen Startup zu einem etablierten Unternehmen mit immer größerem Umfang auszubauen.
Innerhalb des Pools können die einzelnen Datenbanken die Ressourcen innerhalb der festgelegten Parameter flexibel nutzen. Bei hoher Auslastung kann eine Datenbank mehr Ressourcen nutzen, um die Anforderungen zu erfüllen. Datenbanken verbrauchen bei geringerer Auslastung weniger Ressourcen und ohne Auslastung gar keine Ressourcen. Durch die Bereitstellung von Ressourcen für den gesamten Pool und nicht nur für einzelne Datenbanken vereinfachen Sie Ihre Verwaltungsaufgaben. Außerdem verfügen Sie über ein vorhersagbares Budget für den Pool.
Einem vorhandenen Pool können – mit minimaler Downtime – zusätzliche Ressourcen hinzugefügt werden. Falls die zusätzlichen Ressourcen nicht mehr benötigt werden, können sie jederzeit aus einem vorhandenen Pool entfernt werden. Darüber hinaus können Sie Datenbanken zum Pool hinzufügen oder daraus entfernen. Wenn absehbar ist, dass eine Datenbank zu wenig Ressourcen beansprucht, können Sie sie auslagern.
Hinweis
Beim Verschieben von Datenbanken in einen oder aus einem Pool für elastische Datenbanken gibt es keine Ausfallzeiten – abgesehen von einem kurzen Zeitraum (in der Größenordnung von Sekunden) am Ende des Vorgangs, wenn die Datenbankverbindungen getrennt werden.
Wann sollte ein Pool für elastische SQL-Datenbank-Instanzen in Betracht gezogen werden?
Pools eignen sich hervorragend für eine große Anzahl an Datenbanken mit bestimmten Nutzungsmustern. Für eine einzelne Datenbank ist dieses Muster durch eine niedrige durchschnittliche Nutzung mit seltenen Nutzungsspitzen gekennzeichnet. Im Gegensatz dazu sollten mehrere Datenbanken mit dauerhafter mittlerer Auslastung nicht demselben Pool für elastische Datenbanken hinzugefügt werden.
Je mehr Datenbanken Sie einem Pool hinzufügen können, desto mehr sparen Sie. Abhängig vom Auslastungsmuster Ihrer Anwendung können Sie bereits mit nur zwei S3-Datenbanken Ersparnisse erzielen.
Die folgenden Abschnitte helfen Ihnen einzuschätzen, ob Ihre Datenbanksammlung von einem Pool profitieren kann. In den Beispielen werden Pools der Dienstebene „Standard“ verwendet, dieselben Prinzipien gelten aber auch für Pools für elastische Datenbanken auf anderen Dienstebenen.
Bewerten von Datenbanknutzungsmustern
Die folgende Abbildung zeigt ein Beispiel für eine Datenbank, die sich zwar die meiste Zeit im Leerlauf befindet, aber auch regelmäßig Aktivitätsspitzen aufweist. Dieses Auslastungsmuster eignet sich für einen Pool.
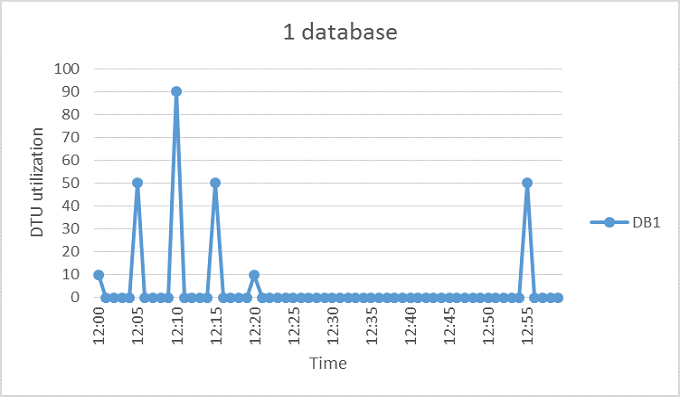
Das Diagramm veranschaulicht die DTU-Nutzung über einen Zeitraum von einer Stunde zwischen 12:00 und 13:00 Uhr, wobei jeder Datenpunkt eine Granularität von einer Minute aufweist. DB1 erreicht um 12:10 Uhr den Spitzenwert von 90 DTUs, die mittlere Auslastung liegt jedoch bei unter fünf DTUs. Zum Ausführen dieser Workload in einer einzelnen Datenbank wird die Computegröße S3 benötigt. Allerdings führt diese Größe dazu, dass die meisten Ressourcen in Zeiten geringer Aktivität nicht genutzt werden.
Mit einem Pool können diese nicht verwendeten DTUs für mehrere Datenbanken freigegeben werden. Ein Pool verringert die benötigten DTUs und senkt die Gesamtkosten.
Ausgehend vom vorherigen Beispiel nehmen wir an, dass weitere Datenbanken ein ähnliches Nutzungsmuster wie DB1 haben. In den beiden folgenden Abbildungen wird die Auslastung von 4 und von weiteren 20 Datenbanken überlagert in einem Diagramm dargestellt. Damit wird veranschaulicht, dass es bei Verwendung des DTU-basierten Kaufmodells im Lauf der Zeit keine Überschneidungen hinsichtlich ihrer Nutzung gibt:
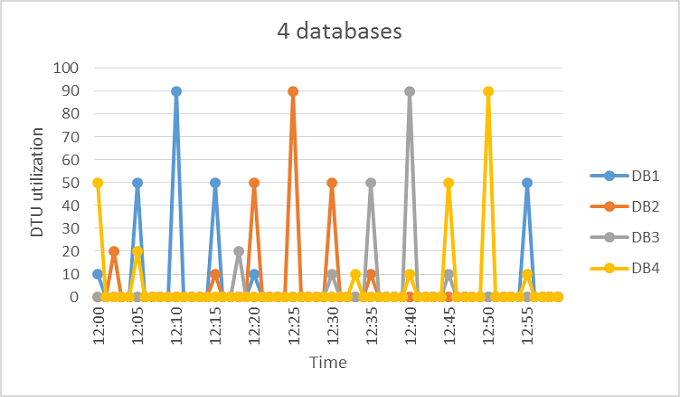
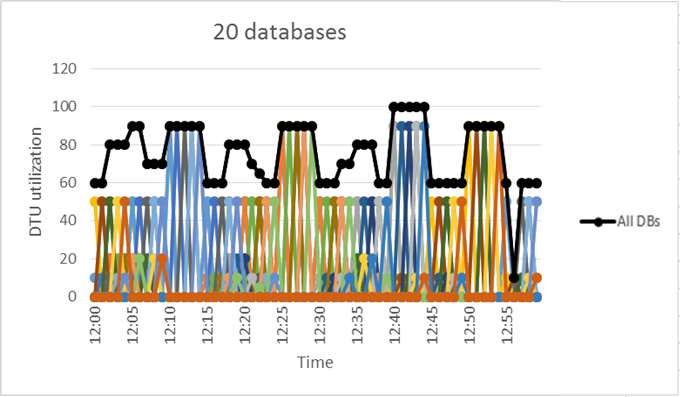
Die schwarze Linie im vorstehenden Diagramm stellt die aggregierte DTU-Nutzung aller 20 Datenbanken dar. Sie zeigt, dass die aggregierte DTU-Nutzung niemals 100 DTUs übersteigt und dass sich die 20 Datenbanken in diesem Zeitraum 100 eDTUs teilen können. Das Ergebnis ist eine 20-fache Verringerung der DTU-Anzahl und eine 13-fache Preisreduzierung gegenüber einer Bereitstellung jeder Datenbank mit Computegröße S3 für Einzeldatenbanken.
Dieses Beispiel ist aus folgenden Gründen ideal geeignet:
- Es gibt große Unterschiede zwischen der Spitzenauslastung und der mittleren Auslastung pro Datenbank.
- Die Spitzenauslastung jeder Datenbank ergibt sich zu jeweils unterschiedlichen Zeitpunkten.
- eDTUs werden von mehreren Datenbanken gemeinsam genutzt.
Im DTU-basierten Kaufmodell ergibt sich der Preis eines Pools aus den eDTUs des Pools. Der eDTU-Einheitspreis für einen Pool ist zwar 1,5-mal höher als der DTU-Einheitspreis für eine einzelne Datenbank, aber die eDTUs eines Pools können von vielen Datenbanken gemeinsam genutzt werden, sodass insgesamt weniger eDTUs benötigt werden. Die Unterschiede bei der Preisgestaltung und die gemeinsame Nutzung von eDTUs sind die Basis des Einsparungspotenzials, das von Pools geboten wird.
Beim vCore-basierten Kaufmodell ist der Preis für Pools für elastische Datenbanken mit dem Einheitenpreis für virtuelle Kerne für die einzelnen Datenbanken identisch.
Wie wähle ich die richtige Poolgröße?
Die optimale Größe eines Pools hängt von den zusammengefassten Ressourcen ab, die für alle Datenbanken im Pool benötigt werden. Sie müssen Folgendes festlegen:
- Maximale Computeressourcen, die von allen Datenbanken im Pool verwendet werden. Computeressourcen werden je nach Kaufmodell entweder anhand der eDTUs oder der virtuellen Kerne indiziert.
- Maximale Speicherbytes, die von allen Datenbanken im Pool verwendet werden.
Weitere Informationen zu den Dienstebenen und Ressourcengrenzwerten für jedes Kaufmodell finden Sie unter DTU-basiertes Kaufmodell bzw. vCore-basiertes Kaufmodell.
Die folgenden Schritte können Ihnen dabei helfen, einzuschätzen, ob ein Pool kostengünstiger als einzelne Datenbanken ist:
Schätzen Sie die für den Pool benötigte Anzahl von eDTUs oder virtuellen Kernen:
- Für das DTU-basierte Kaufmodell:
- MAX(<<Gesamtanzahl von Datenbanken × durchschnittliche DTU-Auslastung pro Datenbank>, <
× DTU-Spitzenauslastung pro Datenbank>>)
- MAX(<<Gesamtanzahl von Datenbanken × durchschnittliche DTU-Auslastung pro Datenbank>, <
- Für das auf virtuellen Kernen basierende Kaufmodell:
- MAX(<<Gesamtanzahl von Datenbanken × durchschnittliche vCore-Auslastung pro Datenbank>, <
× vCore-Spitzenauslastung pro Datenbank>>)
- MAX(<<Gesamtanzahl von Datenbanken × durchschnittliche vCore-Auslastung pro Datenbank>, <
- Für das DTU-basierte Kaufmodell:
Schätzen Sie den für den Pool benötigten Gesamtspeicherplatz, indem Sie das erforderliche Datenvolumen für alle Datenbanken im Pool addieren. Ermitteln Sie für das DTU-basierte Kaufmodell die eDTU-Poolgröße, die diese Menge an Speicher bietet.
Verwenden Sie für das DTU-basierte Kaufmodell die größere der eDTU-Schätzungen aus Schritt 1 und Schritt 2.
- Verwenden Sie für das vCore-basierte Kaufmodell die Schätzung für virtuelle Kerne aus Schritt 1.
Informationen finden Sie auf der Preisseite für SQL-Datenbank.
- Suchen Sie die kleinste Poolgröße, die größer ist als die Schätzung aus Schritt 3.
Vergleichen Sie den Poolpreis aus Schritt 4 mit dem Preis der geeigneten Computegrößen für Einzeldatenbanken.
Wichtig
Wenn sich die Anzahl von Datenbanken in einem Pool dem unterstützten Maximalwert nähert, erhalten Sie unter Ressourcenverwaltung in umfangreichen Pools für elastische Datenbanken Informationen über das mögliche weitere Vorgehen.
Datenbankspezifische Eigenschaften
Legen Sie optional Eigenschaften pro Datenbank fest, um Ressourcenverbrauchsmuster in Pools für elastische Datenbanken zu ändern. Weitere Informationen finden Sie in der Dokumentation zu Ressourcenlimits für DTUs und virtuelle Kerne in Pools für elastische Datenbanken.
Verwenden weiterer SQL Datenbank-Funktionen mit Pools für elastische Datenbanken
Sie können weitere SQL Datenbank-Funktionen für Pools für elastische Datenbanken verwenden.
Elastische Aufträge und Pools für elastische Datenbanken
Mit einem Pool werden die Verwaltungsaufgaben vereinfacht, indem Skripts in elastischen Aufträgen ausgeführt werden. Durch einen elastischen Auftrag entfallen die meisten aufwändigen Schritte, die bei der Verwendung einer großen Anzahl von Datenbanken anfallen.
Weitere Informationen zu anderen Datenbanktools für die Arbeit mit mehreren Datenbanken finden Sie unter Horizontales Hochskalieren mit Azure SQL-Datenbank.
Pools für elastische Hyperscale-Datenbanken
Azure SQL-Datenbank-Hyperscale-Pools für elastische Datenbanken sind allgemein verfügbar.
Optionen für Geschäftskontinuität für Datenbanken in einem Pool für elastische Datenbanken
Pooldatenbanken unterstützen in der Regel die gleichen Geschäftskontinuitätsfeatures, die auch für Einzeldatenbanken zur Verfügung stehen:
- Point-in-Time-Wiederherstellung: Bei der Point-in-Time-Wiederherstellung werden automatische Datenbanksicherungen verwendet, um den Status einer Datenbank in einem Pool zu einem bestimmten Zeitpunkt wiederherzustellen. Siehe Wiederherstellung bis zu einem bestimmten Zeitpunkt.
- Geografische Wiederherstellung: Die geografische Wiederherstellung ist die Standardoption für die Wiederherstellung, wenn eine Datenbank aufgrund eines Vorfalls in der Region, in der die Datenbank gehostet wird, nicht verfügbar ist. Siehe Geowiederherstellung.
- Aktive Georeplikation: Für Anwendungen mit höheren Wiederherstellungsanforderungen, die mit der Geowiederherstellung nicht erfüllt werden können, konfigurieren Sie die aktive Georeplikation oder eine Failovergruppe.
Weitere Informationen zu den oben genannten Strategien finden Sie unter Wiederherstellen einer Azure SQL-Datenbank oder Ausführen eines Failovers auf eine sekundäre Datenbank.
Erstellen eines neuen Pools für elastische SQL-Datenbank-Instanzen über das Azure-Portal
Es gibt im Azure-Portal zwei Möglichkeiten, einen Pool für elastische Datenbanken zu erstellen:
- Erstellen eines Pools für elastische Datenbanken und Auswählen eines vorhandenen oder neuen Servers.
- Erstellen eines Pools für elastische Datenbanken auf einem vorhandenen Server.
So erstellen Sie einen Pool für elastische Datenbanken und wählen einen vorhandenen oder neuen Server aus:
Navigieren Sie zum Azure-Portal, um einen Pool für elastische Datenbanken zu erstellen. Suchen Sie nach Azure SQL, und wählen Sie die entsprechende Option aus.
Wählen Sie Erstellen aus, um den Bereich SQL-Bereitstellungsoption auswählen zu öffnen. Wählen Sie auf der Kachel Datenbanken die Option Details anzeigen aus, um weitere Informationen zu Pools für elastische Datenbanken anzuzeigen.
Wählen Sie auf der Kachel Datenbanken in der Dropdownliste Ressourcentyp die Option Pool für elastische Datenbanken aus. Klicken Sie anschließend auf Erstellen.

Verwalten Sie dann Ihren Pool für Pool für elastische Datenbanken über die Azure-Portal, PowerShell, Azure CLI, REST-API oder T-SQL.

So erstellen Sie einen Pool für elastische Datenbanken auf einem vorhandenen Server:
Navigieren Sie zu einem vorhandenen Server, und wählen Sie Neuer Pool aus, um einen Pool direkt auf diesem Server zu erstellen.
Hinweis
Auf einem Server können mehrere Pools erstellt werden, es ist jedoch nicht möglich, Datenbanken von verschiedenen Servern im gleichen Pool zusammenzufassen.
Die Dienstebene des Pools bestimmt die Features für die elastischen Datenbanken im Pool sowie die für jede Datenbank verfügbare maximale Menge der Ressourcen. Weitere Informationen finden Sie in den Ressourceneinschränkungen für Pools für elastische Datenbanken im DTU-Modell. Informationen zu V-Kern-basierte Ressourceneinschränkungen für Pools für elastische Datenbanken finden Sie unter V-Kern-basierte Ressourceneinschränkungen – Pools für elastische Datenbanken.
Zum Konfigurieren der Ressourcen und des Preismodells für den Pool klicken Sie auf Pool konfigurieren. Wählen Sie dann eine Dienstebene aus, fügen Sie den Pool Datenbanken hinzu, und konfigurieren Sie die Ressourceneinschränkungen für den Pool und seine Datenbanken.
Nachdem Sie den Pool konfiguriert haben, wählen Sie Übernehmen aus, benennen Sie den Pool, und klicken Sie auf OK, um den Pool zu erstellen.
Verwalten Sie dann Ihren Pool für Pool für elastische Datenbanken über die Azure-Portal, PowerShell, Azure CLI, REST-API oder T-SQL.
Überwachen eines Pools für elastische Datenbanken und der zugehörigen Datenbanken
Im Azure-Portal können Sie die Verwendung eines Pools für elastische Datenbanken sowie der darin enthaltenen Datenbanken überwachen. Außerdem können Sie einen Änderungssatz für Ihren Pool für elastische Datenbanken erstellen und alle Änderungen gleichzeitig übermitteln. So können Sie etwa Datenbanken hinzufügen oder entfernen, die Einstellungen des Pools für elastische Datenbanken ändern oder Ihre Datenbankeinstellungen anpassen.
Sie können die integrierte Leistungsüberwachung und die Warnungstools in Kombination mit den Leistungsbewertungen verwenden. Darüber hinaus kann SQL-Datenbank zur einfacheren Überwachung Metriken und Ressourcenprotokolle ausgeben.
Fallstudien
- SnelStart: SnelStart war durch die Nutzung von Pools für elastische Datenbanken mit SQL-Datenbank in der Lage, seine Geschäftsdienste mit einer Rate von 1.000 neuen SQL-Datenbanken pro Monat zügig zu erweitern.
- Umbraco: Umbraco verwendet Pools für elastische Datenbanken mit SQL-Datenbank, um in der Cloud schnell Dienste für Tausende von Mandanten bereitzustellen und zu skalieren.
- Daxko/CSI: Daxko/CSI verwendet Pools für elastische Datenbanken mit SQL-Datenbank, um den Entwicklungszyklus zu beschleunigen und sowohl Kundendienste als auch Leistung zu verbessern.
Zugehöriger Inhalt
- Preisinformationen finden Sie unter Pool für elastische Datenbanken – Preise.
- Informationen zum Skalieren von Pools für elastische Datenbanken finden Sie unter Skalieren von Pools für elastische Datenbanken und Skalieren eines Pools für elastische Datenbanken – Beispielcode.
- So verwalten Sie Pools für elastische Datenbanken in Azure SQL-Datenbank
- Weitere Informationen zu Entwurfsmustern für SaaS-Anwendungen mit Verwendung von Pools für elastische Datenbanken finden Sie unter Entwurfsmuster für mehrinstanzenfähige SaaS-Anwendungen mit SQL-Datenbank.
- Ein SaaS-Tutorial, in dem Pools für elastische Datenbanken verwendet werden, finden Sie in der Einführung in die SaaS-Anwendung Wingtip.
- Weitere Informationen zur Ressourcenverwaltung in Pools für elastische Datenbanken, die viele Datenbanken umfassen, finden Sie unter Ressourcenverwaltung in umfangreichen Pools für elastische Datenbanken.
- Weitere Informationen finden Sie unter Pools für elastische Hyperscale-Datenbanken.