Aufskalierung mit Azure SQL-Datenbank
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Mithilfe der Tools für elastische Datenbanken können Sie Datenbanken in Azure SQL-Datenbank problemlos aufskalieren. Mit diesen Tools und Features können Sie Datenbankressourcen von Azure SQL-Datenbank zum Erstellen von Lösungen für transaktionale Workloads und insbesondere SaaS-Anwendungen (Software-as-a-Service) verwenden. Die Features für elastische Datenbanken umfassen folgende:
- Clientbibliothek für elastische Datenbanken: Die Clientbibliothek ist ein Feature, mit dem Sie Sharddatenbanken erstellen und verwalten können. Weitere Informationen finden Sie unter Erste Schritte mit Tools für elastische Datenbanken.
- Verschieben von Daten zwischen skalierten Clouddatenbanken: Verschiebt Daten zwischen horizontal partitionierten Datenbanken. Dieses Tool ist nützlich zum Verschieben von Daten aus einer mehrinstanzenfähigen Datenbank in eine Datenbank mit einzelnem Mandanten (oder umgekehrt). Siehe Bereitstellen eines Split-Merge-Diensts, um Daten zwischen Sharddatenbanken zu verschieben.
- Elastische Aufträge für Azure SQL-Datenbank: Verwalten Sie eine große Anzahl von Datenbanken in Azure SQL-Datenbank mithilfe von Aufträgen. Führen Sie mithilfe von Aufträgen ganz einfach administrative Vorgänge aus, z.B. Schemaänderungen, die Verwaltung von Anmeldeinformationen, Verweisdatenupdates, die Leistungsdatensammlung oder die Mandanten(Kunden)-Telemetrieerfassung.
- Azure SQL-Datenbank Übersicht über die Abfrage für elastische Datenbanken (Vorschau): Mit diesem Feature können Sie eine Transact-SQL-Abfrage über mehrere Datenbanken hinweg ausführen. Dies ermöglicht eine Verknüpfung mit Berichtstools wie Excel, Power BI, Tableau usw.
- Verteilte Transaktionen über Cloud-Datenbanken hinweg:Dieses Feature ermöglicht das Ausführen von Transaktionen, die sich über mehrere Datenbanken in Azure SQL-Datenbank erstrecken. Elastische Datenbanktransaktionen stehen für .NET-Anwendungen über ADO.NET zur Verfügung und lassen sich mithilfe der Klassen vom Typ System.Transactionin die vertraute Programmierumgebung integrieren.
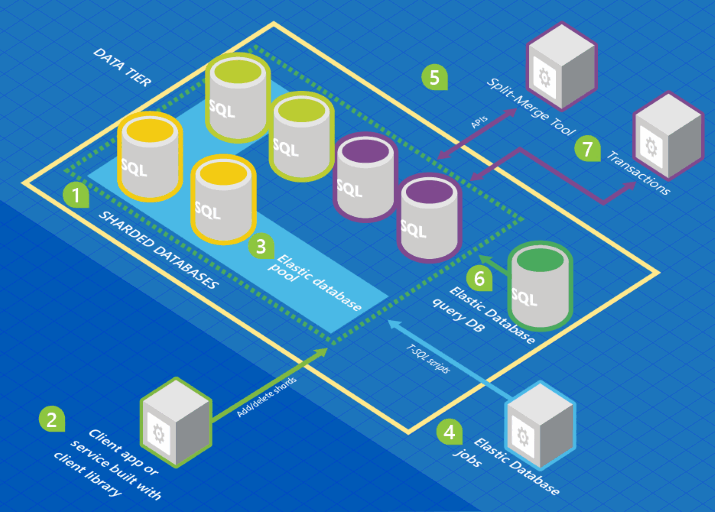
Die folgende Grafik zeigt eine Architektur mit den Features für elastische Datenbanken im Kontext einer Sammlung von Datenbanken.
Die Datenbankfarbe symbolisiert Schemas. Datenbanken mit der gleichen Farbe verwenden die gleichen Schemas.
- Eine Reihe von SQL-Datenbanken wird von Azure unter Verwendung einer Shardingarchitektur gehostet.
- Die Clientbibliothek für elastische Datenbanken dient zum Verwalten einer Shardgruppe.
- Eine Teilmenge der Datenbanken wird einem Pool für elastische Datenbanken zugewiesen.
- Ein Auftrag für elastische Datenbanken führt T-SQL-Skripts für alle Datenbanken aus.
- Mit dem Split-Merge-Tool werden Daten zwischen Shards verschoben.
- Mit der Abfrage für elastische Datenbanken können Sie eine Abfrage für alle Datenbanken in der Shardgruppe erstellen.
- Mit elastischen Transaktionen können Sie Transaktionen ausführen, die sich über mehrere Datenbanken erstrecken.
Gründe für die Verwendung der Tools
Flexibilität und Skalierbarkeit für Cloudanwendungen lassen sich bei virtuellen Computern und Blob Storage durch einfaches Hinzufügen oder Entfernen von Einheiten oder durch Erhöhen der Leistung erreichen. Bei der zustandsbehafteten Datenverarbeitung in relationalen Datenbanken ist es jedoch eine Herausforderung geblieben. Herausforderungen treten in folgenden Szenarios auf:
- Vergrößern und Verkleinern der Kapazität für den relationalen Datenbankteil der Workload.
- Verwalten von Hotspots, die Auswirkungen auf eine bestimmte Teilmenge von Daten haben können – z. B. auf aktive Endkunden (Mandanten).
In der Vergangenheit wurden Szenarien wie diese durch eine Investition in größere Server zur Unterstützung der Anwendung gelöst. Diese Option ist in der Cloud jedoch beschränkt, wo für die gesamte Verarbeitung vordefinierte Standardhardware verwendet wird. Stattdessen stellt die Verteilung von Daten und ihrer Verarbeitung auf mehrere identisch strukturierte Datenbanken (die als „Sharding“ bezeichnete horizontale Hochskalierung) eine Alternative zur herkömmlichen Hochskalierung im Hinblick auf Kosten und Elastizität dar.
Horizontale und vertikale Skalierung
Die folgende Abbildung zeigt die horizontalen und vertikalen Skalierungsdimensionen. Hierbei handelt es sich um die grundlegenden Skalierungsmöglichkeiten für elastische Datenbanken.

Die horizontale Skalierung bezieht sich auf das Hinzufügen oder Entfernen von Datenbanken, um die Kapazität oder die Gesamtleistung anzupassen, was auch als „horizontale Skalierung“ bezeichnet wird. Horizontales Partitionieren, bei dem die Daten auf eine Sammlung identisch strukturierter Datenbanken aufgeteilt werden, ist eine gängige Methode zur Umsetzung der horizontalen Skalierung.
Vertikale Skalierung bezeichnet das Erhöhen oder Verringern der Computegröße einer einzelnen Datenbank. Dies wird auch als „Hochskalieren“ bezeichnet.
Die meisten Datenbankanwendungen für Clouds verwenden eine Kombination aus diesen beiden Ansätzen. Eine SaaS-Anwendung (Software as a Service) kann z. B. die horizontale Skalierung für Bereitstellungen an neue Endkunden nutzen und die vertikale Skalierung, damit die Ressourcen für die Datenbanken der einzelnen Endkunden bei entsprechender Workload vergrößert oder verkleinert werden können.
- Die horizontale Skalierung wird mithilfe der Clientbibliothek für elastische Datenbankenverwaltet.
- Bei der vertikalen Skalierung wird mithilfe von Azure PowerShell-Cmdlets die Dienstebene geändert, oder es werden Datenbanken einem Pool für elastische Datenbanken zugewiesen.
Sharding (Horizontales Partitionieren)
Mit dem horizontalen Partitionieren werden große Mengen identisch strukturierter Daten auf mehrere unabhängige Datenbanken verteilt. Sharding ist besonders bei Cloudentwicklern beliebt, die SaaS-Angebote (Software as a Service) für Endbenutzer oder Unternehmen erstellen. Diese Endkunden werden häufig als „Mandanten“ bezeichnet. Horizontales Partitionieren kann aus einer beliebigen Anzahl von Gründen erforderlich sein:
- Die Gesamtdatenmenge ist so groß, dass sie aufgrund einschlägiger Beschränkungen nicht in einer einzelnen Datenbank gespeichert werden kann.
- Der Transaktionsdurchsatz der Workload überschreitet die Fähigkeiten einer einzelnen Datenbank.
- Mandanten erfordern u. U. eine physische Trennung von anderen Mandaten, sodass für jeden Mandanten eine eigene Datenbank erforderlich ist.
- Verschiedene Abschnitte einer Datenbank müssen sich u. U. aufgrund von Compliance- oder Leistungsanforderungen oder aus geopolitischen Gründen an verschiedenen geografischen Standorten befinden.
In anderen Szenarien, z. B. beim Erfassen von Daten von verteilten Geräten, kann das Sharding eingesetzt werden, um eine Gruppe von Datenbanken über einen Zeitraum verteilt zu füllen. Beispielsweise kann jedem Wochentag oder jeder Woche eine eigene Datenbank zugeordnet werden. In diesem Fall kann der Sharding-Schlüssel eine Ganzzahl sein, die das Datum darstellt (und in allen Zeilen der partitionierten Tabellen vorhanden ist). Abfragen zum Abruf von Informationen für einen Datumsbereich müssen von der Anwendung an die Teilmenge von Datenbanken, welche den fraglichen Bereich abdecken, weitergeleitet werden.
Das Sharding funktioniert am besten, wenn jede Transaktion in einer Anwendung auf einen einzelnen Wert eines Sharding-Schlüssels begrenzt werden kann. Damit wird sichergestellt, dass alle Transaktionen für eine bestimmte Datenbank spezifisch sind.
Mehrere Mandanten und einzelner Mandant
Einige Anwendungen verwenden den einfachsten Ansatz und erstellen für jeden Mandanten eine eigene Datenbank. Dieser Ansatz ist das Shardingmuster mit einzelnen Mandanten, das Isolation, Sicherungs-/Wiederherstellungsfunktion und Ressourcenskalierung auf Ebene einzelner Mandanten bietet. Beim horizontalen Partitionieren mit einzelnen Mandanten ist jede Datenbank mit einem bestimmten Mandanten-ID-Wert (oder Kundenschlüsselwert) verknüpft, wobei der Schlüssel jedoch nicht immer in den Daten vorhanden sein muss. Es ist Aufgabe der Anwendung, die einzelnen Anforderungen an die entsprechende Datenbank weiterzuleiten – dies wird durch die Clientbibliothek vereinfacht.

In anderen Szenarien werden mehrere Mandanten in Datenbanken zusammengefasst, statt sie in getrennten Datenbanken zu isolieren. Bei diesem Muster handelt es sich um ein typisches Shardingszenario mit mehreren Mandanten, dem die Tatsache zugrunde liegen kann, dass eine Anwendung eine große Anzahl von kleinen Mandanten verwalten muss. Beim Sharding mit mehreren Mandanten sollen die Zeilen in den Datenbanktabellen einen Schlüssel enthalten, der die Mandanten-ID oder den Shardschlüssel eindeutig identifiziert. Auch hier ist es Aufgabe der Anwendungsschicht, die Anforderung eines Mandanten an die entsprechende Datenbank weiterzuleiten. Dieser Vorgang kann durch die Clientbibliothek für elastische Datenbanken unterstützt werden. Darüber hinaus kann die Sicherheit auf Zeilenebene zum Filtern der Zeilen verwendet werden, auf die jeder Mandant Zugriff hat. Weitere Informationen hierzu finden Sie unter Mehrinstanzenfähige Anwendungen mit Tools für elastische Datenbanken und zeilenbasierter Sicherheit. Beim horizontalen Partitionieren mit mehreren Mandanten ist möglicherweise eine Neuverteilung der Daten zwischen den Datenbanken erforderlich, die mit dem Split-Merge-Tool für elastische Datenbanken durchgeführt wird. Weitere Informationen zu Entwurfsmustern für SaaS-Anwendungen mit Pools für elastische Datenbanken finden Sie unter Mandantenmuster für mehrinstanzenfähige SaaS-Datenbanken.
Verschieben von Daten aus Datenbanken mit mehreren Mandanten in Datenbanken mit Einzelmandant
Wenn Sie eine SaaS-Anwendung erstellen, wird Interessenten üblicherweise eine Testversion der Software bereitgestellt. In diesem Fall ist es aus Kostengründen sinnvoll, für die Daten eine Datenbank mit mehreren Mandanten zu verwenden. Wenn aus dem Interessenten allerdings ein Kunde wird, ist eine Datenbank mit nur einem Mandanten die bessere Wahl, da diese eine bessere Leistung bietet. Falls der Kunde während des Testzeitraums Daten erstellt, können Sie diese mithilfe des Split-Merge-Tools aus der Datenbank mit mehreren Mandanten in die neue Einzelmandantendatenbank verschieben.
Hinweis
Das Wiederherstellen von mehrinstanzenfähigen Datenbanken in einem einzelnen Mandanten ist nicht möglich.
Beispiele und Tutorials
Unter Erste Schritte mit Tools für elastische Datenbankenfinden Sie eine Beispiel-App zur Veranschaulichung der Clientbibliothek.
Informationen zum Umwandeln von vorhandenen Datenbanken für die Verwendung der Tools finden Sie unter Migrieren vorhandener Datenbanken für die Aufskalierung.
Einzelheiten zum Pool für elastische Datenbanken finden Sie unter Überlegungen zum Preis und zur Leistung von Pools für elastische Datenbanken. Informationen zum Erstellen eines neuen Pools finden Sie unter Erstellen und Verwalten eines Pools für elastische Datenbanken über das Azure-Portal.
Zugehöriger Inhalt
Verwenden Sie noch keine elastischen Datenbanktools? Sehen Sie sich unseren Leitfaden zu den ersten Schritten an. Wenden Sie sich bei Fragen auf der Frageseite von Microsoft Q&A für SQL-Datenbank und für Featureanforderungen an uns, fügen Sie neue Ideen hinzu, oder stimmen Sie im SQL-Datenbank-Feedbackforumüber vorhandene Ideen ab.