Übersicht über die Geschäftskontinuität mit der Azure SQL Managed Instance
Gilt für: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dieser Artikel enthält eine Übersicht über die Business Continuity & Disaster Recovery-Funktionen von Azure SQL Managed Instance, die die Optionen und Empfehlungen zum Wiederherstellen von störenden Ereignissen beschreiben, die zu Datenverlusten führen oder dazu führen können, dass Ihre Instanz und Anwendung nicht mehr verfügbar sind. Erfahren Sie, was zu tun ist, wenn ein Benutzer- oder Anwendungsfehler die Datenintegrität gefährdet, eine Azure-Region ausfällt oder Wartungsaufgaben für Ihre Anwendung ausgeführt werden müssen.
Übersicht
Geschäftskontinuität in Azure SQL Managed Instance bezieht sich auf die Mechanismen, Richtlinien und Verfahren, die Es Ihrem Unternehmen ermöglichen, mit Unterbrechungen fortzufahren, indem Verfügbarkeit, hohe Verfügbarkeit und Notfallwiederherstellung bereitgestellt werden.
In den meisten Fällen behandelt SQL Managed Instance die Störungen, die in der Cloudumgebung auftreten können, und erhält den Betrieb Ihrer Anwendungen und Geschäftsprozesse aufrecht. Es gibt jedoch einige störende Ereignisse, bei denen die Entschärfung einige Zeit in Anspruch nehmen kann, z. B.:
- Ein Benutzer löscht oder aktualisiert versehentlich eine Zeile in einer Tabelle.
- Ein bösartiger Angreifer konnte erfolgreich Daten oder eine Datenbank löschen.
- Katastrophales Naturkatastrophenereignis nimmt ein Rechenzentrum oder eine Verfügbarkeitszone oder Region herunter.
- Seltenes Rechenzentrum, Verfügbarkeitszone oder regionsweite Ausfall durch Konfigurationsänderungen, Softwarefehler oder Hardwarekomponentenfehler.
Verfügbarkeit
Azure SQL Managed Instance bietet eine wichtige Zusage zur Ausfallsicherheit und Zuverlässigkeit, die sie vor Software- oder Hardwarefehlern schützt. Mit automatisierte Sicherungen können Sie Datenbanken ohne Verwaltungsaufwand vor versehentlicher Beschädigung oder Löschung schützen. Als Plattform-as-a-Service (PaaS) bietet der Azure SQL-verwaltete Instanz-Dienst Verfügbarkeit als off-the-shelf-Feature mit einer branchenführenden Verfügbarkeits-SLA von 99,99 %.
Hochverfügbarkeit
Um eine hohe Verfügbarkeit in der Azure-Cloud-Umgebung zu erreichen, müssen Sie die Zonenredundanz aktivieren, damit die Instanz Verfügbarkeitszonen verwendet, um die Widerstandsfähigkeit gegenüber zonalen Ausfällen zu gewährleisten. Viele Azure-Regionen bieten Verfügbarkeitszonen, die getrennte Gruppen von Rechenzentren in einer Region sind, die über unabhängige Energie-, Kühl- und Netzwerkinfrastrukturen verfügen. Verfügbarkeitszonen sind so konzipiert, dass regionale Dienste, Kapazität und hohe Verfügbarkeit in den Zonen für um Standard bereitgestellt werden, wenn eine Zone einen Ausfall erlebt. Durch die Aktivierung von Zonenredundanz ist die Instanz robust für Zonal-Hardware- und Softwarefehler, und die Wiederherstellung ist für Anwendungen transparent. Wenn hohe Verfügbarkeit aktiviert ist, kann der Azure SQL Managed Instance-Dienst eine SLA mit höherer Verfügbarkeit von 99,99 % bereitstellen.
Notfallwiederherstellung
Um eine höhere Verfügbarkeit und Redundanz in allen Regionen zu erreichen, können Sie Notfallwiederherstellungsfunktionen aktivieren, um die Instanz schnell aus einem katastrophalen regionalen Fehler wiederherzustellen. Optionen für die Notfallwiederherstellung für SQL Managed Instance mit Azure Arc-Unterstützung:
- Failovergruppen ermöglichen eine kontinuierliche Synchronisierung zwischen einer primären und sekundären Instanz. Failovergruppen stellen Lese-/Schreibzugriff und schreibgeschützte Listenerendpunkte bereit Standard, die unverändert sind, sodass das Aktualisieren von Anwendungs-Verbindungszeichenfolge s nach dem Failover nicht erforderlich ist.
- Geowiederherstellung ermöglicht es Ihnen, einen regionalen Ausfall wiederherzustellen, indem Sie aus georeplizierten Sicherungen wiederherstellen, wenn Sie nicht auf Ihre Datenbank in der primären Region zugreifen können, indem Sie eine neue Datenbank für jede vorhandene Instanz in einer beliebigen Azure-Region erstellen.
Features zum Sicherstellen der Geschäftskontinuität
Aus Instanzperspektive gibt es vier große potenzielle Störungsszenarien. In der folgenden Tabelle sind die Geschäftskontinuitätsfunktionen von SQL Managed Instance aufgelistet, die Sie verwenden können, um ein mögliches Szenario einer Geschäftsunterbrechung zu entschärfen:
| Szenario für Geschäftsunterbrechungen | Funktionen der Geschäftskontinuität |
|---|---|
| Lokale Hardware- oder Softwarefehler, die Auswirkung auf den Datenbankknoten haben, z. B. Laufwerkfehler. | Um das Risiko lokaler Hardware- und Softwarefehler zu mindern, bietet SQL Managed Instance eine Hochverfügbarkeitsarchitektur, die nach diesen Fehlern eine automatische Wiederherstellung mit einer SLA von bis zu 99,99% Verfügbarkeit gewährleistet. |
| Beschädigte oder gelöschte Daten – in der Regel durch einen Anwendungs- oder Benutzerfehler verursacht. Derartige Fehler sind anwendungsspezifisch und werden normalerweise nicht vom Datenbankdienst erkannt. | Um Ihr Unternehmen vor Datenverlust zu schützen, erstellt SQL Managed Instance automatisch wöchentlich vollständige Datenbanksicherungen, alle 12 oder 24 Stunden differenzielle Datenbanksicherungen und alle 5 bis 10 Minuten Transaktionsprotokollsicherungen. Standardmäßig werden Backups sieben Tage lang in einem georedundanten Speicher abgelegt und unterstützen eine konfigurierbare Backup-Aufbewahrungszeit für die zeitpunktgenaue Wiederherstellung von bis zu 35 Tagen. Sie können eine gelöschte Datenbank an dem Punkt wiederherstellen, an dem sie gelöscht wurde, wenn die Instanz nicht gelöscht wurde oder wenn Sie eine Langzeitaufbewahrung konfiguriert haben. |
| Seltener Ausfall des Rechenzentrums oder der Verfügbarkeitszone, möglicherweise durch ein Naturkatastrophenereignis, Konfigurationsänderung, Softwarefehler oder Hardwarekomponentenfehler. | Um Ausfälle auf der Ebene des Rechenzentrums oder der Verfügbarkeitszone abzumildern, aktivieren Sie die Zonenredundanz für die SQL Managed Instance, um Azure Availability Zones zu verwenden und Redundanz über mehrere physische Zonen innerhalb einer Azure-Region bereitzustellen. Durch Aktivieren der Zonenredundanz wird sichergestellt, dass die verwaltete Instanz widerstandsfähig für Zonalfehler mit bis zu 99,99 % hoher Verfügbarkeits-SLA ist. |
| Seltene Regionenausfälle wirken sich auf alle Verfügbarkeitszonen und die Rechenzentren aus, die sie umfassen, möglicherweise durch katastrophales Naturkatastrophenereignis verursacht. | Um einen regionsweiten Ausfall zu minimieren, aktivieren Sie die Notfallwiederherstellung mithilfe einer der folgenden Optionen: – Kontinuierliche Datensynchronisierung mit Failovergruppen zu Replikaten in einer sekundären Region, die für Failover verwendet wird. – Einstellung der Redundanz des Sicherungsspeichers auf geo-redundanten Sicherungsspeicher zur Verwendung von geo-restore. |
RTO und RPO
Wenn Sie Ihren Plan für die Geschäftskontinuität entwickeln, müssen Sie wissen, wie viel Zeit maximal vergehen darf, bis die Anwendung nach einer Störung vollständig wiederhergestellt ist. Die Zeit, die für die vollständige Wiederherstellung einer Anwendung erforderlich ist, wird als RTO (Recovery Time Objective) bezeichnet. Sie müssen auch herausfinden, über welchen Zeitraum kürzlich durchgeführter Datenupdates (in einem bestimmten Zeitraum) maximal verloren gehen dürfen, wenn die Anwendung nach einer unvorhergesehenen Störung wiederhergestellt wird. Der potenzielle Datenverlust wird als RPO (Recovery Point Objective) bezeichnet.
In der folgenden Tabelle werden die RPO- und RTO-Werte der einzelnen Wiederherstellungsoptionen verglichen:
| Option Geschäftskontinuität | RTO (Ausfallzeit) | RPO (Datenverlust) |
|---|---|---|
| Hohe Verfügbarkeit (mit Zonenredundanz) |
In der Regel weniger als 30 Sekunden | 0 |
| Notfallwiederherstellung (mit Failovergruppen mit kundenverwalteter Failoverrichtlinie) |
In der Regel weniger als 60 Sekunden | Gleich oder größer als 0 (Hängt von Datenänderungen vor dem störenden Ereignis ab, das nicht repliziert wurde) |
| Notfallwiederherstellung (mit geo-restore) |
12 Stunden | 1 Stunde |
Checklisten für Geschäftskontinuität
Informationen zu präskriptiven Empfehlungen zur Maximierung der Verfügbarkeit und zur Erreichung höherer Geschäftskontinuität finden Sie unter:
- Checkliste für die Verfügbarkeit
- Checkliste für Hochverfügbarkeit
- Prüfliste zur Notfallwiederherstellung
Wiederherstellen einer Datenbank innerhalb derselben Azure-Region
Mit automatischen Datenbanksicherungen können Sie eine Datenbank auf einen Zeitpunkt in der Vergangenheit zurücksetzen. Auf diese Weise können Sie Datenbeschädigungen aufgrund von menschlichem Versagen wiederherstellen. Point-in-Time Restore (PITR) ermöglicht es Ihnen, eine neue Datenbank auf derselben oder einer anderen Instanz zu erstellen, die den Zustand der Daten vor dem beschädigenden Ereignis darstellt. Der Wiederherstellungsvorgang ist ein Datenvorgang, der auch von der aktuellen Workload des Zielservers abhängt. Das Wiederherstellen einer sehr großen oder sehr aktiven Datenbank kann länger dauern. Weitere Informationen zur Wiederherstellungszeit finden Sie unter Wiederherstellungszeit für Datenbanken.
Wenn der maximal unterstützte Sicherungsaufbewahrungszeitraum für die Zeitpunktwiederherstellung (Point-In-Time Restore, PITR) für Ihre Anwendung nicht ausreicht, können Sie ihn verlängern, indem Sie eine Richtlinie für die Langzeitaufbewahrung (Long-Term Retention, LTR) für die Datenbanken konfigurieren. Weitere Informationen finden Sie unter Langfristiges Aufbewahren von Sicherungen.
Wiederherstellen einer Datenbank in einer vorhandenen Instanz
Es kommt zwar sehr selten vor, aber es ist möglich, dass ein Azure-Rechenzentrum ausfällt. Ein solcher Ausfall kann den Geschäftsbetrieb einige wenige Minuten oder mehrere Stunden unterbrechen.
- Eine Möglichkeit ist, einfach zu warten, bis der Server wieder online ist, wenn der Rechenzentrumsausfall behoben wurde. Dies funktioniert bei Anwendungen, bei denen die Datenbank nicht notwendigerweise online sein muss. Beispiele hierfür sind Entwicklungsprojekte oder kostenlose Testversionen, mit denen Sie nicht ständig arbeiten müssen. Wenn ein Rechenzentrum ausfällt, wissen Sie nicht, wie lange der Ausfall dauern wird. Daher ist diese Option nur dann in Erwägung zu ziehen, wenn Sie Ihre Datenbank eine Zeit lang nicht benötigen.
- Bei Verwendung von georedundantem oder geozonenredundantem Speicher (GRS bzw. GZRS) besteht eine andere Option darin, eine Datenbank in einer beliebigen verwalteten SQL-Instanz in einer beliebigen Azure-Region mithilfe georedundanter Datenbanksicherungen (Geowiederherstellung) wiederherzustellen. Die Geowiederherstellung verwendet eine georedundante Sicherung als Quelle und kann selbst dann zum Wiederherstellen einer Datenbank auf den letzten verfügbaren Zeitpunkt verwendet werden, wenn die Datenbank oder das Rechenzentrum aufgrund eines Ausfalls nicht mehr verfügbar ist. Die verfügbare Sicherung befindet sich in der gekoppelten Region.
- Schließlich können Sie sich schnell von einem Ausfall erholen, wenn Sie eine geo-sekundäre Gruppe mit einer Failovergruppe für Ihre Instanz konfiguriert haben, die entweder vom Kunden (empfohlen) oder von Microsoft verwaltetes Failover verwendet. Während das Failover selbst nur wenige Sekunden dauert, benötigt der Dienst mindestens eine Stunde, um ein von Microsoft verwaltetes Geo-Failover zu aktivieren, sofern es konfiguriert ist. Diese Zeit ist erforderlich, um sicherzustellen, dass das Failover durch das Ausmaß des Ausfalls gerechtfertigt ist. Außerdem kann das Failover aufgrund der Art der asynchronen Replikation zwischen den gekoppelten Regionen zum Verlust kürzlich geänderter Daten führen.
Wenn Sie Ihren Plan für die Geschäftskontinuität entwickeln, müssen Sie wissen, wie viel Zeit maximal vergehen darf, bis die Anwendung nach einer Störung vollständig wiederhergestellt ist. Die Zeit, die für die vollständige Wiederherstellung einer Anwendung erforderlich ist, wird als RTO (Recovery Time Objective) bezeichnet. Sie müssen auch herausfinden, über welchen Zeitraum kürzlich durchgeführter Datenupdates (in einem bestimmten Zeitraum) maximal verloren gehen dürfen, wenn die Anwendung nach einer unvorhergesehenen Störung wiederhergestellt wird. Der potenzielle Datenverlust wird als RPO (Recovery Point Objective) bezeichnet.
Andere Wiederherstellungsmethoden bieten andere RPO- und RTO-Ebenen. Sie können eine bestimmte Wiederherstellungsmethode auswählen oder verschiedene Methoden kombinieren, um Anwendungen vollständig wiederherzustellen.
Verwenden Sie Failovergruppen, wenn Ihre Anwendung eines dieser Kriterien erfüllt:
- Sie ist geschäftskritisch.
- Es ist eine Vereinbarung zum Servicelevel (SLA) vorhanden, die keine Ausfallzeit von 12 Stunden oder länger erlaubt.
- Ausfallzeiten können Kosten aufgrund finanzieller Haftung nach sich ziehen.
- Daten ändern sich sehr schnell, und ein Datenverlust über eine Stunde ist nicht akzeptabel.
- Die zusätzlichen Kosten für die Georeplikation sind niedriger als die potenziellen Kosten aufgrund der finanziellen Haftung und die damit einhergehenden Geschäftsverluste.
Sie können z. B. je nach den Anforderungen Ihrer Anwendung eine Kombination aus Datenbanksicherungen und Failovergruppen verwenden.
Die nachstehenden Abschnitte bieten eine Übersicht über die Schritte, die zur Wiederherstellung mithilfe von Datenbanksicherungen oder Failovergruppen erforderlich sind.
Vorbereiten auf einen Ausfall
Unabhängig von der Funktion für die Geschäftskontinuität, die Sie einsetzen werden, müssen Sie folgende Aktivitäten ausführen:
- Ermitteln und Vorbereiten der Zielinstanz, einschließlich Netzwerk-IP-Firewallregeln, Anmeldeinformationen und Berechtigungen auf Ebene der
master-Datenbank. - Bestimmen, wie Clients und Clientanwendungen an die neue Instanz umgeleitet werden
- Dokumentieren weiterer Abhängigkeiten wie z.B. Überwachungseinstellungen und Warnungen.
Wenn die Vorbereitung nicht sorgfältig durchgeführt wird, dauert es länger, Anwendungen nach einem Failover oder einer Datenbankwiederherstellung wieder online zu schalten. Zudem werden voraussichtlich weitere Problembehandlungsmaßnahmen zu einem Zeitpunkt erforderlich sein, zu dem Sie bereits unter Stress stehen – eine ungünstige Kombination.
Failover auf eine georeplizierte sekundäre Instanz
Wenn Sie Failovergruppen als Wiederherstellungsmechanismus verwenden, können Sie eine Richtlinie für automatisches Failover konfigurieren. Sobald das Failover initiiert wurde, bewirkt es, dass die sekundäre Instanz zur neuen primären Datenbank wird und neue Transaktionen aufzeichnen sowie auf Abfragen antworten kann. Hierbei entsteht ein minimaler Datenverlust für noch nicht replizierte Daten.
Hinweis
Wenn das Rechenzentrum wieder online geschaltet wird, wird die alte primäre Datenbank automatisch wieder mit der neuen primären Datenbank verbunden und wird damit zur sekundären Instanz. Wenn Sie die primäre Datenbank wieder in den ursprünglichen Bereich verschieben müssen, können Sie manuell ein geplantes Failover initiieren (Failback).
Ausführen einer Geowiederherstellung
Wenn Sie automatisierte Sicherungen mit georedundantem Speicher verwenden (die Standardspeicheroption beim Erstellen Ihrer Instanz), können Sie die Datenbank mithilfe der Geowiederherstellung wiederherstellen. Die Wiederherstellung erfolgt in den meisten Fällen innerhalb von 12 Stunden. Es entsteht ein Datenverlust von bis zu einer Stunde – je nachdem, wann die letzte Protokollsicherung durchgeführt und repliziert wurde. Solange die Wiederherstellung nicht abgeschlossen ist, kann die Datenbank keine Transaktionen aufzeichnen oder auf Abfragen antworten. Beachten Sie, dass die Datenbank mit der Geowiederherstellung nur auf den letzten verfügbaren Zeitpunkt wiederhergestellt wird.
Hinweis
Wenn das Rechenzentrum wieder online ist, bevor Sie Ihre Anwendung auf die wiederhergestellte Datenbank umstellen, können Sie die Wiederherstellung abbrechen.
Ausführen von Aufgaben nach dem Failover bzw. nach der Wiederherstellung
Nach einer Wiederherstellung müssen Sie unabhängig vom Wiederherstellungsmechanismus folgende zusätzliche Aufgaben ausführen, damit Ihre Anwendungen wieder vollständig einsatzfähig sind und von Ihren Benutzern wieder in vollem Umfang verwendet werden können:
- Umleiten von Clients und Clientanwendungen an die neue Instanz.
- Sicherstellen, dass geeignete Netzwerk-IP-Firewallregeln vorhanden sind, damit Benutzer eine Verbindung herstellen können.
- Sicherstellen, dass die geeigneten Anmeldungen und Berechtigungen auf Ebene der
master-Datenbank vorhanden sind (oder Verwenden von eigenständigen Benutzer*innen). - Konfigurieren der erforderlichen Überwachung.
- Konfigurieren der erforderlichen Warnungen.
Hinweis
Wenn Sie eine Failovergruppe verwenden und eine Verbindung mit den Datenbanken über den Lese-/Schreiblistener herstellen, erfolgt die Umleitung nach einem Failover an die Anwendung automatisch und transparent.
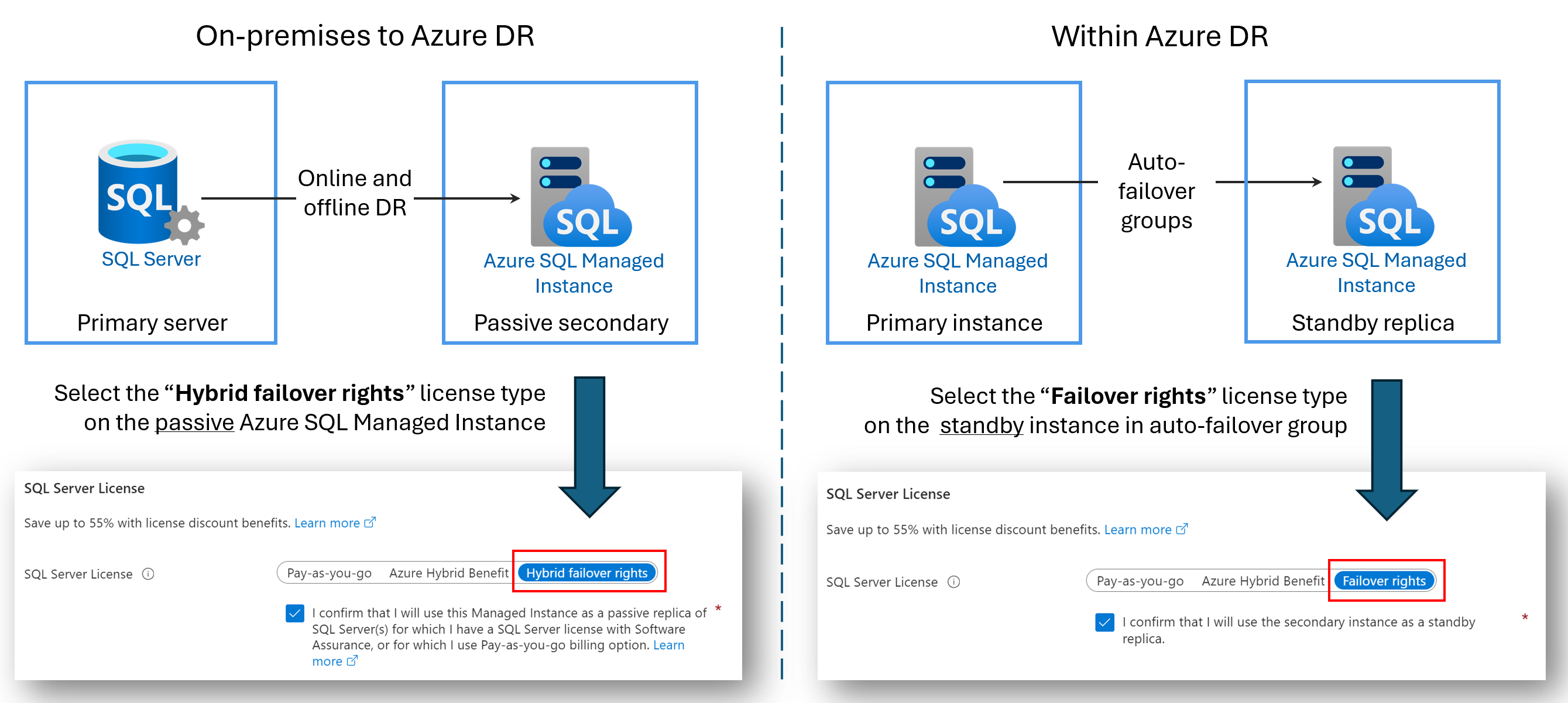
Lizenzfreie DR-Replikate
Sie können Lizenzkosten sparen, indem Sie eine sekundäre Azure SQL Managed Instance-Instanz nur für die Notfallwiederherstellung (DR) konfigurieren. Dieser Vorteil ist verfügbar, wenn Sie eine Failovergruppen zwischen zwei SQL Managed Instance-Instanzen verwenden oder eine Hybridverbindung zwischen SQL Server und Azure SQL Managed Instance konfiguriert haben. Solange die sekundäre Instanz keine Lese- oder Schreibworkloads enthält und nur ein passiver DR-Standby ist, werden Ihnen keine Lizenzgebühren für die von der sekundären Instanz verwendeten virtuellen Kerne in Rechnung gestellt.
Wenn eine sekundäre Instanz als Standbyinstanz festgelegt wird, stellt Microsoft Ihnen ohne zusätzliche Kosten so viele virtuelle Kerne zur Verfügung, wie für die primäre Instanz lizenziert sind. Dies erfolgt im Rahmen des bereitgestellten Vorteils für Failover-Rechte. Ihnen werden trotzdem die Compute- und Speicherkosten in Rechnung gestellt, die von der sekundären Instanz verwendet werden. Genaue Bedingungen des Vorteils von Hybrid-Failover-Rechten finden Sie in den SQL Server-Lizenzierungsbedingungen online im Abschnitt SQL Server – Failover-Rechte.
Die Bezeichnung für diesen Vorteil hängt von Ihrem Szenario ab:
- Hybrid-Failoverrechte für ein passives Replikat: Wenn Sie eine Verbindung zwischen SQL Server und Azure SQL Managed Instance konfigurieren, können Sie den Vorteil Hybrid-Failoverrechte nutzen, um Lizenzierungsgebühren für den virtuellen Kern für das passive sekundäre Replikat zu sparen.
- Failoverrechte für ein Standby-Replikat: Wenn Sie eine Failovergruppe zwischen zwei verwalteten Instanzen konfigurieren, können Sie den Vorteil der Failoverrechte nutzen, um die vCore-Lizenzkosten für das sekundäre Standby-Replikat zu senken.
Das folgende Diagramm zeigt den Vorteil für jedes Szenario:
Nächste Schritte
Weitere Informationen zu Business Continuity-Funktionen finden Sie unter Automatisierte Backups und Failovergruppen. Informationen zur Notfallwiederherstellung finden Sie unter Wiederherstellen einer Datenbank und Aktivieren der Zonenredundanz für Azure SQL Managed Instance.