Das Kopieren von Daten nach und aus Azure Databricks Delta Lake mithilfe von Azure Data Factory oder Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Kopieraktivität in Azure Data Factory und Azure Synapse verwenden, um Daten nach und aus Azure Databricks Delta Lake zu kopieren. Er baut auf dem Artikel zur Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Unterstützte Funktionen
Dieser Azure Databricks Delta Lake-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② |
| Zuordnungsdatenfluss (Quelle/Senke) | ① |
| Lookup-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Im Allgemeinen bietet der Dienst Unterstützung für Delta Lake mit den folgenden Funktionen, um Ihren verschiedenen Anforderungen zu entsprechen.
- Die Kopieraktivität unterstützt den Azure Databricks Delta Lake-Connector beim Kopieren von Daten aus einem beliebigen unterstützten Quelldatenspeicher in die Azure Databricks Delta Lake-Tabelle und aus der Delta Lake-Tabelle in einen beliebigen unterstützten Senkendatenspeicher. Sie nutzt Ihren Databricks-Cluster zur Durchführung der Datenverschiebung. Weitere Informationen finden Sie im Abschnitt Voraussetzungen.
- Der Zuordnungsdatenfluss unterstützt das generische Delta-Format für Azure Storage als Quelle und Senke zum Lesen und Schreiben von Delta-Dateien für ETL-Vorgänge ohne Code und wird unter der verwalteten Azure Integration Runtime ausgeführt.
- Databricks-Aktivitäten unterstützen zusätzlich zu Delta Lake die Orchestrierung Ihrer codezentrischen ETL- oder Machine Learning-Workload.
Voraussetzungen
Um diesen Azure Databricks Delta Lake-Connector zu verwenden, müssen Sie einen Cluster in Azure Databricks einrichten.
- Zum Kopieren von Daten nach Delta Lake ruft die Kopieraktivität den Azure Databricks-Cluster auf, um Daten aus einem Azure Storage zu lesen, bei dem es sich entweder um Ihre ursprüngliche Quelle oder einen Stagingbereich handelt, in den der Dienst die Quelldaten zunächst über eine integrierte gestaffelte Kopie schreibt. Weitere Informationen finden Sie unter Delta Lake als Senke.
- Ähnlich verhält es sich mit dem Kopieren von Daten aus Delta Lake, wobei die Kopieraktivität den Azure Databricks-Cluster aufruft, um Daten in einen Azure Storage zu schreiben, bei dem es sich entweder um Ihre ursprüngliche Senke oder einen Stagingbereich handelt, von dem aus der Dienst weiterhin Daten über eine integrierte gestaffelte Kopie in die endgültige Senke schreibt. Weitere Informationen finden Sie unter Delta Lake als Quelle.
Der Databricks-Cluster muss Zugriff auf das Azure Blob- oder Azure Data Lake Storage Gen2-Konto haben, sowohl auf den Speichercontainer/das Dateisystem, der/das für Quelle/Senke/Staging verwendet wird, als auch auf den Container/das Dateisystem, in den/das Sie die Delta Lake-Tabellen schreiben möchten.
Zur Verwendung von Azure Data Lake Storage Gen2 können Sie im Rahmen der Apache Spark-Konfiguration einen Dienstprinzipal auf dem Databricks-Cluster konfigurieren. Führen Sie die Schritte unter Direkter Zugriff mit Dienstprinzipal aus.
Zur Verwendung von Azure-Blobspeicher können Sie einen Zugriffsschlüssel für das Speicherkonto oder ein SAS-Token auf dem Databricks-Cluster im Rahmen der Apache Spark-Konfiguration konfigurieren. Befolgen Sie die Schritte in Zugreifen auf Azure-Blobspeicher mithilfe der RDD-API.
Wenn der von Ihnen konfigurierte Cluster während der Ausführung der Kopieraktivität beendet wurde, startet der Dienst ihn automatisch. Wenn Sie eine Pipeline mithilfe der Erstellungsbenutzeroberfläche erstellen, benötigen Sie für Vorgänge wie die Datenvorschau einen aktiven Cluster. Der Dienst startet den Cluster nicht in Ihrem Auftrag.
Angeben der Clusterkonfiguration
Wählen Sie in der Dropdownliste Clustermodus die Option Standard aus.
Wählen Sie in der Dropdownliste Databricks-Runtimeversion eine Databricks-Runtimeversion aus.
Aktivieren Sie Automatisches Optimieren, indem Sie die folgenden Eigenschaften zu Ihrer Spark-Konfiguration hinzufügen:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueKonfigurieren Sie Ihren Cluster je nach Ihren Integrations- und Skalierungsanforderungen.
Weitere Informationen zur Clusterkonfiguration finden Sie unter Konfigurieren von Clustern.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
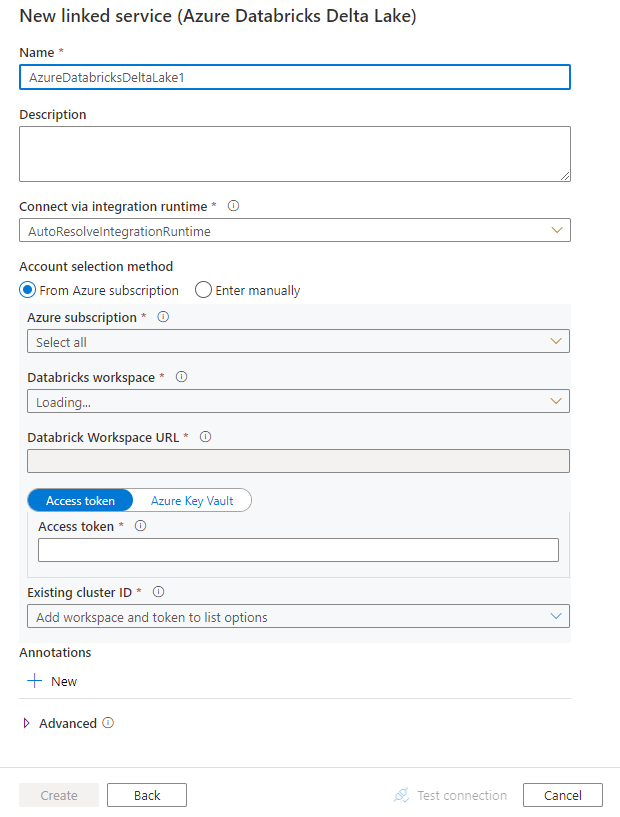
Erstellen eines verknüpften Diensts für Azure Databricks Delta Lake über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst mit Azure Databricks Delta Lake auf der Azure-Portal-Benutzeroberfläche zu erstellen.
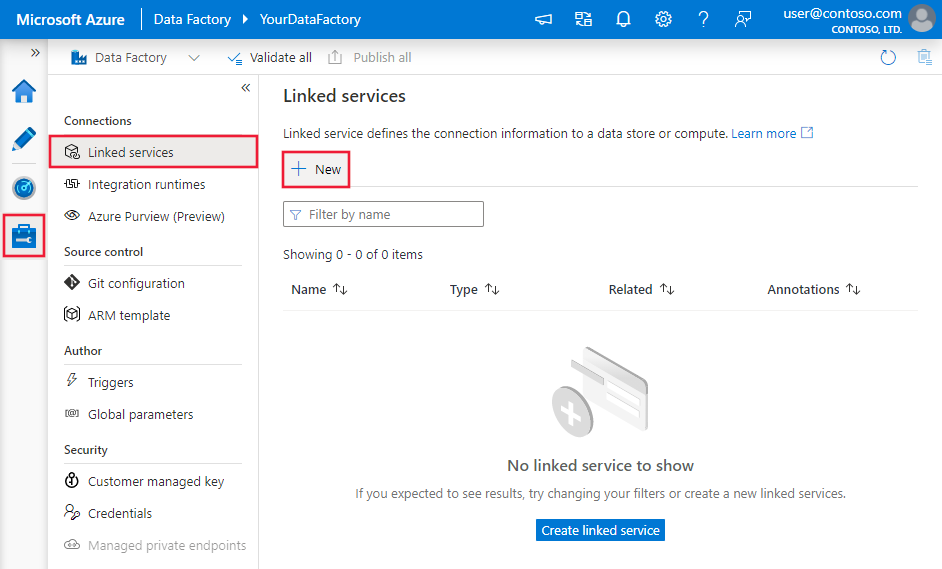
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach Delta, und wählen Sie den Azure Databricks Delta Lake-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Entitäten speziell für einen Azure Databricks Delta Lake-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Dieser Azure Databricks Delta Lake-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
- Zugriffstoken
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Zugriffstoken
Die folgenden Eigenschaften werden für den mit Azure Databricks Delta Lake verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDatabricksDeltaLake festgelegt werden. | Ja |
| Domäne | Geben Sie die Azure Databricks-Arbeitsbereichs-URL an, z. B. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Geben Sie die Cluster-ID eines vorhandenen Clusters an. Dabei sollte es sich um einen bereits erstellten interaktiven Cluster handeln. Sie finden die Cluster-ID eines interaktiven Clusters unter: Databricks-Arbeitsbereich -> Cluster -> Name des interaktiven Clusters -> Konfiguration -> Tags. Weitere Informationen. |
|
| accessToken | Für die Authentifizierung bei Azure Databricks benötigt der Dienst ein Zugriffstoken. Das Zugriffstoken muss im Databricks-Arbeitsbereich generiert werden. Ausführlichere Informationen zum Auffinden des Zugriffstokens finden Sie hier. | |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (wenn sich der Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
Weitere Informationen zu systemseitig zugewiesenen verwalteten Identitäten für Azure-Ressourcen finden Sie unter Systemseitig zugewiesene verwaltete Identität für Azure-Ressourcen.
Führen Sie die folgenden Schritte zum Gewähren von Berechtigungen aus, um die Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität zu verwenden:
Rufen Sie die Informationen zur verwalteten Identität ab, indem Sie den Wert der Objekt-ID der verwalteten Identität kopieren, der zusammen mit Ihrer Data Factory oder Ihrem Synapse-Arbeitsbereich generiert wurde.
Erteilen Sie der verwalteten Identität die geeigneten Berechtigungen in Azure Databricks. Im Allgemeinen müssen Sie Ihrer systemseitig zugewiesenen verwalteten Identität in der Zugriffssteuerung (IAM) von Azure Databricks mindestens die Rolle Mitwirkender gewähren.
Die folgenden Eigenschaften werden für den mit Azure Databricks Delta Lake verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDatabricksDeltaLake festgelegt werden. | Ja |
| Domäne | Geben Sie die Azure Databricks-Arbeitsbereichs-URL an, z. B. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Geben Sie die Cluster-ID eines vorhandenen Clusters an. Dabei sollte es sich um einen bereits erstellten interaktiven Cluster handeln. Sie finden die Cluster-ID eines interaktiven Clusters unter: Databricks-Arbeitsbereich -> Cluster -> Name des interaktiven Clusters -> Konfiguration -> Tags. Weitere Informationen. |
Ja |
| workspaceResourceId | Geben Sie die Arbeitsbereichsressourcen-ID Ihrer Azure Databricks an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (wenn sich der Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Weitere Informationen zu benutzerseitig zugewiesenen verwalteten Identitäten für Azure-Ressourcen finden Sie unter benutzerseitig zugewiesene verwaltete Identitäten.
Führen Sie die folgenden Schritte aus, um die Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität zu verwenden:
Erstellen Sie eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten, und gewähren Sie ihnen Berechtigungen in Ihrem Azure Databricks. Im Allgemeinen müssen Sie Ihrer benutzerseitig zugewiesenen verwalteten Identität in der Zugriffssteuerung (IAM) von Azure Databricks mindestens die Rolle Mitwirkender gewähren.
Weisen Sie Ihrer Data Factory oder Ihrem Synapse-Arbeitsbereich eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Die folgenden Eigenschaften werden für den mit Azure Databricks Delta Lake verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf AzureDatabricksDeltaLake festgelegt werden. | Ja |
| Domäne | Geben Sie die Azure Databricks-Arbeitsbereichs-URL an, z. B. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Geben Sie die Cluster-ID eines vorhandenen Clusters an. Dabei sollte es sich um einen bereits erstellten interaktiven Cluster handeln. Sie finden die Cluster-ID eines interaktiven Clusters unter: Databricks-Arbeitsbereich -> Cluster -> Name des interaktiven Clusters -> Konfiguration -> Tags. Weitere Informationen. |
Ja |
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
| workspaceResourceId | Geben Sie die Arbeitsbereichsressourcen-ID Ihrer Azure Databricks an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (wenn sich der Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Folgende Eigenschaften werden für das Azure Databricks Delta Lake-Dataset unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft des Datasets muss auf AzureDatabricksDeltaLakeDataset festgelegt werden. | Ja |
| database | Der Name der Datenbank. | Quelle: Nein, Senke: Ja |
| table | Der Name der Delta-Tabelle. | Quelle: Nein, Senke: Ja |
Beispiel:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Azure Databricks Delta Lake-Quelle und -Senke unterstützt werden.
Delta Lake als Quelle
Beim Kopieren von Daten aus Azure Databricks Delta Lake werden die folgenden Eigenschaften im Abschnitt source der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf AzureDatabricksDeltaLakeSource festgelegt werden. | Ja |
| Abfrage | Geben Sie die SQL-Abfrage an, um Daten zu lesen. Für die Zeitreisesteuerung folgen Sie dem folgenden Muster: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Nein |
| exportSettings | Erweiterte Einstellungen, die zum Abrufen von Daten aus der Delta-Tabelle verwendet werden. | Nein |
Unter exportSettings: |
||
| type | Der Typ des Exportbefehls, festgelegt auf AzureDatabricksDeltaLakeExportCommand. | Ja |
| dateFormat | Formatieren Sie den Datumstyp in eine Zeichenfolge mit einem Datumsformat. Benutzerdefinierte Datumsformate folgen den Formaten unter datetime-Mustern. Wenn keine Angabe erfolgt, wird der Standardwert yyyy-MM-dd verwendet. |
Nein |
| timestampFormat | Formatieren Sie den Zeitstempeltyp in eine Zeichenfolge mit einem Zeitstempelformat. Benutzerdefinierte Datumsformate folgen den Formaten unter datetime-Mustern. Wenn keine Angabe erfolgt, wird der Standardwert yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] verwendet. |
Nein |
Direkte Kopie aus Delta Lake
Wenn der Senkendatenspeicher und das Format die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mit der Kopieraktivität Kopiervorgänge direkt aus der Azure Databricks Delta-Tabelle in die Senke durchführen. Der Dienst überprüft die Einstellungen und gibt bei der Copy-Aktivitätsausführung einen Fehler aus, wenn die folgenden Kriterien nicht erfüllt werden:
Der verknüpfte Senkendienst ist Azure-Blobspeicher oder Azure Data Lake Storage Gen2. Die Anmeldeinformation für das Konto sollten in der Clusterkonfiguration von Azure Databricks vorkonfiguriert sein. Weitere Informationen finden Sie unter Voraussetzungen.
Das Senkendatenformat lautet Parquet, Durch Trennzeichen getrennter Text oder Avro mit den folgenden Konfigurationen und verweist auf einen Ordner anstatt auf eine Datei.
- Beim Format Parquet wird einer der Komprimierungscodecs None, Snappy oder GZIP verwendet.
- Beim Format Durch Trennzeichen getrennter Text:
rowDelimiterist ein beliebiges einzelnes Zeichen.compressionkann None, BZIP2, GZIP sein.encodingNameUTF-7 wird nicht unterstützt.
- Beim Format Avro wird einer der Komprimierungscodecs None, Deflate oder Snappy verwendet.
In der Quelle der Kopieraktivität ist
additionalColumnsnicht angegeben.Wenn Daten in durch Trennzeichen getrennter Text kopiert werden, muss
fileExtensionin der Kopieraktivitätssenke „.csv“ sein.In der Zuordnung der Kopieraktivität ist die Typkonvertierung nicht aktiviert.
Beispiel:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gestaffelte Kopie aus Delta Lake
Wenn Ihr Senkendatenspeicher oder das Format nicht den Kriterien für die direkte Kopie entspricht, wie im letzten Abschnitt erwähnt, aktivieren Sie die integrierte gestaffelte Kopie mithilfe einer Azure Storage-Zwischeninstanz. Das gestaffelte Kopieren bietet auch einen höheren Durchsatz. Der Dienst exportiert Daten aus Azure Databricks Delta Lake in den Stagingspeicher, kopiert dann die Daten in die Senke und bereinigt schließlich die temporären Daten aus dem Stagingspeicher. Ausführliche Informationen zum Kopieren von Daten mithilfe von Staging finden Sie unter Gestaffeltes Kopieren.
Um dieses Feature verwenden zu können, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst oder einen mit Azure Data Lake Storage Gen2 verknüpften Dienst, der auf das Speicherkonto als Zwischenbereich verweist. Geben Sie dann die Eigenschaften enableStaging und stagingSettings in der Kopieraktivität an.
Hinweis
Die Anmeldeinformation für das Konto des Stagingspeichers sollten in der Clusterkonfiguration von Azure Databricks vorkonfiguriert sein. Weitere Informationen finden Sie unter Voraussetzungen.
Beispiel:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake als Senke
Beim Kopieren von Daten in Azure Databricks Delta Lake werden die folgenden Eigenschaften im Abschnitt sink der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Senke der Kopieraktivität ist auf AzureDatabricksDeltaLakeSink festgelegt. | Ja |
| preCopyScript | Geben Sie eine SQL-Abfrage an, die bei jeder Ausführung von der Kopieraktivität ausgeführt werden soll, bevor Daten in die Databricks-Delta-Tabelle geschrieben werden. Beispiel: VACUUM eventsTable DRY RUN Sie können diese Eigenschaft verwenden, um die vorinstallierten Daten zu bereinigen oder eine „truncate table“- oder „Vacuum“-Anweisung hinzuzufügen. |
Nein |
| importSettings | Erweiterte Einstellungen, die zum Schreiben von Daten in eine Delta-Tabelle verwendet werden. | Nein |
Unter importSettings: |
||
| type | Der Typ des Importbefehls, festgelegt auf AzureDatabricksDeltaLakeImportCommand. | Ja |
| dateFormat | Formatieren Sie die Zeichenfolge in einen Datumstyp mit einem Datumsformat. Benutzerdefinierte Datumsformate folgen den Formaten unter datetime-Mustern. Wenn keine Angabe erfolgt, wird der Standardwert yyyy-MM-dd verwendet. |
Nein |
| timestampFormat | Formatieren Sie die Zeichenfolge in einen Zeitstempeltyp mit einem Zeitstempelformat. Benutzerdefinierte Datumsformate folgen den Formaten unter datetime-Mustern. Wenn keine Angabe erfolgt, wird der Standardwert yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] verwendet. |
Nein |
Direktes Kopieren nach Delta Lake
Wenn der Quelldatenspeicher und das Format die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mit der Kopieraktivität Kopiervorgänge direkt aus der Quelle in Azure Databricks Delta Lake durchführen. Der Dienst überprüft die Einstellungen und gibt bei der Copy-Aktivitätsausführung einen Fehler aus, wenn die folgenden Kriterien nicht erfüllt werden:
Der verknüpfte Quelldienst ist Azure-Blobspeicher oder Azure Data Lake Storage Gen2. Die Anmeldeinformation für das Konto sollten in der Clusterkonfiguration von Azure Databricks vorkonfiguriert sein. Weitere Informationen finden Sie unter Voraussetzungen.
Das Quelldatenformat lautet Parquet, Durch Trennzeichen getrennter Text oder Avro mit den folgenden Konfigurationen und verweist auf einen Ordner anstatt auf eine Datei.
- Beim Format Parquet wird einer der Komprimierungscodecs None, Snappy oder GZIP verwendet.
- Beim Format Durch Trennzeichen getrennter Text:
rowDelimiterist „default“ oder ein beliebiges einzelnes Zeichen.compressionkann None, BZIP2, GZIP sein.encodingNameUTF-7 wird nicht unterstützt.
- Beim Format Avro wird einer der Komprimierungscodecs None, Deflate oder Snappy verwendet.
In der Quelle der Kopieraktivität:
wildcardFileNameenthält nur das Platzhalterzeichen*, aber nicht?, undwildcardFolderNameist nicht angegeben.prefix,modifiedDateTimeStart,modifiedDateTimeEndundenablePartitionDiscoverysind nicht angegeben.additionalColumnsist nicht angegeben.
In der Zuordnung der Kopieraktivität ist die Typkonvertierung nicht aktiviert.
Beispiel:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Gestaffeltes Kopieren nach Delta Lake
Wenn Ihr Quelldatenspeicher oder das Format nicht den Kriterien für die direkte Kopie entspricht, wie im letzten Abschnitt erwähnt, aktivieren Sie die integrierte gestaffelte Kopie mithilfe einer Azure Storage-Zwischeninstanz. Das gestaffelte Kopieren bietet auch einen höheren Durchsatz. Der Dienst konvertiert die Daten automatisch in einen Stagingspeicher, um die Anforderungen an das Datenformat zu erfüllen, und lädt die Daten von dort aus in Delta Lake. Abschließend werden Sie die temporären Daten im Speicher bereinigt. Ausführliche Informationen zum Kopieren von Daten mithilfe von Staging finden Sie unter Gestaffeltes Kopieren.
Um dieses Feature verwenden zu können, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst oder einen mit Azure Data Lake Storage Gen2 verknüpften Dienst, der auf das Speicherkonto als Zwischenbereich verweist. Geben Sie dann die Eigenschaften enableStaging und stagingSettings in der Kopieraktivität an.
Hinweis
Die Anmeldeinformation für das Konto des Stagingspeichers sollten in der Clusterkonfiguration von Azure Databricks vorkonfiguriert sein. Weitere Informationen finden Sie unter Voraussetzungen.
Beispiel:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Überwachung
Es wird der gleiche Ablauf bei der Überwachung von Kopieraktivitäten wie mit anderen Connectors geboten. Da das Laden von Daten von/nach Delta Lake auf Ihrem Azure Databricks-Cluster ausgeführt wird, können Sie darüber hinaus detaillierte Clusterprotokolle anzeigen und die Leistung überwachen.
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität in Azure Data Factory.
Die Lookup-Aktivität kann bis zu 1000 Zeilen zurückgeben. Wenn das Resultset mehr Datensätze enthält, werden die ersten 1000 Zeilen zurückgegeben.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quellen und Senken für die Copy-Aktivität unterstützt werden, finden Sie unter Unterstützte Datenspeicher und Formate.