Kopieren von Daten aus MongoDB mithilfe von Azure Data Factory oder Synapse Analytics (Legacy)
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- oder Azure Synapse Analytics-Pipelines verwenden, um Daten aus einer MongoDB-Datenbank zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Wichtig
Der Dienst umfasst einen neuen MongoDB-Connector, der bessere native MongoDB-Unterstützung gegenüber dieser ODBC-basierten Implementierung bietet. Ausführliche Informationen dazu finden Sie im Artikel MongoDB-Connector.
Unterstützte Funktionen
Sie können Daten aus einer MongoDB-Datenbank in beliebige unterstützte Senkendatenspeicher kopieren. Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Der MongoDB-Connector unterstützt insbesondere Folgendes:
- MongoDB Version 2.4, 2.6, 3.0, 3.2, 3.4 und 3.6
- Kopieren von Daten unter Verwendung der Standard- oder anonymen Authentifizierung
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Integration Runtime bietet einen integrierten MongoDB-Treiber. Daher müssen beim Kopieren von Daten aus MongoDB keine Treiber manuell installiert werden.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts für MongoDB über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen verknüpften Dienst für MongoDB in der Benutzeroberfläche des Azure-Portals zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach Mongo, und wählen Sie den MongoDB-Connector aus.
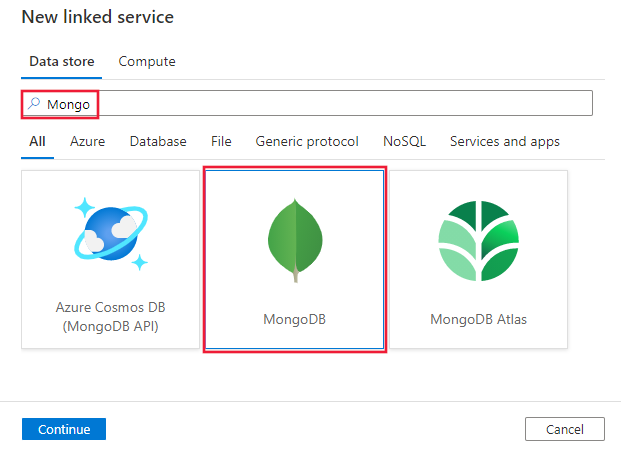
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
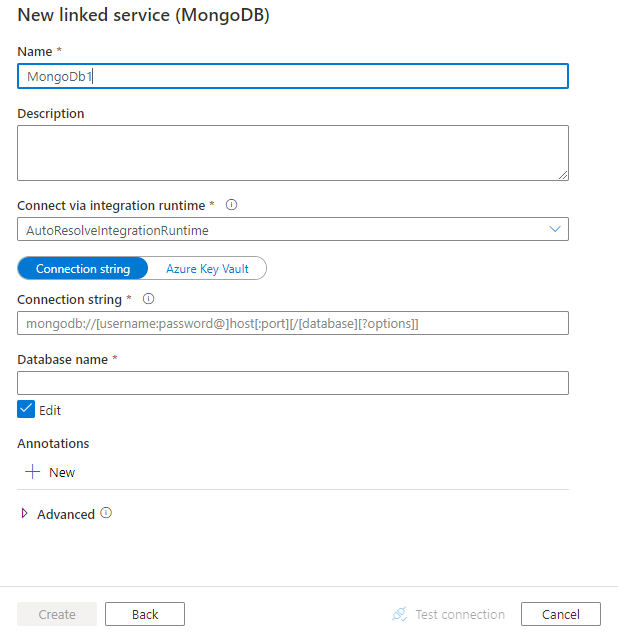
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den MongoDB-Connector verwendet werden:
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit MongoDB verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Folgendes festgelegt werden: MongoDb | Ja |
| server | IP-Adresse oder Hostname des MongoDB-Servers | Ja |
| port | Der TCP-Port, den der MongoDB-Server verwendet, um auf Clientverbindungen zu lauschen | Nein (Standard = 27017) |
| databaseName | Der Name der MongoDB-Datenbank, auf die Sie zugreifen möchten | Ja |
| authenticationType | Typ der Authentifizierung für die Verbindung mit der MongoDB-Datenbank. Zulässige Werte sind: Standard und Anonym. |
Ja |
| username | Benutzerkonto für den Zugriff auf MongoDB | Ja (wenn die Standardauthentifizierung verwendet wird) |
| password | Kennwort für den Benutzer Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja (wenn die Standardauthentifizierung verwendet wird) |
| authSource | Der Name der MongoDB-Datenbank, die Sie zum Überprüfen Ihrer Anmeldeinformationen zur Authentifizierung verwenden möchten | Nein. Bei der Standardauthentifizierung werden standardmäßig das Administratorkonto und die Datenbank verwendet, die mit der databaseName-Eigenschaft angegeben wird |
| enableSsl | Gibt an, ob Verbindungen mit dem Server mit TLS verschlüsselt werden. Der Standardwert ist „FALSE“. | Nein |
| allowSelfSignedServerCert | Gibt an, ob vom Server selbstsignierte Zertifikate zugelassen werden. Der Standardwert ist false. | Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDb",
"typeProperties": {
"server": "<server name>",
"databaseName": "<database name>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie unter Datasets und verknüpfte Dienste. Folgende Eigenschaften werden für das MongoDB-Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf folgenden Wert festgelegt werden: MongoDbCollection | Ja |
| collectionName | Der Name der Sammlung in der MongoDB-Datenbank | Ja |
Beispiel:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbCollection",
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"collectionName": "<Collection name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der MongoDB-Quelle unterstützt werden.
MongoDB als Quelle
Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: MongoDbSource | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-92-Abfrage zum Lesen von Daten. Beispiel: select * from MyTable. | Nein (wenn „collectionName“ im Dataset angegeben ist) |
Beispiel:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tipp
Achten Sie beim Angeben der SQL-Abfrage auf das DateTime-Format. Beispiel: SELECT * FROM Account WHERE LastModifiedDate >= '2018-06-01' AND LastModifiedDate < '2018-06-02' oder verwenden Sie Parameter: SELECT * FROM Account WHERE LastModifiedDate >= '@{formatDateTime(pipeline().parameters.StartTime,'yyyy-MM-dd HH:mm:ss')}' AND LastModifiedDate < '@{formatDateTime(pipeline().parameters.EndTime,'yyyy-MM-dd HH:mm:ss')}'
Schema per Data Factory
Der Azure Data Factory-Dienst leitet ein Schema aus einer MongoDB-Sammlung mithilfe der letzten 100 Dokumente in der Sammlung ab. Wenn diese 100 Dokumente kein vollständiges Schema enthalten, können einige Spalten während des Kopiervorgangs ignoriert werden.
Datentypzuordnung für MongoDB
Beim Kopieren von Daten aus MongoDB werden die folgenden Zuordnungen von MongoDB-Datentypen zu den vom Dienst intern verwendeten Zwischendatentypen verwendet. Unter Schema- und Datentypzuordnungen erfahren Sie, wie Sie Aktivitätszuordnungen für Quellschema und Datentyp in die Senke kopieren.
| MongoDB-Datentyp | Zwischendatentyp des Diensts |
|---|---|
| Binary | Byte[] |
| Boolean | Boolean |
| Date | Datetime |
| NumberDouble | Double |
| NumberInt | Int32 |
| NumberLong | Int64 |
| ObjectID | String |
| String | String |
| UUID | Guid |
| Object | Renormalisiert in vereinfachte Spalten mit dem geschachtelten Trennzeichen „_“ |
Hinweis
Weitere Informationen zur Unterstützung für Arrays mit virtuellen Tabellen finden Sie im Abschnitt Unterstützung für komplexe Typen mit virtuellen Tabellen.
Die folgenden MongoDB-Datentypen werden derzeit nicht unterstützt: „DBPointer“, „JavaScript“, „MaxKey/MinKey“, „Regular Expression“, „Symbol“, „Timestamp“, „Undefined“.
Unterstützung für komplexe Typen mit virtuellen Tabellen
Der Dienst verwendet einen integrierten ODBC-Treiber, um eine Verbindung mit der MongoDB-Datenbank herzustellen und Daten daraus zu kopieren. Für komplexe Typen wie Arrays oder Objekte mit unterschiedlichen Typen in den Dokumenten renormalisiert der Treiber die Daten in die entsprechenden virtuellen Tabellen. Wenn eine Tabelle solche Spalten enthält, generiert der Treiber die folgenden virtuellen Tabellen:
- Eine Basistabelle, die die gleichen Daten wie die echte Tabelle enthält, mit Ausnahme der Spalten mit komplexen Typen. Für die Basistabelle wird der gleiche Name wie für die echte Tabelle verwendet, die sie repräsentiert.
- Eine virtuelle Tabelle für jede Spalte mit komplexen Typen (Erweiterung der geschachtelten Daten). Die virtuellen Tabellen werden mit dem Namen der echten Tabelle benannt und erhalten zusätzlich das Trennzeichen „_“ und den Namen der des Arrays oder Objekts.
Virtuelle Tabellen beziehen sich auf die Daten in der echten Tabelle, sodass der Treiber auf die denormalisierten Daten zugreifen kann. Sie können auf den Inhalt von MongoDB-Arrays zugreifen, indem Sie die virtuellen Tabellen abfragen und verknüpfen.
Beispiel
Beispielsweise ist „ExampleTable“ in diesem Fall eine MongoDB-Tabelle, die eine Spalte (Invoices) mit einem Array von Objekten in jeder Zelle enthält sowie eine Spalte (Ratings) mit einem Array von skalaren Typen.
| _id | Customer Name | Invoices | Dienstebene | Ratings |
|---|---|---|---|---|
| 1111 | ABC | [{invoice_id:"123", item:"toaster", price:"456", discount:"0.2"}, {invoice_id:"124", item:"oven", price: "1235", discount: "0.2"}] | Silber | [5,6] |
| 2222 | XYZ | [{invoice_id:"135", item:"fridge", price: "12543", discount: "0.0"}] | Gold | [1,2] |
Der Treiber erzeugt mehrere virtuelle Tabellen, um diese einzelne Tabelle zu repräsentieren. Die erste virtuelle Tabelle ist die im Beispiel dargestellte Basistabelle mit dem Namen „ExampleTable“. Die Basistabelle enthält alle Daten der ursprünglichen Tabelle, aber die Daten aus den Arrays wurden ausgelassen und werden in den virtuellen Tabellen erweitert.
| _id | Customer Name | Dienstebene |
|---|---|---|
| 1111 | ABC | Silber |
| 2222 | XYZ | Gold |
Die folgenden Tabellen enthalten die virtuellen Tabellen, die die ursprünglichen Arrays im Beispiel darstellen. Diese Tabellen enthalten Folgendes:
- Einen Verweis zurück auf die ursprüngliche Primärschlüsselspalte, die der Zeile des ursprünglichen Arrays entspricht (über die Spalte „_id“)
- Einen Hinweis auf die Position der Daten im ursprünglichen Array
- Die erweiterten Daten für jedes Element innerhalb des Arrays
Tabelle „ExampleTable_Invoices“:
| _id | ExampleTable_Invoices_dim1_idx | invoice_id | item | Preis | Discount |
|---|---|---|---|---|---|
| 1111 | 0 | 123 | toaster | 456 | 0.2 |
| 1111 | 1 | 124 | oven | 1235 | 0.2 |
| 2222 | 0 | 135 | fridge | 12543 | 0,0 |
Tabelle „ExampleTable_Ratings“:
| _id | ExampleTable_Ratings_dim1_idx | ExampleTable_Ratings |
|---|---|---|
| 1111 | 0 | 5 |
| 1111 | 1 | 6 |
| 2222 | 0 | 1 |
| 2222 | 1 | 2 |
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.