Zeilenänderungstransformation im Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
Verwenden Sie die Zeilenänderungstransformation, um Einfüge-, Lösch-, Aktualisierungs- und Upsertrichtlinien für Zeilen festzulegen. Sie können 1: n-Bedingungen als Ausdrücke hinzufügen. Diese Bedingungen müssen in der Reihenfolge ihrer Priorität angegeben werden, da jede Zeile mit der Richtlinie markiert wird, die dem ersten zutreffenden Ausdruck entspricht. Jede dieser Bedingungen kann dazu führen, dass für eine Zeile (oder für mehrere Zeilen) ein Einfüge-, Aktualisierungs-, Lösch- oder Upsertvorgang ausgeführt wird. Die Zeilenänderung kann sowohl DDL- als auch DML-Aktionen für Ihre Datenbank generieren.
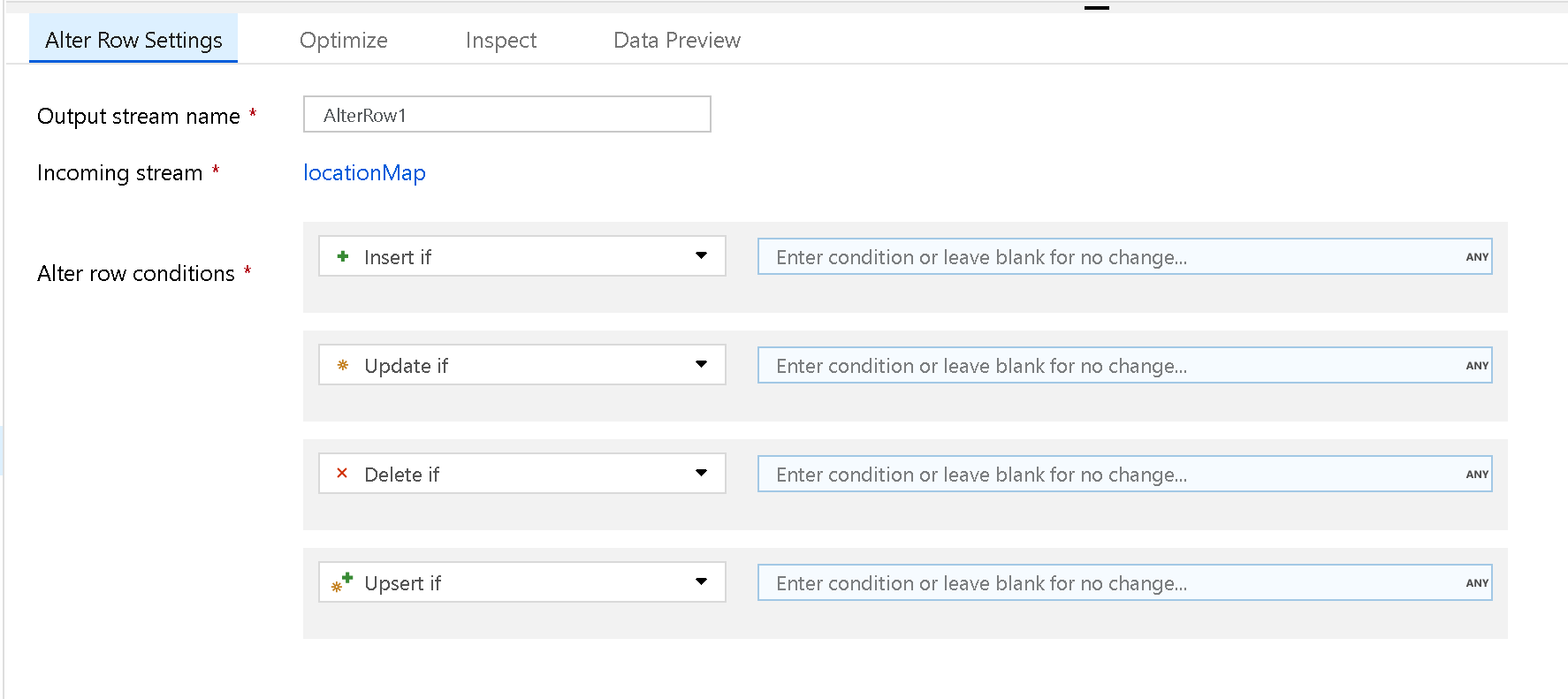
Zeilenänderungstransformationen können nur für Datenbank-, REST- oder Azure Cosmos DB-Senken in Ihrem Datenflow verwendet werden. Die Aktionen, die Sie Zeilen zuweisen (Einfügen, Aktualisieren, Löschen, Upsert), werden während Debugsitzungen nicht ausgeführt. Um die Richtlinien für Zeilenänderungen auf Ihre Datenbanktabellen anzuwenden, führen Sie eine Aktivität des Typs „Datenfluss ausführen“ in einer Pipeline aus.
Hinweis
Für Change Data Capture-Datenflüsse, die native CDC-Quellen wie SQL Server oder SAP verwenden, ist keine Zeilenänderungstransformation erforderlich. In diesen Fällen erkennt ADF automatisch die Zeilenmarkierung, sodass keine Zeilenänderungsrichtlinien erforderlich sind.
Angeben einer Standardzeilenrichtlinie
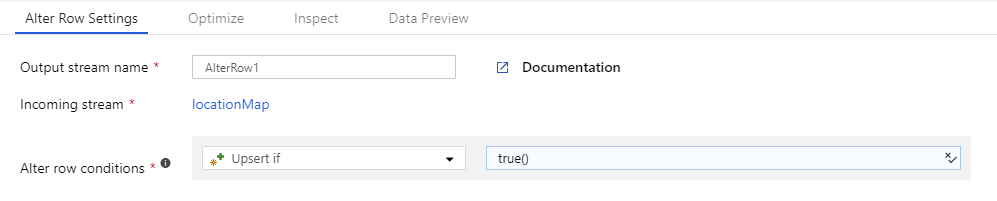
Erstellen Sie eine Zeilenänderungstransformation, und geben Sie eine Zeilenrichtlinie mit der Bedingung true() an. Jede Zeile, die mit keinem der zuvor definierten Ausdrücke übereinstimmt, wird für die angegebene Zeilenrichtlinie gekennzeichnet. Standardmäßig wird jede Zeile, die mit keinem bedingten Ausdruck übereinstimmt, für Insert gekennzeichnet.
Hinweis
Wenn Sie alle Zeilen mit einer Richtlinie kennzeichnen möchten, können Sie eine Bedingung für diese Richtlinie erstellen und true() als Bedingung angeben.
Anzeigen von Richtlinien in der Datenvorschau
Verwenden Sie den Debugmodus, um die Ergebnisse Ihrer Richtlinien für Zeilenänderungen im Datenvorschaubereich anzuzeigen. Eine Datenvorschau einer Zeilenänderungstransformation erzeugt keine DDL- oder DML-Aktionen für Ihr Ziel.
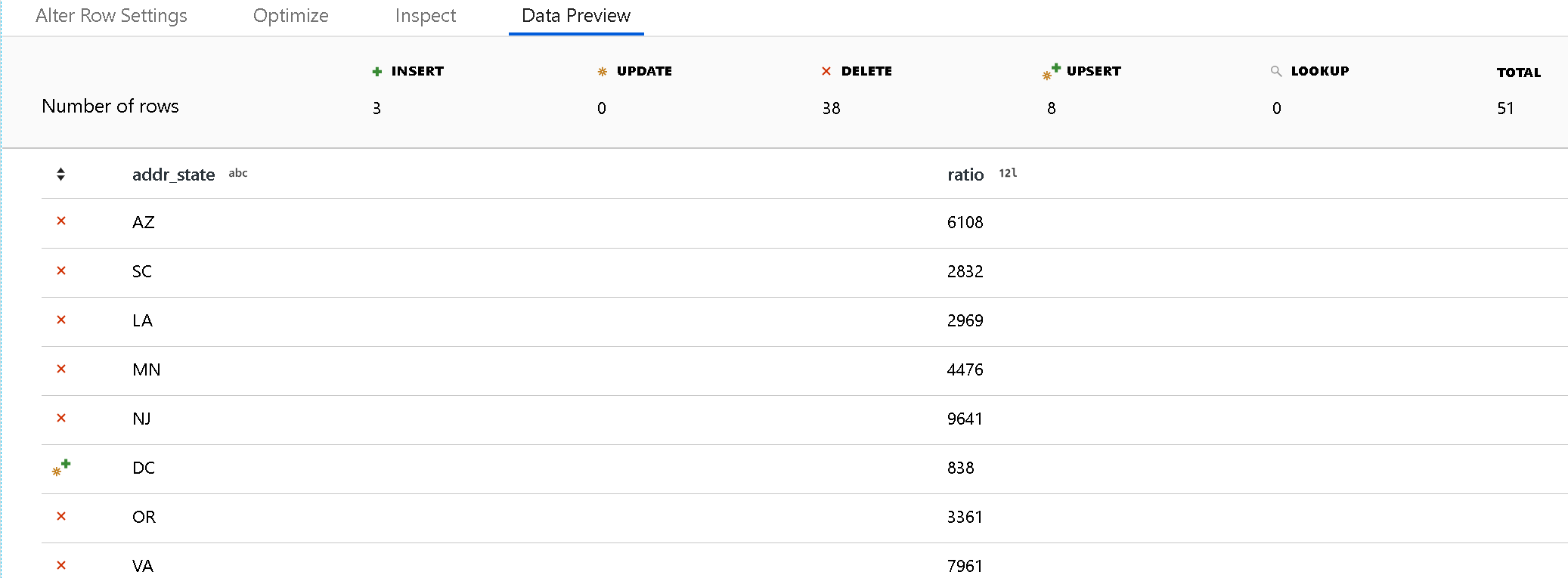
Ein Symbol für jede Richtlinie für Zeilenänderungen gibt an, ob eine Aktion des Typs „Einfügen“, „Aktualisieren“, „Upsert“ oder „Löschen“ ausgeführt wird. Die obere Kopfzeile zeigt, auf wie viele Zeilen sich die einzelnen Richtlinien in der Vorschau auswirken.
Zulassen von Richtlinien für Zeilenänderungen in der Senke
Damit die Richtlinien für Zeilenänderungen funktionieren, muss der Datenstrom in eine Datenbank oder eine Azure Cosmos DB-Senke schreiben. Aktivieren Sie auf der Registerkarte Einstellungen in Ihrer Senke, welche Richtlinien für Zeilenänderungen dafür zulässig sein sollen.
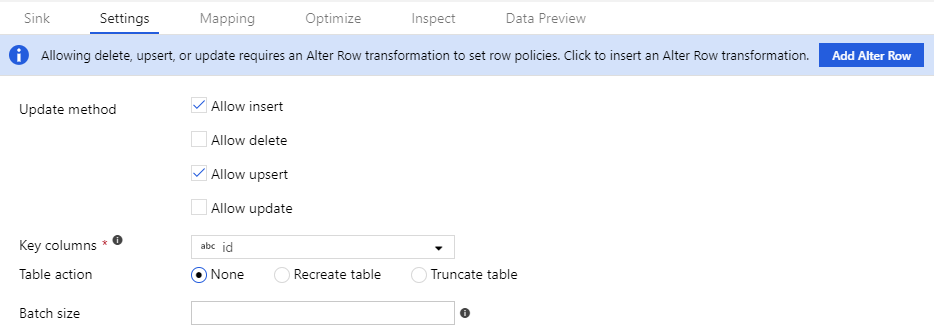
Das Standardverhalten besteht darin, dass nur Einfügevorgänge zugelassen werden. Sollen Aktualisierungs-, Upsert- oder Löschvorgänge zulässig sein, aktivieren Sie das Kontrollkästchen in der Senke, das dieser Bedingung entspricht. Wenn Aktualisierungs-, Upsert- oder Löschvorgänge aktiviert sind, müssen Sie angeben, welche Schlüsselspalten in der Senke abgeglichen werden sollen.
Hinweis
Falls das Schema der Zieltabelle in der Senke durch Ihre Einfüge-, Aktualisierungs- oder Upsertvorgänge geändert wurde, schlägt der Datenfluss fehl. Um das Zielschema in Ihrer Datenbank zu ändern, wählen Sie Tabelle neu erstellen als Tabellenaktion aus. Dadurch wird Ihre Tabelle verworfen und mit der neuen Schemadefinition neu erstellt.
Für die Senkentransformation ist entweder ein einzelner Schlüssel oder eine Reihe von Schlüsseln zur eindeutigen Zeilenidentifizierung in Ihrer Zieldatenbank erforderlich. Legen Sie für SQL-Senken die Schlüssel auf der Registerkarte „Senkeneinstellungen“ fest. Legen Sie für Azure CosmosDB den Partitionsschlüssel in den Einstellungen und außerdem das Azure CosmosDB-Systemfeld „ID“ in Ihrer Senkenzuordnung fest. Bei Azure Cosmos DB ist es zwingend erforderlich, die Systemspalte „ID“ bei Update-, Upsert- und Löschvorgängen mit einzubeziehen.
Zusammenführungen und Upserts mit Azure SQL Database und Azure Synapse
Data Flows unterstützt Zusammenführungen mit Azure SQL Database und Azure Synapse Database Pool (Data Warehouse) mit der Upsert-Option.
Sie könnten jedoch auf Szenarien stoßen, in denen Ihr Zieldatenbankschema die Identity-Eigenschaft von Schlüsselspalten verwendet. Der Dienst erfordert, dass Sie die Schlüssel identifizieren, die Sie verwenden, um die Zeilenwerte für Aktualisierungen und Upserts abzugleichen. Wenn jedoch für die Zielspalte die Identity-Eigenschaft festgelegt ist und Sie die Upsert-Richtlinie verwenden, erlaubt Ihnen die Zieldatenbank nicht, in die Spalte zu schreiben. Möglicherweise treten auch Fehler auf, wenn Sie versuchen, einen Upsert-Vorgang für die Verteilungsspalte einer verteilten Tabelle durchzuführen.
Hier sind die Möglichkeiten zur Behebung dieses Problems:
Wechseln Sie zu den Einstellungen für die Senkentransformation, und legen Sie „Skip writing key columns“ (Schreiben von Schlüsselspalten überspringen) fest. Dadurch wird der Dienst angewiesen, nicht in die Spalte, die Sie als Schlüsselwert für Ihre Zuordnung ausgewählt haben, zu schreiben.
Wenn diese Schlüsselspalte nicht diejenige Spalte ist, die das Problem bei Identitätsspalten verursacht, können Sie die SQL-Option für die Vorbearbeitung von Senkentransformationen verwenden:
SET IDENTITY_INSERT tbl_content ON. Deaktivieren Sie die Option dann mit der SQL-Eigenschaft für Nachverarbeitung:SET IDENTITY_INSERT tbl_content OFF.Sowohl bei der Identitäts- als auch der Verteilungsspalte können Sie Ihre Logik vom Upsert auf die Verwendung einer separaten Updatebedingung und einer separaten Einfügebedingung mithilfe einer Transformation für bedingtes Teilen umstellen. Auf diese Weise können Sie die Zuordnung für den Updatepfad so festlegen, dass die Schlüsselspaltenzuordnung ignoriert wird.
Datenflussskript
Syntax
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Beispiel
Das nachstehende Beispiel ist die Zeilenänderungstransformation CleanData, die aus dem eingehenden Stream SpecifyUpsertConditions drei Zeilenänderungsbedingungen erstellt. In der vorherigen Transformation wird die Spalte alterRowCondition berechnet, die bestimmt, ob eine Zeile in der Datenbank eingefügt, aktualisiert oder gelöscht werden soll oder nicht. Wenn die Spalte einen Zeichenfolgenwert enthält, der mit der Zeilenänderungsregel übereinstimmt, wird ihr diese Richtlinie zugewiesen.
In der Benutzeroberfläche sieht diese Transformation wie in der folgenden Abbildung aus:
Das Datenflussskript für diese Transformation befindet sich im folgenden Codeausschnitt:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Zugehöriger Inhalt
Nach der Zeilenänderungstransformation können Sie Ihre Daten in einen Zieldatenspeicher senken.