Das Parquet-Format in Azure Data Factory and Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Beachten Sie diesen Artikel, wenn Sie die Parquet-Dateien analysieren oder die Daten im Parquet-Format schreiben möchten.
Das Parquet-Format wird für folgende Connectors unterstützt:
- Amazon S3
- Amazon S3 Compatible Storage
- Azure-Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Dateisystem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Eine Liste der unterstützten Features für alle verfügbaren Connectors finden Sie im Artikel Übersicht über die Connectors in Azure Data Factory und Azure Synapse Analytics.
Verwendung der selbstgehosteten Integration Runtime
Wichtig
Wenn Sie bei Kopiervorgängen mithilfe einer selbstgehosteten Integration Runtime, z.B. zwischen lokalen Datenspeichern und der Cloud, Parquet-Dateien nicht unverändert kopieren, müssen Sie die 64-Bit-Version der JRE 8 (Java Runtime Environment), JDK 23 (Java Development Kit) oder OpenJDK auf Ihrem IR-Computer installieren. Weitere Details finden Sie im nächsten Absatz.
Für die Kopiervorgänge in der selbstgehosteten Integration Runtime mit Serialisierung/Deserialisierung von Parquet-Dateien sucht der Service die Java Runtime Environment, indem es zunächst die Registrierung (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) auf JRE überprüft. Wird diese nicht gefunden, wird im nächsten Versuch die Systemvariable JAVA_HOME auf OpenJDK überprüft.
- Für JRE: Die 64-Bit-Integration Runtime erfordert die 64-Bit-JRE. Diese steht hier zur Verfügung.
- Zur Verwendung von JDK: Der 64-Bit-IR erfordert 64-Bit JDK 23. Diese steht hier zur Verfügung. Aktualisieren Sie unbedingt die
JAVA_HOME-Systemvariable auf den Stammordner der JDK 23-Installation, d. h.C:\Program Files\Java\jdk-23, und fügen Sie den Pfad sowohl zu den Ordnern „C:\Program Files\Java\jdk-23\bin“ als auch „C:\Program Files\Java\jdk-23\bin\server“ derPath-Systemvariablen hinzu. - Für OpenJDK: Die Unterstützung ist seit der IR-Version 3.13 verfügbar. Packen Sie jvm.dll zusammen mit allen anderen erforderlichen Aufstellungen von OpenJDK auf den Rechner von Self-hosted IR und setzen Sie die Systemumgebungsvariable JAVA_HOME entsprechend und starten Sie dann Self-hosted IR neu, damit sie sofort wirksam wird. Informationen zum Herunterladen des Microsoft Build of OpenJDK finden Sie unter Microsoft Build of OpenJDK™.
Tipp
Wenn Sie Daten mit der selbstgehosteten Integration Runtime in das/aus dem Parquet-Format kopieren und ein Fehler mit dem Text „Fehler beim Aufrufen von Java, Meldung: java.lang.OutOfMemoryError:Java-Heapspeicher“ auftritt, können Sie auf dem Computer, auf dem sich die selbstgehosteten IR befindet, eine Umgebungsvariable _JAVA_OPTIONS hinzufügen, um die min./max. Heapgröße für JVM anzupassen, sodass eine solche Kopie möglich ist, und dann die Pipeline erneut ausführen.
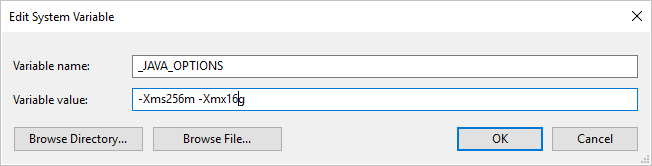
Beispiel: Legen Sie für die Variable _JAVA_OPTIONS den Wert -Xms256m -Xmx16g fest. Das Flag Xms gibt den anfänglichen Speicherzuweisungspool für eine Java Virtual Machine (JVM) an, während Xmx den maximalen Speicherzuweisungspool angibt. Das bedeutet, dass die JVM mit einer Speichergröße von Xms gestartet wird und eine maximale Speichergröße von Xmx verwenden kann. Standardmäßig verwendet der Dienst mindestens 64 MB und maximal 1G.
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der vom Parquet-Dataset unterstützten Eigenschaften.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft des Datasets muss auf Parquet festgelegt werden. | Ja |
| location | Speicherorteinstellungen der Datei(en) Jeder dateibasierte Connector verfügt unter location über seinen eigenen Speicherorttyp und unterstützte Eigenschaften. Informationen hierzu finden Sie im Abschnitt > „Dataset-Eigenschaften“ des Artikels über Connectors. |
Ja |
| compressionCodec | Der Codec für die Komprimierung, der beim Schreiben in Parquet-Dateien verwendet werden soll. Beim Lesen aus Parquet-Dateien bestimmen Data Factorys den Codec für die Komprimierung automatisch anhand der Dateimetadaten. Unterstützte Typen sind „none“, „gzip“, „snappy“ (Standard) und „lzo“. Hinweis: LZO wird derzeit von der Kopieraktivität nicht für das Lesen/Schreiben von Parquet-Dateien unterstützt. |
Nein |
Hinweis
Ein Leerzeichen im Spaltennamen wird für Parquet-Dateien nicht unterstützt.
Nachfolgend sehen Sie das Beispiel eines Parquet-Datasets in Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Parquet-Quelle und -Senke unterstützt werden.
Parquet als Quelle
Die folgenden Eigenschaften werden im Abschnitt *source* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft der Quelle der Kopieraktivität muss auf ParquetSource festgelegt werden. | Ja |
| storeSettings | Eine Gruppe von Eigenschaften für das Lesen von Daten aus einem Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Leseeinstellungen. Informationen hierzu finden Sie im Abschnitt über die >Eigenschaften der Copy-Aktivität im Artikel über Connectors. |
Nein |
Parquet als Senke
Die folgenden Eigenschaften werden im Abschnitt *sink* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft der Senke der Kopieraktivität muss auf ParquetSink festgelegt werden. | Ja |
| formatSettings | Eine Gruppe von Eigenschaften. Weitere Informationen zu Parquet-Schreibeinstellungen finden Sie in der Tabelle unten. | Nein |
| storeSettings | Eine Gruppe von Eigenschaften für das Schreiben von Daten in einen Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Schreibeinstellungen. Informationen hierzu finden Sie im Abschnitt über die >Eigenschaften der Copy-Aktivität im Artikel über Connectors. |
Nein |
Unterstützte Parquet-Schreibeinstellungen unter formatSettings:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Der Typ von „formatSettings“ muss auf ParquetWriteSettings festgelegt werden. | Ja |
| maxRowsPerFile | Wenn Sie Daten in einen Ordner schreiben, können Sie in mehrere Dateien zu schreiben und die maximale Anzahl von Zeilen pro Datei angeben. | Nein |
| fileNamePrefix | Gilt, wenn maxRowsPerFile konfiguriert ist.Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt: <fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft findet keine Anwendung, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist. |
Nein |
Eigenschaften von Mapping Data Flow
Bei Zuordnungsdatenflüssen können Sie in den folgenden Datenspeichern das Parquet-Format lesen und schreiben: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 und SFTP. Darüber hinaus können Sie das Parquet-Format in Amazon S3 lesen.
Quelleigenschaften
In der folgenden Tabelle sind die von einer Parquet-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss parquet sein |
ja | parquet |
format |
| Platzhalterpfade | Alle Dateien, die dem Platzhalterpfad entsprechen, werden verarbeitet. Überschreibt den Ordner und den Dateipfad, die im Dataset festgelegt sind. | nein | String[] | wildcardPaths |
| Partitionsstammpfad | Für partitionierte Dateidaten können Sie einen Partitionsstammpfad eingeben, um partitionierte Ordner als Spalten zu lesen. | nein | String | partitionRootPath |
| Liste mit den Dateien | Gibt an, ob Ihre Quelle auf eine Textdatei verweist, in der die zu verarbeitenden Dateien aufgelistet sind. | nein | true oder false |
fileList |
| Spalte, in der der Dateiname gespeichert wird | Erstellt eine neue Spalte mit dem Namen und Pfad der Quelldatei. | nein | String | rowUrlColumn |
| Nach Abschluss | Löscht oder verschiebt die Dateien nach der Verarbeitung. Dateipfad beginnt mit dem Containerstamm | nein | Löschen: true oder false Verschieben: [<from>, <to>] |
purgeFiles moveFiles |
| Nach der letzten Änderung filtern | Filtern Sie Dateien nach dem Zeitpunkt ihrer letzten Änderung. | nein | Zeitstempel | modifiedAfter modifiedBefore |
| Finden keiner Dateien zulässig | „true“ gibt an, dass kein Fehler ausgelöst wird, wenn keine Dateien gefunden werden. | nein | true oder false |
ignoreNoFilesFound |
Quellbeispiel
Das folgende Bild ist ein Beispiel für eine Parquet-Quellkonfiguration bei Zuordnungsdatenflüssen.
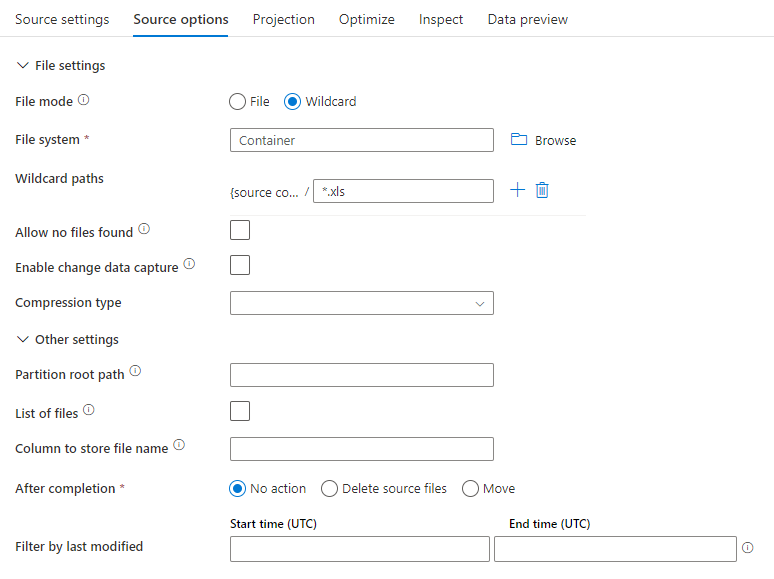
Das zugehörige Datenflussskript ist:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Senkeneigenschaften
In der folgenden Tabelle sind die von einer Parquet-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss parquet sein |
ja | parquet |
format |
| Ordner löschen | Wenn der Zielordner vor dem Schreiben gelöscht wird. | nein | true oder false |
truncate |
| Dateinamenoption | Das Namensformat der geschriebenen Daten. Standardmäßig eine Datei pro Partition im Format part-#####-tid-<guid>. |
Nein | Muster: Zeichenfolge Pro Partition: Zeichenfolge[] Als Daten in Spalte: Zeichenfolge Ausgabe in eine einzelne Datei: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Senkenbeispiel
Das folgende Bild ist ein Beispiel für eine Parquet-Senkenkonfiguration bei Zuordnungsdatenflüssen.
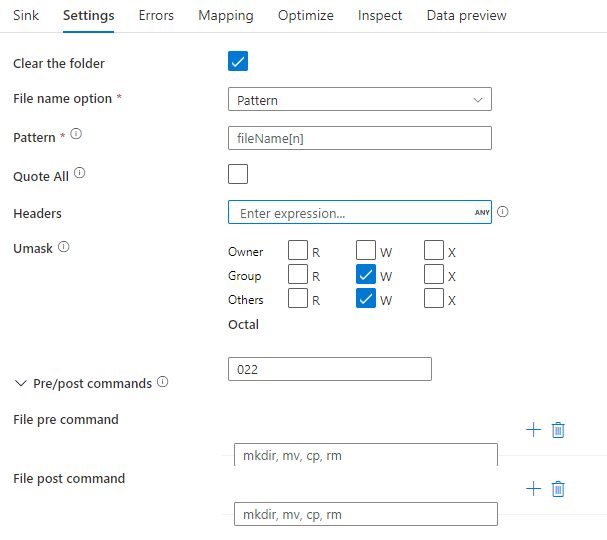
Das zugehörige Datenflussskript ist:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Datentypunterstützung
Komplexe Parquet-Datentypen (z. B. MAP, LIST, STRUCT) werden derzeit nur in Datenflüssen, aber nicht in der Kopieraktivität unterstützt. Wenn Sie komplexe Typen in Datenflüssen verwenden möchten, importieren Sie das Dateischema nicht in das Dataset und lassen das Schema im Dataset leer. Importieren Sie dann die Projektion in die Quelltransformation.