Migrieren von Daten aus Amazon S3 zu Azure Data Lake Storage Gen2
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Verwenden Sie die Vorlagen, um Petabytes an Daten mit mehreren hundert Millionen Dateien von Amazon S3 zu Azure Data Lake Storage Gen2 zu migrieren.
Hinweis
Wenn Sie eine kleine Datenmenge (beispielsweise weniger als 10 TB) von AWS S3 zu Azure migrieren möchten, ist es effizienter und einfacher, das Azure Data Factory-Tool zum Kopieren von Daten zu verwenden. Die in diesem Artikel beschriebene Vorlage ist für Ihre Zwecke umfangreicher als notwendig.
Informationen zu den Lösungsvorlagen
Die Datenpartition ist besonders zu empfehlen, wenn mehr als 10 TB an Daten migriert werden. Nutzen Sie zum Partitionieren der Daten die Einstellung „Präfix“, um die Ordner und Dateien in Amazon S3 nach Name zu filtern. So kann dann mit jedem ADF-Kopierauftrag jeweils eine Partition kopiert werden. Sie können mehrere ADF-Kopieraufträge gleichzeitig ausführen, um einen besseren Durchsatz zu erzielen.
Für die Datenmigration müssen in der Regel einmalig historische Daten migriert und anschließend regelmäßig Änderungen in AWS S3 mit Azure synchronisiert werden. Nachfolgend werden zwei Vorlagen beschrieben: Mit einer Vorlage wird die einmalige Migration historischer Daten und mit der anderen Vorlage die Synchronisierung der Änderungen in AWS S3 mit Azure ausgeführt.
So migrieren Sie mit der Vorlage historische Daten aus Amazon S3 zu Azure Data Lake Storage Gen2
Bei dieser Vorlage (Vorlagenname: migrate historical data from AWS S3 to Azure Data Lake Storage Gen2) wird davon ausgegangen, dass Sie eine Partitionsliste in einer externen Steuertabelle in Azure SQL-Datenbank geschrieben haben. Sie verwendet daher eine Lookup-Aktivität zum Abrufen der Partitionsliste aus der externen Steuertabelle, durchläuft jede Partition und kopiert dann mit jedem ADF-Kopierauftrag jeweils eine Partition. Nach Abschluss eines Kopierauftrags wird die Aktivität Gespeicherte Prozedur verwendet, um den Status des Kopiervorgangs für jede Partition in der Steuertabelle zu aktualisieren.
Die Vorlage enthält fünf Aktivitäten:
- Lookup ruft die Partitionen ab, die noch nicht aus einer externen Steuertabelle in Azure Data Lake Storage Gen2 kopiert wurden. Der Tabellenname lautet s3_partition_control_table und die Abfrage zum Laden von Daten aus der Tabelle "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0" .
- ForEach ruft die Partitionsliste aus der Lookup-Aktivität ab und durchläuft jede Partition für die TriggerCopy-Aktivität. Sie können einen Wert für batchCount festlegen, um mehrere ADF-Kopieraufträge gleichzeitig auszuführen. In dieser Vorlage wurde 2 festgelegt.
- ExecutePipeline führt die Pipeline CopyFolderPartitionFromS3 aus. Die zusätzliche Pipeline, die dafür sorgt, dass bei jedem Kopierauftrag eine Partition kopiert wird, wird hinzugefügt, um den nicht erfolgreichen Kopierauftrag mühelos erneut ausführen und so die spezifische Partition erneut aus AWS S3 laden zu können. Alle anderen Kopieraufträge, bei denen andere Partitionen geladen werden, werden nicht beeinträchtigt.
- Mit der Copy-Aktivität wird jede Partition aus AWS S3 in Azure Data Lake Storage Gen2 kopiert.
- SqlServerStoredProcedure aktualisiert den Status des Kopiervorgangs für jede Partition in der Steuertabelle.
Die Vorlage enthält zwei Parameter:
- AWS_S3_bucketName ist der Name des Buckets in AWS S3, aus dem Daten migriert werden sollen. Wenn Sie Daten aus mehreren Buckets in AWS S3 migrieren möchten, können Sie in Ihrer externen Steuertabelle eine weitere Spalte hinzufügen, um den Bucketnamen für jede Partition zu speichern, und darüber hinaus Ihre Pipeline aktualisieren, um Daten aus dieser Spalte abzurufen.
- Azure_Storage_fileSystem ist der Name des Dateisystems in Azure Data Lake Storage Gen2, in das Sie Daten migrieren möchten.
So kopieren Sie mit der Vorlage nur geänderte Dateien aus Amazon S3 in Azure Data Lake Storage Gen2
Diese Vorlage (Vorlagenname: copy delta data from AWS S3 to Azure Data Lake Storage Gen2) verwendet den LastModifiedTime-Wert jeder Datei, um nur die neuen oder aktualisierten Dateien aus AWS S3 in Azure zu kopieren. Beachten Sie Folgendes: Wenn die Datei- oder Ordnernamen in AWS S3 Zeitangaben zur zeitlichen Partitionierung enthalten (Beispiel: /jjjj/mm/tt/Datei.csv), finden Sie in diesem Tutorial Informationen zu einer leistungsfähigeren Methode zum inkrementellen Laden neuer Dateien. Diese Vorlage setzt voraus, dass Sie eine Partitionsliste in einer externen Steuertabelle in Azure SQL-Datenbank geschrieben haben. Sie verwendet daher eine Lookup-Aktivität zum Abrufen der Partitionsliste aus der externen Steuertabelle, durchläuft jede Partition und kopiert dann mit jedem ADF-Kopierauftrag jeweils eine Partition. Wenn der Kopierauftrag mit dem Kopieren der Dateien aus AWS S3 beginnt, werden anhand der Eigenschaft „LastModifiedTime“ nur die neuen oder aktualisierten Dateien ermittelt und kopiert. Nach Abschluss eines Kopierauftrags wird die Aktivität Gespeicherte Prozedur verwendet, um den Status des Kopiervorgangs für jede Partition in der Steuertabelle zu aktualisieren.
Die Vorlage enthält sieben Aktivitäten:
- Lookup ruft die Partitionen aus einer externen Steuertabelle ab. Der Tabellenname lautet s3_partition_delta_control_table und die Abfrage zum Laden von Daten aus der Tabelle "select distinct PartitionPrefix from s3_partition_delta_control_table" .
- ForEach ruft die Partitionsliste aus der Lookup-Aktivität ab und durchläuft jede Partition für die TriggerDeltaCopy-Aktivität. Sie können einen Wert für batchCount festlegen, um mehrere ADF-Kopieraufträge gleichzeitig auszuführen. In dieser Vorlage wurde 2 festgelegt.
- ExecutePipeline führt die Pipeline DeltaCopyFolderPartitionFromS3 aus. Die zusätzliche Pipeline, die dafür sorgt, dass bei jedem Kopierauftrag eine Partition kopiert wird, wird hinzugefügt, um den nicht erfolgreichen Kopierauftrag mühelos erneut ausführen und so die spezifische Partition erneut aus AWS S3 laden zu können. Alle anderen Kopieraufträge, bei denen andere Partitionen geladen werden, werden nicht beeinträchtigt.
- Mit der Lookup-Aktivität wird der Zeitpunkt der letzten Ausführung des Kopierauftrags aus der externen Steuertabelle abgerufen, damit die neuen oder aktualisierten Dateien anhand von „LastModifiedTime“ ermittelt werden können. Der Tabellenname lautet s3_partition_delta_control_table und die Abfrage zum Laden von Daten aus der Tabelle "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1" .
- Mit der Copy-Aktivität werden nur neue oder geänderte Dateien für jede Partition aus AWS S3 in Azure Data Lake Storage Gen2 kopiert. Die Eigenschaft modifiedDatetimeStart wird auf den Zeitpunkt der letzten Ausführung des Kopierauftrags festgelegt. Die Eigenschaft modifiedDatetimeEnd wird auf den Zeitpunkt der aktuellen Ausführung des Kopierauftrags festgelegt. Beachten Sie, dass für den Zeitpunkt die UTC-Zeitzone gilt.
- SqlServerStoredProcedure aktualisiert bei erfolgreicher Ausführung den Status des Kopiervorgangs für jede Partition und den Ausführungszeitpunkt des Kopiervorgangs in der Steuertabelle. Die Spalte „SuccessOrFailure“ wird auf 1 festgelegt.
- SqlServerStoredProcedure aktualisiert bei fehlerhafter Ausführung den Status des Kopiervorgangs für jede Partition und den Ausführungszeitpunkt des Kopiervorgangs in der Steuertabelle. Die Spalte „SuccessOrFailure“ wird auf 0 festgelegt.
Die Vorlage enthält zwei Parameter:
- AWS_S3_bucketName ist der Name des Buckets in AWS S3, aus dem Daten migriert werden sollen. Wenn Sie Daten aus mehreren Buckets in AWS S3 migrieren möchten, können Sie in Ihrer externen Steuertabelle eine weitere Spalte hinzufügen, um den Bucketnamen für jede Partition zu speichern, und darüber hinaus Ihre Pipeline aktualisieren, um Daten aus dieser Spalte abzurufen.
- Azure_Storage_fileSystem ist der Name des Dateisystems in Azure Data Lake Storage Gen2, in das Sie Daten migrieren möchten.
Informationen zur Verwendung dieser beiden Lösungsvorlagen
So migrieren Sie mit der Vorlage historische Daten aus Amazon S3 zu Azure Data Lake Storage Gen2
Erstellen Sie in Azure SQL-Datenbank eine Steuertabelle zum Speichern der Partitionsliste von AWS S3.
Hinweis
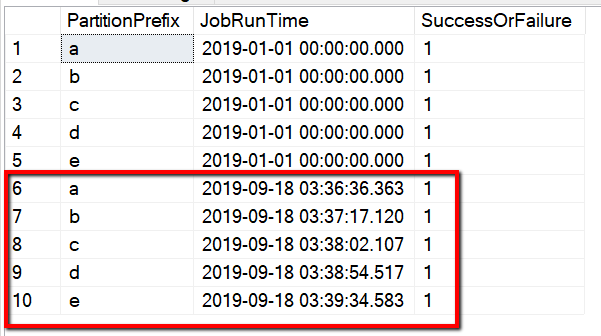
Der Tabellenname lautet „s3_partition_control_table“. Das Schema der Steuertabelle lautet „PartitionPrefix“ und „SuccessOrFailure“. „PartitionPrefix“ ist die Präfixeinstellung in S3 zum Filtern der Ordner und Dateien in Amazon S3 nach Name, und „SuccessOrFailure“ ist der Status des Kopiervorgangs für jede Partition: 0 bedeutet, dass diese Partition nicht in Azure kopiert wurde, und 1 bedeutet, dass diese Partition erfolgreich in Azure kopiert wurde. In der Steuertabelle sind fünf Partitionen definiert, und der Standardstatus des Kopiervorgangs für die einzelnen Partitionen lautet 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Erstellen Sie eine gespeicherte Prozedur in derselben Azure SQL-Datenbank-Instanz für die Steuertabelle.
Hinweis
Der Name der gespeicherten Prozedur lautet „sp_update_partition_success“. Sie wird von der Aktivität „SqlServerStoredProcedure“ in Ihrer ADF-Pipeline aufgerufen.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOWechseln Sie zur Vorlage Migrate historical data from AWS S3 to Azure Data Lake Storage Gen2. Geben Sie die Verbindungen mit der externen Steuertabelle, AWS S3 als Datenquellenspeicher und Azure Data Lake Storage Gen2 als Zielspeicher ein. Achten Sie darauf, dass die externe Steuertabelle und die gespeicherte Prozedur auf dieselbe Verbindung verweisen.
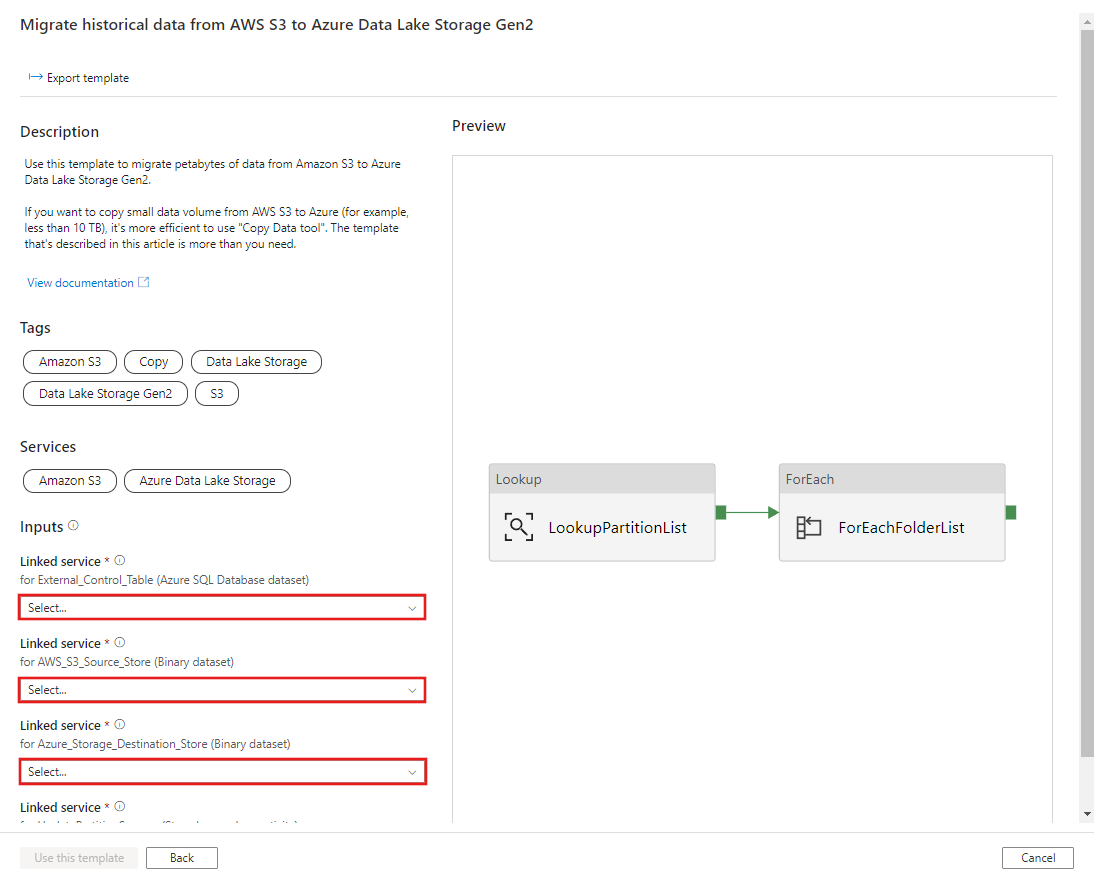
Klicken Sie auf Diese Vorlage verwenden.
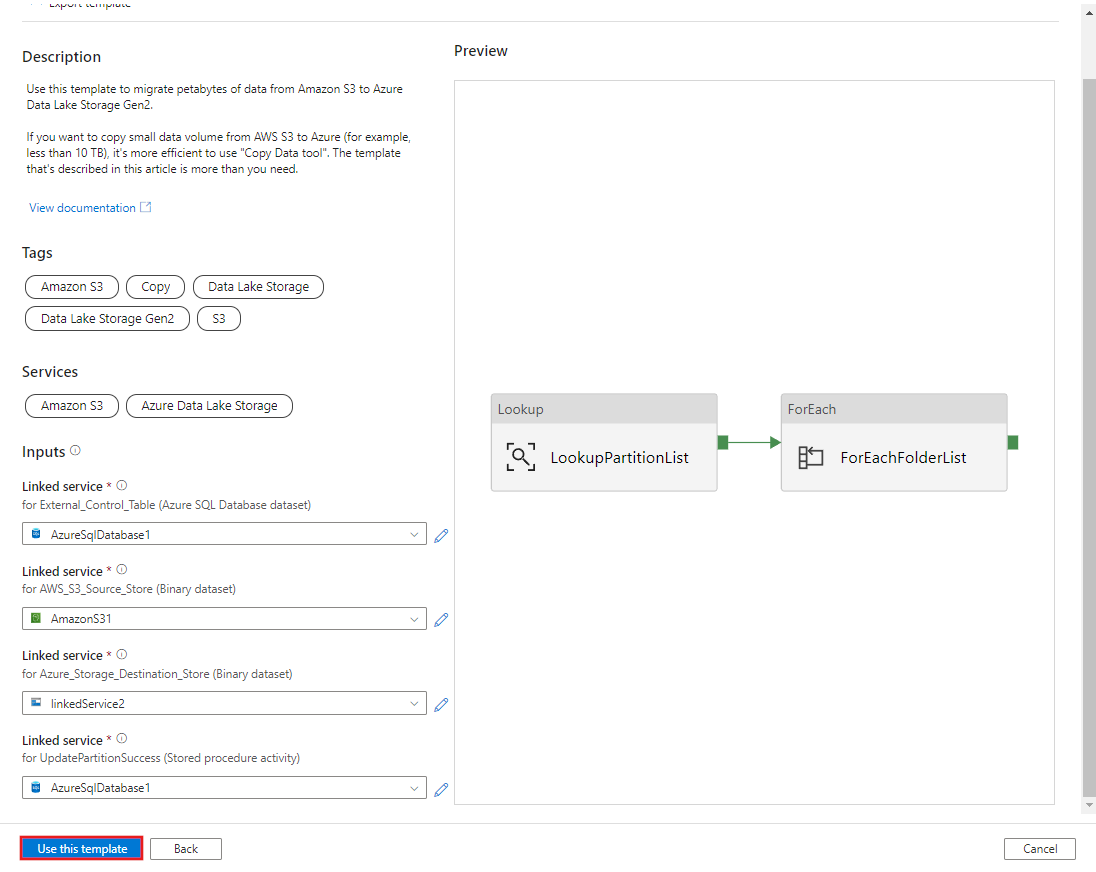
Im folgenden Beispiel sehen Sie, dass zwei Pipelines und drei Datasets erstellt wurden:
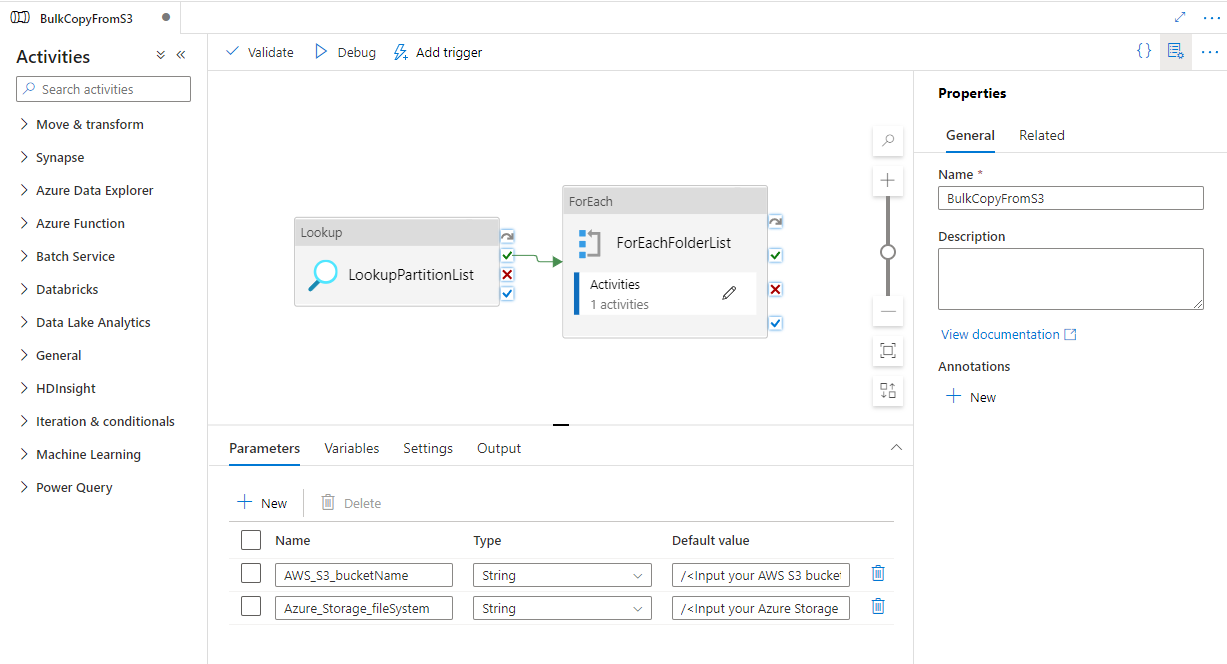
Wechseln Sie zur Pipeline „BulkCopyFromS3“, wählen Sie Debug aus, und geben Sie die Parameter ein. Wählen Sie Fertig stellen aus.
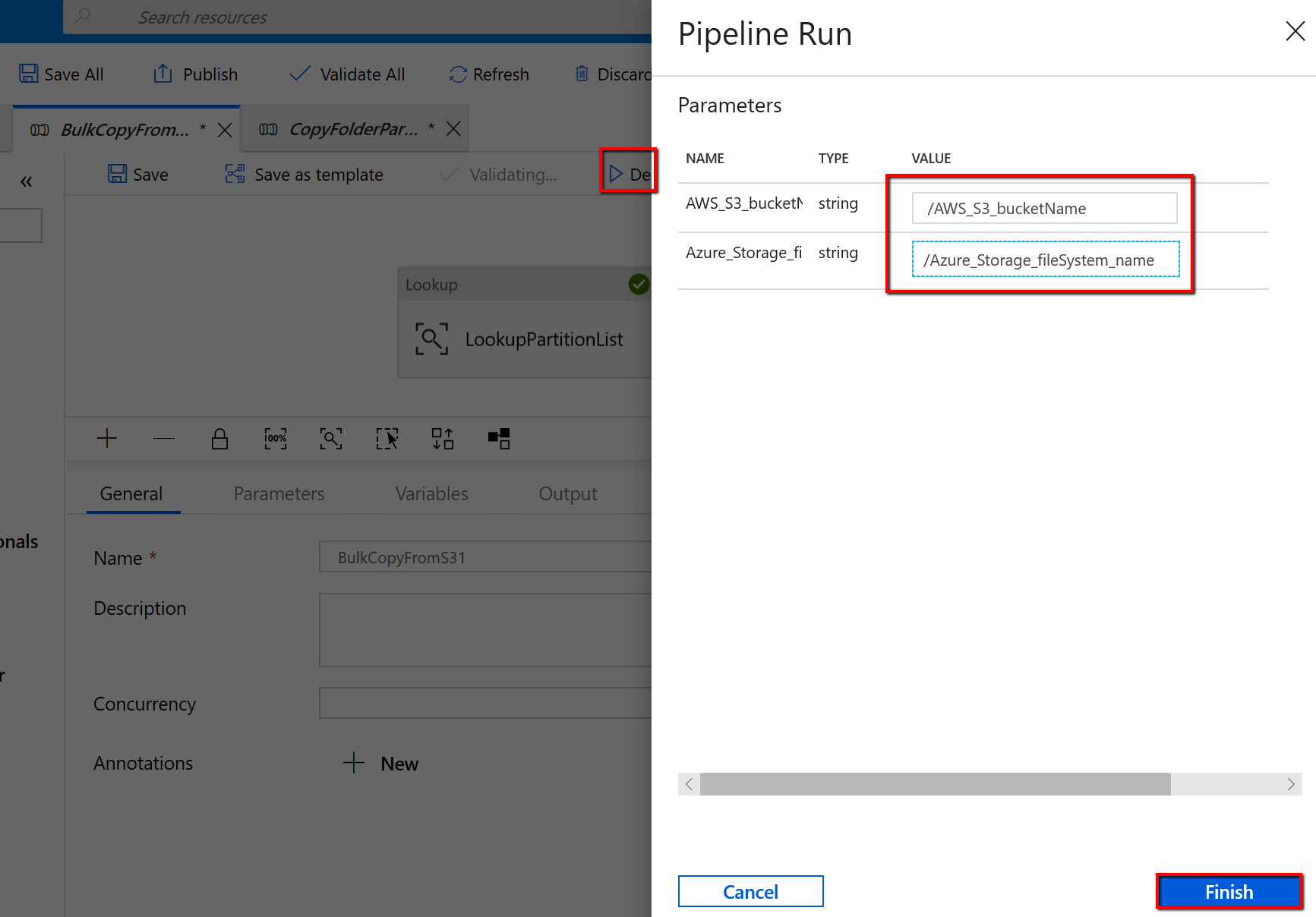
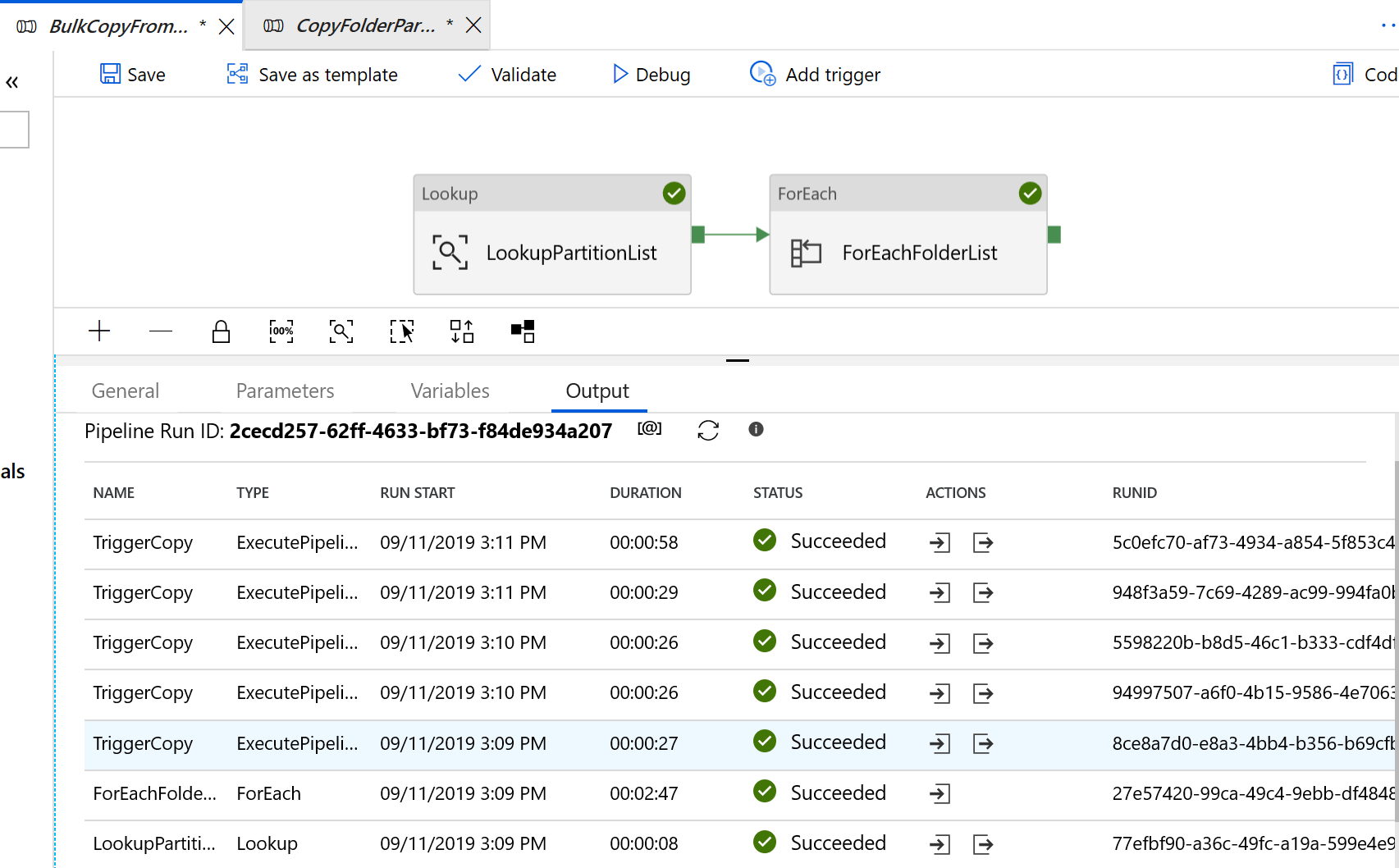
Ihnen werden Ergebnisse angezeigt, die dem folgenden Beispiel ähneln:
So kopieren Sie mit der Vorlage nur geänderte Dateien aus Amazon S3 in Azure Data Lake Storage Gen2
Erstellen Sie in Azure SQL-Datenbank eine Steuertabelle zum Speichern der Partitionsliste von AWS S3.
Hinweis
Der Tabellenname lautet „s3_partition_delta_control_table“. Das Schema der Steuertabelle lautet „PartitionPrefix“, „JobRunTime“ und „SuccessOrFailure“. „PartitionPrefix“ ist die Präfixeinstellung in S3 zum Filtern der Ordner und Dateien in Amazon S3 nach Name, „JobRunTime“ ist der DateTime-Wert für die Ausführung von Kopieraufträgen, und „SuccessOrFailure“ ist der Status des Kopiervorgangs für jede Partition: 0 bedeutet, dass diese Partition nicht in Azure kopiert wurde, und 1 bedeutet, dass diese Partition erfolgreich in Azure kopiert wurde. In der Steuertabelle sind fünf Partitionen definiert. Als Standardwert für „JobRunTime“ kann die Zeit festgelegt werden, zu der die einmalige Migration der historischen Daten beginnt. Die ADF-Kopieraktivität kopiert die Dateien in AWS S3, die nach diesem Zeitpunkt zuletzt geändert wurden. Der Standardstatus zum Kopieren der einzelnen Partitionen ist 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Erstellen Sie eine gespeicherte Prozedur in derselben Azure SQL-Datenbank-Instanz für die Steuertabelle.
Hinweis
Der Name der gespeicherten Prozedur lautet „sp_insert_partition_JobRunTime_success“. Sie wird von der Aktivität „SqlServerStoredProcedure“ in Ihrer ADF-Pipeline aufgerufen.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOWechseln Sie zur Vorlage Copy delta data from AWS S3 to Azure Data Lake Storage Gen2. Geben Sie die Verbindungen mit der externen Steuertabelle, AWS S3 als Datenquellenspeicher und Azure Data Lake Storage Gen2 als Zielspeicher ein. Achten Sie darauf, dass die externe Steuertabelle und die gespeicherte Prozedur auf dieselbe Verbindung verweisen.
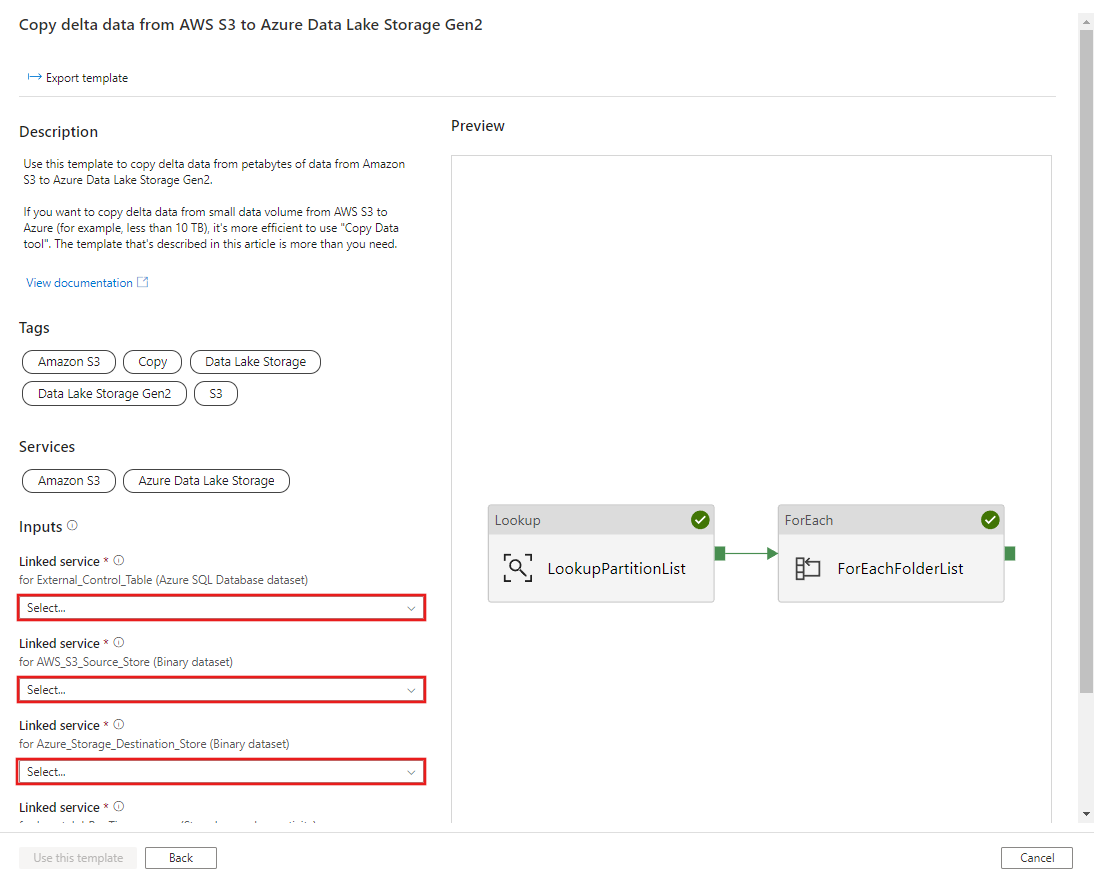
Klicken Sie auf Diese Vorlage verwenden.
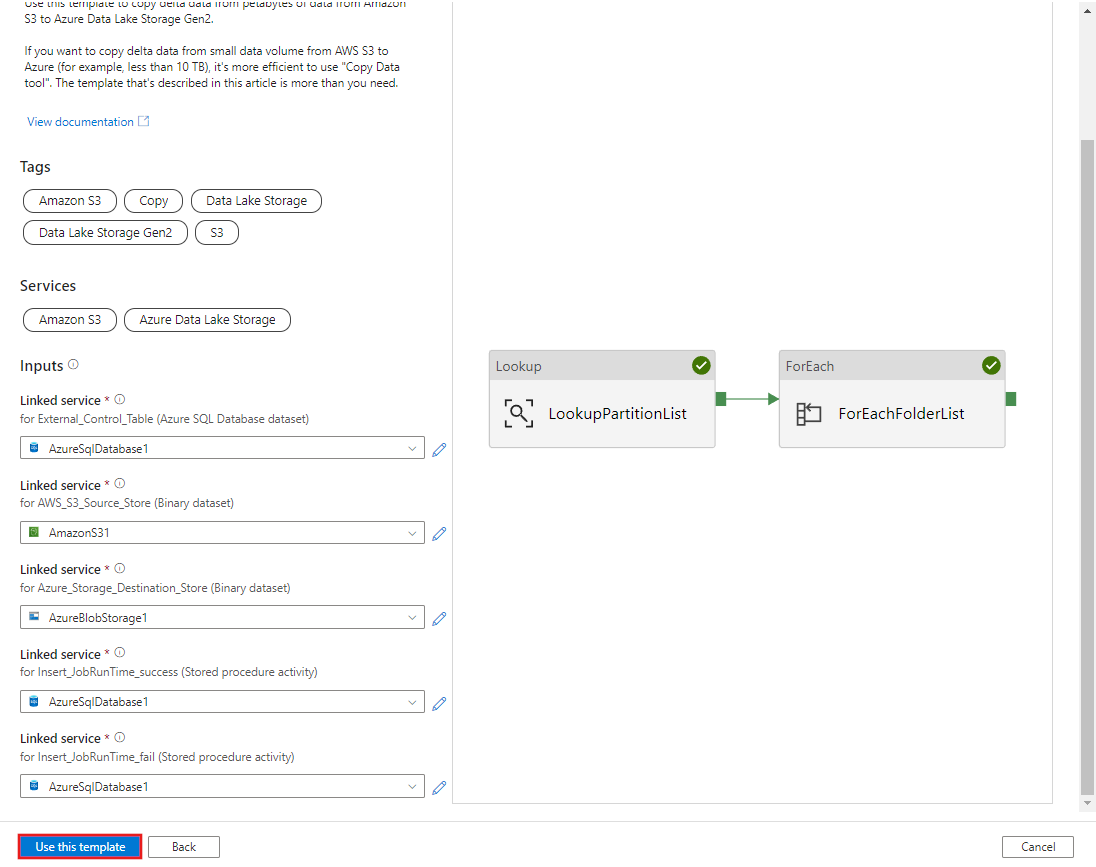
Im folgenden Beispiel sehen Sie, dass zwei Pipelines und drei Datasets erstellt wurden:
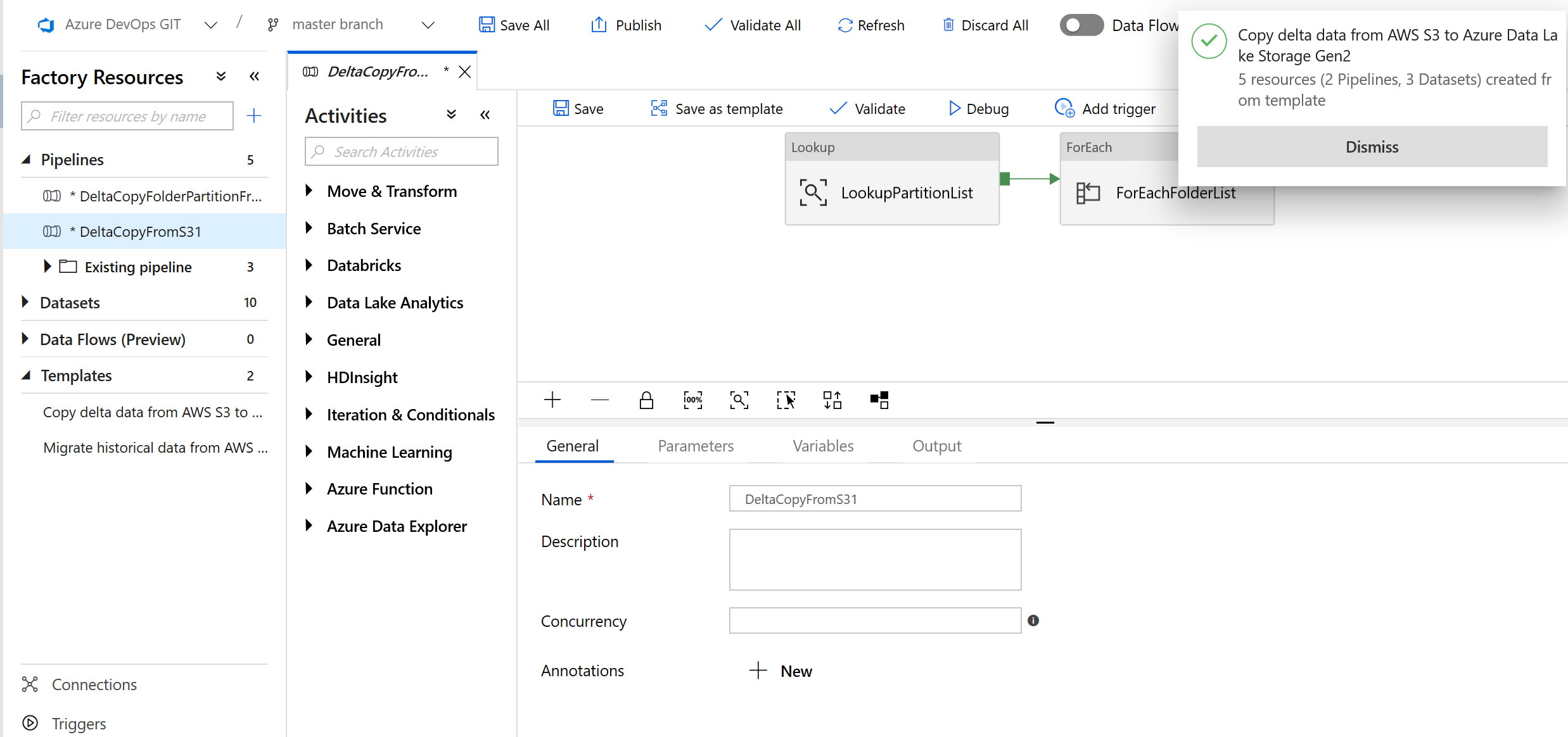
Wechseln Sie zur Pipeline „DeltaCopyFromS3“, wählen Sie Debug aus, und geben Sie die Parameter ein. Wählen Sie Fertig stellen aus.
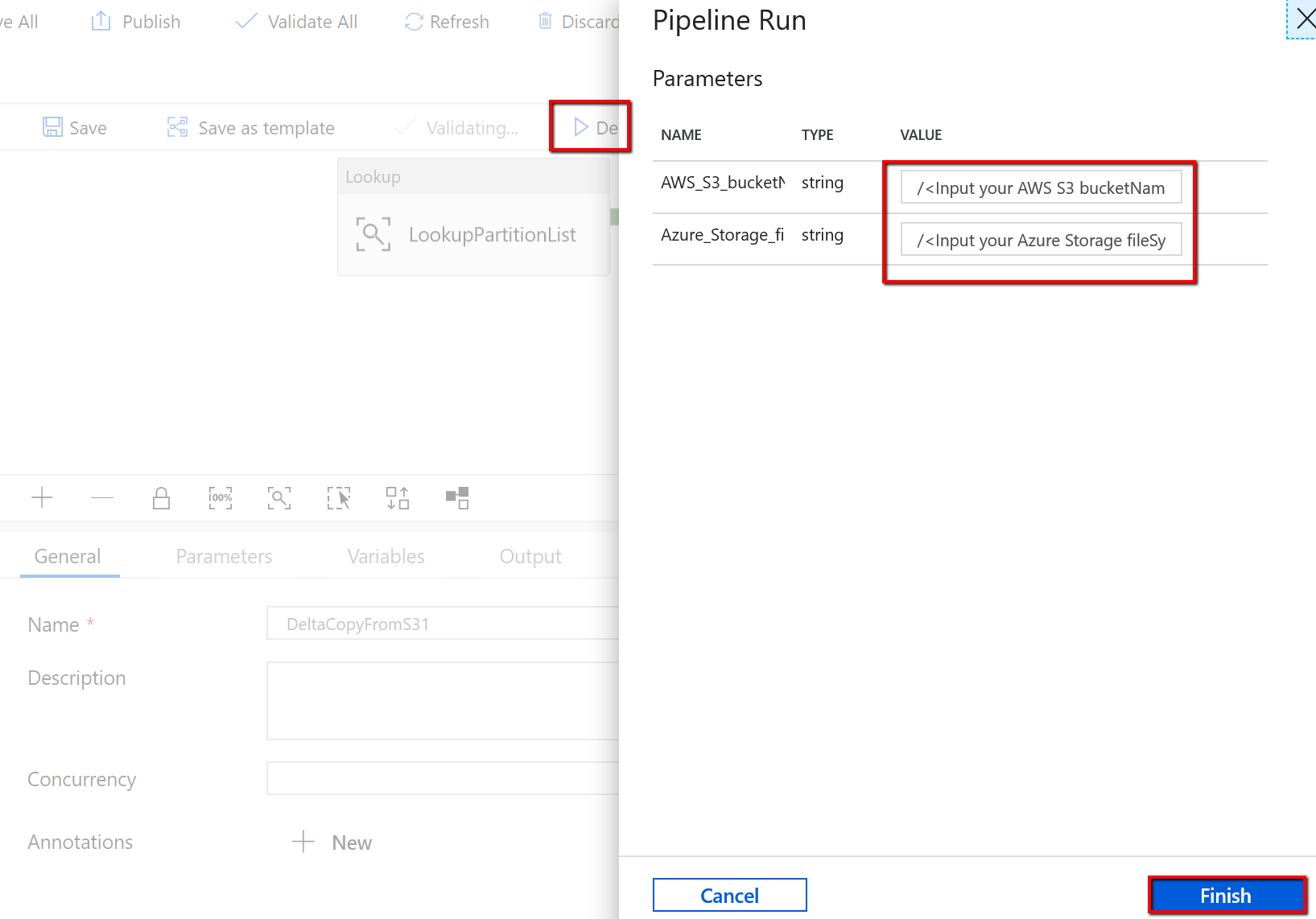
Ihnen werden Ergebnisse angezeigt, die dem folgenden Beispiel ähneln:
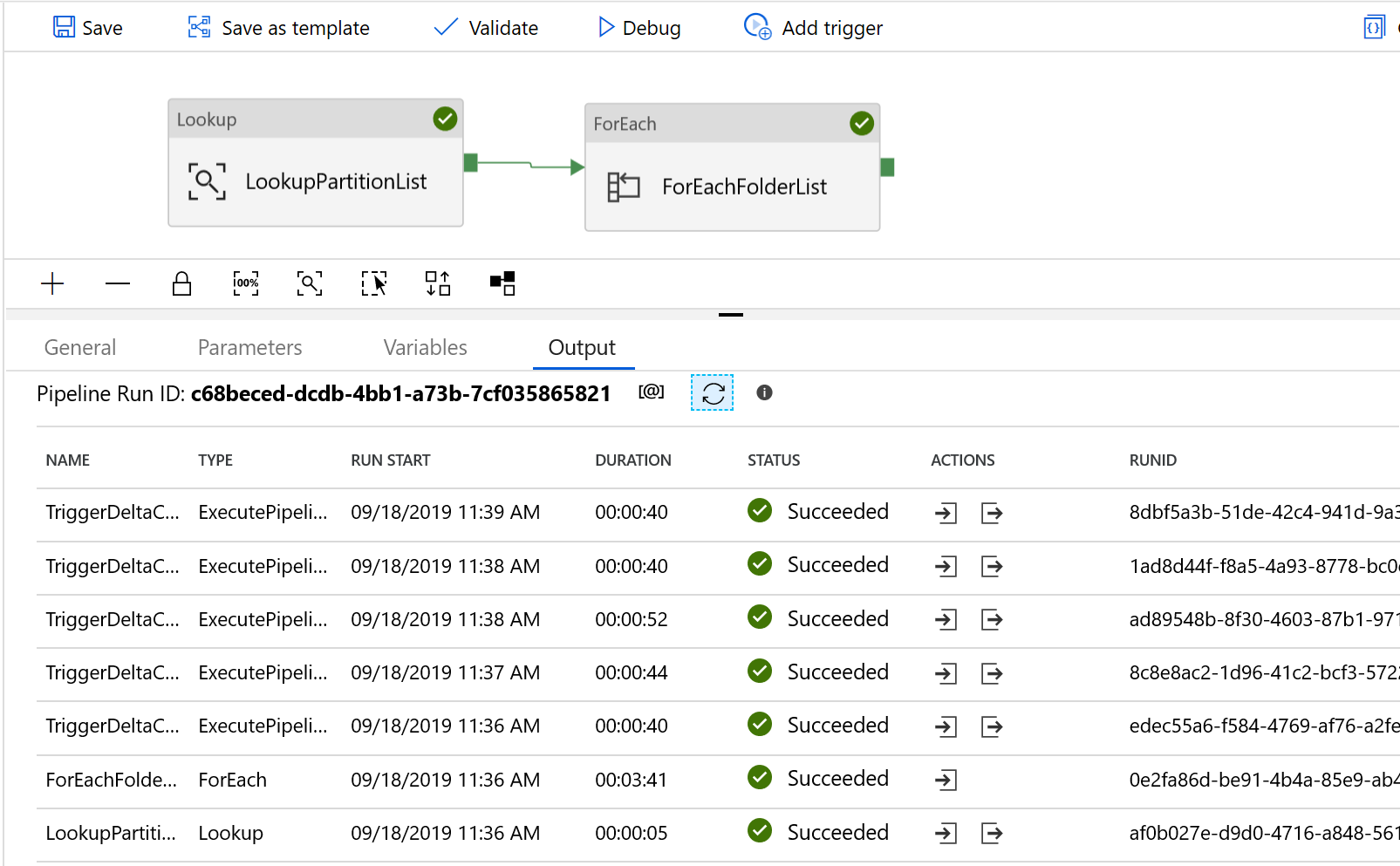
Sie können die Ergebnisse aus der Steuertabelle auch mithilfe der Abfrage "select * from s3_partition_delta_control_table" überprüfen. Die Ausgabe ähnelt dem folgenden Beispiel: