Umwandlung von Daten mithilfe von Hadoop-Streaming-Aktivitäten in Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Die HDInsight-Streaming-Aktivität in einer Azure Data Factory oder Synapse Analytics Pipeline führt Hadoop-Streaming-Programme auf ihrem eigenen oder auf Abruf HDInsight-Cluster aus. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet.
Um mehr zu erfahren, lesen Sie die Einführungsartikel zu Azure Data Factory und Synapse Analytics und führen Sie das Tutorial: Daten transformieren durch, bevor Sie diesen Artikel lesen.
Hinzufügen einer HDInsight Streamingaktivität zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine HDInsight Streamingaktivität in einer Pipeline zu verwenden:
Suchen Sie im Bereich mit den Pipelineaktivitäten nach Streaming, und ziehen Sie eine Streamingaktivität in den Pipelinebereich.
Wählen Sie die neue Streamingaktivität im Canvas aus, wenn sie noch nicht ausgewählt ist.
Wählen Sie die Registerkarte HDI-Cluster aus, um einen neuen verknüpften Dienst für einen HDInsight-Cluster auszuwählen oder zu erstellen, der zum Ausführen der Streamingaktivität verwendet wird.
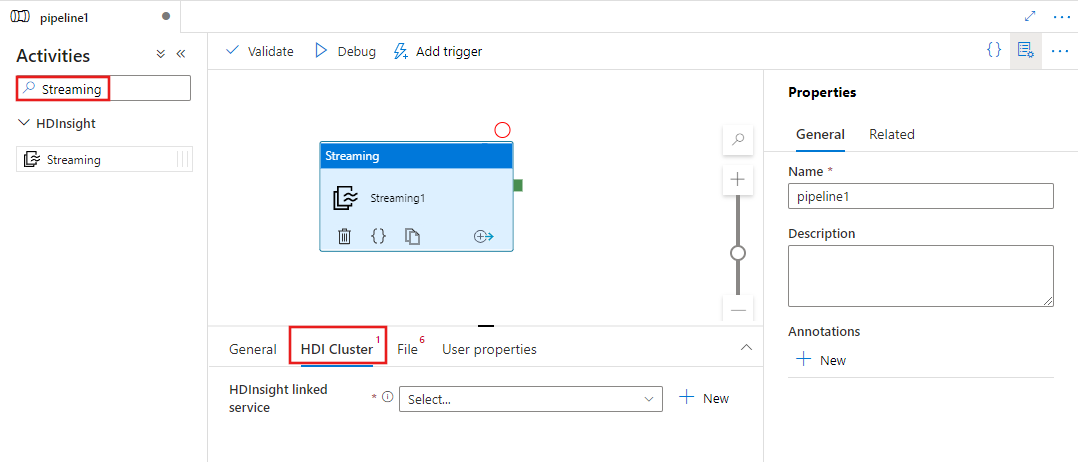
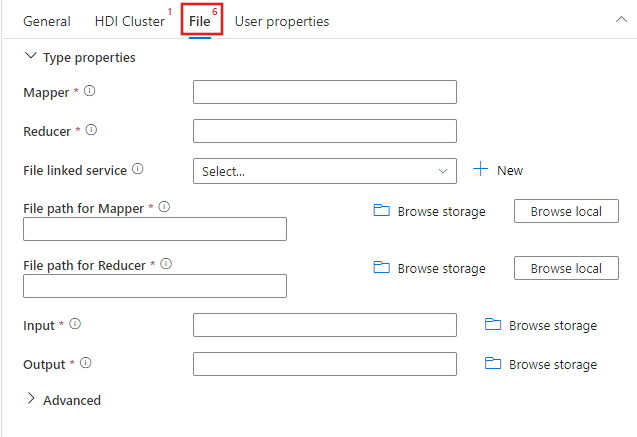
Wählen Sie die Registerkarte Datei aus, um die Mapper- und Reducernamen für Ihren Streamingauftrag anzugeben, und wählen Oder erstellen Sie einen neuen verknüpften Dienst für ein Azure Storage Konto, das die Zuordnungs-, Reduzierungs-, Eingabe- und Ausgabedateien für den Auftrag enthält. Sie können auch erweiterte Details konfigurieren, z. B. eine Debugkonfiguration sowie Argumente und Parameter, die an den Auftrag übergeben werden sollen.
JSON-Beispiel
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntaxdetails
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität | Ja |
| description | Ein Text, der beschreibt, wofür die Aktivität verwendet wird. | Nein |
| type | Für die Hadoop-Streamingaktivität ist der Aktivitätstyp „HDInsightStreaming“. | Ja |
| linkedServiceName | Verweis auf den HDInsight-Cluster, der als verknüpfter Dienst registriert ist. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Von Azure Data Factory unterstützten Compute-Umgebungen. | Ja |
| mapper | Gibt den Namen der ausführbaren Zuordnungsdatei (Mapper) an. | Ja |
| reducer | Gibt den Namen der ausführbaren Reduzierungsdatei (Reducer) an. | Ja |
| combiner | Gibt den Namen der ausführbaren Kombinierungsdatei (Combiner) an. | Nein |
| fileLinkedService | Verweis auf einen verknüpften Azure Storage-Dienst, der zum Speichern der Mapper-, Combiner- und Reducer-Programme verwendet wird. Hier werden nur die verknüpften Azure Blob Storage und ADLS Gen2 -Dienste unterstützt. Wenn Sie diesen verknüpften Dienst nicht angeben, wird der im verknüpften HDInsight-Dienst definierte verknüpfte Azure Storage-Dienst genutzt. | Nein |
| filePath | Geben Sie ein Array mit Pfaden zu den Mapper-, Combiner- und Reducer-Programmen an, die im Azure Storage-Speicher gespeichert sind, auf den „fileLinkedService“ verweist. Der Pfad berücksichtigt die Groß- und Kleinschreibung. | Ja |
| input | Gibt den WASB-Pfad zur Eingabedatei für den Mapper an. | Ja |
| output | Gibt den WASB-Pfad zur Ausgabedatei für den Reducer an. | Ja |
| getDebugInfo | Gibt an, ob die Protokolldateien in den Azure Storage-Speicher kopiert werden, der vom HDInsight-Cluster verwendet (oder) von „scriptLinkedService“ angegeben wird. Zulässige Werte: „None“, „Always“ oder „Failure“. Standardwert: Keine. | Nein |
| Argumente | Gibt ein Array von Argumenten für einen Hadoop-Auftrag an. Die Argumente werden als Befehlszeilenargumente an jeden Vorgang übergeben. | Nein |
| defines | Geben Sie Parameter als Schlüssel-Wert-Paare für Verweise innerhalb des Hive-Skripts an. | No |
Zugehöriger Inhalt
In den folgenden Artikeln erfahren Sie, wie Daten auf andere Weisen transformiert werden: