Herstellen einer Verbindung mit Google Cloud Storage
In diesem Artikel wird beschrieben, wie Sie eine Verbindung mit Azure Databricks konfigurieren, um Tabellen und Daten zu lesen und zu schreiben, die in Google Cloud Storage (GCS) gespeichert sind.
Zum Lesen oder Schreiben aus einem GCS-Bucket müssen Sie ein angefügtes Dienstkonto erstellen und den Bucket dem Dienstkonto zuordnen. Stellen Sie mit einem Schlüssel, den Sie für das Dienstkonto generieren, eine direkte Verbindung mit dem Bucket her.
Direkter Zugriff auf einen GCS-Bucket mit einem Google Cloud-Dienstkontoschlüssel
Um direkt in einen Bucket zu lesen und zu schreiben, konfigurieren Sie einen Schlüssel, der in Ihrer Spark-Konfiguration definiert ist.
Schritt 1: Einrichten eines Google Cloud-Dienstkontos mithilfe der Google Cloud Console
Sie müssen ein Dienstkonto für den Azure Databricks-Cluster erstellen. Databricks empfiehlt, diesem Dienstkonto für die Durchführung seiner Aufgaben die geringsten Berechtigungen zuzuweisen.
Klicken Sie im Navigationsbereich links auf IAM und Admin.
Klicken Sie auf Dienstkonten.
Klicken Sie auf + DIENSTKONTO ERSTELLEN.
Geben Sie den Dienstkontonamen und die Beschreibung ein.
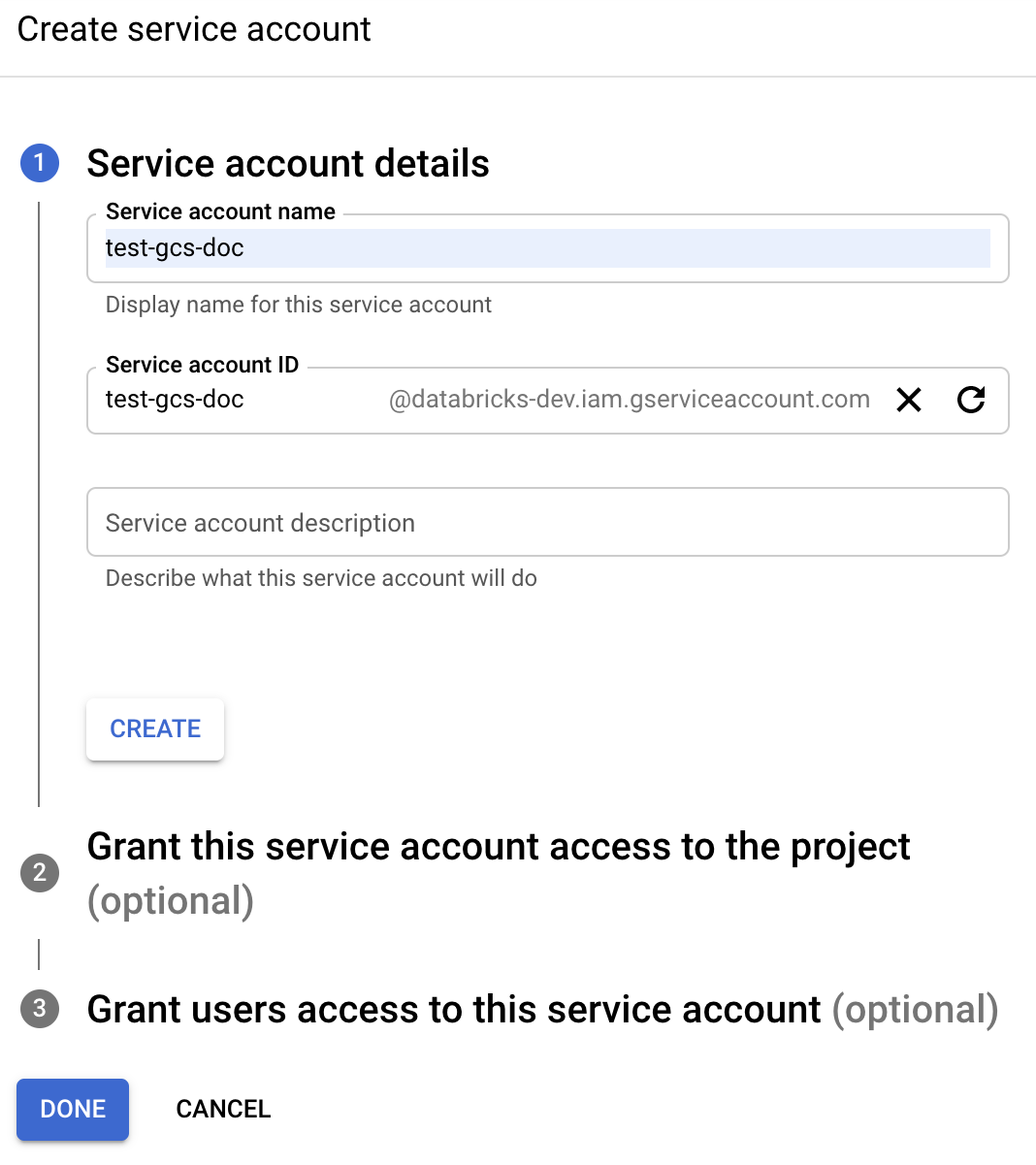
Klicken Sie auf ERSTELLEN.
Klicken Sie auf CONTINUE (WEITER).
Klicken Sie auf FERTIG.
Schritt 2: Erstellen eines Schlüssels für den direkten Zugriff auf GCS-Bucket
Warnung
Der JSON-Schlüssel, den Sie für das Dienstkonto generieren, ist ein privater Schlüssel, der nur für autorisierte Benutzer freigegeben werden sollte, da er den Zugriff auf Datasets und Ressourcen in Ihrem Google Cloud-Konto steuert.
- Klicken Sie in der Google Cloud Console in der Liste der Dienstkonten auf das neu erstellte Konto.
- Klicken Sie im Abschnitt Schlüssel auf SCHLÜSSEL HINZUFÜGEN > Neuen Schlüssel erstellen.
- Akzeptieren Sie den Schlüsseltyp JSON.
- Klicken Sie auf ERSTELLEN. Die Schlüsseldatei wird auf Ihren Computer heruntergeladen.
Schritt 3: Konfigurieren des GCS-Buckets
Erstellen eines Buckets
Wenn Sie noch keinen Bucket haben, erstellen Sie einen:
Klicken Sie im Navigationsbereich links auf Storage.
Klicken Sie auf BUCKET ERSTELLEN.
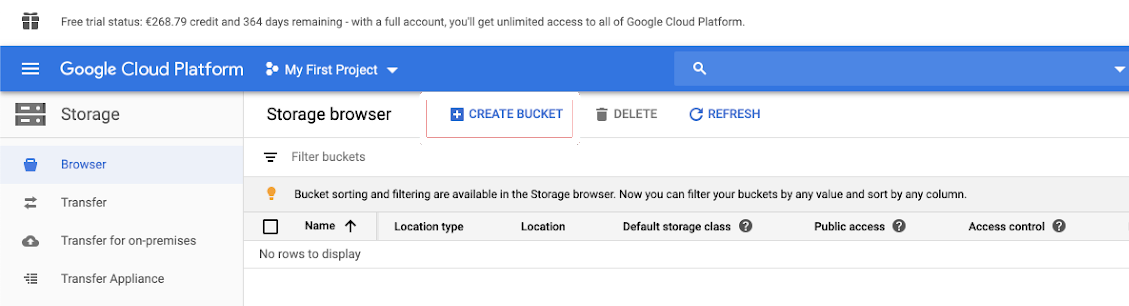
Klicken Sie auf ERSTELLEN.
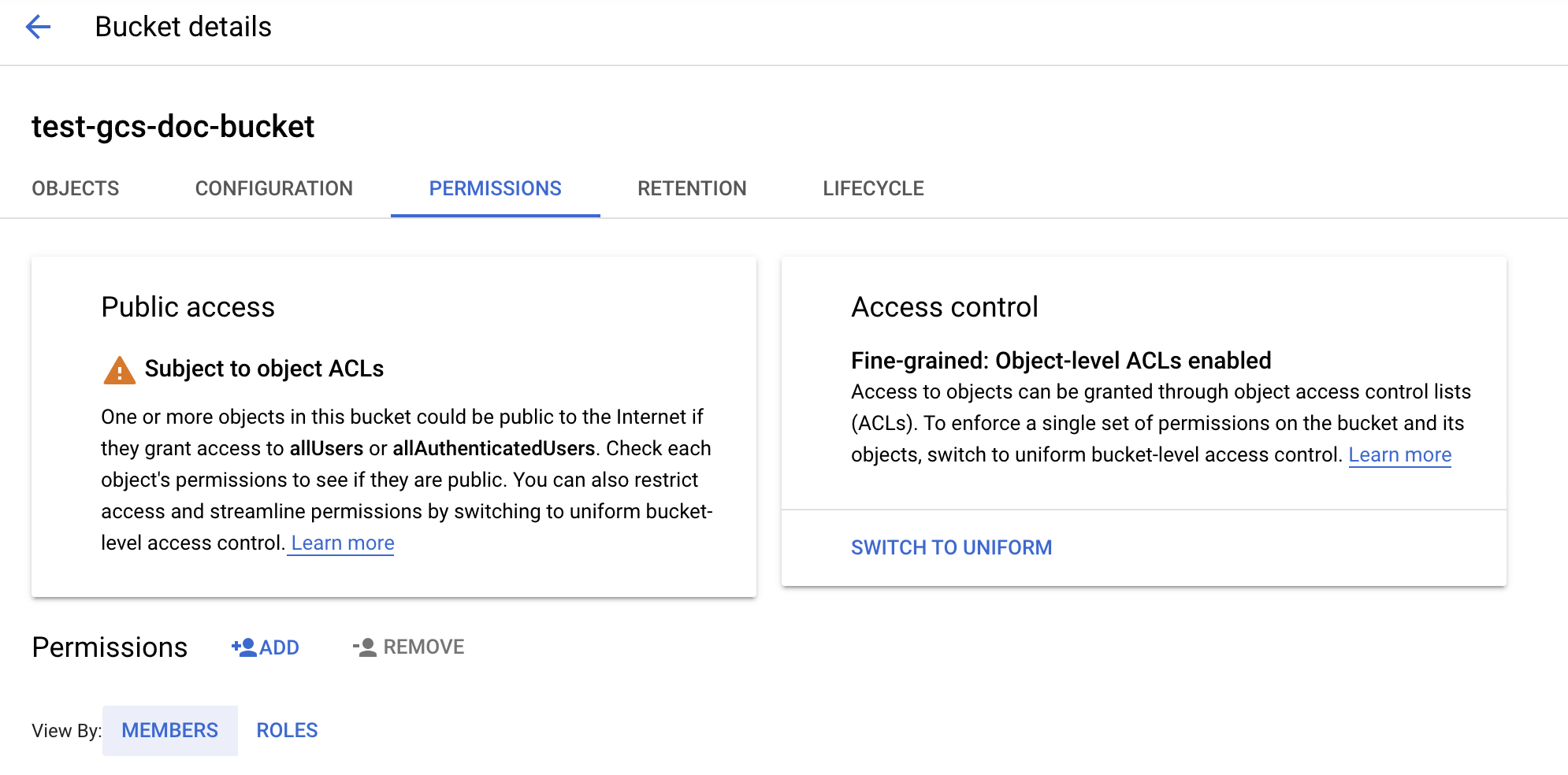
Konfigurieren des Buckets
Konfigurieren Sie die Bucketdetails.
Klicken Sie auf die Registerkarte Berechtigungen.
Klicken Sie neben der Bezeichnung Berechtigungen auf HINZUFÜGEN.
Geben Sie die Berechtigung Storage Admin für das Dienstkonto im Bucket aus den Cloudspeicherrollen an.
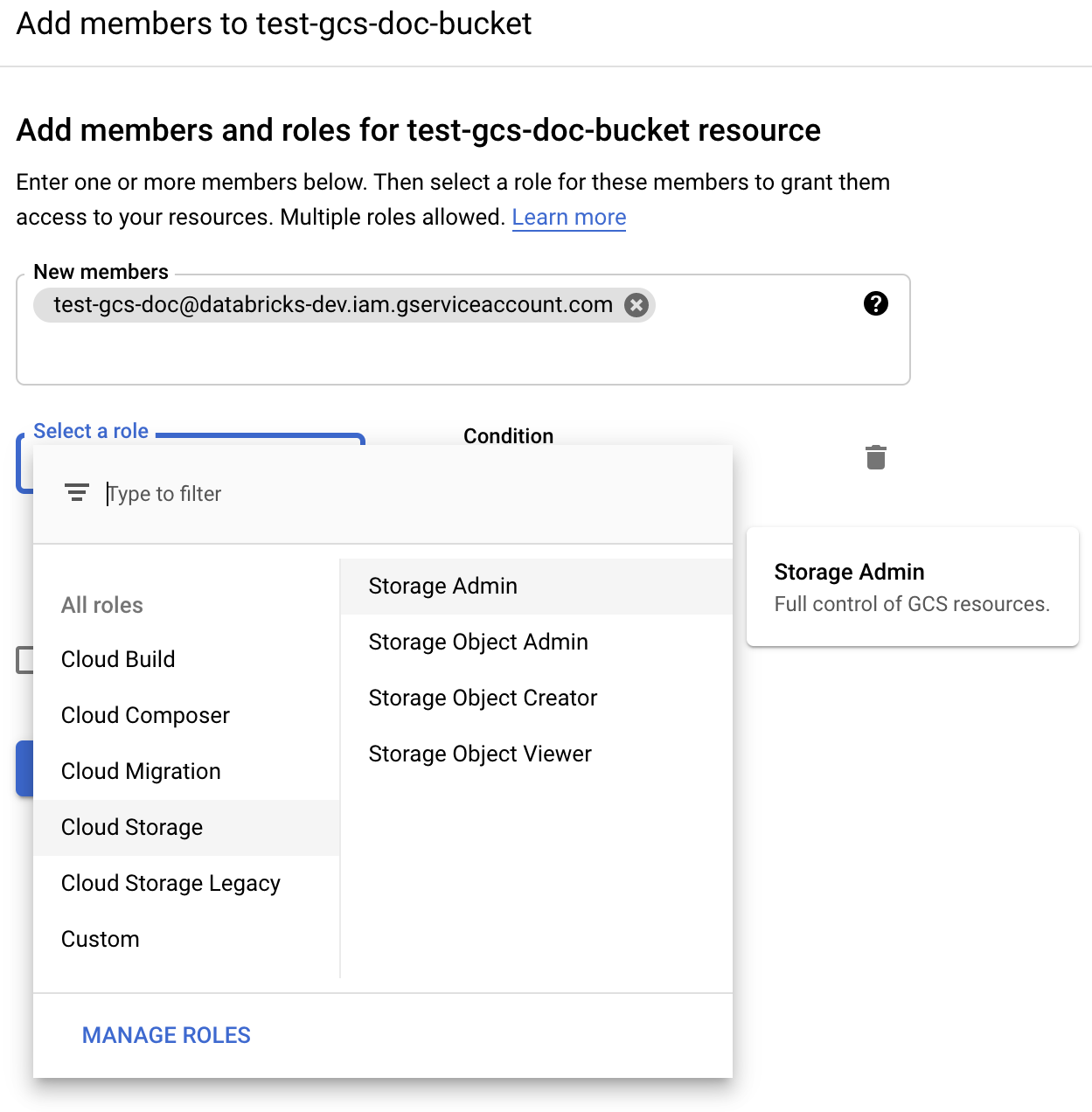
Klicken Sie auf SPEICHERN.
Schritt 4: Platzieren des Dienstkontoschlüssels in Databricks-Geheimnissen
Databricks empfiehlt zum Speichern aller Anmeldeinformationen die Verwendung von Geheimnisbereichen. Sie können den privaten Schlüssel und die PRIVATE Schlüssel-ID aus Ihrer JSON-Schlüsseldatei in geheime Databricks-Bereiche einfügen. Sie können Benutzern, Dienstprinzipalen und Gruppen in Ihrem Arbeitsbereich Lesezugriff für den Geheimnisbereich einräumen. Dadurch wird der Dienstkontoschlüssel geschützt, während Benutzer auf GCS zugreifen können. Informationen zum Erstellen eines geheimen Bereichs finden Sie unter Verwalten von geheimen Schlüsseln.
Schritt 5: Konfigurieren eines Azure Databricks-Clusters
Konfigurieren Sie auf der Registerkarte Spark Config entweder eine globale Konfiguration oder eine Konfiguration pro Bucket. In den folgenden Beispielen werden die Schlüssel mit Werten festgelegt, die als Databricks-Geheimnisse gespeichert sind.
Hinweis
Verwenden Sie die Clusterzugriffssteuerung und die Notebookzugriffssteuerung zusammen, um den Zugriff auf das Dienstkonto und die Daten im GCS-Bucket zu schützen. Siehe Compute-Berechtigungen und Zusammenarbeit mithilfe von Databricks-Notebooks.
Globale Konfiguration
Verwenden Sie diese Konfiguration, wenn die bereitgestellten Anmeldeinformationen für den Zugriff auf alle Buckets verwendet werden sollen.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Ersetzen Sie <client-email> und <project-id> durch die Werte dieser genauen Feldnamen aus Ihrer JSON-Schlüsseldatei.
Bucketspezifische Konfiguration
Verwenden Sie diese Konfiguration, wenn Sie Anmeldeinformationen für bestimmte Buckets konfigurieren müssen. Die Syntax für die Konfiguration pro Bucket hängt den Bucket-Namen an das Ende jeder Konfiguration an, wie im folgenden Beispiel.
Wichtig
Zusätzlich zu den globalen Konfigurationen können auch Konfigurationen pro Bucket verwendet werden. Wenn angegeben, haben die Konfigurationen pro Bucket Vorrang vor den globalen Konfigurationen.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Ersetzen Sie <client-email> und <project-id> durch die Werte dieser genauen Feldnamen aus Ihrer JSON-Schlüsseldatei.
Schritt 6: Lesen aus GCS
Verwenden Sie zum Lesen aus dem GCS-Bucket einen Spark-Lesebefehl in einem beliebigen unterstützten Format, z. B.:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Verwenden Sie zum Schreiben in den GCS-Bucket einen Spark-Schreibbefehl in einem beliebigen unterstützten Format, z. B.:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Ersetzen Sie <bucket-name> durch den Namen des Buckets, den Sie in Schritt 3 : Konfigurieren des GCS-Buckets erstellt haben.