Transformieren von Daten mit Delta Live Tables
In diesem Artikel wird beschrieben, wie Sie mit Delta Live Tables Transformationen für Datasets deklarieren und angeben können, wie Datensätze über Abfragelogik verarbeitet werden. Es enthält auch Beispiele für allgemeine Transformationsmuster zum Erstellen von Delta Live Tables-Pipelines.
Sie können ein Dataset für jede Abfrage definieren, die einen DataFrame zurückgibt. Sie können integrierte Apache Spark-Vorgänge, UDFs, benutzerdefinierte Logik und MLflow-Modelle als Transformationen in Ihrer Delta Live Tables-Pipeline verwenden. Nachdem Daten in Ihre Delta Live Tables-Pipeline aufgenommen wurden, können Sie neue Datasets für upstream-Quellen definieren, um neue Streamingtabellen, materialisierte Ansichten und Ansichten zu erstellen.
Informationen zum effektiven Ausführen zustandsbehafteter Verarbeitung mit Delta Live Tables finden Sie unter Optimieren der zustandsbehafteten Verarbeitung in Delta Live Tables mit Wasserzeichen.
Verwendung von Ansichten, materialisierten Sichten und Streamingtabellen
Wenn Sie Ihre Pipelineabfragen implementieren, wählen Sie den besten Datasettyp aus, um sicherzustellen, dass sie effizient und verwaltet werden können.
Erwägen Sie die Verwendung einer Ansicht, um Folgendes auszuführen:
- Unterteilen Sie eine große oder komplexe Abfrage, die Sie in einfacher zu verwaltende Abfragen benötigen.
- Überprüfen Sie zwischengeschaltete Ergebnisse unter Verwendung von Erwartungen.
- Reduzieren Sie Speicher- und Berechnungskosten für Ergebnisse, die Sie nicht beibehalten müssen. Da Tabellen materialisiert werden, erfordern sie zusätzliche Berechnungs- und Speicherressourcen.
Erwägen Sie die Verwendung einer materialisierten Sicht in folgenden Fällen:
- Die Tabelle wird von mehreren Downstreamabfragen genutzt. Da Sichten bei Bedarf berechnet werden, wird die Sicht bei jeder Abfrage neu berechnet.
- Andere Pipelines, Aufträge oder Abfragen nutzen die Tabelle. Da Sichten nicht materialisiert werden, können Sie sie nur in derselben Pipeline verwenden.
- Sie möchten die Ergebnisse einer Abfrage während der Entwicklung anzeigen. Da Tabellen materialisiert werden und außerhalb der Pipeline angezeigt und abgefragt werden können, bietet die Verwendung von Tabellen während der Entwicklung die Möglichkeit, die Richtigkeit von Berechnungen zu überprüfen. Konvertieren Sie nach der Überprüfung diejenigen Abfragen, die keine Materialisierung erfordern, in Sichten.
Ziehen Sie in folgenden Fällen die Verwendung einer Streamingtabelle in Betracht:
- Eine Abfrage wird für eine Datenquelle definiert, die kontinuierlich oder inkrementell wächst.
- Abfrageergebnisse sollten inkrementell berechnet werden.
- Die Pipeline benötigt hohen Durchsatz und niedrige Latenz.
Hinweis
Streamingtabellen werden immer für Streamingquellen definiert. Sie können auch Streamingquellen mit APPLY CHANGES INTO verwenden, um Updates aus CDC-Feeds anzuwenden. Weitere Informationen finden Sie unter Die APPLY CHANGES-APIs: Vereinfachen der Änderungsdatenerfassung mit Delta Live Tables.
Ausschließen von Tabellen aus dem Zielschema
Wenn Sie Zwischentabellen berechnen müssen, die nicht für den externen Verbrauch vorgesehen sind, können Sie verhindern, dass sie mit dem TEMPORARY Schlüsselwort in einem Schema veröffentlicht werden. Temporäre Tabellen speichern und verarbeiten daten weiterhin entsprechend der Delta Live Tables-Semantik, sollten jedoch nicht außerhalb der aktuellen Pipeline zugegriffen werden. Eine temporäre Tabelle wird für die Lebensdauer der Pipeline beibehalten, die sie erstellt. Verwenden Sie die folgende Syntax, um temporäre Tabellen zu deklarieren:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Kombinieren von Streamingtabellen und materialisierten Sichten in einer einzigen Pipeline
Streamingtabellen erben die Verarbeitungsgarantien für strukturiertes Streamen von Apache Spark und sind für die Verarbeitung von Abfragen aus anfügegeschützten Datenquellen konfiguriert, wobei immer neue Zeilen in die Quelltabelle eingefügt und nicht geändert werden.
Hinweis
Obwohl Streamingtabellen standardmäßig reine Anfüge-Datenquellen erfordern, können Sie dieses Verhalten mit dem Flag skipChangeCommits überschreiben, wenn eine Streamingquelle eine andere Streamingtabelle ist, die Updates oder Löschvorgänge erfordert.
Ein gängiges Streamingmuster umfasst das Aufnehmen von Quelldaten zum Erstellen der anfänglichen Datasets in einer Pipeline. Diese anfänglichen Datasets werden häufig als Bronze-Tabellen bezeichnet und führen häufig einfache Transformationen aus.
Im Gegensatz dazu erfordern die endgültigen Tabellen in einer Pipeline, die häufig als Goldtabellen bezeichnet werden, häufig komplizierte Aggregationen oder das Lesen von Zielen eines APPLY CHANGES INTO Vorgangs. Da diese Vorgänge inhärent Updates erstellen, anstatt sie anzufügen, werden sie nicht als Eingaben in Streaming-Tabellen unterstützt. Diese Transformationen eignen sich besser für materialisierte Sichten.
Indem Sie die Streaming-Tababellen und materialisierte Sichten in einer einzelnen Pipeline kombinieren, können Sie Ihre Pipeline vereinfachen und eine kostspielige erneute Erfassung oder erneute Verarbeitung von Rohdaten vermeiden und die volle Leistung von SQL nutzen, um komplexe Aggregationen über ein effizient codiertes und gefiltertes Dataset zu berechnen. Im folgenden Beispiel wird diese Art der gemischten Verarbeitung veranschaulicht:
Hinweis
In diesen Beispielen wird Autoloader verwendet, um Dateien aus dem Cloudspeicher zu laden. Um Dateien mit Autoloader in einer Pipeline mit Unity Catalog-Aktivierung zu laden, müssen Sie externe Speicherorte verwenden. Weitere Informationen zur Verwendung von Unity Catalog mit Delta Live Tables finden Sie unter Verwenden von Unity Catalog mit Ihren Delta Live Tables-Pipelines.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("LIVE.streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("LIVE.streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(LIVE.streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM LIVE.streaming_silver GROUP BY user_id
Erfahren Sie mehr über die Verwendung des automatischen Ladeprogramms zum inkrementellen Aufnehmen von JSON-Dateien aus Azure Storage.
Streamstatik-Verknüpfungen
Streamstatik-Verknüpfungen sind eine gute Wahl beim Denormalisieren eines kontinuierlichen Datenstroms von Daten, die nur zum Anfügen vorgesehen sind, mit einer hauptsächlich statischen Dimensionstabelle.
Mit jedem Pipelineupdate werden neue Datensätze aus dem Stream mit dem aktuellsten Momentaufnahme der statischen Tabelle verknüpft. Wenn Datensätze in der statischen Tabelle hinzugefügt oder aktualisiert werden, nachdem entsprechende Daten aus der Streamingtabelle verarbeitet wurden, werden die resultierenden Datensätze erst dann neu berechnet, wenn eine vollständige Aktualisierung durchgeführt wird.
In Pipelines, die für die ausgelöste Ausführung konfiguriert sind, gibt die statische Tabelle ergebnisse zurück, sobald das Update gestartet wurde. In Pipelines, die für die kontinuierliche Ausführung konfiguriert sind, wird die neueste Version der statischen Tabelle jedes Mal abgefragt, wenn die Tabelle eine Aktualisierung verarbeitet.
Im Folgenden sehen Sie ein Beispiel für eine Streamstatik-Verknüpfung:
Python
@dlt.table
def customer_sales():
return spark.readStream.table("LIVE.sales").join(spark.readStream.table("LIVE.customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(LIVE.sales)
INNER JOIN LEFT LIVE.customers USING (customer_id)
Effizientes Berechnen von Aggregaten
Sie können Streaming-Livetabellen ebenfalls für das inkrementelle Berechnen von einfachen verteilbaren Aggregaten wie count, min, max oder sum sowie algebraische Aggregate wie Durchschnitts- oder Standardabweichung verwenden. Databricks empfiehlt die inkrementelle Aggregation für Abfragen mit einer begrenzten Anzahl von Gruppen, z. B. eine Abfrage mit einer GROUP BY country Klausel. Bei jedem Update werden nur neue Eingabedaten gelesen.
Weitere Informationen zum Schreiben von Delta Live Tables-Abfragen, die inkrementelle Aggregationen ausführen, finden Sie unter Durchführen von Aggregationen im Fenstermodus mit Grenzwerten.
Verwenden von MLFlow-Modellen in einer Delta Live Tables-Pipeline
Hinweis
Zur Verwendung von MLflow-Modellen in einer Unity Catalog-fähigen Pipeline muss Ihre Pipeline für die Verwendung des preview-Kanals konfiguriert sein. Um den current-Kanal zu verwenden, müssen Sie Ihre Pipeline so konfigurieren, dass sie im Hive-Metastore veröffentlicht wird.
Sie können MLflow-trainierte Modelle in Delta Live Tables-Pipelines verwenden. MLflow-Modelle werden als Transformationen in Azure Databricks behandelt, was bedeutet, dass sie auf eine Spark-DataFrame-Eingabe reagieren und Ergebnisse als Spark DataFrame zurückgeben. Da Delta Live Tables Datasets für DataFrames definiert, können Sie Apache Spark-Workloads konvertieren, die MLflow in Delta Live Tables mit nur wenigen Codezeilen verwenden. Weitere Informationen zu MLflow finden Sie unter ML-Lebenszyklusverwaltung mit MLflow.
Wenn Sie bereits über ein Python-Notebook verfügen, das ein MLflow-Modell aufruft, können Sie diesen Code mithilfe des @dlt.table-Decorators an Delta Live Tables anpassen und sicherstellen, dass Funktionen definiert sind, um Transformationsergebnisse zurückzugeben. Delta Live Tables installiert MLflow standardmäßig nicht. Vergewissern Sie sich also, dass Sie die MLFlow-Bibliotheken installiert %pip install mlflow und importiert und dlt oben im Notizbuch importiert mlflow haben. Eine Einführung in die Syntax von Delta Live Tables finden Sie unter Entwickeln von Pipelinecode mit Python.
Führen Sie die folgenden Schritte aus, um MLflow-Modelle in Delta Live Tables zu verwenden:
- Rufen Sie die Ausführungs-ID und den Modellnamen des MLFlow-Modells ab. Die Ausführungs-ID und der Modellname werden verwendet, um den URI des MLFlow-Modells zu erstellen.
- Verwenden Sie den URI, um eine Spark-UDF zum Laden des MLFlow-Modells zu definieren.
- Rufen Sie die UDF in Ihren Tabellendefinitionen auf, um das MLFlow-Modell zu verwenden.
Das folgende Beispiel zeigt die grundlegende Syntax für dieses Muster:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Als vollständiges Beispiel wird im folgenden Code eine Spark-UDF mit dem Namen loaded_model_udf definiert. Diese lädt ein MLFlow-Modell, das mit Kreditrisikodaten trainiert wurde. Die Datenspalten, die zum Treffen der Vorhersage verwendet werden, werden als Argument an die UDF übergeben. Die Tabelle loan_risk_predictions berechnet Vorhersagen für jede Zeile in loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Beibehalten manueller Löschungen oder Aktualisierungen
Mit Delta Live Tables können Sie Datensätze aus einer Tabelle manuell löschen oder aktualisieren und einen Aktualisierungsvorgang ausführen, um nachgelagerte Tabellen neu zu kompensieren.
Standardmäßig berechnet Delta Live Tables die Tabellenergebnisse auf der Grundlage der Eingabedaten bei jeder Aktualisierung einer Pipeline neu, so dass Sie sicherstellen müssen, dass der gelöschte Datensatz nicht erneut aus den Quelldaten geladen wird. Durch Festlegen der pipelines.reset.allowed Tabelleneigenschaft wird verhindert, false dass eine Tabelle aktualisiert wird, aber nicht verhindert, dass inkrementelle Schreibvorgänge in die Tabellen oder neue Daten in die Tabelle fließen.
Das folgende Diagramm veranschaulicht ein Beispiel mit zwei Streamingtabellen:
raw_user_tableerfasst einen Satz unformatierten Benutzerdaten aus einer Quelle.bmi_tableberechnet inkrementell BMI-Bewertungen anhand der Gewichtung und Höhe ausraw_user_table.
Sie möchten Benutzerdatensätze manuell aus raw_user_table löschen oder aktualisieren und bmi_table neu berechnen.
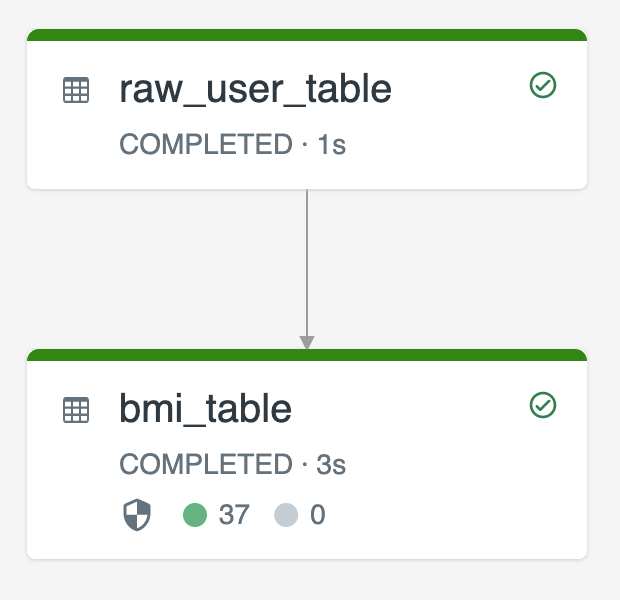
Der folgende Code veranschaulicht das Festlegen der Tabelleneigenschaft pipelines.reset.allowed auf false, um die vollständige Aktualisierung für raw_user_table zu deaktivieren, sodass die beabsichtigten Änderungen im Laufe der Zeit beibehalten werden. Nachgelagerte Tabellen werden jedoch neu berechnet, wenn ein Pipelineupdate ausgeführt wird:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(LIVE.raw_user_table);