Bewerten der Leistung: wichtige Metriken
Dieser Artikel befasst sich mit der Messung der Leistung einer RAG-Anwendung in Bezug auf die Qualität von Abruf, Reaktion und Systemleistung.
Abruf, Reaktion und Leistung
Mit einem Auswertungssatz können Sie die Leistung Ihrer RAG-Anwendung für verschiedene Dimensionen messen, u. a.:
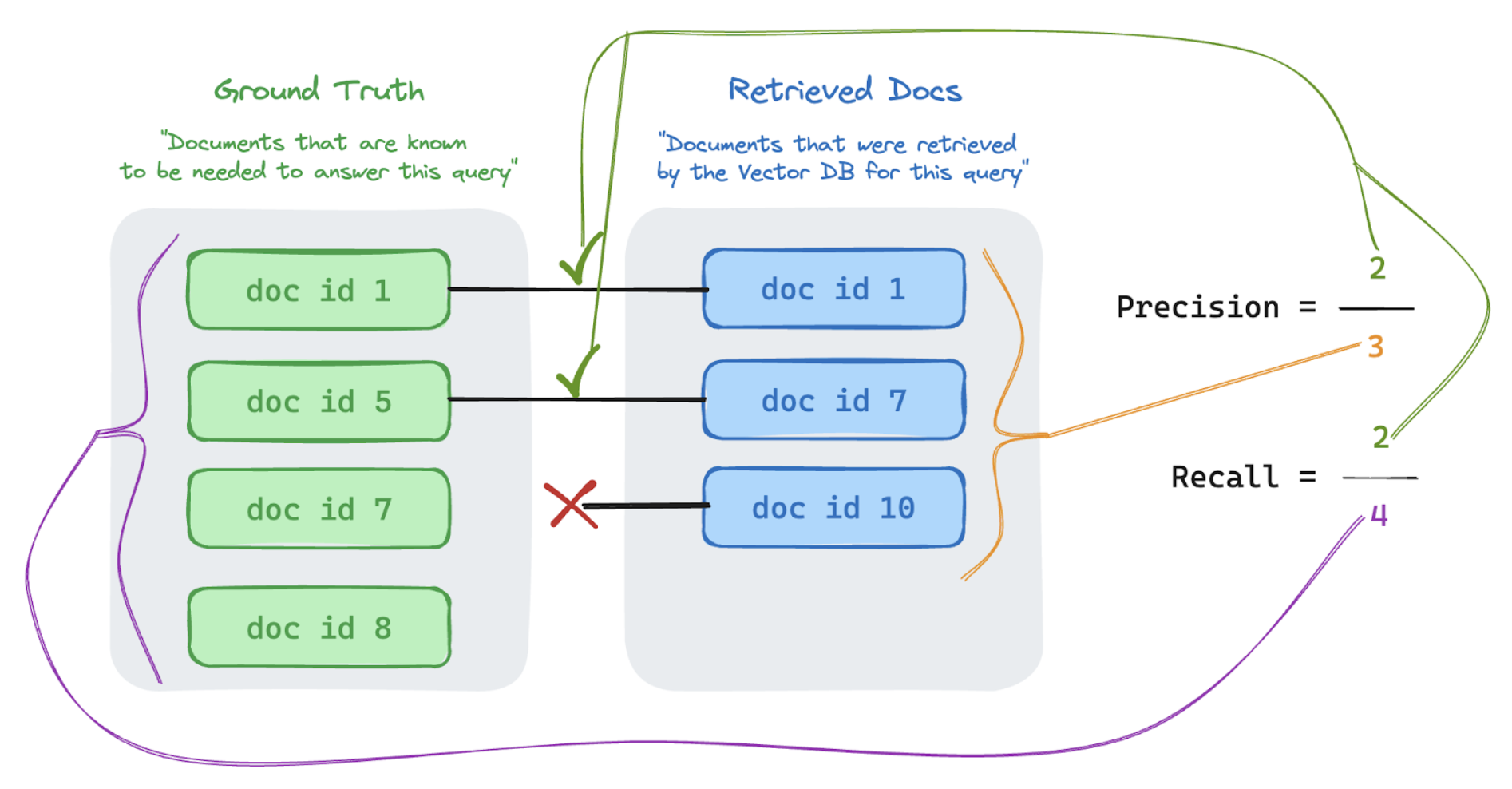
- Abrufqualität: Abrufmetriken bewerten, wie erfolgreich Ihre RAG-Anwendung relevante unterstützende Daten abruft. Genauigkeit und Rückruf sind zwei wichtige Abrufmetriken.
- Antwortqualität: Metriken der Antwortqualität bewerten, wie gut die RAG-Anwendung auf die Anforderung eines Benutzers reagiert. Antwortmetriken können z. B. messen, ob die resultierende Antwort gemäß Grundwahrheit genau ist, wie fundiert die Antwort angesichts des abgerufenen Kontexts war (Beispiel: Falsche Interpretation durch das LLM?) oder wie sicher die Antwort war (anders ausgedrückt: keine Toxizität).
- Systemleistung (Kosten und Wartezeit): Leistungsmetriken erfassen die Gesamtkosten und die Leistung von RAG-Anwendungen. Die Gesamtlatenz und der Tokenverbrauch sind Beispiele für Kettenleistungsmetriken.
Es ist sehr wichtig, sowohl Antwort- als auch Abrufmetriken zu sammeln. Eine RAG-Anwendung kann trotz des Abrufens des richtigen Kontexts eine schlechte Antwort und basierend auf fehlerhaften Abrufen auch gute Antworten liefern. Nur durch die Messung beider Komponenten können wir Probleme in der Anwendung genau diagnostizieren und beheben.
Ansätze zum Messen der Leistung
Es gibt zwei wichtige Ansätze zum Messen der Leistung in diesen Metriken:
- Deterministische Messung: Kosten- und Wartezeitmetriken können deterministisch auf der Grundlage der Anwendungsausgaben berechnet werden. Wenn Ihr Auswertungssatz eine Liste von Dokumenten beinhaltet, die die Antwort auf eine Frage enthalten, kann auch eine Teilmenge der Abrufmetriken deterministisch berechnet werden.
- LLM-Beurteilungsbasiert: Bei diesem Ansatz wird ein separates LLM als Beurteilung verwendet, um die Abruf- und Antwortqualität der RAG-Anwendung zu bewerten. Einige LLM-Beurteilungen, etwa zur Korrektheit der Antwort, vergleichen die menschenmarkierte Grundwahrheit mit den App-Ausgaben. Andere LLM-Beurteilungen, etwa zur Fundiertheit, erfordern keine menschenmarkierte Grundwahrheit, um ihre App-Ausgaben zu bewerten.
Wichtig
Damit eine LLM-Beurteilung effektiv ist, muss sie für den Anwendungsfall optimiert sein. Dies erfordert eine sorgfältige Prüfung, um zu ermitteln, wo die Beurteilung gut funktioniert und wo nicht, und um sie dann für die Fehlerfälle zu optimieren.
Mosaic AI Agent Evaluation ermöglicht die direkte Implementierung mit gehosteten LLM-Beurteilungsmodellen für jede auf dieser Seite erläuterte Metrik. Die Dokumentation zu Agent Evaluation enthält die Details zur Implementierung dieser Metriken und Beurteilungen und bietet Funktionen zur Optimierung der Beurteilungen, um ihre Genauigkeit zu erhöhen.
Übersicht der Metriken
Im Anschluss finden Sie eine Zusammenfassung der Metriken, die Databricks zur Messung der Qualität, Kosten und Wartezeit Ihrer RAG-Anwendung empfiehlt. Diese Metriken werden in Mosaic AI Agent Evaluation implementiert.
| Dimensionen | Metrikname | Frage | Gemessen an | Grundwahrheit erforderlich? |
|---|---|---|---|---|
| Abrufen | chunk_relevance/precision | Welcher Prozentsatz der abgerufenen Blöcke ist für die Anforderung relevant? | LLM-Richter | No |
| Abrufen | document_recall | Welcher Prozentsatz der Grundwahrheitsdokumente sind in den abgerufenen Blöcken dargestellt? | Deterministisch | Ja |
| Antwort | correctness | Hat der Agent insgesamt eine richtige Antwort generiert? | LLM-Richter | Ja |
| Antwort | relevance_to_query | Ist die Antwort für die Anforderung relevant? | LLM-Richter | No |
| Antwort | groundedness | Ist die Antwort im Kontext einer Halluzination oder begründet? | LLM-Richter | No |
| Antwort | Sicherheit | Gibt es schädliche Inhalte in der Antwort? | LLM-Richter | No |
| Kosten | total_token_count, total_input_token_count, total_output_token_count | Was ist die Gesamtzahl der Token für LLM-Generationen? | Deterministisch | No |
| Latency | latency_seconds | Was ist die Wartezeit bei der App-Ausführung? | Deterministisch | No |
Funktionsweise von Abrufmetriken
Mithilfe von Abrufmetriken können Sie nachvollziehen, ob Ihr Abrufer relevante Ergebnisse liefert. Abrufmetriken basieren auf Genauigkeit und Abruf.
| Metrikname | Frage beantwortet | Details |
|---|---|---|
| Präzision | Welcher Prozentsatz der abgerufenen Blöcke ist für die Anforderung relevant? | Genauigkeit ist der Anteil der abgerufenen Dokumente, die tatsächlich für die Anforderung des Benutzers relevant sind. Eine LLM-Beurteilung kann verwendet werden, um die Relevanz der einzelnen abgerufenen Blöcke für die Anforderung des Benutzers zu bewerten. |
| Recall | Welcher Prozentsatz der Grundwahrheitsdokumente sind in den abgerufenen Blöcken dargestellt? | Abruf ist der Anteil der Grundwahrheitsdokumente, die in den abgerufenen Blöcken dargestellt sind. Dies ist ein Maß für die Vollständigkeit der Ergebnisse. |
Präzision und Abruf
Unten finden Sie eine kurze Einführung in Präzision und Rückruf, die diesem hervorragenden Wikipedia-Artikel entnommen ist.
Präzisionsformel
Bei Präzision wird Folgendes gemessen: „Wie viel Prozent der von mir abgerufenen Blöcke sind tatsächlich relevant für die Anfrage meines Benutzers?“ Die Computepräzision erfordert nicht, dass alle relevanten Elemente bekannt sind.
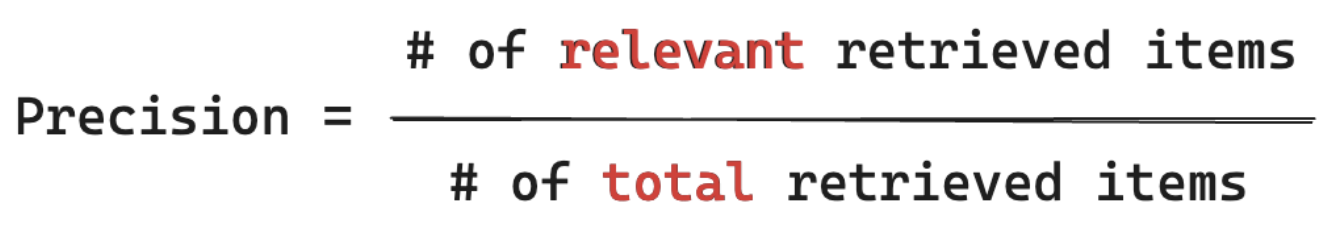
Abrufformel
Beim Abruf wird Folgendes gemessen: „Aus wie viel Prozent ALLER Dokumente, die für die Abfrage meines Benutzers relevant sind, habe ich einen Teil abgerufen?“ Beim Computingabruf muss die Grundwahrheit alle relevanten Elemente enthalten. Elemente können entweder ein Dokument oder ein Block eines Dokuments sein.
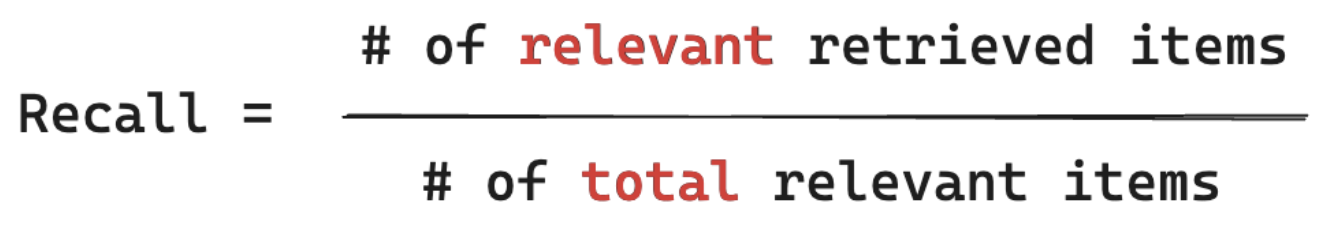
Im folgenden Beispiel waren zwei der drei abgerufenen Ergebnisse relevant für die Benutzerabfrage. Daher betrug die Präzision 0,66 (2/3). Die abgerufenen Dokumente enthielten zwei von insgesamt vier relevanten Dokumenten. Daher betrug der Abruf 0,5 (2/4).