Umfang der Lakehouse-Plattform
Ein modernes Daten- und KI-Plattformframework
Um den Umfang der Databricks Data Intelligence-Plattform zu erörtern, ist es hilfreich, zunächst ein grundlegendes Framework für die moderne Daten- und KI-Plattform zu definieren:
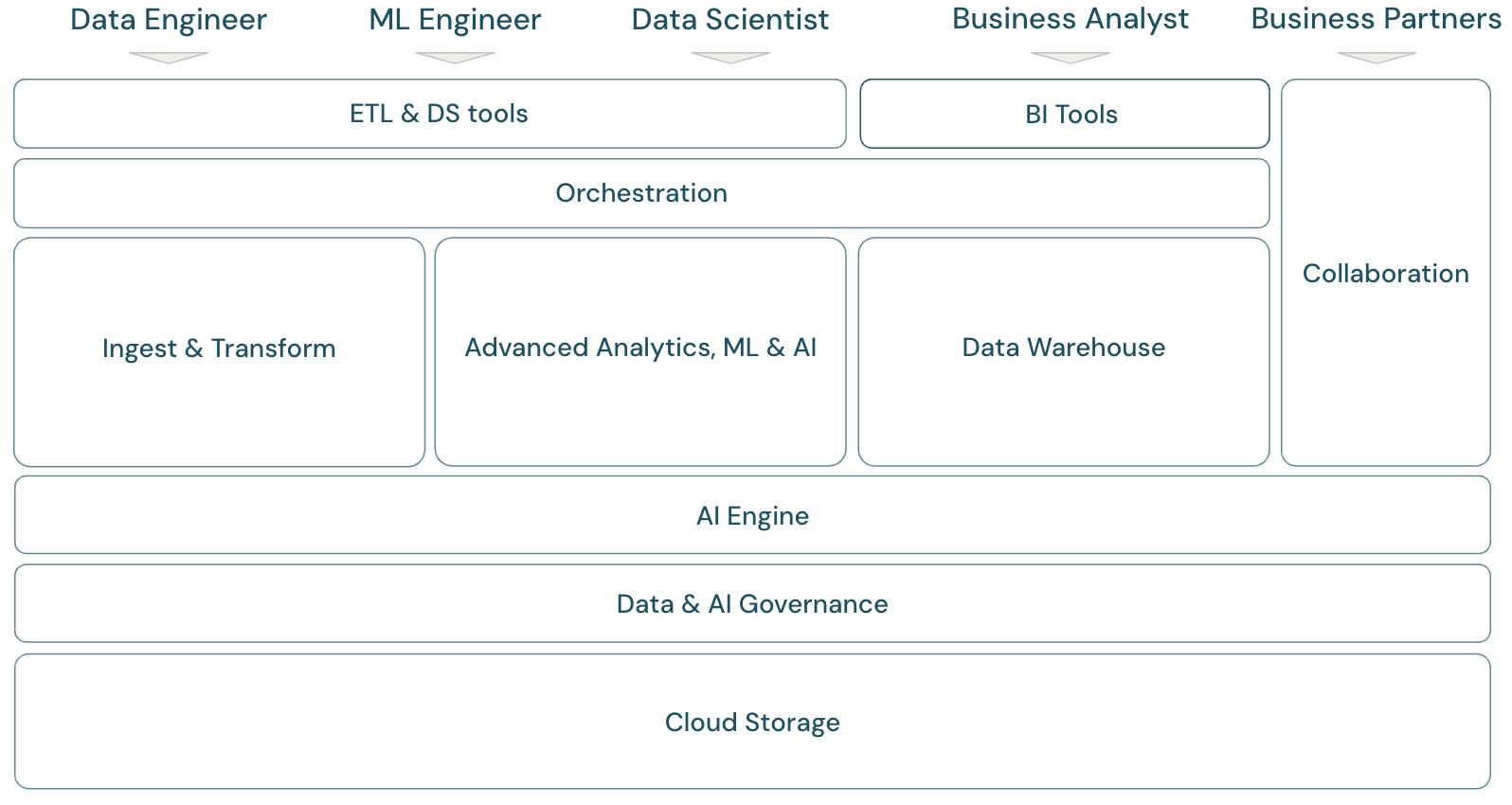
Überblick über den Lakehouse-Umfang
Die Databricks Data Intelligence-Plattform deckt das komplette Framework einer modernen Datenplattform ab. Sie basiert auf der Lakehouse-Architektur und wird von einem Data Intelligence-Modul unterstützt, das die einzigartigen Eigenschaften Ihrer Daten versteht. Sie ist eine offene und einheitliche Grundlage für ETL-, ML/KI- und DWH/BI-Workloads und stellt Unity Catalog als zentrale Daten- und KI-Governancelösung bereit.
Personas des Plattformframeworks
Das Framework umfasst die primären Datenteammitglieder (Personas), die mit den Anwendungen im Framework arbeiten:
- Technische Fachkräfte für Daten versorgen wissenschaftliche Fachkräfte für Daten und Business Analysts mit genauen und reproduzierbaren Daten für eine zeitnahe Entscheidungsfindung und Erkenntnissen in Echtzeit. Sie implementieren äußerst konsistente und zuverlässige ETL-Prozesse, um das Benutzervertrauen in Daten zu stärken. Sie stellen sicher, dass die Daten gut in die verschiedenen Säulen des Unternehmens integriert sind und folgen in der Regel den Best Practices der Softwareentwicklung.
- Wissenschaftliche Fachkräfte für Daten vereinen analytisches Fachwissen und Geschäftsverständnis, um Daten in strategische Erkenntnisse und Prognosemodelle umzuwandeln. Sie sind in der Lage, geschäftliche Herausforderungen in datengesteuerte Lösungen zu übersetzen, sei es durch retrospektive analytische Erkenntnisse oder durch vorausschauende Prognosemodellierung. Durch den Einsatz von Datenmodellierung und maschinellen Lerntechniken entwerfen, entwickeln und implementieren sie Modelle, die Muster, Trends und Prognosen in Daten aufdecken. Sie fungieren als Brücke, indem sie komplexe Daten in verständliche Geschichten umwandeln und so sicherstellen, dass Geschäftsbeteiligte die datengestützten Empfehlungen nicht nur verstehen, sondern auch umsetzen können, was wiederum einen datenzentrierten Ansatz zur Problemlösung innerhalb einer Organisation fördert.
- Technische Fachkräfte für ML (maschinelles Lernen) leiten die praktische Anwendung von Data Science in Produkten und Lösungen, indem sie Modelle für maschinelles Lernen erstellen, bereitstellen und pflegen. Ihr Hauptaugenmerk richtet sich auf den technischen Aspekt der Modellentwicklung und -bereitstellung. Technische Fachkräfte für ML sorgen für die Stabilität, Zuverlässigkeit und Skalierbarkeit von Systemen für maschinelles Lernen in Liveumgebungen und kümmern sich um Herausforderungen in Bezug auf Datenqualität, Infrastruktur und Leistung. Durch die Integration von KI- und ML-Modellen in betriebliche Geschäftsprozesse und benutzerorientierte Produkte erleichtern sie die Nutzung von Data Science zur Lösung geschäftlicher Herausforderungen und stellen sicher, dass die Modelle nicht nur in der Forschung verbleiben, sondern einen greifbaren Geschäftswert schaffen.
- Business Analysts versorgen Projektbeteiligte und Geschäftsteams mit umsetzbaren Daten. Sie interpretieren häufig Daten und erstellen mit Hilfe von Standard-BI-Tools Berichte oder andere Dokumentationen für die Geschäftsleitung. Sie sind in der Regel die erste Anlaufstelle für nicht-technische Geschäfts- und Betriebskollegen bei schnellen Analysefragen.
- Geschäftspartner sind wichtige Beteiligte in einer zunehmend vernetzten Geschäftswelt. Sie sind definiert als Unternehmen oder Einzelpersonen, mit denen ein Unternehmen eine formelle Beziehung zur Erreichung eines gemeinsamen Ziels unterhält, und können Anbieter, Lieferanten, Vertriebspartner und andere Drittpartner umfassen. Die gemeinsame Nutzung von Daten ist ein wichtiger Aspekt von Geschäftspartnerschaften, da sie die Übertragung und den Austausch von Daten zur Verbesserung der Zusammenarbeit und der datengestützten Entscheidungsfindung ermöglicht.
Domänen des Plattformframeworks
Die Plattform umfasst mehrere Domänen:
Speicher: In der Cloud werden Daten hauptsächlich in skalierbarem, effizientem und robustem Objektspeicher auf Cloudanbietern gespeichert.
Governance: Funktionen rund um Datengovernance, z. B. Zugriffssteuerung, Überwachung, Metadatenverwaltung, Nachverfolgung der Datenherkunft und Überwachung für alle Daten und KI-Ressourcen.
KI-Engine: Die KI-Engine bietet generative KI-Funktionen für die gesamte Plattform.
Erfassung und Transformation: Die Funktionen für ETL-Workloads.
Erweiterte Analysen, ML und KI: Alle Funktionen rund um maschinelles Lernen, KI, generative KI und auch Streaminganalysen.
Data Warehouse: Die Domäne, die DWH- und BI-Anwendungsfälle unterstützt.
Orchestrierung: zentrales Workflowmanagement von Datenverarbeitungs-, Machine Learning- und Analysepipelines.
ETL- und DS-Tools: Die Front-End-Tools, mit denen technische und wissenschaftliche Fachkräfte für Daten sowie technische Fachkräfte für ML hauptsächlich arbeiten.
BI-Tools: Die Front-End-Tools, mit denen BI-Analysten hauptsächlich arbeiten.
Zusammenarbeit: Funktionen für die Datenfreigabe zwischen zwei oder mehr Parteien.
Umfang der Databricks-Plattform
Die Databricks Data Intelligence-Plattform und ihre Komponenten können dem Framework auf folgende Weise zugeordnet werden:
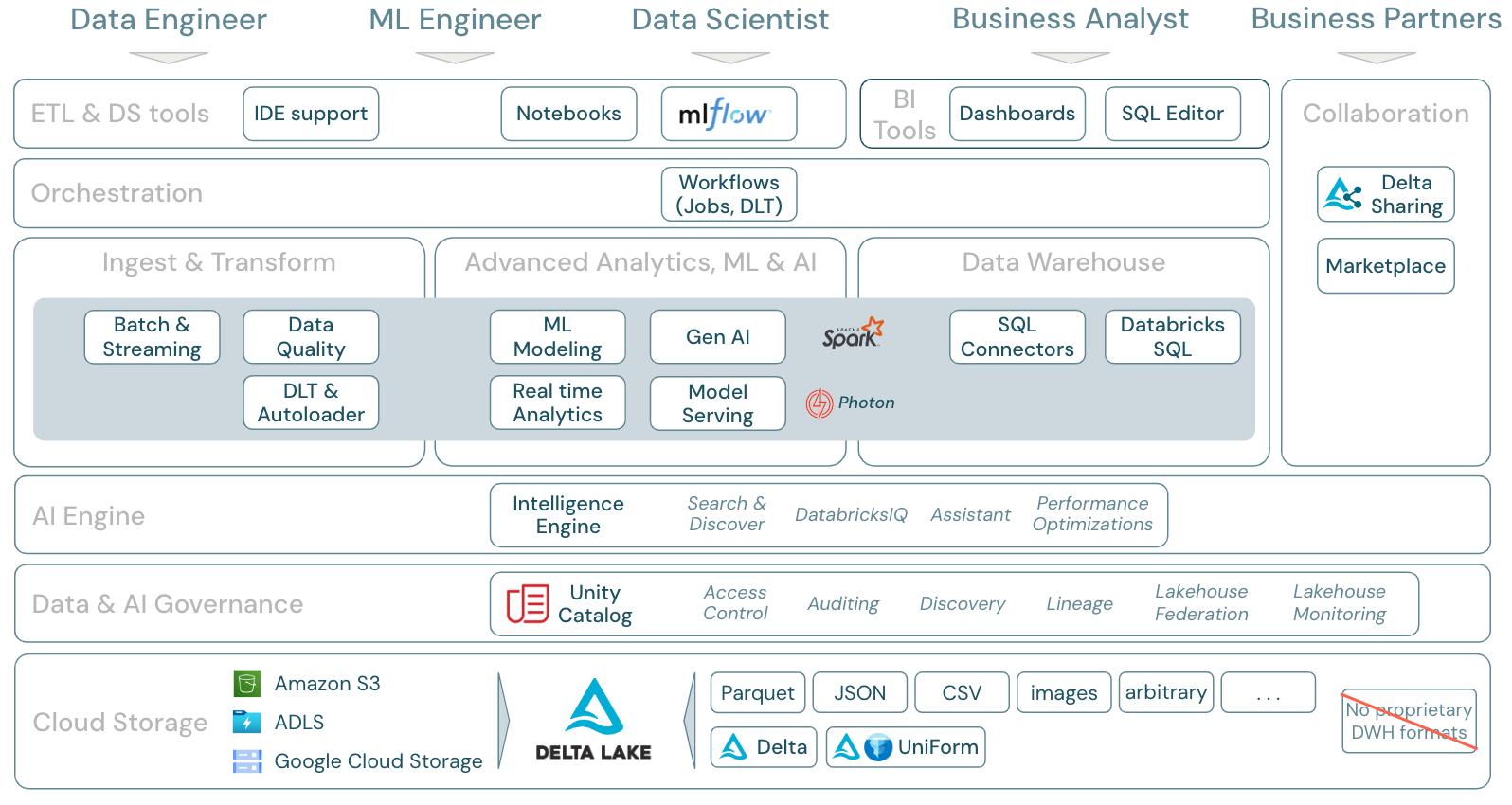
Download: Umfang des Lakehouse – Databricks-Komponenten
Datenworkloads in Azure Databricks
Vor allem deckt die Databricks Data Intelligence-Plattform alle relevanten Workloads für die Datendomäne in einer Plattform ab, mit Apache Spark/Photon als Engine:
Erfassung und Transformation
Für die Datenerfassung verarbeitet der Autoloader inkrementell und automatisch Dateien, die im Cloudspeicher landen, in geplanten oder kontinuierlichen Aufträgen – ohne dass Zustandsinformationen verwaltet werden müssen. Nach der Erfassung müssen Rohdaten transformiert werden, damit sie für BI und ML/KI bereit sind. Databricks bietet leistungsstarke ETL-Funktionen für technische und wissenschaftliche Fachkräfte für Daten sowie für Analysten.
Mit Delta Live Tables (DLT) können ETL-Aufträge auf deklarative Weise geschrieben werden, was den gesamten Implementierungsprozess vereinfacht. Die Datenqualität kann durch die Definition von Datenerwartungen verbessert werden.
Erweiterte Analysen, ML und KI
Die Plattform verfügt über Databricks Mosaic AI, eine Reihe von vollständig integrierten ML- und KI-Tools für klassisches maschinelles Lernen und Deep Learning sowie generative KI und große Sprachmodelle (LLMs). Sie deckt den gesamten Workflow von der Datenvorbereitung über die Erstellung von Modellen für maschinelles Lernen und Deep Learning bis hin zur Mosaic AI-Modellbereitstellung ab.
Strukturierte Spark-Streams und DLT ermöglichen Echtzeitanalysen.
Data Warehouse
Die Databricks Data Intelligence-Plattform hat auch eine komplette Data Warehouse-Lösung mit Databricks SQL, zentral verwaltet durch Unity Catalog mit differenzierter Zugriffssteuerung.
Gliederung der Azure Databricks-Featurebereiche
Dies ist eine Zuordnung der Funktionen der Databricks Data Intelligence-Plattform zu den anderen Ebenen des Frameworks, von unten nach oben:
Cloudspeicher
Alle Daten für das Lakehouse werden im Objektspeicher des Cloudanbieters gespeichert. Databricks unterstützt drei Cloudanbieter: AWS, Azure und GCP. Dateien in verschiedenen strukturierten und halbstrukturierten Formaten (z. B. Parquet, CSV, JSON und Avro) sowie unstrukturierte Formate (z. B. Bilder) werden entweder über Batch- oder Streamingprozesse erfasst und transformiert.
Delta Lake ist das empfohlene Datenformat für das Lakehouse (Dateitransaktionen, Zuverlässigkeit, Konsistenz, Aktualisierungen usw.) und ist vollständig quelloffen, um Abhängigkeit zu vermeiden. Das universelle Delta-Format (UniForm) ermöglicht außerdem das Lesen von Delta-Tabellen mit Iceberg-Leserclients.
In der Databricks Data Intelligence-Plattform werden keine proprietären Datenformate verwendet.
Datengovernance
Zusätzlich zur Speicherebene bietet Unity Catalog eine breite Palette an Datengovernancefunktionen, einschließlich Metadatenverwaltung im Metaspeicher, Zugriffssteuerung, Überwachung, Datenermittlung und Datenherkunft.
Lakehouse-Überwachung bietet sofort einsatzbereite Qualitätsmetriken für Daten und KI-Ressourcen sowie automatisch generierte Dashboards zur Visualisierung dieser Metriken.
Externe SQL-Quellen können über den Lakehouse-Verbund in das Lakehouse und Unity Catalog integriert werden.
KI-Modul
Die Data Intelligence-Plattform basiert auf der Lakehouse-Architektur und wird durch das Data Intelligence-Modul DatabricksIQ erweitert. DatabricksIQ kombiniert generative KI mit den Vereinheitlichungsvorteilen der Lakehouse-Architektur, um die einzigartige Semantik Ihrer Daten zu verstehen. Intelligente Suche und der Databricks-Assistent sind Beispiele für KI-gestützte Dienste, die die Arbeit mit der Plattform für alle Benutzer vereinfachen.
Orchestrierung
Mit Databricks-Aufträgen können Sie unterschiedliche Workloads für den gesamten Daten- und KI-Lebenszyklus in jeder Cloud ausführen. Sie ermöglichen Ihnen die Orchestrierung von Aufträgen sowie Delta Live Tables für SQL, Spark, Notebooks, DBT, ML-Modelle und mehr.
ETL- und DS-Tools
Auf der Verbrauchsebene nutzen technische Fachkräfte für Daten und ML in der Regel IDEs für das Arbeiten mit der Plattform. Wissenschaftliche Fachkräfte für Daten bevorzugen häufig Notebooks und verwenden die ML- und KI-Runtimes sowie das Workflowsystem für maschinelles Lernen MLflow, um Experimente nachzuverfolgen und den Modelllebenszyklus zu verwalten.
BI-Tools
Business Analysts verwenden in der Regel ihr bevorzugtes BI-Tool für den Zugriff auf das Databricks-Data Warehouse. Databricks SQL kann von verschiedenen Analyse- und BI-Tools abgefragt werden, siehe BI und Visualisierung.
Darüber hinaus bietet die Plattform standardmäßig Abfrage- und Analysetools:
- Dashboards zum Ziehen und Ablegen von Datenvisualisierungen und zum Teilen von Erkenntnissen.
- SQL-Editor für SQL-Analysten zum Analysieren von Daten.
Kollaboration
Delta Sharing ist ein von Databricks entwickeltes offenes Protokoll für eine sichere Datenfreigabe für andere Organisationen, unabhängig von den verwendeten Computingplattformen.
Databricks Marketplace ist ein offenes Forum für den Austausch von Datenprodukten. Dabei wird Delta Sharing genutzt, um Datenanbietern die Tools zum sicheren Teilen von Datenprodukten und Datenverbrauchern die Möglichkeit zu geben, ihren Zugriff auf die benötigten Daten und Datendienste zu erkunden und zu erweitern.