Worum handelt es sich bei der Medallion Lakehouse-Architektur?
Die Medaillon-Architektur beschreibt eine Reihe von Datenebenen, die die Qualität der im Lakehouse gespeicherten Daten kennzeichnen. Azure Databricks empfiehlt, einen mehrschichtigen Ansatz zum Erstellen einer einzigen Quelle der Wahrheit für Enterprise-Datenprodukte zu erstellen.
Diese Architektur garantiert Unteilbarkeit, Konsistenz, Isolierung und Dauerhaftigkeit, da die Daten mehrere Ebenen von Validierungen und Transformationen durchlaufen, bevor sie in einem für effiziente Analysen optimierten Layout gespeichert werden. Die Begriffe Bronze (roh), Silber (validiert) und Gold (angereichert) beschreiben die Qualität der Daten auf jeder dieser Ebenen.
Medallion-Architektur als Datenentwurfsmuster
Eine Medallion-Architektur ist ein Datenentwurfsmuster, das zum logischen Organisieren von Daten verwendet wird. Ziel ist es, die Struktur und Qualität der Daten inkrementell und schrittweise zu verbessern, da sie durch jede Ebene der Architektur fließt (aus Bronze ⇒ Silber ⇒ Gold-Schichttabellen). Medallion-Architekturen werden manchmal auch als Multi-Hop-Architekturen bezeichnet.
Durch den Fortschritt von Daten über diese Ebenen können Organisationen die Datenqualität und -zuverlässigkeit inkrementell verbessern, sodass sie für Business Intelligence- und Machine Learning-Anwendungen besser geeignet ist.
Das Folgen der Medallion-Architektur ist eine empfohlene bewährte Methode, aber keine Anforderung.
| Frage | Bronze | Silber | Gold |
|---|---|---|---|
| Was geschieht in dieser Ebene? | Rohdatenerfassung | Datenreinigung und -validierung | Dimensionale Modellierung und Aggregation |
| Wer ist der beabsichtigte Benutzer? | - Dateningenieure - Datenvorgänge – Compliance- und Überwachungsteams |
- Dateningenieure - Datenanalysten (verwenden Sie die Silver-Ebene für ein verfeinertes Dataset, das weiterhin detaillierte Informationen aufbewahrt, die für eine eingehende Analyse erforderlich sind) - Data Scientists (Erstellen von Modellen und Durchführen erweiterter Analysen) |
- Business Analysts und BI-Entwickler - Data Scientists und Machine Learning (ML) Ingenieure - Führungskräfte und Entscheidungsträger - Operative Teams |
Beispiel-Medallion-Architektur
Dieses Beispiel einer Medaillenarchitektur zeigt Bronze-, Silber- und Goldschichten für die Verwendung durch ein Geschäftsbetriebsteam. Jede Ebene wird in einem anderen Schema des Ops-Katalogs gespeichert.
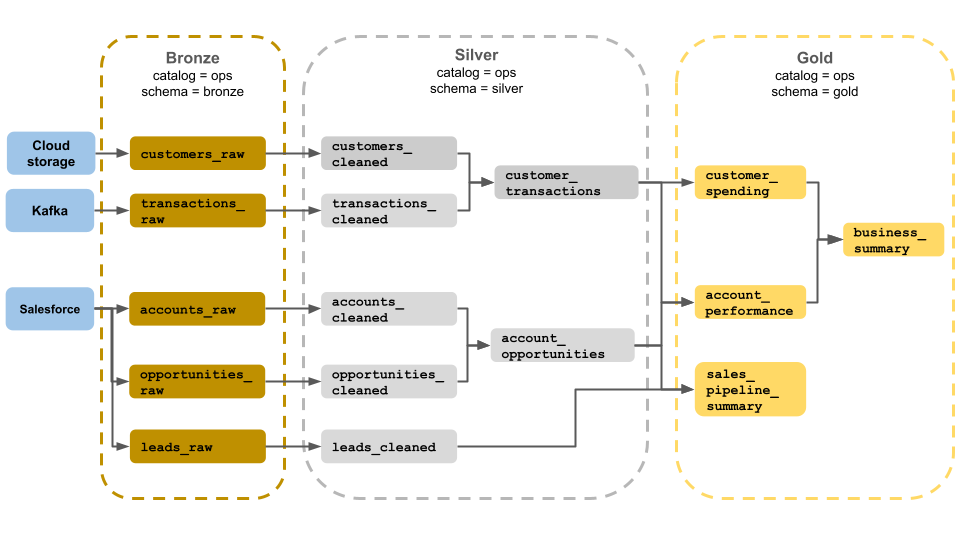
- Bronzeschicht (
ops.bronze): Erfasst Rohdaten aus Cloudspeicher, Kafka und Salesforce. Hier werden keine Datenbereinigungen oder Überprüfungen durchgeführt. - Silberschicht (
ops.silver): Datenbereinigung und -validierung werden auf dieser Ebene durchgeführt.- Daten zu Kunden und Transaktionen werden bereinigt, indem Nullen gelöscht und ungültige Datensätze in Quarantäne gesetzt werden. Diese Datasets werden mit einem neuen Dataset verknüpft, das aufgerufen wird
customer_transactions. Data Scientists können dieses Dataset für Predictive Analytics verwenden. - Ebenso werden Konten und Verkaufschancen-Datasets aus Salesforce verknüpft, um zu erstellen
account_opportunities, was mit Kontoinformationen erweitert wird. - Die
leads_rawDaten werden in einem Dataset bereinigt, das aufgerufen wirdleads_cleaned.
- Daten zu Kunden und Transaktionen werden bereinigt, indem Nullen gelöscht und ungültige Datensätze in Quarantäne gesetzt werden. Diese Datasets werden mit einem neuen Dataset verknüpft, das aufgerufen wird
- Goldschicht (
ops.gold): Diese Ebene wurde für Geschäftsbenutzer entwickelt. Es enthält weniger Datasets als Silber und Gold.customer_spending: Durchschnittliche und Gesamtausgaben für jeden Kunden.account_performance: Tägliche Leistung für jedes Konto.sales_pipeline_summary: Informationen zur End-to-End-Vertriebspipeline.business_summary: Hoch aggregierte Informationen für die Leitenden Mitarbeiter.
Erfassen von Rohdaten auf der Bronzeebene
Die Bronzeschicht enthält rohe, nichtvalidierte Daten. Die in der Bronzeschicht aufgenommenen Daten haben in der Regel die folgenden Merkmale:
- Enthält und verwaltet den rohen Zustand der Datenquelle in den ursprünglichen Formaten.
- Daten werden inkrementell hinzugefügt und wachsen mit der Zeit.
- Ist für den Verbrauch durch Workloads vorgesehen, die Daten für Silbertabellen anreichern, nicht für den Zugriff durch Analysten und Data Scientists.
- Dient als einzige Quelle der Wahrheit, wobei die Genauigkeit der Daten erhalten bleibt.
- Ermöglicht die Erneute Verarbeitung und Überwachung, indem alle historischen Daten aufbewahrt werden.
- Dabei kann es sich um eine beliebige Kombination aus Streaming- und Batchtransaktionen aus Quellen handeln, z. B. Cloudobjektspeicher (z. B. S3, GCS, ADLS), Nachrichtenbusse (z. B. Kafka, Kinesis usw.) und Verbundsysteme (z. B. Lakehouse Federation).
Einschränken der Datenbereinigung oder -validierung
Die minimale Datenüberprüfung erfolgt in der Bronzeschicht. Um vor verworfenen Daten sicherzustellen, empfiehlt Azure Databricks, die meisten Felder als Zeichenfolge, VARIANT oder Binärdatei zu speichern, um vor unerwarteten Schemaänderungen zu schützen. Metadatenspalten können hinzugefügt werden, z. B. die Herkunft oder Quelle der Daten (z. B _metadata.file_name . ).
Validieren und Deduplizieren von Daten auf der Silberebene
Die Datenbereinigung und -validierung werden in Silberschicht durchgeführt.
Bauen Sie silberne Tische aus der Bronzeschicht
Um die Silberschicht zu erstellen, lesen Sie Daten aus einem oder mehreren Bronze- oder Silbertabellen, und schreiben Sie Daten in Silbertabellen.
Azure Databricks empfiehlt sich nicht, direkt aus der Aufnahme in Silbertabellen zu schreiben. Wenn Sie direkt aus der Aufnahme schreiben, treten Fehler aufgrund von Schemaänderungen oder beschädigten Datensätzen in Datenquellen auf. Wenn alle Quellen nur angefügt sind, konfigurieren Sie die meisten Lesevorgänge aus Bronze als Streaminglesevorgänge. Batchlesevorgänge sollten für kleine Datasets reserviert werden (z. B. kleine dimensionale Tabellen).
Die Silberschicht stellt überprüfte, gereinigte und angereicherte Versionen der Daten dar. Die Silberschicht:
- Sollte immer mindestens eine validierte, nicht aggregierte Darstellung jedes Datensatzes enthalten. Wenn aggregierte Darstellungen viele nachgelagerte Workloads fördern, befinden sich diese Darstellungen möglicherweise in der Silberschicht, aber normalerweise befinden sie sich in der Goldschicht.
- Hier führen Sie datenbereinigung, Deduplizierung und Normalisierung durch.
- Verbessert die Datenqualität, indem Fehler und Inkonsistenzen korrigiert werden.
- Strukturiert Daten in einem konsumierbareren Format für die nachgelagerte Verarbeitung.
Erzwingen der Datenqualität
Die folgenden Vorgänge werden in Silbertabellen ausgeführt:
- Schemaerzwingung
- Behandeln von Null- und fehlenden Werten
- Datendeduplizierung
- Lösung von Problemen mit veralteten und verspätet eingehenden Daten
- Überprüfungen und Durchsetzung von Datenqualität
- Schema-Entwicklung
- Typumwandlung
- Joins
Modellieren von Daten beginnen
Es ist üblich, mit der Durchführung der Datenmodellierung in der Silberschicht zu beginnen, einschließlich der Auswahl, wie stark geschachtelte oder halbstrukturierte Daten dargestellt werden sollen:
- Verwenden Sie
VARIANTden Datentyp. - Verwenden Sie
JSONZeichenfolgen. - Erstellen sie Strukturen, Zuordnungen und Arrays.
- Flaches Schema oder Normalisieren von Daten in mehreren Tabellen.
Unterstützung von Analysen mit der Goldebene
Die Goldschicht stellt hoch verfeinerte Ansichten der Daten dar, die nachgelagerte Analysen, Dashboards, ML und Anwendungen fördern. Goldschichtdaten werden häufig hoch aggregiert und nach bestimmten Zeiträumen oder geografischen Regionen gefiltert. Sie enthält semantisch aussagekräftige Datasets, die Geschäftsfunktionen und -anforderungen zugeordnet sind.
Die Goldschicht:
- Besteht aus aggregierten Daten, die auf Analysen und Berichte zugeschnitten sind.
- Richtet sich an Geschäftslogik und Anforderungen.
- Ist für die Leistung in Abfragen und Dashboards optimiert.
Ausrichten an Geschäftslogik und Anforderungen
Auf der Goldschicht modellieren Sie Ihre Daten für die Berichterstellung und Analyse mithilfe eines dimensionalen Modells, indem Sie Beziehungen erstellen und Measures definieren. Analysten mit Zugriff auf Daten in Gold sollten in der Lage sein, domänenspezifische Daten zu finden und Fragen zu beantworten.
Da die Goldschicht eine Geschäftsdomäne modelliert, erstellen einige Kunden mehrere Goldschichten, um unterschiedliche Geschäftsanforderungen wie PERSONAL, Finanzen und IT zu erfüllen.
Erstellen von Aggregats, die auf Analysen und Berichte zugeschnitten sind
Organisationen müssen häufig Aggregatfunktionen für Measures wie Mittelwerte, Anzahl, Höchstwerte und Mindestwerte erstellen. Wenn Ihr Unternehmen beispielsweise Fragen zu wöchentlichen Gesamtverkäufen beantworten muss, könnten Sie eine materialisierte Ansicht erstellen, die diese weekly_sales Daten vorab aggregiert, sodass Analysten und andere nicht häufig verwendete materialisierte Ansichten neu erstellen müssen.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimieren der Leistung in Abfragen und Dashboards
Das Optimieren von Goldschichttabellen für die Leistung ist eine bewährte Methode, da diese Datasets häufig abgefragt werden. Auf große Mengen an historischen Daten wird in der Regel in der Schrägschicht zugegriffen und nicht in der Goldschicht materialisiert.
Steuern der Kosten durch Anpassen der Datenaufnahmehäufigkeit
Steuern Sie die Kosten, indem Sie bestimmen, wie häufig Daten aufgenommen werden sollen.
| Datenaufnahmehäufigkeit | Kosten | Latency | Deklarative Beispiele | Verfahrensbeispiele |
|---|---|---|---|---|
| Kontinuierliche inkrementelle Aufnahme | Höher | Niedriger | – Streamingtabelle, die spark.readStream zum Aufnehmen aus Cloudspeicher oder Nachrichtenbus verwendet wird.– Die Delta Live Tables-Pipeline, die diese Streamingtabelle aktualisiert, wird kontinuierlich ausgeführt. – Strukturierter Streamingcode, der spark.readStream in einem Notizbuch zum Aufnehmen aus Cloudspeicher oder Nachrichtenbus in eine Delta-Tabelle verwendet wird.– Das Notizbuch wird mit einem Azure Databricks-Auftrag mit einem fortlaufenden Auftragstrigger orchestriert. |
|
| Inkrementelle Aufnahme ausgelöst | Geringer | Höher | - StreamingTabellenaufnahme aus Cloudspeicher oder Nachrichtenbus mithilfe spark.readStreamvon .– Die Pipeline, die diese Streamingtabelle aktualisiert, wird durch den geplanten Trigger des Auftrags oder einen Dateiankunftsauslöser ausgelöst. – Strukturierter Streamingcode in einem Notizbuch mit einem Trigger.Available Trigger.– Dieses Notizbuch wird durch den geplanten Trigger des Auftrags oder einen Dateiankunftsauslöser ausgelöst. |
|
| Batchaufnahme mit manueller inkrementeller Erfassung | Geringer | Die höchste, aufgrund von seltenen Läufen. | - Streaming table ingest from cloud storage using spark.read.- Verwendet strukturiertes Streaming nicht. Verwenden Sie stattdessen Grundtypen wie Partitionsüberschreibung, um eine gesamte Partition gleichzeitig zu aktualisieren. - Erfordert eine umfangreiche upstream-Architektur, um die inkrementelle Verarbeitung einzurichten, was Kosten ermöglicht, die strukturierten Streaming-Lese-/Schreibvorgängen ähneln. - Erfordert außerdem die Partitionierung von Quelldaten nach einem datetime Feld und anschließendes Verarbeiten aller Datensätze aus dieser Partition in das Ziel. |