Erstellen einer Trainingsausführung mit der Benutzeroberfläche für das Training von Mosaic AI-Modellen
Wichtig
Dieses Feature ist in den folgenden Regionen als Public Preview verfügbar: centralus, eastus, eastus2, northcentralus und westus.
In diesem Artikel wird beschrieben, wie Sie eine Trainingsausführung mithilfe der Benutzeroberfläche für das Training von Mosaic AI-Modellen (früher Foundation Model Training) erstellen und konfigurieren. Sie können eine Ausführung auch mit der API erstellen. Anweisungen finden Sie unter Erstellen einer Trainingsausführung mithilfe der API für das Training von Mosaic AI-Modellen.
Anforderungen
Siehe Anforderungen.
Erstellen einer Trainingsausführung mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um mithilfe der Benutzeroberfläche eine Trainingsausführung zu erstellen.
Wählen Sie auf der linken Randleiste Experimente aus.
Wählen Sie auf der Karte Training von Mosaic AI-Modellen die Option Mosaic AI-Modellexperiment erstellen aus.
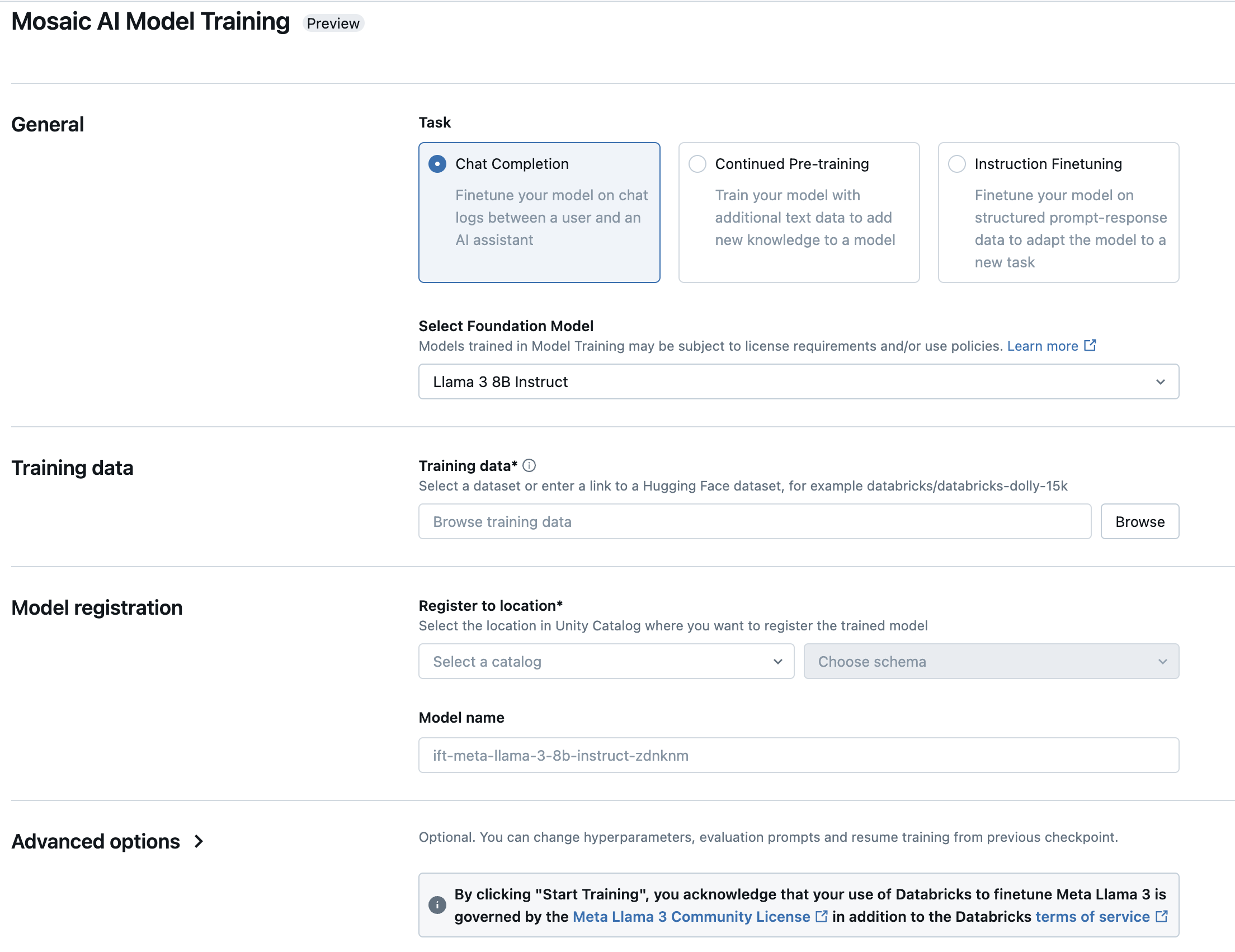
Das Formular Training von Mosaic AI-Modell wird geöffnet. Mit einem Sternchen gekennzeichnete Elemente müssen ausgefüllt werden. Treffen Sie Ihre Auswahl, und wählen Sie dann Training starten aus.
Typ: Wählen Sie die Aufgabe aus, die ausgeführt werden soll.
Aufgabe Beschreibung Anweisungsoptimierung Setzen Sie das Training eines Basismodells mit Prompt-Antwort-Eingaben fort, um das Modell für eine bestimmte Aufgabe zu optimieren. Fortlaufendes Vorabtraining Setzen Sie das Training eines Basismodells fort, um ihm themenspezifisches Wissen zu vermitteln. Chatvervollständigung Setzen Sie das Training eines Basismodells mit Chatprotokollen fort, um es für Frage/Antwort- oder Unterhaltungsanwendungen zu optimieren. Basismodell auswählen: Wählen Sie das Modell aus, das Sie optimieren oder trainieren möchten. Eine Liste der unterstützten Modelle finden Sie unter Unterstützte Modelle.
Trainingsdaten: Wählen Sie Durchsuchen aus, um eine Tabelle in Unity Catalog auszuwählen, oder geben Sie die vollständige URL eines Hugging Face-Datasets ein. Empfehlungen zur Datengröße finden Sie unter Empfohlene Datengröße für das Modelltraining.
Wenn Sie eine Tabelle in Unity Catalog auswählen, müssen Sie auch die Computeressourcen auswählen, die zum Lesen der Tabelle verwendet werden sollen.
Speicherort für Registrierung: Wählen Sie im Dropdownmenü den Unity Catalog-Katalog und das Schema aus. Das trainierte Modell wird an diesem Speicherort gespeichert.
Modellname: Das Modell wird mit diesem Namen im von Ihnen angegebenen Katalog und Schema gespeichert. In diesem Feld wird ein Standardname angezeigt, den Sie bei Bedarf ändern können.
Erweiterte Optionen: Für weitere Anpassungen können Sie optionale Einstellungen für die Auswertung, Hyperparameteroptimierung oder das Trainieren mit einem vorhandenen proprietären Modell konfigurieren.
Einstellung Beschreibung Training duration Dauer der Trainingsausführung in Epochen (z. B. 10ep) oder Token (z. B.1000000tok). Der Standardwert ist1ep.Learning rate (Lernrate) Die Lernrate für das Modelltraining. Der Standardwert ist 5e-7. Der Optimierer ist DecoupledLionW mit Betawerten von 0,99 und 0,95 und keinem Gewichtungsverfall. Der Planer für die Lernrate ist LinearWithWarmupSchedule mit einer Aufwärmrate von 2 % der gesamten Trainingsdauer und einem finalen Lernratenmultiplikator von 0 (null).Kontextlänge Die maximale Sequenzlänge einer Datenstichprobe. Daten, die länger als diese Einstellung sind, werden abgeschnitten. Die Standardeinstellung hängt vom ausgewählten Modell ab. Auswertungsdaten Wählen Sie Durchsuchen aus, um eine Tabelle in Unity Catalog auszuwählen, oder geben Sie die vollständige URL eines Hugging Face-Datasets ein. Wenn Sie dieses Feld leer lassen, wird keine Auswertung durchgeführt. Prompts zur Modellauswertung Geben Sie optionale Prompts ein, die zum Auswerten des Modells verwendet werden sollen. Experimentname Standardmäßig wird für jede Ausführung ein neuer automatisch generierter Name zugewiesen. Sie können optional einen benutzerdefinierten Namen eingeben oder ein vorhandenes Experiment aus der Dropdownliste auswählen. Benutzerdefinierte Gewichtungen Standardmäßig beginnt das Training mit den ursprünglichen Gewichtungen des ausgewählten Modells. Um mit benutzerdefinierten Gewichtungen von einem Composer-Prüfpunkt zu beginnen, geben Sie den Pfad zur Unity Catalog-Tabelle ein, die die Prüfpunktwerte enthält.
Nächste Schritte
Nach Abschluss der Trainingsausführung können Sie Metriken in MLflow überprüfen und Ihr Modell für Rückschlüsse bereitstellen. Lesen Sie die Schritte 5 bis 7 im Tutorial: Erstellen und Bereitstellen einer Mosaic AI Model Training-Ausführung.
Ein Beispiel finden Sie im Demo-Notebook für die Feinabstimmung von Instruktionen mit dem Titel Feinabstimmung von Instruktionen: Erkennung benannter Entitäten, das Sie durch die Datenvorbereitung, die Konfiguration des Feinabstimmungs-Trainingslaufs und die Bereitstellung führt.