April 2018
Releases werden gestaffelt. Ihr Azure Databricks-Konto wird möglicherweise erst eine Woche nach dem Datum der ersten Veröffentlichung aktualisiert.
Hinweis
In den Versions- und Kompatibilitätshinweisen von Databricks Runtime finden Sie jetzt Hinweise auf die Abschaffung von Databricks Runtime.
Geheimnis-CLI
26. April 2018
Version 0.7.0 der Databricks-CLI bietet Ihnen die Möglichkeit, Geheimnisse über die Befehlszeile zu verwalten. In der Geheimnisdokumentation wird nun gezeigt, wie Sie mit den Befehlen der Geheimnis-CLI Geheimnisse erstellen und verwalten können.
Siehe Verwaltung von Geheimnissen.
Deep Learning-Handbücher
24. April 2018
Es wurde eine Dokumentation für Deep Learning in Azure Databricks mit Verwendung von CPU-Clustern hinzugefügt.
Siehe Deep Learning.
Update für Geheimnis-API: Erstellen von Geheimnisbereichen
25. April – 1. Mai 2018: Version 2.70
Der Endpunkt zum Erstellen eines Geheimnisses (2.0/preview/secret/scopes/create) ersetzt ab sofort das Feld initial_manage_acl und verwendet stattdessen initial_manage_principal. Das neue Feld bietet die gleiche Funktionalität, aber eine bessere Semantik.
Weitere Informationen finden Sie unter Geheimnis-API 2.0.
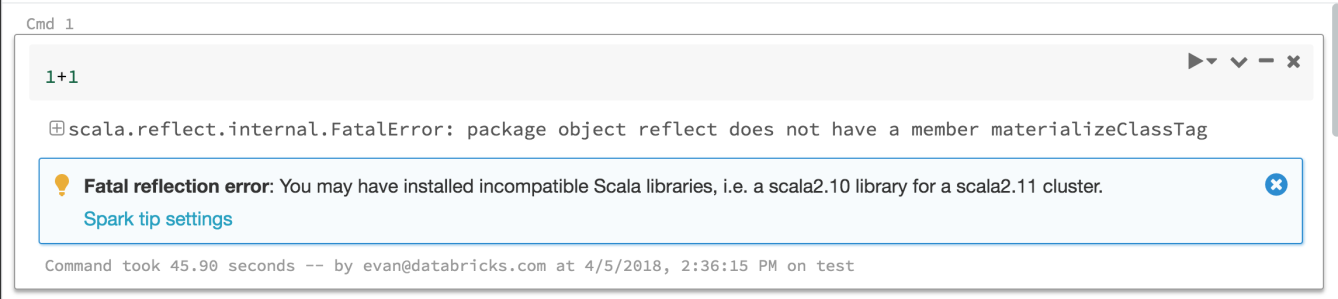
Tipps zu Spark-Fehlern
24. April – 1. Mai 2018: Version 2.70
Azure Databricks stellt ab sofort Tipps zur Verfügung, die Ihnen beim Interpretieren und Beheben vieler Fehler helfen, die beim Ausführen von Spark-Befehlen auftreten können. Und es werden weitere Tipps hinzukommen.
Databricks CLI 0.7.0
24. April 2018
Version 0.7.0 der Databricks-CLI enthält Fehlerbehebungen.
Außerdem wird eine Befehlszeilenschnittstelle für die Geheimnis-API bereitgestellt.
Siehe Databricks CLI (Legacy).
Heraufgesetztes Limit für die Kürzung der Initialisierungsskriptausgabe
24. April – 1. Mai 2018: Version 2.70
Das Limit bis zum Abschneiden der Ausgabe wurde für Initialisierungsskripts auf 500.000 Zeichen erhöht.
Weitere Informationen finden Sie unter Was sind Initskripts?.
Cluster-API: UPSIZE_COMPLETED-Ereignistyp hinzugefügt
24. April – 1. Mai 2018: Version 2.70
Der neue Clusterereignistyp UPSIZE_COMPLETED gibt an, dass die Hinzufügung von Knoten zu einem Cluster abgeschlossen ist.
Weitere Informationen finden Sie unter ClusterEventType in der Cluster-API-Referenz.
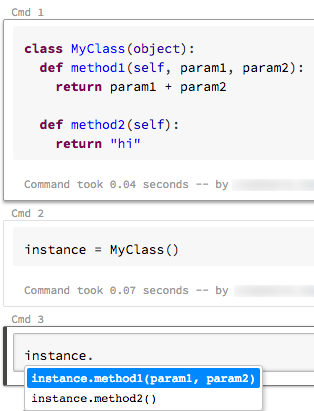
Befehl „AutoVervollständigen“
10. April – 17. April 2018: Version 2.69
Azure Databricks unterstützt jetzt zwei AutoVervollständigen-Typen in Ihren Notebooks: lokal und serverbasiert. Beim lokalen AutoVervollständigen werden Wörter vervollständigt, die im Notebook vorhanden sind. Beim serverbasierten AutoVervollständigen wird für definierte Typen, Klassen und Objekte sowie für SQL-Datenbank- und Tabellennamen auf den Cluster zugegriffen, deshalb ist diese Methode leistungsstärker. Um das serverbasierte AutoVervollständigen zu aktivieren, müssen Sie Ihr Notebook an einen ausgeführten Cluster anfügen und alle Zellen ausführen, die zu vervollständigende Objekte definieren.
Serverlose Pools auf Databricks Runtime 4.0 aktualisiert
10. April 2018
Die Runtimeversion für serverlose Pools wurde von Databricks Runtime 3.5 (diese schließt Apache Spark 2.2.1 ein) auf Databricks Runtime 4.0 aktualisiert (die Apache Spark 2.3.0 enthält). Sie müssen Ihre Cluster neu starten, um diese Änderung zu übernehmen.
Das Upgrade stellt eine geringfügige Aktualisierung der Apache Spark-Version dar und ist abwärtskompatibel.