Shiny in Azure Databricks
Shiny ist ein R-Paket, das in CRAN verfügbar ist und zum Erstellen interaktiver R-Anwendungen und -Dashboards verwendet wird. Sie können Shiny in RStudio Server verwenden, das auf Azure Databricks-Clustern gehostet wird. Sie können Shiny-Anwendungen auch direkt über ein Azure Databricks-Notebook entwickeln, hosten und freigeben.
Informationen zu den ersten Schritten mit Shiny finden Sie in den Tutorials zu Shiny. Sie können diese Tutorials in Azure Databricks ausführen.
In diesem Artikel wird beschrieben, wie Sie Shiny-Anwendungen in Azure Databricks ausführen und Apache Spark innerhalb von Shiny-Anwendungen verwenden.
Shiny in R-Notebooks
Erste Schritte mit Shiny in R-Notebooks
Das Shiny-Paket ist in Databricks Runtime inbegriffen. Sie können in Azure Databricks Shiny-Anwendungen auf ähnliche Weise wie im gehosteten RStudio in interaktiven R-Notebooks entwickeln und testen.
Führen Sie zum Einstieg die folgenden Schritte aus:
Erstellen Sie ein R-Notebook.
Importieren Sie das Shiny-Paket, und führen Sie die Beispiel-App
01_hellowie folgt aus:library(shiny) runExample("01_hello")Wenn die App bereit ist, enthält die Ausgabe die URL der Shiny-App als klickbaren Link, über den eine neue Registerkarte geöffnet wird. Informationen zum Freigeben dieser App für andere Benutzer finden Sie unter Freigeben der URL der Shiny-App.

Hinweis
- Protokollmeldungen werden im Befehlsergebnis angezeigt, ähnlich wie in der Standardprotokollmeldung (
Listening on http://0.0.0.0:5150), die im Beispiel gezeigt wird. - Klicken Sie auf Abbrechen, um die Shiny-App zu beenden.
- Die Shiny-App verwendet den Notebook-R-Prozess. Wenn Sie das Notebook vom Cluster trennen oder die Zelle, in der die Anwendung läuft, beenden, wird die Shiny-App beendet. Sie können keine anderen Zellen ausführen, solange die Shiny-App ausgeführt wird.
Ausführen von Shiny-Apps aus Databricks-Git-Ordnern
Sie können Shiny-Apps ausführen, die in Databricks-Git-Ordnern eingecheckt wurden.
Führen Sie die Anwendung aus.
library(shiny) runApp("006-tabsets")
Ausführen von Shiny-Apps aus Dateien
Wenn der Shiny-Anwendungscode Teil eines Projekts ist, das der Versionskontrolle unterliegt, können Sie ihn im Notebook ausführen.
Hinweis
Sie müssen den absoluten Pfad verwenden oder mit setwd() das Arbeitsverzeichnis festlegen.
Checken Sie den Code einem Repository aus, indem Sie Code wie diesen verwenden:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Um die Anwendung auszuführen, geben Sie einen Code ähnlich dem folgenden in eine andere Zelle ein:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Freigeben des URL der Shiny-App
Die URL der Shiny-App, die generiert wird, wenn Sie eine App starten, kann für andere Benutzer freigegeben werden. Jeder Azure Databricks-Benutzer mit der KANN ANFÜGEN AN-Berechtigung im Cluster kann die App anzeigen und mit ihr interagieren, solange sowohl die App als auch das Cluster ausgeführt werden.
Wenn der Cluster, in dem die App ausgeführt wird, beendet wird, ist kein Zugriff auf die App mehr möglich. Sie können in den Clustereinstellungen die automatische Beendigung deaktivieren.
Wenn Sie das Notebook, das die Shiny-App hostet, an einen anderen Cluster anfügen und dort ausführen, ändert sich die Shiny-URL. Auch wenn Sie die App im selben Cluster neu starten, könnte Shiny einen anderen Port nach dem Zufallsprinzip auswählen. Um eine stabile URL zu gewährleisten, können Sie die Option shiny.port festlegen oder beim Neustarten der App im selben Cluster das Argument port angeben.
Shiny auf gehostetem RStudio Server
Anforderungen
Wichtig
Mit RStudio Server Pro müssen Sie die Proxyauthentifizierung deaktivieren.
Stellen Sie sicher, dass auth-proxy=1 nicht in /etc/rstudio/rserver.conf vorhanden ist.
Erste Schritte mit Shiny auf gehostetem RStudio Server
Öffnen Sie RStudio in Azure Databricks.
Importieren Sie in RStudio das Shiny-Paket, und führen Sie die Beispiel-App
01_hellowie folgt aus:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Es wird ein neues Fenster mit der Shiny-Anwendung angezeigt.
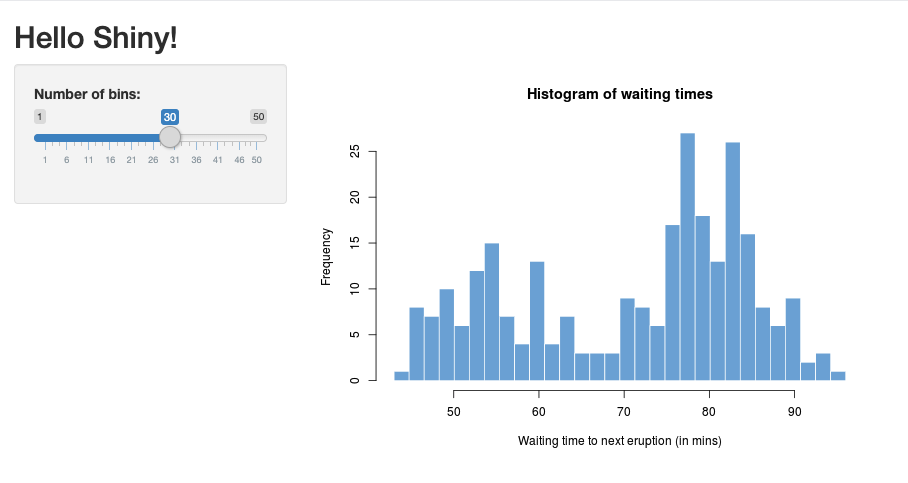
Ausführen einer Shiny-App über ein R-Skript
Um eine Shiny-App über ein R-Skript auszuführen, öffnen Sie das Skript im RStudio-Editor, und klicken Sie oben rechts auf die Schaltfläche App ausführen,.
Verwenden von Apache Spark in Shiny-Apps
Sie können Apache Spark innerhalb von Shiny-Apps entweder mit SparkR oder sparklyr verwenden.
Verwenden von SparkR mit Shiny in einem Notebook
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Verwenden von sparklyr mit Shiny in einem Notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
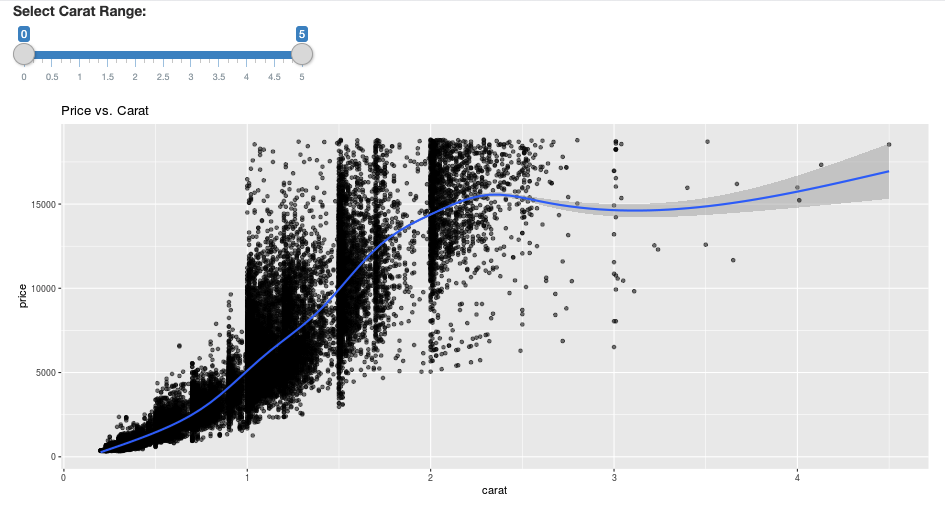
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Häufig gestellte Fragen (FAQ)
- Warum ist meine Shiny-App nach einiger Zeit abgeblendet?
- Warum verschwindet mein Shiny-Viewerfenster nach einer Weile?
- Warum werden lange Spark-Aufträge nie zurückgegeben?
- Wie kann ich das Timeout vermeiden?
- Meine App stürzt sofort nach dem Start ab, aber der Code scheint richtig zu sein. Was geht da vor?
- Wie viele Verbindungen können während der Entwicklung für einen Shiny-App-Link akzeptiert werden?
- Kann ich eine andere Version des Shiny-Pakets als die in Databricks Runtime installierte Version verwenden?
- Wie kann ich eine Shiny-Anwendung entwickeln, die auf einem Shiny-Server veröffentlicht werden und auf Daten in Azure Databricks zugreifen kann?
- Kann ich eine Shiny-Anwendung in einem Azure Databricks-Notebook entwickeln?
- Wie kann ich die Shiny-Anwendungen speichern, die ich auf dem gehosteten RStudio Server entwickelt habe?
Warum ist meine Shiny-App nach einiger Zeit abgeblendet?
Wenn keine Interaktion mit der Shiny-App erfolgt, wird die Verbindung mit der App nach ca. 4 Minuten geschlossen.
Um die Verbindung wiederherzustellen, aktualisieren Sie die Seite der Shiny-App. Der Dashboardzustand wird zurückgesetzt.
Warum verschwindet mein Shiny-Viewerfenster nach einer Weile?
Wenn das Fenster des Shiny-Viewers nicht mehr angezeigt wird, nachdem er sich mehrere Minuten im Leerlauf befunden hat, ist dies auf dasselbe Timeout wie das im „Abgeblendet“-Szenario zurückzuführen.
Warum werden lange Spark-Aufträge nie zurückgegeben?
Dies liegt ebenfalls am Leerlauftimeout. Jeder Spark-Auftrag, der länger als die zuvor erwähnten Timeouts ausgeführt wird, kann sein Ergebnis nicht rendern, da die Verbindung geschlossen wird, bevor der Auftrag zurückgegeben wird.
Wie kann ich das Timeout vermeiden?
Es gibt eine Problemumgehung, die in Featureanforderung: Der Client soll eine Keep Alive-Nachricht senden, um bei einigen Lastenausgleichsmodulen ein TCP-Timeout zu verhindern auf Github vorgeschlagen wird. Die Problemumgehung sendet Heartbeats, um die Websocket-Verbindung aktiv zu halten, wenn sich die App im Leerlauf befindet. Wenn die App jedoch durch eine zeitintensive Berechnung blockiert wird, funktioniert diese Problemumgehung nicht.
Shiny unterstütz keine zeitintensiven Aufgaben. In einem Shiny-Blogbeitrag wird empfohlen, Zusagen und Futures zu verwenden, um lange Aufgaben asynchron auszuführen und die App unblockiert zu halten. Im Folgenden finden Sie ein Beispiel, in dem Heartbeats verwendet werden, um die Shiny-App aktiv zu halten, und in dem ein zeitintensiver Spark-Auftrag in einem
future-Konstrukt ausgeführt wird.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Es gibt eine harte Grenze von 12 Stunden seit dem ersten Laden der Seite, nach der jede Verbindung, selbst wenn sie aktiv ist, beendet wird. Sie müssen die Shiny-App aktualisieren, um in diesen Fällen die Verbindung wiederherzustellen. Die zugrunde liegende WebSocket-Verbindung kann jedoch jederzeit durch eine Vielzahl von Faktoren wie Netzwerkinstabilität oder Computerruhezustand geschlossen werden. Databricks empfiehlt, Shiny-Apps so neuzuschreiben, dass sie keine langlebige Verbindung benötigen und sich nicht übermäßig auf den Sitzungszustand verlassen.
Meine App stürzt sofort nach dem Start ab, aber der Code scheint richtig zu sein. Was geht da vor?
Es gibt einen Grenzwert von 50 MB für die Gesamtmenge der Daten, die in einer Shiny-App in Azure Databricks angezeigt werden können. Wenn die Gesamtdatengröße der Anwendung diesen Grenzwert überschreitet, stürzt sie sofort nach dem Start ab. Um dies zu vermeiden, empfiehlt Databricks, die Datengröße zu reduzieren, z. B. durch Downsampling der angezeigten Daten oder durch Verringern der Auflösung von Bildern.
Wie viele Verbindungen können während der Entwicklung für einen Shiny-App-Link akzeptiert werden?
Databricks empfiehlt bis zu 20.
Kann ich eine andere Version des Shiny-Pakets als die in Databricks Runtime installierte Version verwenden?
Ja. Siehe Korrigieren der Version von R-Paketen.
Wie kann ich eine Shiny-Anwendung entwickeln, die auf einem Shiny-Server veröffentlicht werden und auf Daten in Azure Databricks zugreifen kann?
Sie können zwar während der Entwicklung und des Testens in Azure Databricks ganz natürlich mit SparkR oder sparklyr auf Daten zugreifen, doch nach der Veröffentlichung einer Shiny-Anwendung in einem eigenständigen Hostingdienst kann diese nicht direkt auf die Daten und Tabellen in Azure Databricks zugreifen.
Um Ihrer Anwendung die Funktion außerhalb von Azure Databricks zu ermöglichen, müssen Sie umschreiben, wie sie auf Daten zugreift. Es gibt ein paar Optionen:
- Verwenden Sie JDBC/ODBC, um Abfragen an einen Azure Databricks-Cluster zu übermitteln.
- Verwenden Sie Databricks Connect.
- Direktzugriff auf Daten im Objektspeicher.
Databricks empfiehlt, dass Sie gemeinsam mit Ihrem Azure Databricks-Lösungsteam arbeiten, um den besten Ansatz für Ihre vorhandene Daten- und Analysearchitektur zu finden.
Kann ich eine Shiny-Anwendung in einem Azure Databricks-Notebook entwickeln?
JA, Sie können eine Shiny-Anwendung in einem Azure Databricks-Notebook entwickeln.
Wie kann ich die Shiny-Anwendungen speichern, die ich auf dem gehosteten RStudio Server entwickelt habe?
Sie können Ihren Anwendungscode entweder in DBFS speichern oder Ihren Code in ein Versionskontrollsystem einchecken.