Warum inkrementelle Datenstromverarbeitung?
Die heutigen datengesteuerten Unternehmen produzieren kontinuierlich Daten, was technische Datenpipelinen erfordert, die diese Daten kontinuierlich aufnehmen und transformieren. Diese Pipelines sollten in der Lage sein, Daten genau einmal zu verarbeiten und bereitzustellen, Ergebnisse mit Latenzen von weniger als 200 Millisekunden zu erzielen und immer versuchen, Kosten zu minimieren.
In diesem Artikel werden Batch- und inkrementelle Streamverarbeitungsansätze für technische Datenpipelinen beschrieben, warum die inkrementelle Datenstromverarbeitung die bessere Option ist, und die nächsten Schritte für die ersten Schritte mit Databricks inkrementellen Datenstromverarbeitungsangeboten, Streaming auf Azure Databricks und Was ist Delta Live Tables?. Mit diesen Features können Sie Pipelines schnell schreiben und ausführen, die Die Übermittlungssemantik, Latenz, Kosten und vieles mehr garantieren.
Die Fallstricke wiederholter Batchaufträge
Beim Einrichten der Datenpipeline können Sie zunächst wiederholte Batchaufträge schreiben, um Ihre Daten aufzunehmen. Beispielsweise könnten Sie jede Stunde einen Spark-Auftrag ausführen, der aus Ihrer Quelle liest und Daten in eine Spüle wie Delta Lake schreibt. Die Herausforderung bei diesem Ansatz ist die inkrementelle Verarbeitung Ihrer Quelle, da der Spark-Auftrag, der alle Stunde ausgeführt wird, beginnen muss, wo die letzte beendet wurde. Sie können den neuesten Zeitstempel der verarbeiteten Daten aufzeichnen und dann alle Zeilen mit Zeitstempeln auswählen, die aktueller sind als dieser Zeitstempel, aber es gibt Fallstricke:
Um eine fortlaufende Datenpipeline auszuführen, können Sie versuchen, einen stündliche Batchauftrag zu planen, der inkrementell aus Ihrer Quelle liest, Transformationen durchführt und das Ergebnis in eine Spüle schreibt, z. B. Delta Lake. Dieser Ansatz kann Fallfälle haben:
- Ein Spark-Auftrag, der alle neuen Daten nach einem Zeitstempel abfragt, versäumt verspätete Daten.
- Ein Spark-Auftrag, der fehlschlägt, kann dazu führen, dass genau einmal garantiert wird, wenn er nicht sorgfältig behandelt wird.
- Ein Spark-Auftrag, der die Inhalte von Cloudspeicherorten auflistet, um neue Dateien zu finden, wird teuer.
Sie müssen diese Daten dann immer noch immer transformieren. Sie können wiederholte Batchaufträge schreiben, die dann Ihre Daten aggregieren oder andere Vorgänge anwenden, wodurch die Effizienz der Pipeline weiter erschwert und reduziert wird.
Ein Batchbeispiel
Beachten Sie die folgenden Beispiele, um die Fallstricke der Batchaufnahme und -transformation für Ihre Pipeline vollständig zu verstehen.
Verpasste Daten
Angesichts eines Kafka-Themas mit Nutzungsdaten, das bestimmt, wie viel Kunden belastet werden sollen, und Ihre Pipeline in Batches aufgenommen wird, kann die Abfolge von Ereignissen wie folgt aussehen:
- Ihr erster Batch enthält zwei Datensätze um 8 Uhr und 8:30 Uhr.
- Sie aktualisieren den neuesten Zeitstempel auf 8:30 Uhr.
- Sie erhalten einen weiteren Eintrag um 8:15 Uhr.
- Ihre zweite Batchabfrage nach allem nach 8:30 Uhr, sodass Sie den Datensatz um 8:15 Uhr verpassen.
Darüber hinaus möchten Sie Ihre Benutzer nicht überladen oder unterladen, damit Sie sicherstellen müssen, dass Sie jeden Datensatz genau einmal aufnehmen.
Redundante Verarbeitung
Angenommen, Ihre Daten enthalten Zeilen von Benutzerkäufen und möchten den Umsatz pro Stunde aggregieren, damit Sie die beliebtesten Zeiten in Ihrem Store kennen. Wenn Käufe für dieselbe Stunde in verschiedenen Batches ankommen, haben Sie mehrere Batches, die Ausgaben für dieselbe Stunde erzeugen:
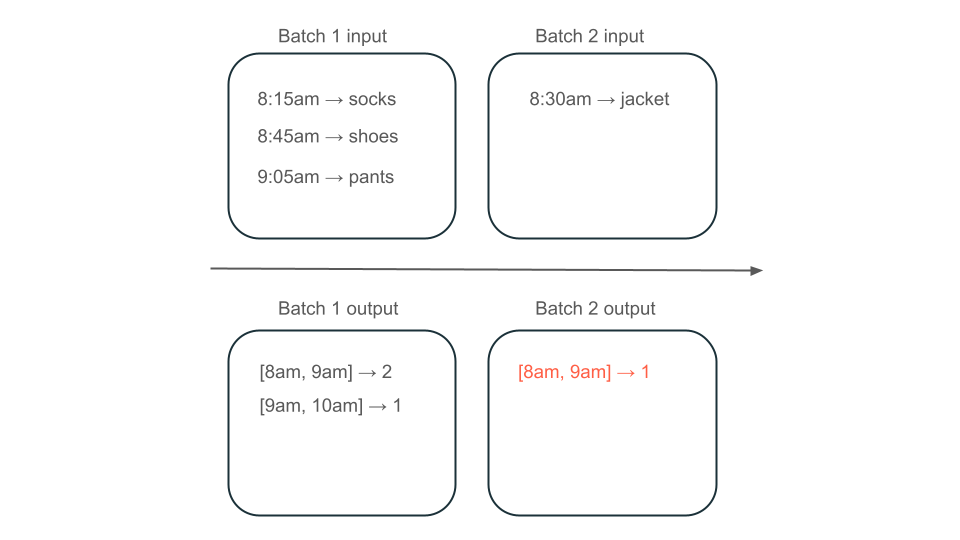
Verfügt das Fenster "8am" bis "9am" über zwei Elemente (die Ausgabe von Batch 1), ein Element (die Ausgabe von Batch 2) oder drei (die Ausgabe keiner der Batche)? Die daten, die erforderlich sind, um ein bestimmtes Zeitfenster zu erzeugen, werden in mehreren Batches der Transformation angezeigt. Um dies zu beheben, können Sie Ihre Daten täglich partitionieren und die gesamte Partition erneut verarbeiten, wenn Sie ein Ergebnis berechnen müssen. Anschließend können Sie die Ergebnisse in Ihrer Spüle überschreiben:
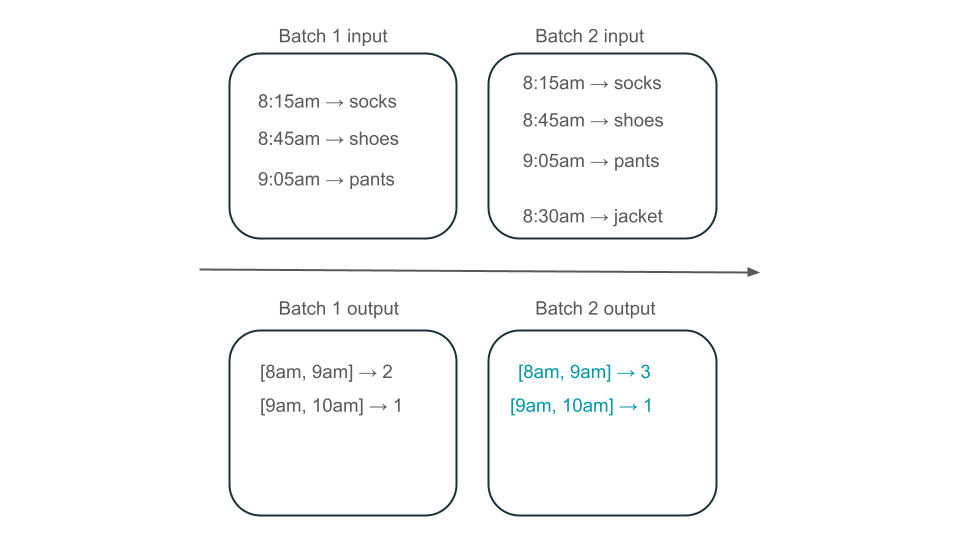
Dies geschieht jedoch auf Kosten von Latenz und Kosten, da der zweite Batch die unnötige Arbeit der Verarbeitung von Daten ausführen muss, die er möglicherweise bereits verarbeitet hat.
Keine Fallstricke mit inkrementeller Datenstromverarbeitung
Die inkrementelle Datenstromverarbeitung erleichtert das Vermeiden aller Fallstricke wiederholter Batchaufträge zum Aufnehmen und Transformieren von Daten. Databricks Structured Streaming and Delta Live Tables verwalten Implementierungskomplexe des Streamings, damit Sie sich nur auf Ihre Geschäftslogik konzentrieren können. Sie müssen nur angeben, mit welcher Quelle eine Verbindung hergestellt werden soll, mit welchen Transformationen die Daten erfolgen sollen und wo das Ergebnis geschrieben werden soll.
Inkrementelle Aufnahme
Die inkrementelle Aufnahme in Databricks wird von Apache Spark Structured Streaming unterstützt, das inkrementell eine Datenquelle verbrauchen und in eine Spüle schreiben kann. Das Structured Streaming-Modul kann Daten genau einmal nutzen, und das Modul kann Out-of-Order-Daten verarbeiten. Das Modul kann entweder in Notizbüchern oder mithilfe von Streamingtabellen in Delta Live Tables ausgeführt werden.
Das Structured Streaming-Modul auf Databricks bietet proprietäre Streamingquellen wie AutoLoader, die Clouddateien inkrementell auf kostengünstige Weise verarbeiten können. Databricks bietet auch Connectors für andere beliebte Nachrichtenbusse wie Apache Kafka, Amazon Kinesis, Apache Pulsar und Google Pub/Sub.
Inkrementelle Transformation
Mit der inkrementellen Transformation in Databricks mit strukturiertem Streaming können Sie Transformationen in DataFrames mit derselben API wie eine Batchabfrage angeben, daten jedoch über Batches und aggregierte Werte im Laufe der Zeit nachverfolgen, sodass Sie nicht müssen. Es muss keine Daten erneut verarbeiten, sodass es schneller und kostengünstiger ist als wiederholte Batchaufträge. Strukturiertes Streaming erzeugt einen Datenstrom, den er an Ihre Spüle anfügen kann, z. B. Delta Lake, Kafka oder einen anderen unterstützten Connector.
Materialisierte Ansichten in Delta Live Tables werden vom Enzymmodul unterstützt. Enzyme verarbeitet Ihre Quelle immer noch inkrementell, aber anstatt einen Datenstrom zu produzieren, erstellt es eine materialisierte Ansicht, bei der es sich um eine vorab berechnete Tabelle handelt, in der die Ergebnisse einer Abfrage gespeichert werden, die Sie ihm zugeben. Enzyme ist in der Lage, effizient zu bestimmen, wie sich neue Daten auf die Ergebnisse Ihrer Abfrage auswirken, und es hält die vorab berechnete Tabelle auf dem neuesten Stand.
Materialisierte Ansichten erstellen eine Ansicht über Ihrem Aggregat, die immer effizient aktualisiert wird, sodass Sie beispielsweise in dem oben beschriebenen Szenario wissen, dass das 8am-9am-Fenster drei Elemente aufweist.
Strukturierte Streaming- oder Delta Live-Tabellen?
Der wesentliche Unterschied zwischen strukturiertem Streaming und Delta Live Tables ist die Art und Weise, in der Sie Ihre Streamingabfragen operationalisieren. In Structured Streaming geben Sie manuell viele Konfigurationen an, und Sie müssen Abfragen manuell zusammenfügen. Sie müssen Abfragen explizit starten, warten, bis sie beendet werden, sie bei Einem Fehler abbrechen und andere Aktionen ausführen. In Delta Live Tables geben Sie Delta Live Tables deklarativ an, dass Ihre Pipelines ausgeführt werden, und sie werden weiterhin ausgeführt.
Delta Live Tables verfügt auch über Features wie materialisierte Ansichten, die transformationen Ihrer Daten effizient und inkrementell vorkompilieren.
Weitere Informationen zu diesen Features finden Sie unter Streaming auf Azure Databricks und Was ist Delta Live Tables?.
Nächste Schritte
Erstellen Sie Ihre erste Pipeline mit Delta Live Tables. Siehe Tutorial: Ausführen Ihrer ersten Delta Live Tables-Pipeline.
Führen Sie Ihre ersten strukturierten Streaming-Abfragen auf Databricks aus. Siehe "Ausführen Ihrer ersten strukturierten Streaming-Workload".
Verwenden Sie eine materialierte Ansicht. Weitere Informationen finden Sie unter Verwenden materialisierter Sichten in Databricks SQL.