Verwenden von Apache Oozie mit Apache Hadoop zum Definieren und Ausführen eines Workflows in Linux-basiertem Azure HDInsight
Hier erfahren Sie, wie Sie Apache Oozie mit Apache Hadoop in Azure HDInsight verwenden. Oozie ist ein Workflow- und Koordinationssystem zur Verwaltung von Hadoop-Aufträgen. Oozie ist in den Hadoop-Stack integriert und unterstützt die folgenden Aufträge:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Sie können Oozie auch dazu verwenden, bestimmte Aufträge für ein System zu planen, beispielsweise Java-Programme oder Shellskripts.
Hinweis
Eine weitere Option zum Definieren von Workflows mit HDInsight ist die Verwendung von Azure Data Factory. Weitere Informationen zu Data Factory finden Sie unter Verwenden von Apache Pig und Apache Hive mit Data Factory. Informationen zur Verwendung von Oozie in Clustern mit dem Enterprise-Sicherheitspaket finden Sie unter Ausführen von Apache Oozie in in die Domäne eingebundenen HDInsight Hadoop-Clustern.
Voraussetzungen
Einen Hadoop-Cluster in HDInsight. Weitere Informationen finden Sie unter Erste Schritte mit HDInsight unter Linux.
SSH-Client. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit HDInsight (Apache Hadoop) per SSH.
Eine Azure SQL-Datenbank. Weitere Informationen finden Sie unter Erstellen einer Datenbank in Azure SQL-Datenbank im Azure-Portal. Der Artikel verwendet eine Datenbank namens oozietest.
Das URI-Schema für Ihren primären Clusterspeicher.
wasb://für Azure Storage,abfs://für Azure Data Lake Storage Gen2 oderadl://für Azure Data Lake Storage Gen1. Wenn die sichere Übertragung für Azure Storage aktiviert ist, lautet der URIwasbs://. Siehe auch Vorschreiben einer sicheren Übertragung in Azure Storage.
Beispielworkflow
Der in diesem Dokument verwendeten Workflows weist zwei Aktionen auf. Aktionen sind Definitionen von Aufgaben, z.B. das Ausführen von Hive, Sqoop, MapReduce oder anderen Prozessen:
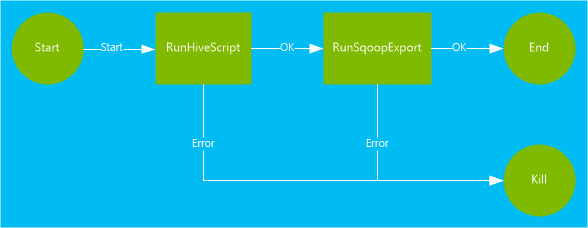
Eine Hive-Aktion führt ein HiveQL-Skript zum Extrahieren von Datensätzen aus der in HDInsight enthaltenen Tabelle
hivesampletableaus. Jede Datenzeile beschreibt einen Besuch eines bestimmten Mobilgeräts. Das Format des Eintrags sieht ähnlich wie der folgende Text aus:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Das in diesem Dokument verwendete Hive-Skript zählt die gesamten Besuche jeder Plattform (z.B. Android oder iPhone) und speichert die Werte in einer neuen Hive-Tabelle.
Weitere Informationen zu Hive finden Sie unter „[Verwenden von Apache Hive mit HDInsight][hdinsight-use-hive]“.
Die Sqoop-Aktion exportiert den Inhalt der neuen Hive-Tabelle in eine Tabelle, die in Azure SQL-Datenbank erstellt wurde. Weitere Informationen zu Sqoop finden Sie unter Verwenden von Sqoop mit Hadoop in HDInsight.
Hinweis
Informationen zu den unterstützten Oozie-Versionen in HDInsight-Clustern finden Sie unter Neuheiten in den von HDInsight bereitgestellten Hadoop-Clusterversionen.
Erstellen des Arbeitsverzeichnisses
Oozie erwartet, dass die für einen Auftrag erforderlichen Ressourcen im selben Verzeichnis gespeichert werden. In diesem Beispiel wird wasbs:///tutorials/useoozie verwendet. Erstellen Sie das Verzeichnis, und führen Sie die folgenden Schritte aus:
Bearbeiten Sie den Code unten so, dass
sshuserdurch den SSH-Benutzername für den Cluster ersetzt wird, und ersetzen SieCLUSTERNAMEdurch den Namen des Clusters. Geben Sie dann den Code ein, um mithilfe von SSH eine Verbindung mit dem HDInsight-Cluster herzustellen.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerwenden Sie zum Erstellen des Verzeichnisses den folgenden Befehl:
hdfs dfs -mkdir -p /tutorials/useoozie/dataHinweis
Der Parameter
-pbewirkt, dass alle Verzeichnisse im Pfad erstellt werden. Das Verzeichnisdatadient zum Speichern der Daten, die vom Skriptuseooziewf.hqlverwendet werden.Bearbeiten Sie den Code unten so, dass
sshuserdurch Ihren SSH-Benutzername ersetzt wird. Führen Sie den folgenden Befehl aus, damit Oozie die Identität Ihres Benutzerkontos annehmen kann:sudo adduser sshuser usersHinweis
Sie können Fehler ignorieren, die besagen, dass der Benutzer bereits Mitglied der Gruppe
usersist.
Hinzufügen eines Datenbanktreibers
Dieser Workflow verwendet Sqoop zum Exportieren von Daten in die SQL-Datenbank. Deshalb müssen Sie eine Kopie des JDBC-Treibers bereitstellen, der für die Interaktion mit der SQL-Datenbank verwendet wird. Führen Sie den folgenden Befehl in der SSH-Sitzung aus, um den JDBC-Treiber in das Arbeitsverzeichnis zu kopieren:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Wichtig
Überprüfen Sie den tatsächlichen JDBC-Treiber, der unter dem Pfad /usr/share/java/ verfügbar ist.
Wenn Ihr Workflow andere Ressourcen wie z.B. eine JAR-Datei mit einer MapReduce-Anwendung verwendet hat, müssen Sie diese Ressourcen ebenfalls hinzufügen.
Definieren der Hive-Abfrage
Verwenden Sie die folgenden Schritte, um ein Skript der Hive-Abfragesprache (HiveQL) zu erstellen, das eine Abfrage definiert. Sie verwenden die Abfrage in einem Oozie-Workflow weiter unten in diesem Dokument.
Führen Sie über die SSH-Verbindung den folgenden Befehl aus, um eine Datei mit dem Namen
useooziewf.hqlzu erstellen:nano useooziewf.hqlNachdem der GNU-Nano-Editor geöffnet wurde, verwenden Sie die folgende Abfrage als Inhalt der Datei:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Im Skript werden zwei Variablen verwendet:
${hiveTableName}: Enthält den Namen der zu erstellenden Tabelle.${hiveDataFolder}: Enthält den Speicherort der Datendateien für die Tabelle.Die Workflowdefinitionsdatei („workflow.xml“ in diesem Artikel) übergibt diese Werte zur Laufzeit an das HiveQL-Skript.
Um die Datei zu speichern, drücken Sie STRG+X, geben Sie J ein, und drücken Sie auf die EINGABETASTE.
Führen Sie den folgenden Befehl aus, um
useooziewf.hqlnachwasbs:///tutorials/useoozie/useooziewf.hqlzu kopieren:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlMit diesem Befehl wird die Datei
useooziewf.hqlin dem mit Hadoop Distributed File System kompatiblen Speicher für den Cluster gespeichert.
Definieren des Workflows
Oozie-Workflowdefinitionen sind in der Sprache der Hadoop-Prozessdefinition (hPDL) geschrieben. Dabei handelt es sich um eine Sprache der XML-Prozessdefinition. Führen Sie zum Definieren des Workflows die folgenden Schritte aus:
Verwenden Sie die folgende Anweisung zum Erstellen und Bearbeiten einer neuen Datei:
nano workflow.xmlNachdem der Nano-Editor geöffnet wurde, verwenden Sie den folgenden XML-Code als Inhalt der Datei:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Im Workflow sind zwei Aktionen definiert:
RunHiveScript: Diese Aktion ist die Startaktion und führt das Hive-Skriptuseooziewf.hqlaus.RunSqoopExport:Diese Aktion exportiert die vom Hive-Skript erstellten Daten mithilfe von Sqoop in die SQL-Datenbank. Diese Aktion wird nur ausgeführt, wenn die AktionRunHiveScripterfolgreich war.Der Workflow weist mehrere Einträge auf, z.B.
${jobTracker}. Sie ersetzen diese Einträge durch die Werte, die Sie in der Auftragsdefinition verwenden. Sie erstellen die Auftragsdefinition weiter unten in diesem Dokument.Beachten Sie auch den Eintrag
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>im Abschnitt „Sqoop“. Dieser Eintrag weist Oozie an, dieses Archiv für Sqoop zur Verfügung zu stellen, wenn diese Aktion ausgeführt wird.
Um die Datei zu speichern, drücken Sie STRG+X, geben Sie J ein, und drücken Sie auf die EINGABETASTE.
Kopieren Sie mit folgendem Befehl die Datei
workflow.xmlnach/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Erstellen einer Tabelle
Hinweis
Es gibt viele Möglichkeiten, zum Erstellen einer Tabelle eine Verbindung mit SQL Database herzustellen. Die folgenden Schritte verwenden FreeTDS aus dem HDInsight-Cluster.
Verwenden Sie den folgenden Befehl, um FreeTDS im HDInsight-Cluster zu installieren:
sudo apt-get --assume-yes install freetds-dev freetds-binBearbeiten Sie den Code unten so, dass
<serverName>durch den Namen Ihres logischen SQL-Servers ersetzt wird und<sqlLogin>durch die Serveranmeldung. Geben Sie den Befehl ein, um eine Verbindung mit der vorausgesetzten SQL-Datenbank herzustellen. Geben Sie in der Eingabeaufforderung das Kennwort ein.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestSie erhalten dann eine Ausgabe wie etwa den folgenden Text:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Geben Sie bei der Eingabeaufforderung
1>folgende Zeilen ein:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GONach Eingabe der Anweisung
GOwerden die vorherigen Anweisungen ausgewertet. Mithilfe dieser Anweisungen wird eine Tabelle mit dem Namenmobiledataerstellt, die vom Workflow verwendet wird.Um sicherzustellen, dass die Tabelle erstellt wurde, verwenden Sie die folgenden Befehle:
SELECT * FROM information_schema.tables GOIhnen sollte eine Ausgabe wie der folgende Text angezeigt werden:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEGeben Sie zum Beenden des Dienstprogramms „tsql“ in die Eingabeaufforderung
1>den Befehlexitein.
Erstellen der Auftragsdefinition
Die Auftragsdefinition beschreibt, wo sich die workflow.xml-Datei befindet. Sie beschreibt außerdem, wo sich andere vom Workflow verwendete Dateien (wie etwa useooziewf.hql) befinden. Sie definiert auch die Werte für Eigenschaften, die innerhalb des Workflows verwendet werden, und die zugeordneten Dateien.
Geben Sie den folgenden Befehl ein, um die vollständige Adresse des Standardspeichers abzurufen. Diese Adresse wird in der Konfigurationsdatei verwendet, die Sie im nächsten Schritt erstellen.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlDie in der Rückgabe dieses Befehls enthaltenen Informationen sind ähnlich dem folgenden XML-Code:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Hinweis
Falls der HDInsight-Cluster Azure Storage als Standardspeicher verwendet, beginnt der Inhalt des Elements
<value>mitwasbs://. Wenn stattdessen Azure Data Lake Storage Gen1 verwendet wird, beginnt er mitadl://. Wenn Azure Data Lake Storage Gen2 verwendet wird, beginnt er mitabfs://.Speichern Sie den Inhalt des Elements
<value>. Dieser wird im nächsten Schritt verwendet.Bearbeiten Sie das xml-Dokument unten folgendermaßen:
Platzhalterwert Ersetzter Wert wasbs://mycontainer@mystorageaccount.blob.core.windows.net Wert aus Schritt 1 admin Ihr Anmeldename für den HDInsight-Cluster, falls Sie kein Administrator sind. serverName Name des Azure SQL-Datenbank-Servers sqlLogin Anmeldung des Azure SQL-Datenbank-Servers sqlPassword Anmeldekennwort des Azure SQL-Datenbank-Servers <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>Die meisten der Informationen in dieser Datei dienen zum Auffüllen der Werte, die in der Datei „workflow.xml“ oder „ooziewf.hql“ (z.B.
${nameNode}) verwendet werden. Wenn der Pfad ein Pfad des Typswasbsist, müssen Sie den vollständigen Pfad verwenden. Verkürzen Sie ihn nicht bloß aufwasbs:///. Der Eintragoozie.wf.application.pathdefiniert, wo die Datei „workflow.xml“ zu finden ist. Diese Datei enthält den Workflow, der von diesem Auftrag ausgeführt wurde.Verwenden Sie zum Erstellen der Konfiguration der Oozie-Auftragsdefinition den folgenden Befehl:
nano job.xmlNachdem der Nano-Editor geöffnet wurde, fügen Sie den bearbeiteten XML-Code als Inhalt der Datei ein.
Um die Datei zu speichern, drücken Sie STRG+X, geben Sie J ein, und drücken Sie auf die EINGABETASTE.
Übermitteln und Verwalten des Auftrags
Die folgenden Schritte verwenden den Oozie-Befehl zum Übermitteln und Verwalten von Oozie-Workflows im Cluster. Der Oozie-Befehl ist eine benutzerfreundliche Schnittstelle, die über die Oozie-REST-APIzur Verfügung steht.
Wichtig
Wenn Sie den Oozie-Befehl verwenden, müssen Sie den vollqualifizierten Domänennamen (FQDN) des HDInsight-Hauptknotens verwenden. Auf diesen FQDN kann nur innerhalb des Clusters zugegriffen werden. Wenn der Cluster sich in einem virtuellen Azure-Netzwerk befindet, ist der Zugriff von anderen Computern im selben Netzwerk möglich.
Geben Sie zum Abrufen der URL des Oozie-Diensts den folgenden Befehl an:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlDie zurückgegebenen Informationen ähneln dem folgenden XML-Code:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>Der Teil
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieist die mit dem Oozie-Befehl zu verwendende URL.Bearbeiten Sie den Code so, dass die URL durch diejenige ersetzt wird, die Sie zuvor erhalten haben. Geben Sie Folgendes an, um eine Umgebungsvariable für die URL erstellen, damit Sie sie nicht für jeden Befehl eingeben müssen:
export OOZIE_URL=http://HOSTNAMEt:11000/oozieGeben Sie zum Übermitteln des Auftrags Folgendes an:
oozie job -config job.xml -submitMit diesem Befehl werden die Auftragsinformationen aus der Datei
job.xmlgeladen und an Oozie übermittelt, ohne dass die Datei ausgeführt wird.Nach Abschluss des Befehls sollte die ID des Auftrags zurückgegeben werden, z.B.
0000005-150622124850154-oozie-oozi-W. Diese ID wird verwendet, um den Auftrag zu verwalten.Bearbeiten Sie den Code unten so, dass
<JOBID>durch die ID ersetzt wird, die im vorherigen Schritt zurückgegeben wurde. Verwenden Sie den folgenden Befehl, um den Status des Auftrags zu prüfen:oozie job -info <JOBID>Die Ausgabe sieht in etwa wie der folgende Text aus:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Dieser Auftrag hat den Status
PREP. Dieser Status gibt an, dass der Auftrag erstellt, aber nicht gestartet wurde.Bearbeiten Sie den Code unten so, dass
<JOBID>durch die ID ersetzt wird, die zuvor zurückgegeben wurde. Verwenden Sie den folgenden Befehl zum Starten des Auftrags:oozie job -start <JOBID>Wenn Sie nach diesem Befehl den Status überprüfen, lautet dieser „Wird ausgeführt“, und Informationen für die Aktionen innerhalb des Auftrags werden zurückgegeben. Die Ausführung des Auftrags nimmt einige Minuten in Anspruch.
Bearbeiten Sie den Code unten so, dass
<serverName>durch Ihren Servernamen ersetzt wird und<sqlLogin>durch die Serveranmeldung. Sobald die Aufgabe erfolgreich abgeschlossen wurde, können Sie mit dem folgenden Befehl überprüfen, ob die Daten generiert wurden und ob die SQL-Datenbanktabelle exportiert wurde. Geben Sie in der Eingabeaufforderung das Kennwort ein.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestGeben Sie bei der Eingabeaufforderung
1>folgende Abfrage ein:SELECT * FROM mobiledata GODie zurückgegebenen Informationen ähneln dem folgenden Text:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Weitere Informationen zum Oozie-Befehl finden Sie unter Apache Oozie-Befehlszeilentool.
Oozie-REST-API
Mit der Oozie-REST-API können Sie eigene Tools erstellen, die mit Oozie arbeiten. Die folgenden Informationen zur Verwendung der Oozie-REST-API sind HDInsight-spezifisch:
URI: Unter
https://CLUSTERNAME.azurehdinsight.net/ooziekönnen Sie von außerhalb des Clusters auf die REST-API zugreifen.Authentifizierung: Verwenden Sie die API mit dem HTTP-Clusteradministratorkonto und -kennwort, um sich zu authentifizieren. Beispiel:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Weitere Informationen zur Verwendung der Oozie-REST-API finden Sie unter Apache Oozie-Webdienste-API.
Oozie-Webbenutzeroberfläche
Die Oozie-Webbenutzeroberfläche bietet eine webbasierte Anzeige des Status von Oozie-Aufträgen im Cluster. In der Web-UI können Sie die folgenden Informationen anzeigen:
- Auftragsstatus
- Auftragsdefinition
- Konfiguration
- Ein Diagramm der im Auftrag enthaltenen Aktionen
- Protokolle für den Auftrag
Sie können auch die Informationen zu den Aktionen innerhalb eines Auftrags anzeigen.
Um auf die Oozie-Webbenutzeroberfläche zuzugreifen, gehen Sie folgendermaßen vor:
Erstellen Sie einen SSH-Tunnel zum HDInsight-Cluster. Weitere Informationen finden Sie unter Verwenden von SSH-Tunneling mit HDInsight.
Nachdem Sie einen Tunnel erstellt haben, öffnen Sie mithilfe des URI
http://headnodehost:8080die Ambari-Webbenutzeroberfläche in Ihrem Webbrowser.Klicken Sie auf der linken Seite der Seite auf Oozie>QuickLinks>Oozie Web UI.
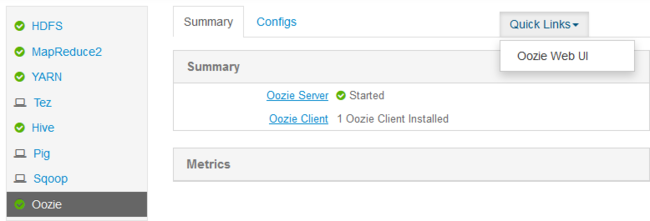
Die Oozie-Webbenutzeroberfläche zeigt standardmäßig aktive Workflowaufträge an. Klicken Sie zum Anzeigen aller Workflowaufträge auf Alle Aufträge.
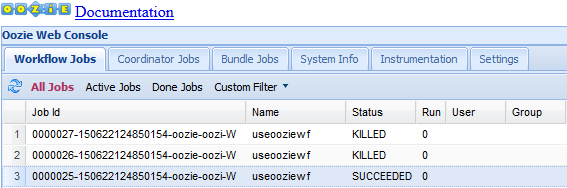
Um weitere Informationen über einen Auftrag anzuzeigen, klicken Sie auf den Auftrag.
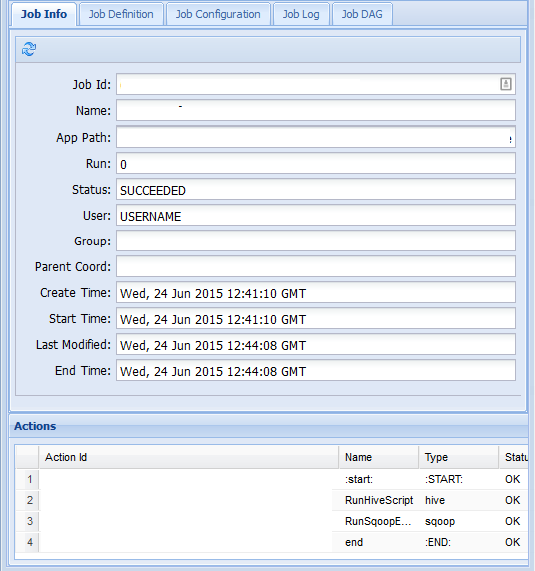
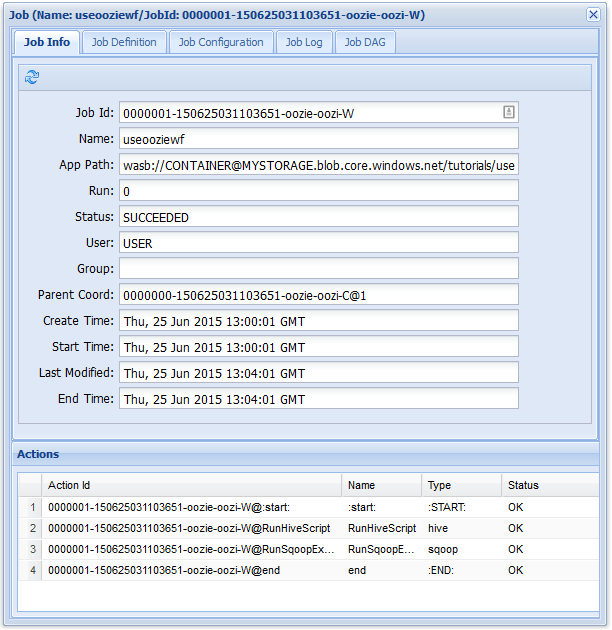
Auf der Registerkarte Auftragsinformationen können Sie die grundlegenden Auftragsinformationen und die einzelnen Aktionen innerhalb des Auftrags anzeigen. Auf den Registerkarten am oberen Rand können Sie die Auftragsdefinition und Auftragskonfiguration anzeigen, auf das Auftragsprotokoll zugreifen oder einen gerichteten azyklischen Graph (Directed Acyclic Graph, DAG) unter DAG des Auftrags anzeigen.
Auftragsprotokoll: Klicken Sie auf die Schaltfläche Get Logs (Protokolle abrufen), um alle Protokolle für den Auftrag abzurufen, oder verwenden Sie zum Filtern von Protokollen das Feld
Enter Search Filter.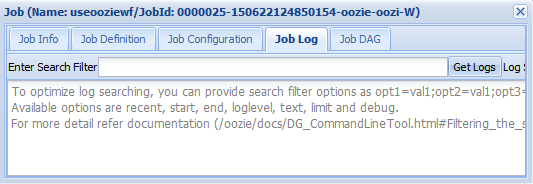
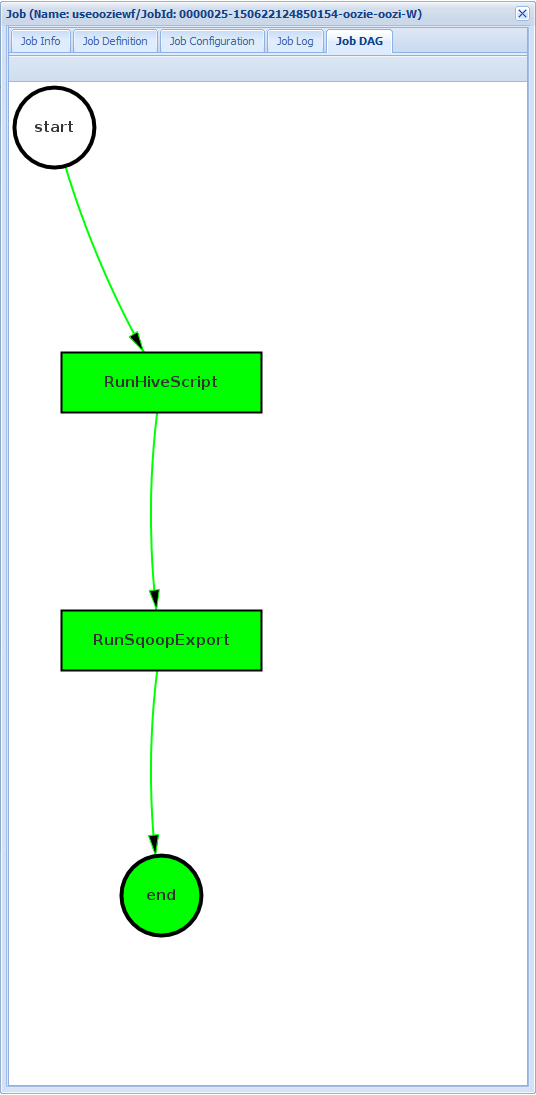
Auftrags-DAG: Der DAG ist eine grafische Übersicht über die Datenpfade, die im Workflow gewählt wurden.
Wenn Sie eine der Aktionen auf der Registerkarte Auftragsinformationen auswählen, werden Informationen zur Aktion eingeblendet. Wählen Sie z.B. die Aktion RunSqoopExport aus.
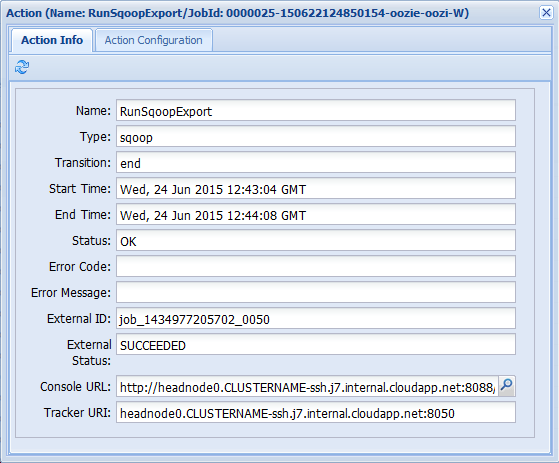
Sie können Details für die Aktion anzeigen, z. B. einen Link zur Konsolen-URL. Verwenden Sie diesen Link zum Anzeigen von JobTracker-Informationen für den Auftrag.
Planen von Aufträgen
Sie können den Koordinator verwenden, um den Start, das Ende und die Häufigkeit von Aufträgen anzugeben. Um einen Zeitplan für den Workflow zu definieren, führen Sie die folgenden Schritte aus:
Verwenden Sie den folgenden Befehl, um eine Datei namens coordinator.xml zu erstellen:
nano coordinator.xmlVerwenden Sie den folgenden XML-Code als Inhalt der Datei:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Hinweis
Die
${...}-Variablen werden zur Laufzeit durch Werte in der Auftragsdefinition ersetzt. Die Variablen heißen wie folgt:${coordFrequency}: Die Zeit zwischen der Ausführung von Instanzen des Auftrags.${coordStart}: Die Startzeit des Auftrags.${coordEnd}: Die Endzeit des Auftrags.${coordTimezone}: Für Koordinatoraufträge wird eine feste Zeitzone ohne Sommerzeit verwendet (in der Regel in UTC). Diese Zeitzone wird als Oozie-Verarbeitungszeitzone bezeichnet.${wfPath}: Der Pfad der Datei „workflow.xml“.
Um die Datei zu speichern, drücken Sie STRG+X, geben Sie J ein, und drücken Sie auf die EINGABETASTE.
Verwenden Sie den folgenden Befehl, um die Datei in das Arbeitsverzeichnis dieses Auftrags zu kopieren:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlVerwenden Sie zum Bearbeiten der zuvor erstellten
job.xml-Datei den folgenden Befehl:nano job.xmlNehmen Sie die folgenden Änderungen vor:
Um Oozie anzuweisen, die Koordinatordatei statt des Workflows auszuführen, ändern Sie
<name>oozie.wf.application.path</name>in<name>oozie.coord.application.path</name>.Fügen Sie zum Festlegen der Variablen
workflowPath, die vom Koordinator verwendet wird, den folgenden XML-Code hinzu:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Ersetzen Sie den Text
wasbs://mycontainer@mystorageaccount.blob.core.windowsdurch den Wert, der in weiteren Einträgen in der Datei „job.xml“ verwendet wird.Fügen Sie den folgenden XML-Code hinzu, um Start, Ende und Häufigkeit für den Koordinator festzulegen:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Diese Werte legen die Startzeit auf 12:00 Uhr am 10. Mai 2018 und die Endzeit auf den 12. Mai 2018 fest. Das Intervall für die Auftragsausführung ist auf „täglich“ festgelegt. Die Häufigkeit wird in Minuten angegeben. Daher gilt 24 Stunden x 60 Minuten = 1.440 Minuten. Schließlich wird die Zeitzone auf UTC festgelegt.
Um die Datei zu speichern, drücken Sie STRG+X, geben Sie J ein, und drücken Sie auf die EINGABETASTE.
Verwenden Sie den folgenden Befehl zum Übermitteln und Starten des Auftrags:
oozie job -config job.xml -runWenn Sie zur Oozie-Webbenutzeroberfläche wechseln und die Registerkarte Koordinatoraufträge auswählen, werden Informationen ähnlich wie in der folgenden Abbildung angezeigt:

Der Eintrag Next Materialization (Nächste Materialisierung) enthält die nächste Ausführungszeit des Auftrags.
Wie beim vorherigen Workflowauftrag werden beim Auswählen des Auftragseintrags auf der Webbenutzeroberfläche Informationen zum Auftrag angezeigt:
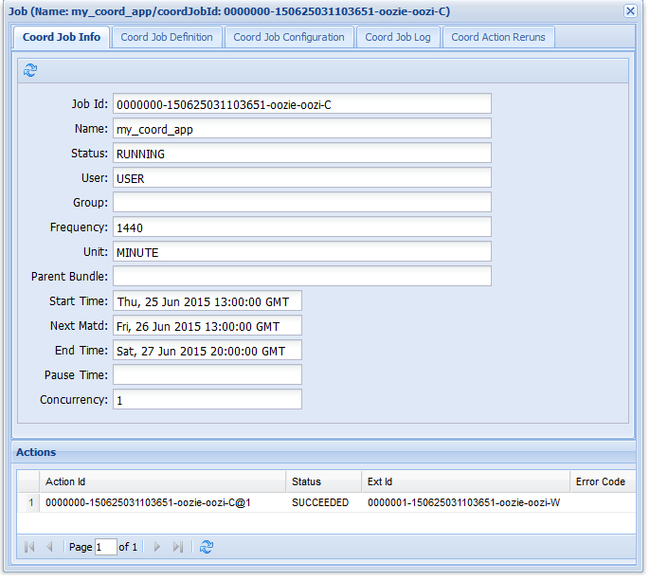
Hinweis
In dieser Abbildung werden nur erfolgreiche Ausführungen des Auftrags und nicht einzelne Aktionen innerhalb des geplanten Workflows angezeigt. Um die einzelnen Aktionen anzuzeigen, wählen Sie eine der Aktionseinträge aus.
Nächste Schritte
In diesem Artikel haben Sie gelernt, wie ein Oozie-Workflow definiert und Oozie-Auftrag ausgeführt wird. Weitere Informationen zum Arbeiten mit HDInsight finden Sie in den folgenden Artikeln: