Verwenden von MirrorMaker zum Replizieren von Apache Kafka-Themen mit Kafka in HDInsight
Erfahren Sie, wie Sie die Spiegelungsfunktion von Apache Kafka verwenden, um Themen in einen sekundären Cluster zu replizieren. Sie können die Spiegelung als kontinuierlichen Prozess oder intermittierend ausführen, um Daten von einem Cluster in einen anderen zu migrieren.
In diesem Artikel werden Sie die Spiegelung verwenden, um Themen zwischen zwei HDInsight-Clustern zu replizieren. Diese Cluster befinden sich in verschiedenen virtuellen Netzen in unterschiedlichen Rechenzentren.
Warnung
Verwenden Sie die Spiegelung nicht als Mittel, um Fehlertoleranz zu erreichen. Der Versatz zu Elementen innerhalb eines Themas ist zwischen dem primären und dem sekundären Cluster unterschiedlich, so dass die Kunden die beiden nicht austauschbar verwenden können. Falls Sie Bedenken wegen der Fehlertoleranz haben, sollten Sie die Replikation für die Themen in Ihrem Cluster festlegen. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight.
Funktionsweise der Apache Kafka-Spiegelung
Das Mirroring funktioniert mit dem Tool MirrorMaker, das Teil von Apache Kafka ist. MirrorMaker konsumiert Datensätze von Themen auf dem primären Cluster und erstellt dann eine lokale Kopie auf dem sekundären Cluster. MirrorMaker nutzt einen (oder mehrere) Consumer zum Lesen von Daten aus dem primären Cluster und einen Producer, der in den lokalen Cluster (sekundären Cluster) schreibt.
Das nützlichste Mirroring-Setup für die Notfallwiederherstellung verwendet Kafka-Cluster in verschiedenen Azure-Regionen. Zu diesem Zweck werden die virtuellen Netzwerke, in denen sich die Cluster befinden, zu einem Peeringnetzwerk zusammengeschlossen.
Das folgende Diagramm veranschaulicht den Spiegelungsprozess und den Kommunikationsfluss zwischen den Clustern:
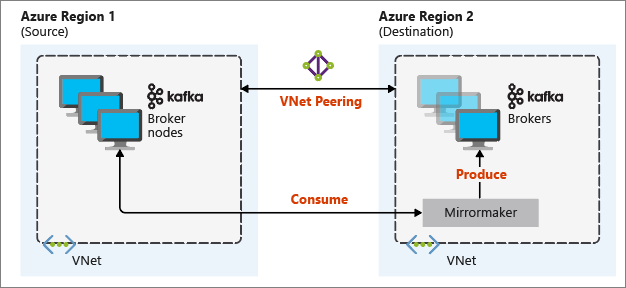
Der primäre und der sekundäre Cluster können sich in Bezug auf die Anzahl von Knoten und Partitionen unterscheiden, und auch der Versatz in den Themen ist unterschiedlich. Beim Spiegeln wird der Schlüsselwert beibehalten, der für die Partitionierung verwendet wird, sodass die Datensatzreihenfolge pro Schlüssel beibehalten wird.
Spiegelung über Netzwerkgrenzen hinweg
Wenn Sie eine Spiegelung zwischen Kafka-Clustern in unterschiedlichen Netzwerken durchführen müssen, sollten Sie außerdem Folgendes beachten:
Gateways: Die Netzwerke müssen auf TCP/IP-Ebene kommunizieren können.
Server-Adressierung: Sie können Ihre Clusterknoten über ihre IP-Adressen oder vollständig qualifizierte Domänennamen adressieren.
IP-Adressen: Wenn Sie Ihre Kafka-Cluster für die Verwendung von IP-Adresswerbung konfigurieren, können Sie mit der Einrichtung der Spiegelung fortfahren, indem Sie die IP-Adressen der Broker-Knoten und ZooKeeper-Knoten verwenden.
Domänennamen: Wenn Sie Ihre Kafka-Cluster nicht für die Bekanntgabe von IP-Adressen konfigurieren, müssen die Cluster in der Lage sein, über vollständig qualifizierte Domänennamen (FQDNs) eine Verbindung zueinander herzustellen. Dazu ist in jedem Netz ein DNS-Server (Domain Name System) erforderlich, der so konfiguriert ist, dass er Anfragen an die anderen Netze weiterleitet. Wenn Sie ein virtuelles Azure-Netzwerk erstellen, müssen Sie anstelle des automatischen DNS, das mit dem Netzwerk bereitgestellt wird, einen benutzerdefinierten DNS-Server und die IP-Adresse für den Server angeben. Nachdem Sie das virtuelle Netzwerk erstellt haben, müssen Sie anschließend eine virtuelle Azure-Maschine erstellen, die diese IP-Adresse verwendet. Dann installieren und konfigurieren Sie die DNS-Software auf dem Gerät.
Wichtig
Erstellen und konfigurieren Sie den benutzerdefinierten DNS-Server, bevor Sie HDInsight im virtuellen Netzwerk installieren. Es ist keine zusätzliche Konfiguration erforderlich, damit HDInsight den für das virtuelle Netzwerk konfigurierten DNS-Server verwendet.
Weitere Informationen zur Verbindung zweier virtueller Azure-Netzwerke finden Sie unter Konfigurieren einer Verbindung.
Architektur der Spiegelung
Diese Architektur umfasst zwei Cluster in verschiedenen Ressourcengruppen und virtuellen Netzen: einen primären und einen sekundären.
Schritte zur Erstellung
Erstellen Sie zwei neue Ressourcengruppen:
Resource group Standort kafka-primary-rg USA, Mitte kafka-secondary-rg USA Nord Mitte Erstellen Sie in kafka-primary-rg ein neues virtuelles Netzwerk namens kafka-primary-vnet. Übernehmen Sie die Standardeinstellungen.
Erstellen Sie – ebenfalls mit den Standardeinstellungen – in kafka-secondary-rg ein neues virtuelles Netzwerk namens kafka-secondary-vnet.
Erstellen Sie zwei neue Kafka-Cluster:
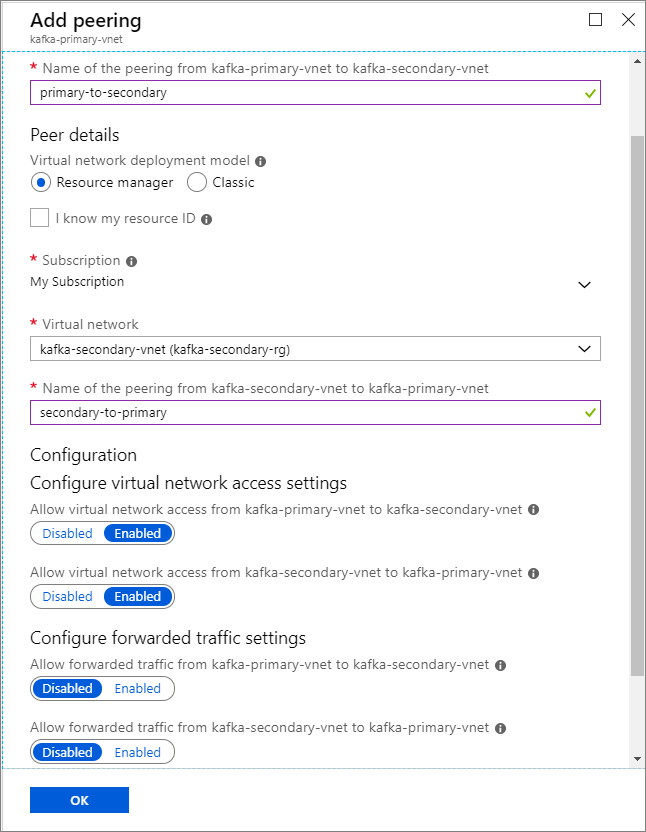
Clustername Resource group Virtuelles Netzwerk Speicherkonto kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Erstellen Sie virtuelle Netzwerkpeerings. Dieser Schritt erzeugt zwei Peerings: eines von kafka-primär-vnet zu kafka-secondary-vnet und eines zurück von kafka-secondary-vnet zu kafka-primär-vnet.
Wählen Sie das virtuelle Netzwerk kafka-primary-vnet aus.
Klicken Sie unter Einstellungen auf Peerings.
Wählen Sie Hinzufügen.
Geben Sie auf dem Bildschirm Peering hinzufügen die Details ein, wie in der folgenden Abbildung gezeigt.
Konfigurieren der Ankündigung der IP-Adresse
Konfigurieren Sie die IP-Werbung, damit ein Client eine Verbindung über Broker-IP-Adressen anstelle von Domänennamen herstellen kann.
Wechseln Sie zum Ambari-Dashboard für den primären Cluster:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Wählen Sie Dienste>Kafka aus. Wählen Sie die Registerkarte Configs aus.
Fügen Sie dem unteren Abschnitt kafka-env template folgende Konfigurationszeilen hinzu. Wählen Sie Speichern aus.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesGeben Sie auf dem Bildschirm Konfiguration speichern einen Hinweis ein, und wählen Sie Speichern.
Wenn Sie eine Konfigurationswarnung erhalten, wählen Sie Beständig fortfahren.
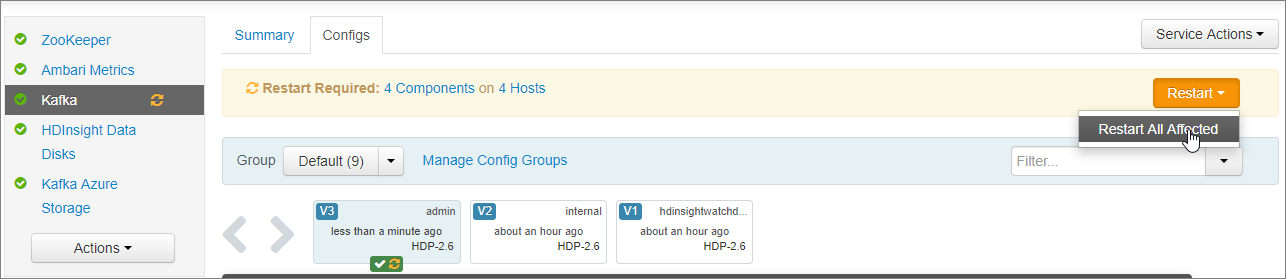
Wählen Sie auf Konfigurationsänderungen speichern die Option Ok.
Wählen Sie in der Meldung Neustart erforderlich die Optionen Neustart>Neustart für alle Betroffenen. Wählen Sie dann Bestätigen Sie den Neustart aller.
Konfigurieren Sie Kafka so, dass es auf allen Netzwerkschnittstellen lauscht
- Bleiben Sie auf der Registerkarte Configs (Konfigurationen) unter Services>Kafka (Dienste > Kafka). Setzen Sie im Abschnitt Kafka Broker die Eigenschaft listeners auf
PLAINTEXT://0.0.0.0:9092. - Wählen Sie Speichern aus.
- Wählen Sie Neustart>Bestätigen Sie Neustart alle.
Aufzeichnung der Broker-IP-Adressen und ZooKeeper-Adressen für den primären Cluster
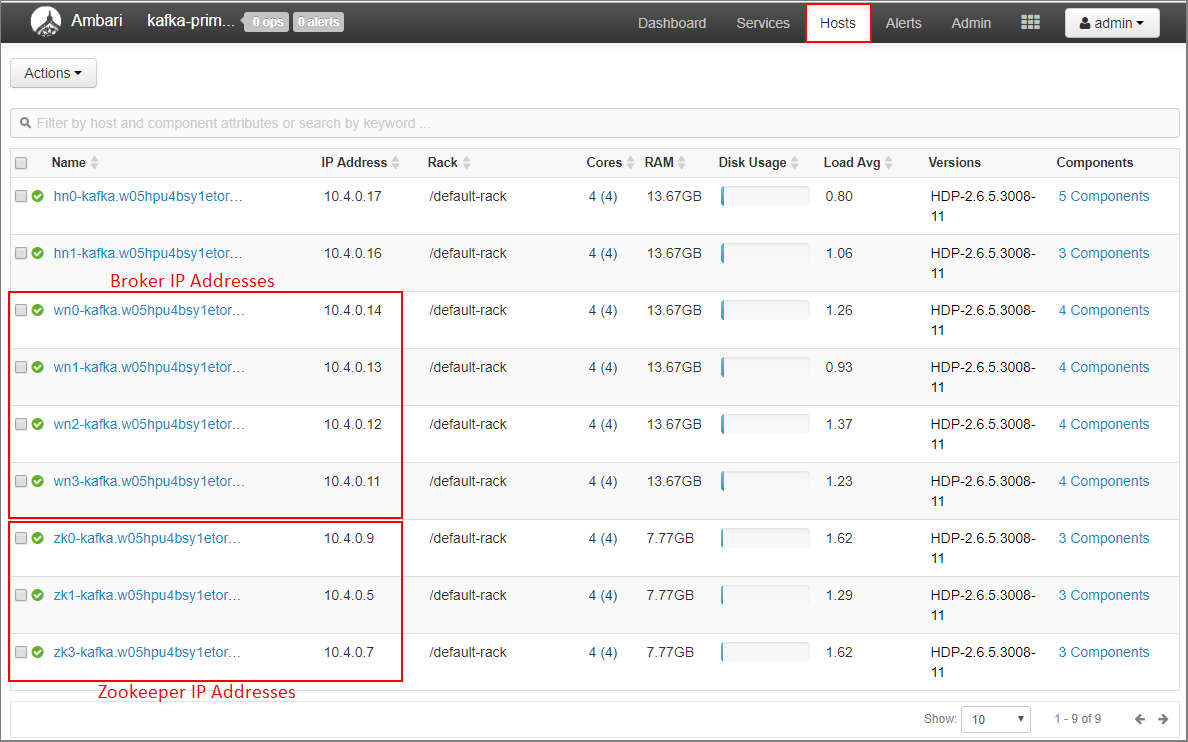
Wählen Sie auf dem Ambari-Dashboard Hosts aus.
Notieren Sie sich die IP-Adressen für die Broker und ZooKeeper. Die Broker-Knoten haben wn als die ersten beiden Buchstaben des Host-Namens, und die ZooKeeper-Knoten haben zk als die ersten beiden Buchstaben des Host-Namens.
Wiederholen Sie die vorherigen drei Schritte für den zweiten Cluster, kafka-secondary-cluster: Konfigurieren Sie die IP-Werbung, legen Sie Listener fest und notieren Sie sich die IP-Adressen von Broker und ZooKeeper.
Erstellen von Themen
Verbinden Sie sich mit dem primären Cluster über SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netErsetzen Sie
sshuserdurch den SSH-Benutzernamen, den Sie bei der Erstellung des Clusters verwendet haben. Ersetzen SiePRIMARYCLUSTERdurch den Basisnamen, den Sie bei der Erstellung des Clusters verwendet haben.Weitere Informationen finden Sie unter Verwenden von SSH mit Linux-basiertem Hadoop in HDInsight unter Linux, Unix oder OS X.
Verwenden Sie den folgenden Befehl, um zwei Umgebungsvariablen mit den Apache ZooKeeper-Hosts und Broker-Hosts für den primären Cluster zu erstellen. Ersetzen Sie Zeichenfolgen wie
ZOOKEEPER_IP_ADDRESS1durch die tatsächlichen IP-Adressen, die zuvor aufgezeichnet wurden, z. B.10.23.0.11und10.23.0.7. Dasselbe gilt fürBROKER_IP_ADDRESS1. Wenn Sie die FQDN-Auflösung mit einem benutzerdefinierten DNS-Server verwenden, führen Sie die folgenden Schritte aus, um Broker- und ZooKeeper-Namen zu erhalten.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Um ein Thema mit Namen
testtopiczu erstellen, nutzen Sie den folgenden Befehl:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSVerwenden Sie den folgenden Befehl, um zu bestätigen, dass das Thema erstellt wurde:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSDie Antwort enthält
testtopic.Gehen Sie wie folgt vor, um die Broker-Host-Informationen für diesen (den primären) Cluster anzuzeigen:
echo $PRIMARY_BROKERHOSTSDie Ausgabe sieht in etwa wie folgt aus:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Speichern Sie diese Informationen. Sie werden im nächsten Abschnitt verwendet.
Konfigurieren der Spiegelung
Verbinden Sie sich mit dem sekundären Cluster, indem Sie eine andere SSH-Sitzung verwenden:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netErsetzen Sie
sshuserdurch den SSH-Benutzernamen, den Sie bei der Erstellung des Clusters verwendet haben. Ersetzen SieSECONDARYCLUSTERdurch den Namen, den Sie bei der Erstellung des Clusters verwendet haben.Weitere Informationen finden Sie unter Verwenden von SSH mit Linux-basiertem Hadoop in HDInsight unter Linux, Unix oder OS X.
Verwenden Sie eine
consumer.properties-Datei, um die Kommunikation mit dem Primärcluster zu konfigurieren. Verwenden Sie zum Erstellen der Datei den folgenden Befehl:nano consumer.propertiesVerwenden Sie als Inhalt der Datei
consumer.propertiesden folgenden Text:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupErsetzen Sie
PRIMARY_BROKERHOSTSdurch die IP-Adressen der Broker-Hosts des primären Clusters.In dieser Datei werden die Consumerinformationen beschrieben, die beim Lesen aus dem primären Kafka-Cluster verwendet werden sollten. Weitere Informationen finden Sie unter Verbraucherkonfigurationen auf
kafka.apache.org.Um die Datei zu speichern, drücken Sie Strg+X, drücken Sie Y und dann die Eingabetaste.
Bevor Sie den Producer konfigurieren, der mit dem sekundären Cluster kommuniziert, richten Sie eine Variable für die IP-Adressen der Broker des sekundären Clusters ein. Verwenden Sie die folgenden Befehle, um diese Variable zu erstellen:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Der Befehl
echo $SECONDARY_BROKERHOSTSgibt Informationen ähnlich dem folgenden Text zurück:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Verwenden Sie eine
producer.properties-Datei, um den sekundären Cluster zu kommunizieren. Verwenden Sie zum Erstellen der Datei den folgenden Befehl:nano producer.propertiesVerwenden Sie als Inhalt der Datei
producer.propertiesden folgenden Text:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneErsetzen Sie
SECONDARY_BROKERHOSTSdurch die im vorherigen Schritt verwendeten Broker-IP-Adressen.Weitere Informationen finden Sie unter Producer Configs auf
kafka.apache.org.Verwenden Sie die folgenden Befehle, um eine Umgebungsvariable mit den IP-Adressen der ZooKeeper-Hosts für den sekundären Cluster zu erstellen:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Die Standardkonfiguration für Kafka auf HDInsight erlaubt keine automatische Erstellung von Themen. Sie müssen eine der folgenden Optionen verwenden, bevor Sie den Spiegelungsprozess starten:
Erstellen der Themen im sekundären Cluster: Bei dieser Option haben Sie auch die Möglichkeit, die Anzahl von Partitionen und den Replikationsfaktor festzulegen.
Mit folgendem Befehl können Sie Themen vorab erstellen:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSErsetzen Sie
testtopicdurch den Namen des zu erstellenden Themas.Konfigurieren Sie den Cluster für die automatische Themenerstellung: Diese Option ermöglicht es MirrorMaker, automatisch Themen zu erstellen. Beachten Sie, dass es diese mit einer anderen Anzahl von Partitionen oder einem anderen Replikationsfaktor als das primäre Thema erstellen kann.
Um den sekundären Cluster für das automatische Erstellen von Themen zu konfigurieren, führen Sie die folgenden Schritte aus:
- Wechseln Sie zum Ambari-Dashboard für den sekundären Cluster:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Wählen Sie Dienste>Kafka aus. Wählen Sie dann die Registerkarte Konfigurationen.
- Geben Sie in das Feld Filter den Wert
auto.createein. Dies filtert die Liste der Eigenschaften und zeigt die Einstellungauto.create.topics.enable. - Ändern Sie den Wert von
auto.create.topics.enablezutrue, und klicken Sie dann auf Speichern. Fügen Sie einen Hinweis hinzu, und wählen Sie dann erneut Speichern. - Wählen Sie den Dienst Kafka, dann die Option Neu starten und abschließend die Option Neustart aller betroffenen. Klicken Sie bei entsprechender Aufforderung auf Neustart aller Dienste bestätigen.
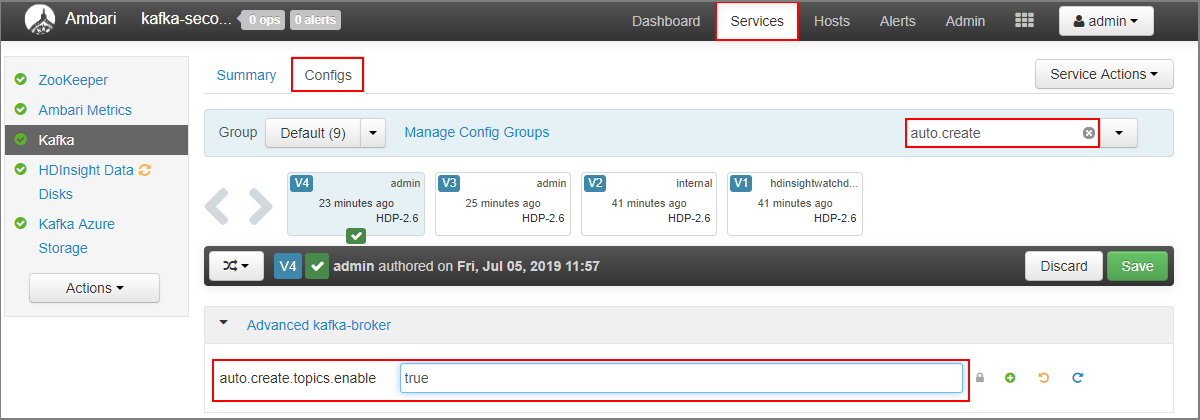
- Wechseln Sie zum Ambari-Dashboard für den sekundären Cluster:
Starten von MirrorMaker
Hinweis
In diesem Artikel wird ein Begriff verwendet, der von Microsoft nicht mehr genutzt wird. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Verwenden Sie den folgenden Befehl über die SSH-Verbindung mit dem sekundären Cluster, um den MirrorMaker-Prozess zu starten:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Die in diesem Beispiel verwendeten Parameter sind:
Parameter BESCHREIBUNG --consumer.configGibt die Datei an, in der die Consumereigenschaften enthalten sind. Sie verwenden diese Eigenschaften, um einen Verbraucher zu erstellen, der aus dem primären Kafka-Cluster liest. --producer.configGibt die Datei an, in der die Producereigenschaften enthalten sind. Sie verwenden diese Eigenschaften, um einen Produzenten zu erstellen, der in den sekundären Kafka-Cluster schreibt. --whitelistEine Liste mit Themen, die von MirrorMaker aus dem primären in den sekundären Cluster repliziert werden. --num.streamsDie Anzahl von Consumerthreads, die erstellt werden sollen. Der Consumer auf dem sekundären Knoten wartet jetzt auf Nachrichten.
Verwenden Sie den folgenden Befehl über die SSH-Verbindung mit dem primären Cluster, um einen Producer zu starten und Nachrichten an das Thema zu senden:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicSobald der Cursor an einer leeren Zeile steht, geben Sie einige Textnachrichten ein. Diese Nachrichten werden an das Thema im primären Cluster gesendet. Wenn Sie fertig sind, drücken Sie Strg+C, um den Erzeugungsprozess zu beenden.
Drücken Sie bei der SSH-Verbindung zum sekundären Cluster die Tastenkombination Strg+C, um den MirrorMaker-Prozess zu beenden. Es kann einige Sekunden dauern, bis der Vorgang abgeschlossen ist. Um sicherzustellen, dass die Nachrichten im sekundären Cluster repliziert wurden, verwenden Sie den folgenden Befehl:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningDie Themenliste enthält nun auch das Thema
testtopic, das erstellt wurde, als MirrorMaker das Thema vom primären an den sekundären Cluster gespiegelt hat. Die aus dem Thema abgerufenen Nachrichten sind identisch mit den Nachrichten, die Sie im primären Cluster eingegeben haben.
Löschen des Clusters
Warnung
Die Abrechnung für die HDInsight-Cluster erfolgt anteilsmäßig auf Minutenbasis und ist unabhängig von der Verwendung. Daher sollten Sie Ihren Cluster nach der Verwendung unbedingt wieder löschen. Sehen Sie sich die Informationen zum Löschen eines HDInsight-Clusters an.
Mit den Schritten in diesem Artikel wurden Cluster in verschiedenen Azure-Ressourcengruppen erstellt. Um alle erstellten Ressourcen zu löschen, können Sie die beiden erstellten Ressourcengruppen löschen: kafka-primary-rg und kafka-secondary-rg. Durch das Löschen der Ressourcengruppen werden alle Ressourcen entfernt, die nach diesem Artikel erstellt wurden, einschließlich Cluster, virtuelle Netzwerke und Speicherkonten.
Nächste Schritte
In diesem Artikel haben Sie gelernt, wie man MirrorMaker verwendet, um ein Replikat eines Apache Kafka-Clusters zu erstellen. Verwenden Sie die folgenden Links, um weitere Möglichkeiten zur Arbeit mit Kafka kennenzulernen: