Vorhersage im großen Stil: viele Modelle und verteiltes Training
In diesem Artikel geht es um das Trainieren von Vorhersagemodellen für große Mengen von Verlaufsdaten. Anweisungen und Beispiele zum Trainieren von Vorhersagemodellen in automatisiertem ML finden Sie in unserem Artikel Einrichten von AutoML zum Trainieren eines Zeitreihenvorhersagemodells mit Python.
Zeitreihendaten können aufgrund der Anzahl der Datenreihen, der Anzahl der verlaufsbezogenen Beobachtungen oder beides groß sein. Viele Modelle und hierarchische Zeitreihen oder HTS sind Skalierungslösungen für das frühere Szenario, in dem die Daten aus einer großen Anzahl von Zeitreihen bestehen. In diesen Fällen kann es für die Modellgenauigkeit und Skalierbarkeit von Vorteil sein, die Daten in Gruppen zu partitionieren und eine große Anzahl unabhängiger Modelle parallel für die Gruppen zu trainieren. Umgekehrt gibt es Szenarien, in denen es besser ist, ein Modell oder einige wenige Modelle mit hoher Kapazität zu verwenden. Das verteilte DNN-Training zielt auf diesen Fall ab. Im weiteren Verlauf des Artikels werden die Konzepte zu diesen Szenarien erläutert.
Viele Modelle
Die vielen Modellkomponenten in AutoML ermöglichen es Ihnen, Millionen von Modellen parallel zu trainieren und zu verwalten. Angenommen, Sie verfügen über Verlaufsdaten für eine große Anzahl von Geschäften. Sie können viele Modelle verwenden, um parallele AutoML-Trainingsaufträge für jeden Speicher zu starten, wie im folgenden Diagramm dargestellt:

Die Trainingskomponente für viele Modelle wendet Modell-Sweeping und -Auswahl von AutoML unabhängig auf jeden Speicher in diesem Beispiel an. Diese Modellunabhängigkeit unterstützt die Skalierbarkeit und kann die Modellgenauigkeit insbesondere dann nutzen, wenn die Verkaufsdynamik in den Filialen unterschiedlich ist. Ein einzelner Modellansatz kann jedoch zu genaueren Vorhersagen führen, wenn allgemeine Vertriebsdynamiken vorhanden sind. Weitere Informationen zu diesem Fall finden Sie im Abschnitt Verteiltes DNN-Training.
Sie können die Datenpartitionierung, die AutoML-Einstellungen für die Modelle und den Grad der Parallelität für viele Modelltrainingsaufträge konfigurieren. Beispiele finden Sie im Abschnitt zu vielen Modellkomponenten in unserem Leitfaden.
Hierarchische Zeitreihenvorhersage
Es ist üblich, dass Zeitreihen in Geschäftsanwendungen geschachtelte Attribute aufweisen, die eine Hierarchie bilden. Geografie- und Produktkatalogattribute werden beispielsweise häufig geschachtelt. Betrachten Sie ein Beispiel, in dem die Hierarchie über zwei geografische Attribute verfügt: Zustands- und Speicher-ID sowie zwei Produktattribute, Kategorie und SKU:

Diese Hierarchie ist in der nachfolgenden Abbildung dargestellt:

Wichtig ist, dass sich die Verkaufsmengen auf der Blattebene (SKU) zu den aggregierten Verkaufsmengen auf der Status- und Gesamtumsatzebene addieren. Hierarchische Vorhersagemethoden behalten diese Aggregationseigenschaften bei, wenn die verkaufte Menge auf einer beliebigen Hierarchieebene vorhergesagt wird. Vorhersagen mit dieser Eigenschaft sind hinsichtlich der Hierarchie kohärent.
AutoML unterstützt die folgenden Features für hierarchische Zeitreihen (HTS):
- Training auf jeder Ebene der Hierarchie. In einigen Fällen sind die Daten auf Blattebene möglicherweise verrauscht, aber Aggregate können für Vorhersagen leichter geeignet sein.
- Abrufen von Punktprognosen auf jeder Ebene der Hierarchie. Wenn das Prognoseniveau „unterhalb“ des Trainingsniveaus liegt, werden Vorhersagen aus der Trainingsstufe anhand der durchschnittlichen historischen Proportionen oder Proportionen der historischen Durchschnitte aufgeschlüsselt. Prognosen auf Trainingsebene werden entsprechend der Aggregationsstruktur zusammengefasst, wenn die Prognosestufe „über“ der Trainingsstufe liegt.
- Abrufen von quantilen/probabilistischen Vorhersagen für Ebenen auf oder „unterhalb“ der Trainingsebene. Aktuelle Modellierungsfunktionen unterstützen die Disaggregation von probabilistischen Vorhersagen.
HTS-Komponenten in AutoML basieren auf vielen Modellen, sodass HTS die skalierbaren Eigenschaften vieler Modelle gemeinsam verwendet. Beispiele finden Sie im Abschnitt zu HTS-Komponenten in unserem Leitfaden.
Verteiltes DNN-Training (Preview)
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Datenszenarien mit großen Mengen historischer Beobachtungen und/oder einer großen Anzahl verwandter Zeitreihen können von einem skalierbaren Ansatz mit einem einzelnen Modell profitieren. Entsprechend unterstützt AutoML verteiltes Training und die Modellsuche für TCN-Modelle (Temporal Convolutional Network), bei denen es sich um eine Art Deep Neural Network (DNN) für Zeitreihendaten handelt. Weitere Informationen zur TCN-Modellklasse von AutoML finden Sie in unserem DNN-Artikel.
Verteiltes DNN-Training erreicht Skalierbarkeit mithilfe eines Datenpartitionierungsalgorithmus, der Zeitreihengrenzen berücksichtigt. Das folgende Diagramm veranschaulicht ein einfaches Beispiel mit zwei Partitionen:
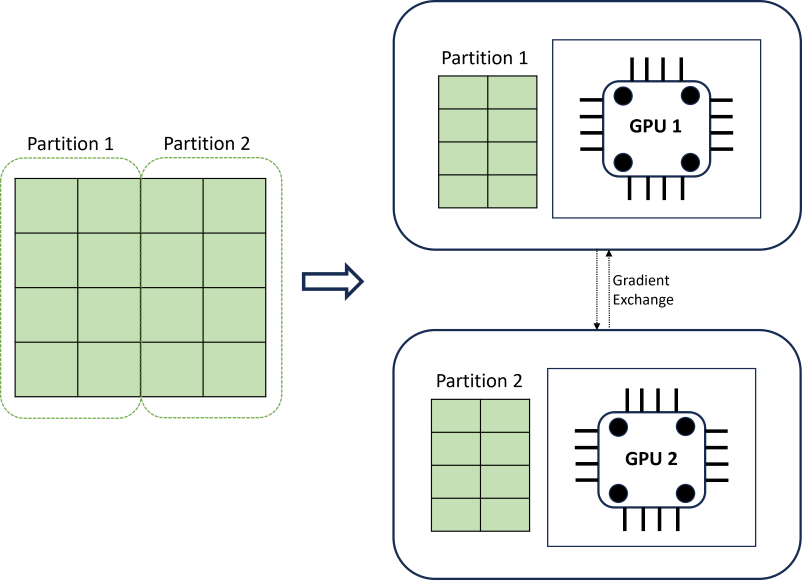
Während des Trainings laden die DNN-Datenladevorgänge auf jeder Compute-Instanz genau das, was sie benötigen, um eine Iteration der Rückweitergabe abzuschließen. Nie wird das gesamte Dataset in den Arbeitsspeicher eingelesen. Die Partitionen werden weiter auf mehrere Computekerne (in der Regel GPUs) auf möglicherweise mehreren Knoten verteilt, um das Training zu beschleunigen. Die Koordination zwischen Computes wird durch das Horovod-Framework bereitgestellt.
Nächste Schritte
- Erfahren Sie mehr über das Einrichten von AutoML zum Trainieren eines Zeitreihenvorhersagemodells.
- Erfahren Sie mehr über die Verwendung von maschinellem Lernen in AutoML zum Erstellen von Vorhersagemodellen.
- Erfahren Sie mehr über Deep Learning-Modelle für Vorhersagen in automatisiertem ML.