Einrichten einer Entwicklungsumgebung mit Azure Databricks und automatisiertem maschinellem Lernen in Azure Machine Learning
Hier erfahren Sie, wie Sie in Azure Machine Learning eine Entwicklungsumgebung konfigurieren, die Azure Databricks und automatisiertes maschinelles Lernen (AutoML) verwendet.
Azure Databricks eignet sich ideal für die Ausführung umfangreicher ML-Workflows auf der skalierbaren Apache Spark-Plattform in der Azure-Cloud. Sie stellt eine Notebook-basierte Umgebung mit CPU- oder GPU-basierten Computeclustern für die Zusammenarbeit bereit.
Informationen zu anderen Entwicklungsumgebungen für maschinelles Lernen finden Sie unter Einrichten einer Python-Entwicklungsumgebung.
Voraussetzung
Einen Azure Machine Learning-Arbeitsbereich. Verwenden Sie zum Erstellen eines solchen Arbeitsbereichs die Schritte im Artikel Erstellen von Arbeitsbereichsressourcen.
Azure Databricks mit Azure Machine Learning und automatisiertem maschinellem Lernen
Azure Databricks lässt sich in Azure Machine Learning und die zugehörigen AutoML-Funktionen integrieren.
Sie können Azure Databricks für Folgendes verwenden:
- Trainieren eines Modells mithilfe von Spark MLlib und Bereitstellen des Modells ACI/AKS
- Über ein Azure Machine Learning SDK mit AutoML-Funktionen.
- Nutzen als Computeziel einer Azure Machine Learning-Pipeline
Einrichten eines Databricks-Clusters
Erstellen Sie einen Databricks-Cluster. Einige Einstellungen sind nur erforderlich, wenn Sie das SDK für automatisiertes Machine Learning in Databricks verwenden.
Die Erstellung des Clusters dauert einige Minuten.
Verwenden Sie die folgenden Einstellungen:
| Einstellung | Anwendungsbereich | Wert |
|---|---|---|
| Clustername | immer | IhrClustername |
| Databricks-Runtimeversion | immer | 9.1 LTS |
| Python-Version | immer | 3 |
| Workertyp (bestimmt die maximale Anzahl gleichzeitiger Iterationen) |
Automatisiertes maschinelles Lernen Machine Learning |
Arbeitsspeicheroptimierte VM bevorzugt |
| Worker | immer | 2 oder mehr |
| Automatische Skalierung aktivieren | Automatisiertes maschinelles Lernen Machine Learning |
Deaktivieren |
Warten Sie, bis der Cluster ausgeführt wird, bevor Sie fortfahren.
Hinzufügen des Azure Machine Learning SDK zu Databricks
Erstellen Sie nach der Ausführung des Clusters eine Bibliothek, um das entsprechende Azure Machine Learning SDK-Paket Ihrem Cluster anzufügen.
Um AutoML zu verwenden, fahren Sie mit Hinzufügen des Azure Machine Learning SDK mit AutoML zu Databricks fort.
Klicken Sie mit der rechten Maustaste auf den aktuellen Arbeitsbereichsordner, in dem Sie die Bibliothek speichern möchten. Wählen Sie Bibliothek>erstellen aus.
Tipp
Wenn Sie eine alte SDK-Version nutzen, deaktivieren Sie diese in den installierten Bibliotheken des Clusters, und verschieben Sie sie in den Papierkorb. Installieren Sie die neue SDK-Version, und starten Sie den Cluster neu. Wenn nach dem Neustart ein Problem vorliegt, trennen Sie Ihren Cluster, und fügen Sie ihn wieder an.
Wählen Sie die folgende Option aus (andere SDK-Installationen werden nicht unterstützt).
SDK-Paketergänzungen Quelle PyPi-Name Für Databricks Python Egg oder PyPI hochladen azureml-sdk[databricks] Warnung
Sie können keine weiteren SDK-Zusatzkomponenten installieren. Wählen Sie nur die [
databricks]-Option aus.- Wählen Sie nicht Attach automatically to all clusters (Automatisch an alle Cluster anfügen) aus.
- Wählen Sie Anfügen neben dem Namen Ihres Clusters aus.
Der Status wird in Angefügt geändert. Dieser Vorgang kann einige Minuten in Anspruch nehmen. Überprüfen Sie währenddessen, ob Fehler auftreten. Wenn bei diesem Schritt ein Fehler auftritt:
Versuchen Sie, Ihren Cluster wie folgt neu zu starten:
- Wählen Sie im linken Bereich die Option Cluster aus.
- Wählen Sie in der Tabelle den Namen Ihres Clusters aus.
- Klicken Sie auf der Registerkarte Bibliotheken auf Neu starten.
Eine erfolgreiche Installation sieht wie folgt aus:
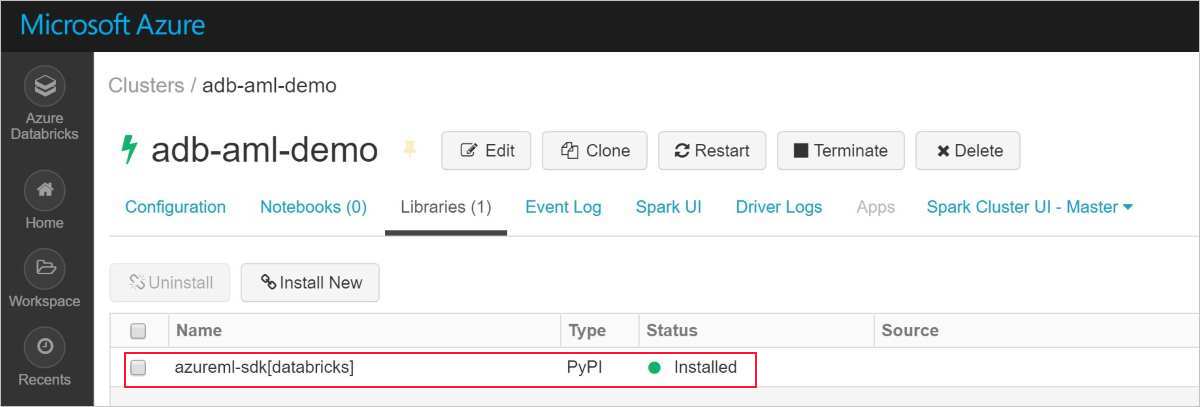
Hinzufügen des Azure Machine Learning SDK mit AutoML zu Databricks
Wenn der Cluster mit Databricks Runtime 7.3 LTS oder höher (nicht ML) erstellt wurde, führen Sie den folgenden Befehl in der ersten Zelle Ihres Notebooks aus, um das Azure Machine Learning SDK zu installieren.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
AutoML-Konfigurationseinstellungen
Fügen Sie in der AutoML-Konfiguration bei Verwendung von Azure Databricks die folgenden Parameter hinzu:
max_concurrent_iterationsbasiert auf der Anzahl der Workerknoten in Ihrem Cluster.spark_context=scbasiert auf dem standardmäßigen Spark-Kontext.
ML-Notebooks, die mit Azure Databricks funktionieren
So können Sie Azure Databricks testen:
Von den vielen verfügbaren Beispielnotebooks können nur ganz bestimmte mit Azure Databricks verwendet werden.
Importieren Sie diese Beispiele direkt aus Ihrem Arbeitsbereich. Siehe unten:
Erfahren Sie, wie Sie mit Databricks als Computeziel für das Trainieren von Modellen eine Pipeline erstellen.
Problembehandlung
Databricks – Abbrechen einer automatisierten Ausführung des maschinellen Lernens: Wenn Sie Funktionen für automatisiertes maschinelles Lernen in Azure Databricks verwenden um eine Ausführung abzubrechen und eine neue Experimentausführung zu starten, starten Sie Ihren Azure Databricks-Cluster neu.
Databricks > als zehn Iterationen von automatisiertem maschinellem Lernen: Sofern in den Einstellungen für automatisiertes maschinelles Lernen mehr als zehn Iterationen vorgesehen sind, legen Sie
show_outputaufFalsefest, wenn Sie die Ausführung übermitteln.Databricks-Widget für das Azure Machine Learning SDK und automatisiertes maschinelles Lernen: Das Azure Machine Learning SDK-Widget wird in Databricks-Notebooks nicht unterstützt, da die Notebooks keine HTML-Widgets analysieren können. Sie können das Widget im Portal anzeigen, indem Sie diesen Python-Code in die Zelle Ihres Azure Databricks-Notebooks einfügen:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Fehler beim Installieren von Paketen
Bei der Installation des Azure Machine Learning SDK tritt in Azure Databricks ein Fehler auf, wenn mehrere Pakete installiert werden. Einige Pakete, z.B.
psutil, können Konflikte verursachen. Um Fehler bei der Installation zu vermeiden, frieren Sie die Bibliotheksversion beim Installieren der Pakete ein. Dieses Problem hängt mit Databricks und nicht mit dem Azure Machine Learning SDK zusammen. Es kann auch mit anderen Bibliotheken auftreten. Beispiel:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Falls bei Python-Bibliotheken immer wieder Installationsprobleme auftreten, können Sie alternativ Initialisierungsskripts verwenden. Dieser Ansatz wird nicht offiziell unterstützt. Weitere Informationen finden Sie unter Initialisierungsskripts im Clusterbereich.
Importfehler: Der Name
Timedeltakann nicht auspandas._libs.tslibsimportiert werden: Wenn dieser Fehler angezeigt wird, wenn Sie automatisiertes Machine Learning verwenden, führen Sie die beiden folgenden Zeilen in Ihrem Notebook aus:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Importfehler: Kein Modul mit dem Namen „pandas.core.indexes“ : Wenn diese Fehlermeldung bei Verwendung von automatisiertem maschinellem Lernen angezeigt wird, gehen Sie folgendermaßen vor:
Führen Sie diesen Befehl aus, um zwei Pakete in Ihrem Azure Databricks-Cluster zu installieren:
scikit-learn==0.19.1 pandas==0.22.0Trennen Sie den Cluster auf, und fügen Sie ihn dann wieder an Ihr Notebook an.
Wenn diese Schritte das Problem nicht beheben, versuchen Sie, den Cluster neu zu starten.
FailToSendFeather: Sollte beim Lesen von Daten aus einem Azure Databricks-Cluster ein Fehler vom Typ
FailToSendFeatherauftreten, haben Sie folgende Möglichkeiten:- Upgraden Sie das Paket
azureml-sdk[automl]auf die aktuelle Version. - Fügen Sie mindestens die Version 1.1.8 von
azureml-dataprephinzu. - Fügen Sie mindestens die Version 0.11 von
pyarrowhinzu.
- Upgraden Sie das Paket
Nächste Schritte
- Trainieren und Bereitstellen eines Modells in Azure Machine Learning mit dem MNIST-Dataset
- Weitere Informationen erhalten Sie in der Referenz zum Azure Machine Learning SDK für Python.