Problembehandlung bei Machine Learning-Pipelines
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie Probleme durch Fehler in Machine Learning-Pipelines mit dem Azure Machine Learning SDK und dem Azure Machine Learning-Designer beheben.
Tipps zur Problembehandlung
Die folgende Tabelle enthält häufige Probleme bei der Pipelinentwicklung mit möglichen Lösungen.
| Problem | Mögliche Lösung |
|---|---|
Daten können nicht in das Verzeichnis PipelineData übergeben werden |
Stellen Sie sicher, dass Sie im Skript ein Verzeichnis erstellt haben, das dem entspricht, wo Ihre Pipeline die Schrittausgabedaten erwartet. In den meisten Fällen definiert ein Eingabeargument das Ausgabeverzeichnis, und dann erstellen Sie das Verzeichnis explizit. Verwenden Sie os.makedirs(args.output_dir, exist_ok=True), um das Ausgabeverzeichnis zu erstellen. Im Tutorial finden Sie ein Beispiel für ein Bewertungsskript, das dieses Entwurfsmuster zeigt. |
| Fehler bei Abhängigkeiten | Wenn in Ihrer Remotepipeline Abhängigkeitsfehler angezeigt werden, die beim lokalen Testen nicht aufgetreten sind, vergewissern Sie sich, dass die Abhängigkeiten und Versionen Ihrer Remoteumgebung mit denen in Ihrer Testumgebung übereinstimmen. (Siehe Erstellen, Zwischenspeichern und Wiederverwenden von Umgebungen) |
| Mehrdeutige Fehler bei Computezielen | Versuchen Sie, Computeziele zu löschen und neu zu erstellen. Die Neuerstellung von Computezielen erfolgt schnell und kann vorübergehende Probleme beheben. |
| Pipeline verwendet Schritte nicht wieder | Die Wiederverwendung von Schritten ist standardmäßig aktiviert, aber stellen Sie sicher, dass Sie sie in einem Pipelineschritt nicht deaktiviert haben. Wenn die Wiederverwendung deaktiviert ist, wird der Parameter allow_reuse im Schritt auf False festgelegt. |
| Pipeline wird unnötigerweise erneut ausgeführt | Um sicherzustellen, dass Schritte nur dann erneut ausgeführt werden, wenn die zugrunde liegenden Daten oder Skripts geändert werden, entkoppeln Sie Ihre Quellcodeverzeichnisse für die einzelnen Schritte. Wenn Sie dasselbe Quellverzeichnis für mehrere Schritte verwenden, kann es zu unnötigen Wiederholungen kommen. Verwenden Sie den Parameter source_directory in einem Pipelineschrittobjekt, um auf Ihr isoliertes Verzeichnis für diesen Schritt zu verweisen, und stellen Sie sicher, dass Sie nicht denselben source_directory-Pfad für mehrere Schritte verwenden. |
| Verlangsamter Schritt über Trainingsepochen oder andere Schleifenverhalten | Versuchen Sie, alle Dateischreibvorgänge, einschließlich der Protokollierung, von as_mount() zu as_upload() zu wechseln. Im mount-Modus wird ein virtualisiertes Remotedateisystem verwendet und die gesamte Datei jedes Mal hochgeladen, wenn sie angefügt wird. |
| Start des Computeziels dauert sehr lange | Docker-Images für Computeziele werden aus Azure Container Registry (ACR) geladen. Standardmäßig erstellt Azure Machine Learning eine ACR-Instanz mit der Dienstebene Basic. Wenn Sie die ACR-Instanz für Ihren Arbeitsbereich auf den Tarif „Standard“ oder „Premium“ umstellen, kann dies die Zeit zum Erstellen und Laden von Images verringern. Weitere Informationen finden Sie unter Azure Container Registry-Tarife. |
Authentifizierungsfehler
Wenn Sie einen Verwaltungsvorgang innerhalb eines Remoteauftrags auf ein Computeziel anwenden, erhalten Sie eine der folgenden Fehlermeldungen:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Sie erhalten beispielsweise eine Fehlermeldung, wenn Sie versuchen, ein Computeziel anhand einer ML-Pipeline zu erstellen oder anzuhängen, die zur Remoteausführung übermittelt wird.
Problembehandlung für ParallelRunStep
Das Skript für ParallelRunStep muss zwei Funktionen enthalten:
init(): Verwenden Sie diese Funktion für alle aufwendigen oder allgemeinen Vorbereitungsmaßnahmen für den späteren Rückschluss. Ein Beispiel wäre etwa das Laden des Modells in ein globales Objekt. Diese Funktion wird nur einmal zu Beginn des Prozesses aufgerufen.run(mini_batch): Die Funktion wird für jede Instanz vom Typmini_batchausgeführt.mini_batch:ParallelRunStepruft die Ausführungsmethode auf und übergibt entweder eine Liste oder einen Pandas-Datenrahmen (DataFrame) als Argument an die Methode. Jeder Eintrag in „mini_batch“ entspricht einem Dateipfad, wenn die Eingabe einFileDatasetist, bzw. einem Pandas-Datenrahmen (DataFrame), wenn die Eingabe einTabularDatasetist.response: Die Run-Methode sollte einen Pandas-Datenrahmen (DataFrame) oder ein Array zurückgeben. Bei Verwendung von „append_row output_action“ werden diese zurückgegebenen Elemente am Ende der allgemeinen Ausgabedatei hinzugefügt. Bei Verwendung von „summary_only“ wird der Inhalt der Elemente ignoriert. Bei allen Ausgabeaktionen geben die zurückgegebenen Ausgabeelemente jeweils eine erfolgreiche Ausführung für ein Eingabeelement aus dem Eingabeminibatch an. Stellen Sie sicher, dass das Ausführungsergebnis genügend Daten für eine Zuordnung zwischen der Eingabe und der Ausgabe des Ausführungsergebnisses enthält. Die Ausführungsausgabe wird in die Ausgabedatei geschrieben. Da hierbei nicht unbedingt die Reihenfolge eingehalten wird, müssen Sie einen Schlüssel in der Ausgabe verwenden, um sie der Eingabe zuzuordnen.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Wenn das Verzeichnis mit Ihrem Rückschlussskript noch andere Dateien oder Ordner enthält, können Sie einen Verweis darauf erstellen, indem Sie das aktuelle Arbeitsverzeichnis ermitteln.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parameter für ParallelRunConfig
ParallelRunConfig ist die Hauptkonfiguration für die ParallelRunStep-Instanz innerhalb der Azure Machine Learning-Pipeline. Sie wird verwendet, um Ihr Skript zu umschließen und die erforderlichen Parameter, einschließlich der folgenden Einträge, zu konfigurieren:
entry_script: Ein Benutzerskript als lokaler Dateipfad, das parallel auf mehreren Knoten ausgeführt wird. Istsource_directoryvorhanden, verwenden Sie einen relativen Pfad. Verwenden Sie andernfalls einen beliebigen Pfad, auf den auf dem Computer zugegriffen werden kann.mini_batch_size: Die Größe des Minibatchs, der an einen einzelnen Aufruf vonrun()übergeben wird (optional; Standardwerte sind10Dateien fürFileDatasetund1MBfürTabularDataset).- Bei
FileDatasethandelt es sich um die Anzahl von Dateien (Mindestwert:1). Mehrere Dateien können zu einem Minibatch zusammengefasst werden. - Bei
TabularDatasethandelt es sich um die Datengröße. Beispielwerte:1024,1024KB,10MB,1GB. Empfohlener Wert:1MB. Der Minibatch auf der Grundlage vonTabularDatasetgeht nie über Dateigrenzen hinaus. Ein Beispiel: Angenommen, Sie verfügen über unterschiedlich große CSV-Dateien. Die kleinste Datei hat eine Größe von 100 KB, die größte Datei ist 10 MB groß. Wenn Siemini_batch_size = 1MBfestlegen, werden Dateien mit einer Größe von weniger als 1 MB als einzelner Minibatch behandelt. Dateien mit einer Größe von mehr als 1 MB werden dagegen in mehrere Minibatches aufgeteilt.
- Bei
error_threshold: Die Anzahl von Datensatzfehlern fürTabularDatasetbzw. Dateifehlern fürFileDataset, die während der Verarbeitung ignoriert werden sollen. Übersteigt die Fehleranzahl für die gesamte Eingabe diesen Wert, wird der Auftrag abgebrochen. Der Fehlerschwellenwert gilt für die gesamte Eingabe und nicht für den einzelnen Minibatch, der an die Methoderun()gesendet wird. Zulässiger Bereich:[-1, int.max]. Der Teil-1gibt an, dass bei der Verarbeitung alle Fehler ignoriert werden sollen.output_action: Einer der folgenden Werte gibt an, wie die Ausgabe strukturiert werden soll:summary_only: Das Benutzerskript speichert die Ausgabe.ParallelRunStepverwendet die Ausgabe nur zur Berechnung des Fehlerschwellenwerts.append_row: Für alle Eingaben wird lediglich eine einzelne Datei im Ausgabeordner erstellt, in der alle Ausgaben angefügt werden (getrennt durch eine Zeile).
append_row_file_name: Zum Anpassen des Namens der Ausgabedatei für append_row output_action (optional; der Standardwert istparallel_run_step.txt).source_directory: Pfade zu Ordnern mit allen Dateien, die am Computeziel ausgeführt werden sollen (optional).compute_target: NurAmlComputewird unterstützt.node_count: Die Anzahl von Computeknoten, die zum Ausführen des Benutzerskripts verwendet werden sollen.process_count_per_node: Die Anzahl von Prozessen pro Knoten. Die bewährte Methode besteht im Festlegen auf die Anzahl der GPUs oder CPUs pro Knoten (optional; der Standardwert ist1).environment: Die Python-Umgebungsdefinition. Sie kann für die Verwendung einer vorhandenen Python-Umgebung oder für die Einrichtung einer temporären Umgebung konfiguriert werden. Die Definition kann auch zum Festlegen der erforderlichen Anwendungsabhängigkeiten verwendet werden (optional).logging_level: Die Ausführlichkeit des Protokolls. Mögliche Werte (mit zunehmender Ausführlichkeit):WARNING,INFO,DEBUG. (optional; Standardwert:INFO)run_invocation_timeout: Das Timeout für den Aufruf der Methoderun()in Sekunden. (optional; Standardwert60)run_max_try: Maximale Anzahl der Versuche vonrun()für einen Minibatch. Einrun()ist fehlgeschlagen, wenn eine Ausnahme ausgelöst wird oder beim Erreichen vonrun_invocation_timeoutnichts zurückgegeben wird (optional; der Standardwert ist3).
Sie können mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout und run_max_try als PipelineParameter festlegen, sodass Sie die Parameterwerte beim erneuten Senden einer Pipelineausführung optimieren können. In diesem Beispiel verwenden Sie PipelineParameter für mini_batch_size und Process_count_per_node, und Sie ändern diese Werte, wenn Sie später erneut eine Ausführung übermitteln.
Parameter zum Erstellen von ParallelRunStep
Erstellen Sie ParallelRunStep mithilfe von Skript, Umgebungskonfiguration und Parametern. Geben Sie das Computeziel an, das Sie bereits als Ausführungsziel für Ihr Rückschlussskript an Ihren Arbeitsbereich angefügt haben. Verwenden Sie ParallelRunStep, um den Batchrückschluss-Pipelineschritt mit folgenden Parametern zu erstellen:
name: Der Name des Schritts. Benennungseinschränkungen: eindeutig, 3–32 Zeichen und regulärer Ausdruck ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: Ein Objekt vom TypParallelRunConfig, wie zuvor definiert.inputs: Mindestens ein Azure Machine Learning-Dataset mit einem einzelnen Typ, das für die Parallelverarbeitung partitioniert werden soll.side_inputs: Verweisdaten oder Datasets, die als Seiteneingabe verwendet werden und für die keine Partitionierung erforderlich ist.output: EinOutputFileDatasetConfig-Objekt, das dem Ausgabeverzeichnis entspricht.arguments: Eine Liste mit Argumenten, die an das Benutzerskript übergeben werden. Verwenden Sie „unknown_args“, um sie in Ihrem Einstiegsskript zu nutzen (optional).allow_reuse: Angabe, ob bei dem Schritt vorherige Ergebnisse wiederverwendet werden sollen, wenn er mit den gleichen Einstellungen/Eingaben ausgeführt wird. Ist der Parameter aufFalsefestgelegt, wird für diesen Schritt bei der Pipelineausführung eine neue Ausführung generiert. (optional; StandardwertTrue)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Debuggingverfahren
Es gibt drei Haupttechniken zum Debuggen von Pipelines:
- Debuggen der einzelnen Pipelineschritte auf dem lokalen Computer
- Verwenden von Protokollierung und Application Insights zum Isolieren und Diagnostizieren der Problemursache
- Anfügen eines Remotedebuggers an eine in Azure ausgeführte Pipeline
Lokales Testen von Skripts
Einer der häufigsten Fehler in einer Pipeline besteht darin, dass das Domänenskript nicht wie beabsichtigt ausgeführt wird oder Laufzeitfehler im Remotecomputekontext enthält, die schwierig zu debuggen sind.
Pipelines selbst können nicht lokal ausgeführt werden. Wenn Sie jedoch die Skripts isoliert auf dem lokalen Computer ausführen, können Sie schneller debuggen, da Sie nicht auf den Compute- und Umgebungserstellungsprozess warten müssen. Hierfür ist ein gewisser Entwicklungsaufwand erforderlich:
- Wenn sich Ihre Daten in einem Clouddatenspeicher befinden, müssen Sie Daten herunterladen und Ihrem Skript zur Verfügung stellen. Die Verwendung einer kleinen Stichprobe Ihrer Daten ist eine gute Möglichkeit, die Laufzeit zu verkürzen und schnell Feedback zum Skriptverhalten zu erhalten.
- Wenn Sie versuchen, einen Pipelinezwischenschritt zu simulieren, müssen Sie die Objekttypen, die das jeweilige Skript vom vorherigen Schritt erwartet, möglicherweise manuell erstellen.
- Sie müssen Ihre eigene Umgebung definieren und die in Ihrer Remotecomputeumgebung definierten Abhängigkeiten replizieren.
Nachdem Sie ein Skript für die Ausführung in Ihrer lokalen Umgebung eingerichtet haben, gestalten sich Debuggingaufgaben wie die Folgenden viel einfacher:
- Anfügen einer benutzerdefinierten Debugkonfiguration
- Anhalten der Ausführung und Überprüfen des Objektzustands
- Abfangen von Typfehlern oder logischen Fehlern, die bis zur Laufzeit nicht verfügbar gemacht werden
Tipp
Wenn Sie sichergestellt haben, dass ihr Skript erwartungsgemäß ausgeführt wird, empfiehlt es sich, das Skript nun in einer Einzelschritt-Pipeline auszuführen, anstatt zu versuchen, das Skript in einer Pipeline mit mehreren Schritten auszuführen.
Konfigurieren und Überprüfen von Pipelineprotokollen sowie Schreiben in diese
Das lokale Testen von Skripts ist eine hervorragende Möglichkeit, wichtige Codefragmente und komplexe Logik zu debuggen, bevor Sie mit dem Erstellen einer Pipeline beginnen. Irgendwann müssen Sie Skripts während des eigentlichen Pipelinelaufs debuggen, insbesondere bei der Diagnose von Verhalten, das während der Interaktion zwischen Pipelineschritten auftritt. Wir empfehlen die großzügige Verwendung von print()-Anweisungen in Ihren Schrittskripts, damit Sie den Objektzustand und die erwarteten Werte während der Remoteausführung sehen können, ähnlich wie beim Debuggen von JavaScript-Code.
Protokollierungsoptionen und -verhalten
In der nachstehenden Tabelle finden Sie Informationen zu verschiedenen Debuggingoptionen für Pipelines. Es handelt sich nicht um eine vollständige Liste, da neben den hier gezeigten Optionen für Azure Machine Learning und Python auch andere vorhanden sind.
| Bibliothek | type | Beispiel | Destination | Ressourcen |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metrik | run.log(name, val) |
Benutzeroberfläche des Azure Machine Learning-Portals | Nachverfolgen von Experimenten Klasse „azureml.core.Run“ |
| Python-Druck/-Protokollierung | Log | print(val)logging.info(message) |
Treiberprotokolle, Azure Machine Learning-Designer | Nachverfolgen von Experimenten Python-Protokollierung |
Beispiel für Protokollierungsoptionen
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Azure Machine Learning-Designer
Die 70_driver_log-Dateien für die im Designer erstellten Pipelines finden Sie entweder auf der Seite zur Dokumenterstellung oder auf der Detailseite zur Pipelineausführung.
Aktivieren der Protokollierung für Echtzeitendpunkte
Für die Problembehandlung und das Debuggen von Echtzeitendpunkten im Designer müssen Sie die Application Insights-Protokollierung mithilfe des SDK aktivieren. Mithilfe der Protokollierung können Sie Probleme bei der Modellimplementierung und -verwendung behandeln und debuggen. Weitere Informationen finden Sie unter Protokollierung für bereitgestellte Modelle.
Abrufen von Protokollen auf der Seite zur Dokumenterstellung
Wenn Sie eine Pipelineausführung übermitteln und auf der Seite der Dokumenterstellung bleiben, finden Sie die Protokolldateien, die für jede Komponente generiert werden, sobald die Ausführung der einzelnen Komponenten abgeschlossen ist.
Wählen Sie eine Komponente aus, dessen Ausführung im Dokumenterstellungsbereich beendet wurde.
Wechseln Sie im rechten Bereich der Komponente zur Registerkarte Ausgaben und Protokolle.
Erweitern Sie den Bereich auf der rechten Seite, und wählen Sie die Datei 70_driver_log.txt aus, um sie im Browser anzuzeigen. Sie können Protokolle auch lokal herunterladen.
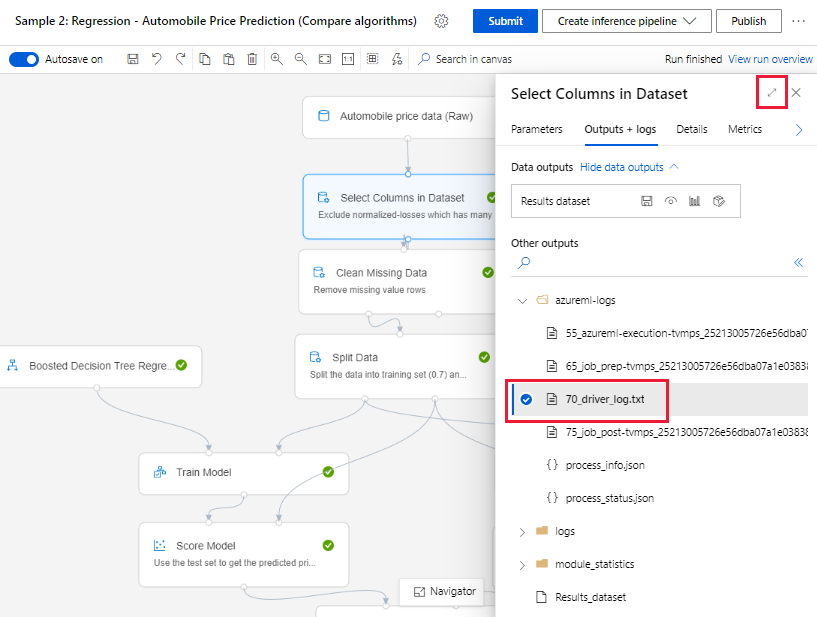
Abrufen von Protokollen von Pipelineausführungen
Sie finden die Protokolldateien bestimmter Ausführungen auch auf der Detailseite für Pipelineausführungen, entweder im Abschnitt Pipelines oder im Abschnitt Experimente des Studios.
Wählen Sie eine im Designer erstellte Pipelineausführung aus.
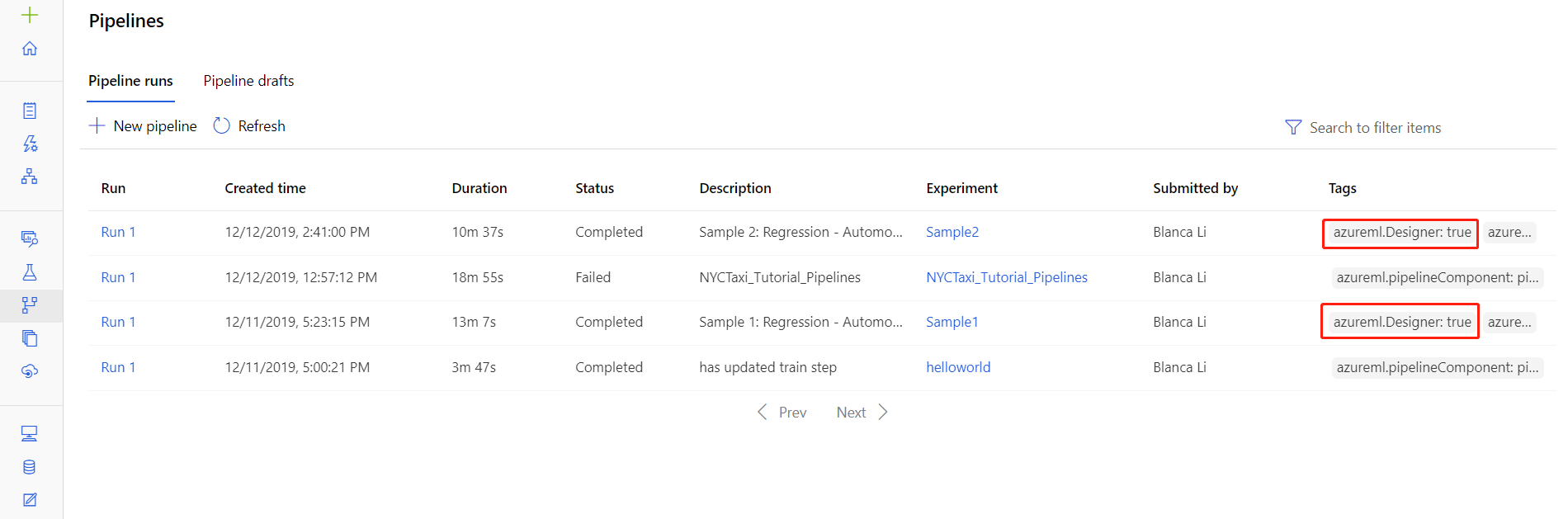
Wählen Sie im Vorschaubereich eine Komponente aus.
Wechseln Sie im rechten Bereich der Komponente zur Registerkarte Ausgaben und Protokolle.
Erweitern Sie den Bereich auf der rechten Seite, um die Datei std_log.txt im Browser anzuzeigen, oder wählen Sie die Datei aus, um die Protokolle lokal herunterzuladen.
Wichtig
Wenn Sie eine Pipeline über die Detailseite für Pipelineausführungen aktualisieren möchten, müssen Sie die Pipelineausführung in einen neuen Pipelineentwurf klonen. Pipelineausführungen sind Momentaufnahmen von Pipelines. Sie ähneln Protokolldateien und können nicht geändert werden.
Interaktives Debuggen mit Visual Studio Code
In einigen Fällen muss der in Ihrer ML-Pipeline verwendete Python-Code ggf. interaktiv debugged werden. Mit Visual Studio Code (VS Code) und debugpy können Sie am den Code anfügen, während er in der Trainingsumgebung ausgeführt wird. Weitere Informationen finden Sie im Leitfaden zum interaktiven Debuggen in VS Code.
Bei HyperdriveStep und AutoMLStep tritt mit Netzwerkisolation ein Fehler auf
Nach der Verwendung von HyperdriveStep und AutoMLStep wird beim Versuch, das Modell zu registrieren, möglicherweise ein Fehler angezeigt.
Sie verwenden das Azure Machine Learning SDK v1.
Ihr Azure Machine Learning-Arbeitsbereich ist für Netzwerkisolation (VNet) konfiguriert.
Ihre Pipeline versucht, das Modell zu registrieren, das im vorherigen Schritt generiert wurde. Im folgenden Beispiel ist der Parameter
inputsdas „saved_model“ aus einem HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Problemumgehung
Wichtig
Dieses Verhalten tritt bei Verwendung des Azure Machine Learning SDK v2 nicht auf.
Verwenden Sie zum Umgehen dieses Fehlers die Run-Klasse, um das Modell abzurufen, das im HyperdriveStep oder AutoMLStep erstellt wurde. Nachfolgend finden Sie ein Beispielskript, das das Ausgabemodell aus einem HyperdriveStep abruft:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Die Datei kann dann in einem PythonScriptStep verwendet werden:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Nächste Schritte
Ein vollständiges Tutorial zur Verwendung von
ParallelRunStepfinden Sie unter Tutorial: Erstellen einer Azure Machine Learning-Pipeline für die Batchbewertung.Ein umfassendes Beispiel, das automatisiertes maschinelles Lernen in ML-Pipelines veranschaulicht, finden Sie unter Verwenden von automatisiertem ML in einer Azure Machine Learning-Pipeline in Python.
Hilfe zu den Paketen azureml-pipelines-core und azureml-pipelines-steps finden Sie in der SDK-Referenz.
Weitere Informationen finden Sie in der Liste Designer-Ausnahmen und-Fehlercodes.