Beheben von Kubernetes-Computeproblemen
In diesem Artikel erfahren Sie, wie Sie häufige Fehler bei Workloads für die Kubernetes-Compute-Instanz beheben können. Häufige Fehler sind Trainingsaufträge und Endpunktfehler.
Rückschlussleitfaden
Die üblichen Kubernetes-Endpunktfehler für die Kubernetes-Compute-Instanz werden in zwei Bereiche kategorisiert: Computebereich und Clusterbereich. Die Computebereichsfehler beziehen sich auf das Computeziel, z. B. wird das Computeziel nicht gefunden, oder das Computeziel ist nicht zugänglich. Die Clusterbereichsfehler beziehen sich auf den zugrunde liegenden Kubernetes-Cluster, z. B. ist der Cluster selbst nicht erreichbar oder der Cluster wird nicht gefunden.
Kubernetes-Computefehler
Im Folgenden sehen Sie allgemeine Fehlertypen aus dem Computebereich, die auftreten können, wenn Sie Kubernetes-Compute verwenden, um Onlineendpunkte und Onlinebereitstellungen für Echtzeitmodellrückschlüsse zu erstellen. Diese Fehler können Sie mithilfe der folgenden Leitfäden beheben:
- FEHLER: GenericComputeError
- FEHLER: ComputeNotFound
- FEHLER: ComputeNotAccessible
- FEHLER: InvalidComputeInformation
- FEHLER: InvalidComputeNoKubernetesConfiguration
FEHLER: GenericComputeError
Fehlermeldung:
Failed to get compute information.
Dieser Fehler tritt auf, wenn das System die Computeinformationen aus dem Kubernetes-Cluster nicht abrufen konnte. Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
- Überprüfen Sie den Status des Kubernetes-Clusters. Wenn der Cluster nicht ausgeführt wird, müssen Sie zunächst den Cluster starten.
- Überprüfen Sie die Integrität des Kubernetes-Clusters.
- Sie können im Bericht zur Clusterintegritätsprüfung nach allen Problemen suchen, auch wenn z. B. der Cluster nicht erreichbar ist.
- Wechseln Sie zu Ihrem Arbeitsbereichsportal, um den Computestatus zu überprüfen.
- Überprüfen Sie, ob die Instanztypeninformationen korrekt sind. Sie können die unterstützten Instanztypen in der Dokumentation zu Kubernetes-Compute überprüfen.
- Versuchen Sie ggf., die Compute-Instanz zu trennen und erneut an den Arbeitsbereich anzufügen.
Hinweis
Damit Sie Fehler durch ein erneutes Anfügen behandeln können, müssen Sie die Compute-Instanz unbedingt mit derselben Konfiguration wie zuvor anfügen (d. h. mit demselben Computenamen und Namespace), da andernfalls weitere Fehler auftreten können.
FEHLER: ComputeNotFound
Die Fehlermeldung lautet wie folgt:
Cannot find Kubernetes compute.
Dieser Fehler tritt in folgenden Situationen auf:
- Das System kann die Compute-Instanz beim Erstellen/Aktualisieren neuer Onlineendpunkte/Bereitstellungen nicht finden.
- Die Compute-Instanz vorhandener Onlineendpunkte/Bereitstellungen wurde entfernt.
Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
- Versuchen Sie, den Endpunkt und die Bereitstellung erneut zu erstellen.
- Versuchen Sie, die Compute-Instanz zu trennen und erneut an den Arbeitsbereich anzufügen. Beachten Sie die ergänzenden Hinweise zum erneuten Anfügen.
FEHLER: ComputeNotAccessible
Die Fehlermeldung lautet wie folgt:
The Kubernetes compute is not accessible.
Dieser Fehler tritt auf, wenn die verwaltete Identität (MSI) des Arbeitsbereichs keinen Zugriff auf den AKS-Cluster hat. Sie können überprüfen, ob die Arbeitsbereichs-MSI Zugriff auf AKS hat. Andernfalls können Sie den Zugriff und die Identität mithilfe dieses Dokuments verwalten.
FEHLER: InvalidComputeInformation
Die Fehlermeldung lautet wie folgt:
The compute information is invalid.
Bei der Bereitstellung von Modellen in Ihrem Kubernetes-Cluster wird ein Prozess zur Überprüfung der Computeziele durchgeführt. Dieser Fehler tritt auf, wenn die Computeinformationen ungültig sind, wenn z. B. das Computeziel nicht gefunden wurde oder die Konfiguration der Azure Machine Learning-Erweiterung in Ihrem Kubernetes-Cluster aktualisiert wurde.
Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
- Überprüfen Sie, ob das verwendete Computeziel korrekt und in Ihrem Arbeitsbereich vorhanden ist.
- Versuchen Sie, die Compute-Instanz zu trennen und erneut an den Arbeitsbereich anzufügen. Beachten Sie die ergänzenden Hinweise zum erneuten Anfügen.
FEHLER: InvalidComputeNoKubernetesConfiguration
Die Fehlermeldung lautet wie folgt:
The compute kubeconfig is invalid.
Dieser Fehler tritt auf, wenn das System keine Konfiguration für die Verbindung mit dem Cluster gefunden hat, z. B.:
- Für Arc-Kubernetes-Cluster wird keine Azure Relay-Konfiguration gefunden.
- Für AKS-Cluster wird keine AKS-Konfiguration gefunden.
Um die Konfiguration der Computeverbindung in Ihrem Cluster neu zu erstellen, können Sie versuchen, die Compute-Instanz zu trennen und erneut an den Arbeitsbereich anzufügen. Beachten Sie die ergänzenden Hinweise zum erneuten Anfügen.
Kubernetes-Clusterfehler
Im Folgenden finden Sie eine Liste der Fehlertypen aus dem Clusterbereich, die auftreten können, wenn Sie Kubernetes-Compute verwenden, um Onlineendpunkte und Onlinebereitstellungen für Echtzeitmodellrückschlüsse zu erstellen. Diese Fehler können Sie mithilfe des folgenden Leitfadens beheben:
- FEHLER: GenericClusterError
- FEHLER: ClusterNotReachable
- FEHLER: ClusterNotFound
- ERROR: ClusterServiceNotFound
- ERROR: ClusterUnauthorized
FEHLER: GenericClusterError
Die Fehlermeldung lautet wie folgt:
Failed to connect to Kubernetes cluster: <message>
Dieser Fehler tritt auf, wenn das System aus einem unbekannten Grund keine Verbindung mit dem Kubernetes-Cluster herstellen konnte. Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
Für AKS-Cluster:
- Überprüfen Sie, ob der AKS-Cluster heruntergefahren wurde.
- Wenn der Cluster nicht ausgeführt wird, müssen Sie zunächst den Cluster starten.
- Überprüfen Sie, ob das ausgewählte Netzwerk mithilfe autorisierter IP-Bereiche im AKS-Cluster aktiviert wurde.
- Wenn im AKS-Cluster autorisierte IP-Bereiche aktiviert wurden, stellen Sie sicher, dass alle IP-Bereiche der Azure Machine Learning-Steuerungsebene für den AKS-Cluster aktiviert wurden. Weitere Informationen finden Sie in diesem Dokument.
Für AKS-Cluster oder Azure Arc-fähige Kubernetes-Cluster:
- Überprüfen Sie, ob auf den Kubernetes-API-Server zugegriffen werden kann, indem Sie den Befehl
kubectlim Cluster ausführen.
FEHLER: ClusterNotReachable
Die Fehlermeldung lautet wie folgt:
The Kubernetes cluster is not reachable.
Dieser Fehler tritt auf, wenn das System keine Verbindung mit einem Cluster herstellen kann. Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
Für AKS-Cluster:
- Überprüfen Sie, ob der AKS-Cluster heruntergefahren wurde.
- Wenn der Cluster nicht ausgeführt wird, müssen Sie zunächst den Cluster starten.
Für AKS-Cluster oder Azure Arc-fähige Kubernetes-Cluster:
- Überprüfen Sie, ob auf den Kubernetes-API-Server zugegriffen werden kann, indem Sie den Befehl
kubectlim Cluster ausführen.
FEHLER: ClusterNotFound
Die Fehlermeldung lautet wie folgt:
Cannot found Kubernetes cluster.
Dieser Fehler tritt auf, wenn das System den AKS-/Arc-Kubernetes-Cluster nicht finden kann.
Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
- Überprüfen Sie zunächst die Clusterressourcen-ID im Azure-Portal, um zu prüfen, ob die Kubernetes-Clusterressource noch vorhanden ist und normal ausgeführt wird.
- Wenn der Cluster vorhanden ist und ausgeführt wird, können Sie versuchen, die Compute-Instanz zu trennen und erneut an den Arbeitsbereich anzufügen. Beachten Sie die ergänzenden Hinweise zum erneuten Anfügen.
ERROR: ClusterServiceNotFound
Die Fehlermeldung lautet wie folgt:
AzureML extension service not found in cluster.
Dieser Fehler tritt in der Regel auf, wenn der erweiterungseigene Eingangsdienst nicht über genügend Back-End-Pods verfügt.
Sie können Folgendes ausführen:
- Greifen Sie auf den Cluster zu, und überprüfen Sie den Status des Diensts
azureml-ingress-nginx-controllerund seines Back-End-Pods unter demazureml-Namespace. - Wenn der Cluster über keine ausgeführten Back-End-Pods verfügt, überprüfen Sie den Grund, indem Sie den Pod beschreiben. Wenn der Pod beispielsweise nicht über genügend Ressourcen für die Ausführung verfügt, können Sie einige Pods löschen, um ausreichend Ressourcen für den Eingangspod freizugeben.
ERROR: ClusterUnauthorized
Die Fehlermeldung lautet wie folgt:
Request to Kubernetes cluster unauthorized.
Dieser Fehler sollte nur im Cluster mit TA-Aktivierung auftreten. Das bedeutet, dass das Zugriffstoken während der Bereitstellung abgelaufen ist.
Sie können es nach einigen Minuten erneut versuchen.
Tipp
Weitere Anleitungen zur Problembehandlung allgemeiner Fehler beim Erstellen/Aktualisieren der Kubernetes-Onlineendpunkte und -Onlinebereitstellungen finden Sie unter Problembehandlung bei der Bereitstellung und Bewertung von Onlineendpunkten.
Identitätsfehler
FEHLER: RefreshExtensionIdentityNotSet
Dieser Fehler tritt auf, wenn die Erweiterung installiert wird, aber die Erweiterungsidentität nicht ordnungsgemäß zugewiesen ist. Sie können versuchen, die Erweiterung erneut zu installieren, um den Fehler zu beheben.
Bitte beachten Sie, dass dieser Fehler nur für verwaltete Cluster gilt
Wie überprüfen Sie, ob sslCertPemFile und sslKeyPemFile korrekt sind?
Damit alle bekannten Fehler angezeigt werden können, können Sie mithilfe der Befehle eine Baselineüberprüfung für Ihr Zertifikat und Ihren Schlüssel ausführen. Beim zweiten Befehl können Sie als Rückgabe „RSA key ok“ (RSA-Schlüssel in Ordnung) erwarten, ohne dass Sie zur Eingabe des Kennworts aufgefordert werden.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Führen Sie die Befehle aus, um zu überprüfen, ob sslCertPemFile und sslKeyPemFile übereinstimmen:
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Bei sslCertPemFile handelt es sich um das öffentliche Zertifikat. Es muss die Zertifikatkette mit folgenden Zertifikaten in der hier angegebenen Reihenfolge enthalten: Serverzertifikat, Zertifikat der Zwischenzertifizierungsstelle und Zertifikat der Stammzertifizierungsstelle:
- Serverzertifikat: Während des TLS-Handshakes stellt der Server sein Zertifikat für den Client bereit. Es enthält den öffentlichen Schlüssel, den Domänennamen und andere Informationen des Servers. Das Serverzertifikat wird von einer Zwischenzertifizierungsstelle signiert, die für die Serveridentität bürgt.
- Zertifikat der Zwischenzertifizierungsstelle: Die Zwischenzertifizierungsstelle stellt das Zertifikat für den Client bereit, um ihre Befugnis zum Signieren des Serverzertifikats nachzuweisen. Es enthält den öffentlichen Schlüssel, den Namen und andere Informationen der Zwischenzertifizierungsstelle. Das Zertifikat der Zwischenzertifizierungsstelle wird von einer Stammzertifizierungsstelle signiert, die für die Identität der Zwischenzertifizierungsstelle bürgt.
- Zertifikat der Stammzertifizierungsstelle: Die Stammzertifizierungsstelle stellt das Zertifikat für den Client bereit, um ihre Befugnis zum Signieren des Zertifikats der Zwischenzertifizierungsstelle nachzuweisen. Es enthält den öffentlichen Schlüssel, den Namen und andere Informationen der Stammzertifizierungsstelle. Das Zertifikat der Stammzertifizierungsstelle ist selbstsigniert und wird vom Client als vertrauenswürdig eingestuft.
Trainingsleitfaden
Wenn der Trainingsauftrag ausgeführt wird, können Sie den Status des Auftrags im Arbeitsbereichsportal überprüfen. Wenn Sie auf einen anormalen Auftragsstatus stoßen, z. B. wenn der Auftrag mehrfach wiederholt wurde, im Initialisierungsstatus stecken geblieben ist oder sogar fehlerhaft war, können Sie die Anleitung zur Problembehandlung befolgen.
Debuggen der Auftragswiederholung
Wenn der im Cluster ausgeführte Pod für den Trainingsauftrag beendet wurde, da der Knoten in den Status „Knoten-OOM“ (nicht genügend Arbeitsspeicher) geriet, wird der Auftrag in einem anderen verfügbaren Knoten automatisch wiederholt.
Um die Grundursache des Auftragsversuchs weiter zu debuggen, können Sie zum Arbeitsbereichsportal wechseln, um das Auftragswiederholungsprotokoll zu überprüfen.
- Jedes Wiederholungsprotokoll wird in einem neuen Protokollordner mit dem Format „Wiederholung-<Wiederholungsnummer>“ (z. B. Wiederholung-001) aufgezeichnet.
Anschließend können Sie die Informationen zur Knotenzuordnung von Wiederholungsaufträgen abrufen, um herauszufinden, auf welchem Knoten der Wiederholungsauftrag ausgeführt wurde.
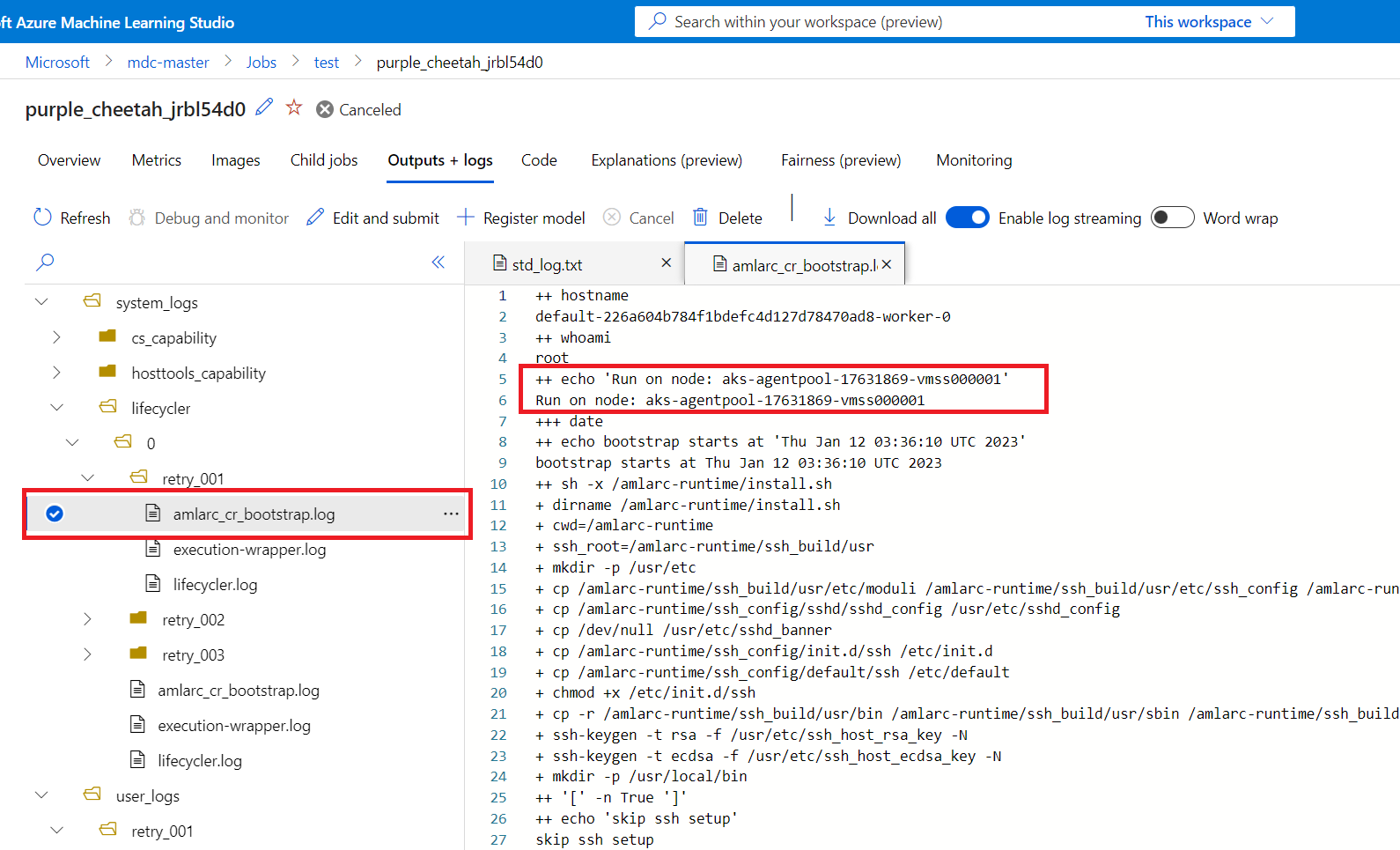
Sie können Auftragsknotenzuordnungsinformationen aus der Datei amlarc_cr_bootstrap.log im Ordner system_logs abrufen.
Der Hostname des Knotens, auf dem der Pod des Auftrags ausgeführt wird, wird in diesem Protokoll angegeben, beispielsweise:
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
„ask-agentpool-17631869-vmss0000“ stellt den Knotenhostnamen dar, der diesen Auftrag in Ihrem AKS-Cluster ausführt. Anschließend können Sie auf den Cluster zugreifen, um den Knotenstatus für weitere Untersuchungen zu überprüfen.
Auftragspod bleibt im Initialisierungszustand hängen
Wenn der Auftrag länger als erwartet ausgeführt wird und Sie feststellen, dass Ihre Auftragspods mit der Warnung Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched im Initialisierungszustand hängen bleiben, könnte das Problem dadurch verursacht werden, dass die Azure Machine Learning-Erweiterung den Downloadmodus für Eingabedaten nicht unterstützt.
Um dieses Problem zu beheben, stellen Sie Ihre Eingabedaten auf den Einbindungsmodus um.
Häufige Auftragsfehler
Im Folgenden finden Sie eine Liste häufiger Fehlertypen, auf die Sie stoßen können, wenn Sie die Kubernetes-Compute-Instanz verwenden, um einen Trainingsauftrag zu erstellen und auszuführen, und die Sie mithilfe des Leitfadens beheben können:
- Fehler beim Ausführen des Auftrags. 137
- Fehler beim Ausführen des Auftrags. E45004
- Fehler beim Ausführen des Auftrags. 400
- Geben Sie entweder einen Kontoschlüssel oder ein SAS-Token an.
- Fehler bei der AzureBlob-Autorisierung
Fehler beim Ausführen des Auftrags. 137
Die Fehlermeldung lautet:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Überprüfen Sie Ihre Proxyeinstellung, und ob 127.0.0.1 in proxy-skip-range hinzugefügt wurde, wenn Sie az connectedk8s connect verwenden. Befolgen Sie dazu diese Netzwerkkonfiguration.
Fehler beim Ausführen des Auftrags. E45004
Die Fehlermeldung lautet:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Überprüfen Sie, ob Sie bei der Installation der Azure Machine Learning-Erweiterung enableTraining=True festgelegt haben. Weitere Informationen finden Sie unter Bereitstellen der AzureML-Erweiterung auf AKS- oder Arc Kubernetes-Cluster.
Fehler beim Ausführen des Auftrags. 400
Die Fehlermeldung lautet:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Im Abschnitt zur Problembehandlung bei Private Link finden Sie Informationen zum Überprüfen Ihrer Netzwerkeinstellungen.
Geben Sie entweder einen Kontoschlüssel oder ein SAS-Token an.
Wenn Sie auf Azure Container Registry (ACR) für ein Docker-Image und ein Speicherkonto für Trainingsdaten zugreifen müssen, tritt dieses Problem auf, wenn die Compute-Instanz nicht mit einer verwalteten Identität angegeben wurde.
Um von einem Kubernetes-Computecluster aus auf die Azure Container Registry (ACR) für Docker-Images oder auf ein Speicherkonto für Trainingsdaten zuzugreifen, müssen Sie die Kubernetes-Compute-Instanz mit einer system- oder benutzerseitig zugewiesenen verwalteten Identität verbinden.
Im obigen Trainingsszenario ist diese Compute-Identität notwendig, damit die Kubernetes-Compute-Instanz als Anmeldeinformation für die Kommunikation zwischen der an den Arbeitsbereich gebundenen ARM-Ressource und dem Kubernetes-Computecluster verwendet werden kann. Ohne diese Identität tritt bei dem Trainingsauftrag ein Fehler auf, und es wird ein fehlender Kontoschlüssel oder ein fehlendes SAS-Token gemeldet. Wenn Sie z. B. beim Zugriff auf ein Speicherkonto keine verwaltete Identität für Ihre Kubernetes-Compute-Instanz angeben, tritt beim Auftrag ein Fehler mit folgender Fehlermeldung auf:
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
Das liegt daran, dass das Standardspeicherkonto für den Machine Learning-Arbeitsbereich ohne Anmeldeinformationen nicht für Trainingsaufträge in der Kubernetes-Compute-Instanz zugänglich ist.
Um dieses Problem zu beheben, können Sie der Compute-Instanz die verwaltete Identität beim Anfügen oder danach zuweisen. Weitere Informationen finden Sie unter Zuweisen einer verwalteten Identität zum Computeziel.
Fehler bei der AzureBlob-Autorisierung
Wenn Sie in Ihren Trainingsaufträgen für die Kubernetes-Compute-Instanz zum Hoch- oder Herunterladen von Daten auf AzureBlob zugreifen müssen, tritt bei diesem Auftrag ein Fehler mit folgender Fehlermeldung auf:
Unable to upload project files to working directory in AzureBlob because the authorization failed.
Das liegt daran, dass die Autorisierung fehlerhaft war, als der Auftrag versucht hat, die Projektdateien in AzureBlob hochzuladen. Überprüfen Sie die folgenden Elemente, um das Problem zu beheben:
- Stellen Sie sicher, dass für das Speicherkonto die Ausnahmen von „Azure-Diensten in der Liste vertrauenswürdiger Dienste den Zugriff auf dieses Speicherkonto erlauben“ aktiviert wurden und dass der Arbeitsbereich in der Liste der Ressourceninstanzen enthalten ist.
- Stellen Sie sicher, dass der Arbeitsbereich über eine systemseitig zugewiesene verwaltete Identität verfügt.
Probleme bei Private Link
Mit der folgenden Methode können Sie die Einrichtung von Private Link überprüfen. Melden Sie sich dazu bei einem Pod im Kubernetes-Cluster an, und überprüfen Sie dann die zugehörigen Netzwerkeinstellungen.
Suchen Sie die Arbeitsbereichs-ID im Azure-Portal, oder rufen Sie diese ID ab, indem Sie
az ml workspace showan der Befehlszeile ausführen.Sie können alle „azureml-fe“-Pods anzeigen, indem Sie
kubectl get po -n azureml -l azuremlappname=azureml-feausführen.Melden Sie sich bei einem von diesen an, und führen Sie
kubectl exec -it -n azureml {scorin_fe_pod_name} bashaus.Wenn der Cluster keinen Proxy verwendet, führen Sie
nslookup {workspace_id}.workspace.{region}.api.azureml.msaus. Wenn Sie den Private Link vom VNet zum Arbeitsbereich ordnungsgemäß eingerichtet haben, sollte die interne IP-Adresse im VNet über das Tool DNSLookup reagieren.Wenn der Cluster einen Proxy verwendet, können Sie versuchen,
curlfür den Arbeitsbereich auszuführen.
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Wenn der Proxy und der Arbeitsbereich ordnungsgemäß mit einer privaten Verbindung eingerichtet sind, sollten Sie sehen, dass versucht wird, eine Verbindung mit einer internen IP-Adresse herzustellen. Eine Antwort mit dem HTTP-Statuscode 401 wird in diesem Szenario erwartet, wenn kein Token bereitgestellt wird.
Andere bekannte Probleme
Kubernetes-Compute-Update tritt nicht in Kraft
Derzeit lassen CLI v2 und SDK v2 das Aktualisieren einer Konfiguration einer vorhandenen Kubernetes-Computeressource nicht zu. Beispielsweise wird eine Änderung des Namespace nicht wirksam.
Arbeitsbereichs- oder Ressourcengruppenname endet mit „-“
Eine häufige Ursache für den Fehler „InternalServerError“ beim Erstellen von Workloads wie Bereitstellungen, Endpunkten oder Aufträgen in einer Kubernetes-Computeressource ist die Verwendung von Sonderzeichen wie „-“ am Ende des Arbeitsbereichs- oder Ressourcengruppennamens.