Bereitstellen von Modellen für die Bewertung in Batchendpunkten
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Batchendpunkte bieten eine bequeme Möglichkeit, Modelle bereitzustellen, die Rückschlüsse über große Datenmengen ausführen. Diese Endpunkte vereinfachen das Hosten Ihrer Modelle für die Batchbewertung, sodass Sie sich auf das maschinelle Lernen und nicht auf die Infrastruktur konzentrieren können.
Verwenden Sie Batchendpunkte in folgenden Fällen für die Modellimplementierung:
- Sie verfügen über aufwendige Modelle, bei denen die Ausführung des Rückschlusses mehr Zeit in Anspruch nimmt.
- Sie müssen Rückschlüsse über große Datenmengen durchführen, die auf mehrere Dateien verteilt sind.
- Sie haben keine niedrigen Latenzanforderungen.
- Sie können die Parallelisierung nutzen.
In diesem Artikel verwenden Sie einen Batchendpunkt, um ein Machine Learning-Modell bereitzustellen, das das klassische MNIST-Ziffernerkennungsproblem (Modified National Institute of Standards and Technology) löst. Das bereitgestellte Modell führt dann Batchrückschlüsse über große Datenmengen aus – in diesem Fall Bilddateien. Zunächst erstellen Sie eine Batchbereitstellung eines Modells, das mit Torch erstellt wurde. Dies wird die Standardbereitstellung des Endpunkts. Später erstellen Sie eine zweite Bereitstellung eines Modells, das mit TensorFlow (Keras) erstellt wurde, testen diese zweite Bereitstellung und legen sie dann als Standardbereitstellung des Endpunkts fest.
Wenn Sie die Codebeispiele und Dateien nachvollziehen möchten, die zum lokalen Ausführen der Befehle in diesem Artikel erforderlich sind, lesen Sie den Abschnitt Klonen des Beispielrepositorys. Die Codebeispiele und Dateien sind im Repository azureml-examples enthalten.
Voraussetzungen
Stellen Sie vor dem Ausführen der Schritte in diesem Artikel sicher, dass Sie die folgenden Voraussetzungen erfüllt sind:
Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Ein Azure Machine Learning-Arbeitsbereich. Wenn Sie keinen Arbeitsbereich haben, führen Sie die Schritte im Artikel Verwalten von Arbeitsbereichen aus, um einen Arbeitsbereich zu erstellen.
Um die folgenden Aufgaben auszuführen, müssen Sie im Arbeitsbereich über die folgenden Berechtigungen verfügen:
Verwenden Sie zum Erstellen/Verwalten von Batchendpunkten und Bereitstellungen die Rolle „Besitzer“ oder „Mitwirkender“ bzw. eine benutzerdefinierte Rolle, die
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*zulässt.Verwenden Sie zum Erstellen von ARM-Bereitstellungen in der Ressourcengruppe des Arbeitsbereichs die Rolle „Besitzer“ oder „Mitwirkender“ bzw. eine benutzerdefinierte Rolle, die
Microsoft.Resources/deployments/writein der Ressourcengruppe zulässt, in der der Arbeitsbereich bereitgestellt wird.
Für die Arbeit mit Azure Machine Learning müssen Sie die folgende Software installieren:
GILT FÜR
Azure CLI-ML-Erweiterung v2 (aktuell)Die Azure CLI und die
ml-Erweiterung für Azure Machine Learning.az extension add -n ml
Klonen des Beispielrepositorys
Das Beispiel in diesem Artikel basiert auf Codebeispielen, die im Repository azureml-examples enthalten sind. Um die Befehle lokal auszuführen, ohne YAML und andere Dateien kopieren/einfügen zu müssen, klonen Sie zunächst das Repository, und ändern Sie dann die Verzeichnisse zum Ordner:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Vorbereiten Ihres Systems
Herstellen einer Verbindung mit Ihrem Arbeitsbereich
Stellen Sie zunächst eine Verbindung mit dem Azure Machine Learning-Arbeitsbereich her, in dem Sie arbeiten.
Wenn Sie die Standardeinstellungen für die Azure-Befehlszeilenschnittstelle noch nicht festgelegt haben, speichern Sie Ihre Standardeinstellungen. Um zu vermeiden, dass Sie die Werte für Ihr Abonnement, Ihren Arbeitsbereich, Ihre Ressourcengruppe und Ihren Standort mehrfach eingeben müssen, führen Sie den folgenden Code aus:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Erstellen von Computeressourcen
Batchendpunkte werden in Computeclustern ausgeführt und unterstützen sowohl Azure Machine Learning-Computecluster (AmlCompute) als auch Kubernetes-Cluster. Cluster sind eine freigegebene Ressource, sodass ein Cluster eine oder mehrere Batchbereitstellungen hosten kann (zusammen mit anderen Workloads, falls gewünscht).
Erstellen Sie eine Computeressource mit dem Namen batch-cluster, wie im folgenden Code dargestellt. Sie können diese nach Bedarf anpassen und mit azureml:<your-compute-name> auf Ihre Computeressourcen verweisen.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Hinweis
Zu diesem Zeitpunkt werden Ihnen noch keine Computeressourcen in Rechnung gestellt, da der Cluster bei 0 (null) Knoten verbleibt, bis ein Batchendpunkt aufgerufen und ein Batchbewertungsauftrag übermittelt wird. Weitere Informationen zu Computekosten finden Sie unter Verwalten und Optimieren der Kosten für AmlCompute.
Erstellen eines Batchendpunkts
Ein Batchendpunkt ist ein HTTPS-Endpunkt, den Clients aufrufen können, um einen Batchbewertungsauftrag auszulösen. Ein Batchbewertungsauftrag ist ein Auftrag, der mehrere Eingaben bewertet. Eine Batchbereitstellung umfasst die Computeressourcen, mit denen das Modell gehostet wird, das die eigentlichen Batchbewertungen (oder Batchrückschlüsse) durchführt. Ein Batchendpunkt kann über mehrere Batchbereitstellungen verfügen. Weitere Informationen zu Batchendpunkten finden Sie unter Was sind Batchendpunkte?.
Tipp
Eine der Batchbereitstellungen dient als Standardbereitstellung für den Endpunkt. Wenn der Endpunkt aufgerufen wird, führt die Standardbereitstellung die eigentliche Batchbewertung durch. Weitere Informationen zu Batchendpunkten und -bereitstellungen finden Sie unter Batchendpunkte und Batchbereitstellung.
Benennen Sie den Endpunkt. Der Name des Endpunkts muss innerhalb einer Azure-Region eindeutig sein, da der Name im URI des Endpunkts enthalten ist. Beispielsweise kann es nur einen Endpunkt namens
mybatchendpointinwestus2geben.Speichern Sie den Namen des Endpunkts in einer Variable, damit Sie später ganz einfach darauf verweisen können.
ENDPOINT_NAME="mnist-batch"Konfigurieren des Batchendpunkts
Die folgende YAML-Datei definiert einen Batchendpunkt. Sie können diese Datei mit dem CLI-Befehl für die Erstellung von Batchendpunkten verwenden.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningIn der folgenden Tabelle werden die wichtigsten Eigenschaften des Endpunkts beschrieben. Das vollständige YAML-Schema für den Batchendpunkt finden Sie unter CLI (v2) Batchendpunkt-YAML-Schema.
Schlüssel BESCHREIBUNG nameDer Name des Batchendpunkts. Muss auf Azure-Regionsebene eindeutig sein. descriptionDie Beschreibung des Batchendpunkts. Diese Eigenschaft ist optional. tagsDie Tags, die in den Endpunkt eingeschlossen werden sollen. Diese Eigenschaft ist optional. Erstellen des Endpunkts:
Führen Sie den folgenden Code aus, um einen Batchendpunkt zu erstellen.
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
Erstellen einer Batchbereitstellung
Eine Modellimplementierung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das die eigentlichen Rückschlüsse ausführt. Um eine Batchmodellimplementierung zu erstellen, benötigen Sie die folgenden Elemente:
- Ein im Arbeitsbereich registriertes Modell
- Code zur Bewertung des Modells
- Eine Umgebung, in der die Abhängigkeiten des Modells installiert sind
- Vordefinierte Compute- und Ressourceneinstellungen
Beginnen Sie mit der Registrierung des Modells, das bereitgestellt werden soll, in diesem Fall ein Torch-Modell für das bekannte Problem der Ziffernerkennung (MNIST). Mit Batchbereitstellungen können nur Modelle bereitgestellt werden, die im Arbeitsbereich registriert sind. Sie können diesen Schritt überspringen, wenn das Modell, das Sie bereitstellen möchten, bereits registriert ist.
Tipp
Modelle sind der Bereitstellung und nicht dem Endpunkt zugeordnet. Dies bedeutet, dass an einem einzelnen Endpunkt mehrere Modelle (oder Modellversionen) bereitgestellt werden können, sofern die verschiedenen Modelle (oder Modellversionen) in verschiedenen Bereitstellungen bereitgestellt werden.
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"Nun ist es an der Zeit, ein Bewertungsskript zu erstellen. Batchbereitstellungen erfordern ein Bewertungsskript, das angibt, wie ein bestimmtes Modell ausgeführt werden soll und wie Eingabedaten verarbeitet werden müssen. Batchendpunkte unterstützen in Python erstellte Skripts. In diesem Fall wird ein Modell bereitgestellt, das Dateien mit Bilddarstellungen von Ziffern liest und die entsprechende Ziffer ausgibt. Das Bewertungsskript entspricht dem folgenden:
Hinweis
Bei MLflow-Modellen generiert Azure Machine Learning das Bewertungsskript automatisch, sodass Sie keines angeben müssen. Wenn es sich bei Ihrem Modell um ein MLflow-Modell handelt, können Sie diesen Schritt überspringen. Weitere Einzelheiten zur Funktionsweise von Batchendpunkten mit MLflow-Modellen finden Sie im Artikel Verwenden von MLflow-Modellen in Batchbereitstellungen.
Warnung
Wenn Sie ein AutoML-Modell (automatisiertes maschinelles Lernen) auf einem Batchendpunkt bereitstellen, beachten Sie, dass das von AutoML bereitgestellte Bewertungsskript nur für Onlineendpunkte funktioniert und nicht für die Batchausführung konzipiert ist. Weitere Informationen zum Erstellen eines Bewertungsskripts für Ihre Batchbereitstellung finden Sie unter Erstellen von Bewertungsskripts für Batchbereitstellungen.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Erstellen Sie eine Umgebung, in der Ihre Batchbereitstellung ausgeführt wird. Diese Umgebung muss die Pakete
azureml-coreundazureml-dataset-runtime[fuse]enthalten, die für Batchendpunkte benötigt werden, sowie alle für die Ausführung Ihres Codes erforderlichen Abhängigkeiten. In diesem Fall wurden die Abhängigkeiten in der Dateiconda.yamlerfasst:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Wichtig
Die Pakete
azureml-coreundazureml-dataset-runtime[fuse]sind für Batchbereitstellungen erforderlich und sollten in die Umgebungsabhängigkeiten aufgenommen werden.Geben Sie die Umgebung wie folgt an:
Die Umgebungsdefinition wird als anonyme Umgebung in die Bereitstellungsdefinition selbst aufgenommen. Sie sehen die folgenden Zeilen in der Bereitstellung:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlWarnung
Zusammengestellte Umgebungen werden in Batchbereitstellungen nicht unterstützt. Sie müssen Ihre eigene Umgebung angeben. Sie können jederzeit das Basisimage einer zusammengestellten Umgebung als Ihres verwenden, um den Prozess zu vereinfachen.
Neue Bereitstellungsdefinition erstellen
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoIn der folgenden Tabelle werden die wichtigsten Eigenschaften der Batchbereitstellung beschrieben. Das vollständige YAML-Schema für die Batchbereitstellung finden Sie unter CLI (v2) Batchbereitstellungs-YAML-Schema.
Schlüssel BESCHREIBUNG nameDer Name der Bereitstellung endpoint_nameDer Name des Endpunkts, unter dem die Bereitstellung erstellt werden soll. modelDas Modell, das für die Batchbewertung verwendet werden soll. Im Beispiel wird ein Inline-Modell mit pathdefiniert. Mit dieser Definition können Modelldateien automatisch hochgeladen und mit automatisch generierten Werten für Name und Version registriert werden. Im Modellschema finden Sie weitere Optionen. Als bewährtes Verfahren für Produktionsszenarien sollten Sie das Modell separat erstellen und hier darauf verweisen. Um auf ein bestehendes Modell zu verweisen, verwenden Sie die Syntaxazureml:<model-name>:<model-version>.code_configuration.codeDas lokale Verzeichnis, das den gesamten Python-Quellcode für die Bewertung des Modells enthält. code_configuration.scoring_scriptDie Python-Datei im Verzeichnis code_configuration.code. Diese Datei muss über eine Funktion vom Typinit()und über eine Funktion vom Typrun()verfügen. Verwenden Sie dieinit()-Funktion für die aufwendige oder häufig angewandte Vorbereitungsschritte (z. B. wenn Sie das Modell in den Arbeitsspeicher laden).init()wird nur einmal zu Beginn des Prozesses aufgerufen. Verwenden Sierun(mini_batch), um die einzelnen Einträge zu bewerten. Der Wert vonmini_batchist eine Liste mit Dateipfaden. Die Funktionrun()sollte einen Pandas-Datenrahmen oder ein Array zurückgeben. Jedes zurückgegebene Element deutet auf eine erfolgreiche Ausführung eines Eingabeelements immini_batchhin. Weitere Informationen zum Erstellen eines Bewertungsskripts finden Sie unter Grundlegendes zum Bewertungsskript.environmentDie Umgebung zum Bewerten des Modells. Im Beispiel wird eine Inline-Umgebung mit conda_fileundimagedefiniert. Dieconda_file-Abhängigkeiten werden zusätzlich zumimageinstalliert. Die Umgebung wird automatisch mit einem automatisch generierten Namen und einer automatisch generierten Version registriert. Im Umgebungsschema finden Sie weitere Optionen. Als bewährtes Verfahren für Produktionsszenarien sollten Sie die Umgebung separat erstellen und hier referenzieren. Verwenden Sie die Syntaxazureml:<environment-name>:<environment-version>, um auf eine vorhandene Umgebung zu verweisen.computeDie Computeressource zum Ausführen der Batchbewertung. Im Beispiel wird der am Anfang erstellte batch-clusterverwendet, auf den mithilfe der Syntaxazureml:<compute-name>verwiesen wird.resources.instance_countDie Anzahl der Instanzen, die für jeden Batchbewertungsauftrag verwendet werden sollen. settings.max_concurrency_per_instanceDie maximale Anzahl von parallelen scoring_scriptLäufen pro Instanz.settings.mini_batch_sizeDie Anzahl der Dateien, die scoring_scriptin einemrun()-Aufruf verarbeiten kann.settings.output_actionGibt an, wie die Ausgabe in der Ausgabedatei organisiert werden soll append_rowführt alle vonrun()zurückgegebenen Ausgabeergebnisse in einer einzelnen Datei mit dem Namenoutput_file_namezusammen.summary_onlyführt die Ausgabeergebnisse nicht zusammen, sondern berechnet nurerror_threshold.settings.output_file_nameDer Name der Ausgabedatei der Batchbewertung für append_rowoutput_action.settings.retry_settings.max_retriesDie maximale Anzahl von Versuchen bei einer nicht erfolgreichen scoring_scriptrun().settings.retry_settings.timeoutDie Zeitüberschreitung in Sekunden für ein scoring_scriptrun()für das Erfassen eines Mini-Batches.settings.error_thresholdDie Anzahl von Eingabedatei-Bewertungsfehlern, die ignoriert werden sollen. Wenn die Fehlerzahl für die gesamte Eingabe diesen Wert übersteigt, wird der Batchbewertungsauftrag abgebrochen. Im Beispiel wird -1verwendet. Dadurch wird angegeben, dass eine beliebige Anzahl von Fehlern zulässig ist, ohne den Batchbewertungsauftrag abzubrechen.settings.logging_levelDie Ausführlichkeit des Protokolls. Mögliche Werte nach zunehmender Ausführlichkeit sind „WARNING“ (Warnung), „INFO“ (Information) und „DEBUG“ (Debuggen). settings.environment_variablesWörterbuch mit Namen-Wert-Paaren von Umgebungsvariablen, die für jeden Batch-Scoring-Auftrag festzulegen sind. Erstellen Sie die Bereitstellung:
Führen Sie den folgenden Code aus, um eine Batchbereitstellung unter dem Batchendpunkt zu erstellen und diese als Standardbereitstellung festzulegen.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultTipp
Der
--set-default-Parameter legt die neu erstellte Bereitstellung als Standardbereitstellung des Endpunkts fest. Insbesondere beim erstmaligen Erstellen einer Bereitstellung ist dies eine praktische Möglichkeit, um eine neue Standardbereitstellung des Endpunkts zu erstellen. Als bewährte Methode für Produktionsszenarien wird empfohlen, eine neue Bereitstellung zu erstellen, ohne sie als Standard festzulegen. Überprüfen Sie, ob die Bereitstellung wie erwartet funktioniert, und aktualisieren Sie die Standardbereitstellung später. Weitere Informationen zur Implementierung dieses Prozesses finden Sie im Abschnitt Bereitstellen eines neuen Modells.Überprüfen Sie die Batchendpunkt- und Bereitstellungsdetails.
Verwenden Sie
show, um die Details zu Endpunkt und Bereitstellung zu überprüfen. Führen Sie den folgenden Code aus, um eine Batchbereitstellung zu überprüfen:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAME

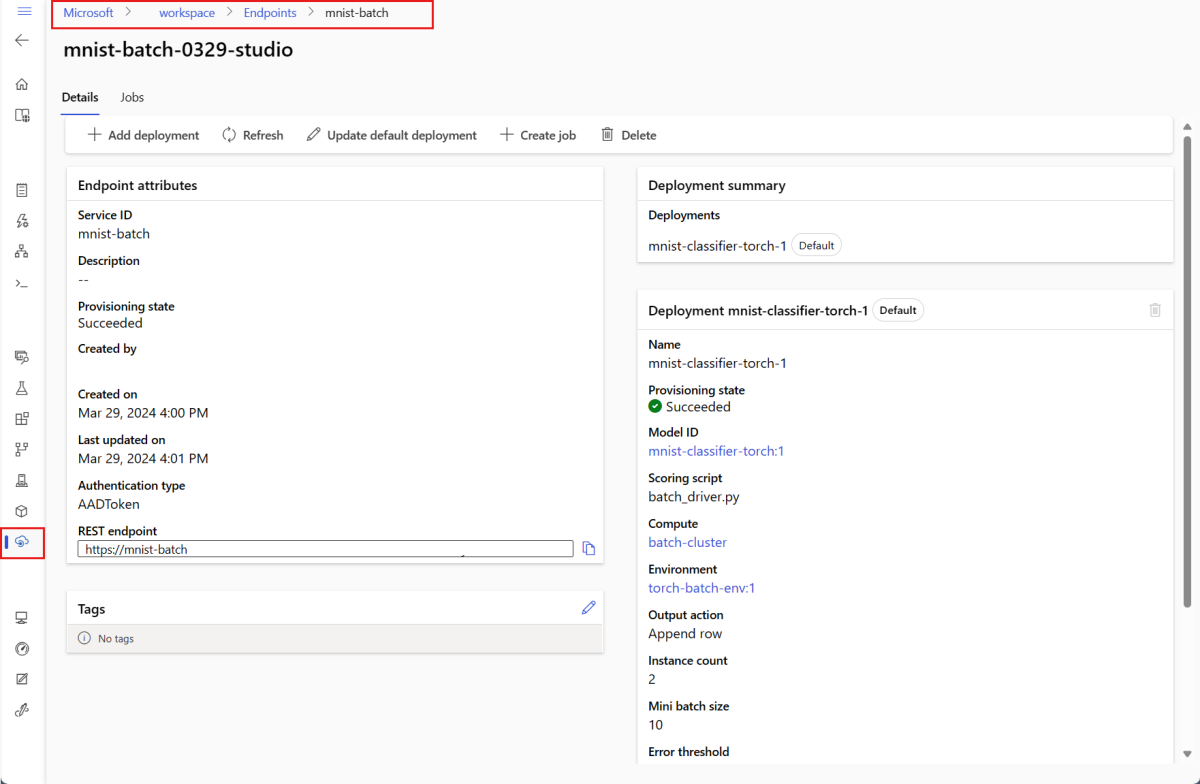
Ausführen von Batch-Endpunkten und Zugreifen auf Ergebnisse
Das Aufrufen eines Batchendpunkts löst einen Batchbewertungsauftrag aus. Von der Aufrufantwort wird der Auftrag name zurückgegeben, mit dem Sie den Fortschritt der Batchbewertung nachverfolgen können. Wenn Sie Modelle für die Bewertung auf Batchendpunkten ausführen, müssen Sie den Pfad zu den Eingabedaten angeben, damit die Endpunkte die Daten finden können, die Sie bewerten möchten. Das folgende Beispiel zeigt, wie Sie einen neuen Auftrag über eine Stichprobe von Daten der MNIST-Datenbank starten, die in einem Azure Storage-Konto gespeichert ist.
Sie können einen Batchendpunkt mit der Azure CLI, dem Azure Machine Learning-SDK oder REST-Endpunkten ausführen und aufrufen. Weitere Informationen zu diesen Optionen finden Sie unter Erstellen von Aufträgen und Eingabedaten für Batchendpunkte.
Hinweis
Wie funktioniert die Parallelisierung?
Batchbereitstellungen verteilen die Arbeit auf Dateiebene. Demnach generiert ein Ordner mit 100 Dateien mit Minibatches von 10 Dateien 10 Batches mit jeweils 10 Dateien. Beachten Sie, dass dies unabhängig von der Größe der involvierten Dateien erfolgt. Wenn Ihre Dateien zu groß sind, um in großen Minibatches verarbeitet zu werden, wird empfohlen, die Dateien entweder in kleinere Dateien aufzuteilen, um ein höheres Maß an Parallelität zu erzielen, oder die Anzahl Dateien pro Minibatch zu verringern. Derzeit können Batchbereitstellungen keine Scherung in der Größenverteilung einer Datei berücksichtigen.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Batchendpunkte unterstützen das Lesen von Dateien oder Ordnern, die sich an unterschiedlichen Standorten befinden. Weitere Informationen zu den unterstützten Typen und deren Angabe finden Sie unter Zugreifen auf Daten aus Batchendpunktaufträgen.
Überwachen des Ausführungsfortschritts des Batch-Auftrags
Bei Batchbewertungsaufträgen dauert es in der Regel etwas, bis sämtliche Eingaben verarbeitet wurden.
Der folgende Code überprüft den Auftragsstatus und gibt einen Link zu Azure Machine Learning Studio für weitere Details aus.
az ml job show -n $JOB_NAME --web

Überprüfen der Ergebnisse der Batchbewertung
Die Ausgaben des Auftrags werden im Cloudspeicher gespeichert, und zwar entweder im Standardblobspeicher des Arbeitsbereichs oder in dem von Ihnen angegebenen Speicher. Weitere Informationen zum Ändern der Standardwerte finden Sie unter Konfigurieren des Ausgabespeicherorts. Befolgen Sie nach Abschluss des Auftrags die nachstehenden Schritte, um die Bewertungsergebnisse in Azure Storage-Explorer anzuzeigen:
Führen Sie den folgenden Code aus, um den Batchbewertungsauftrag in Azure Machine Learning Studio zu öffnen. Der Studio-Link des Auftrags ist ebenfalls in der Antwort von
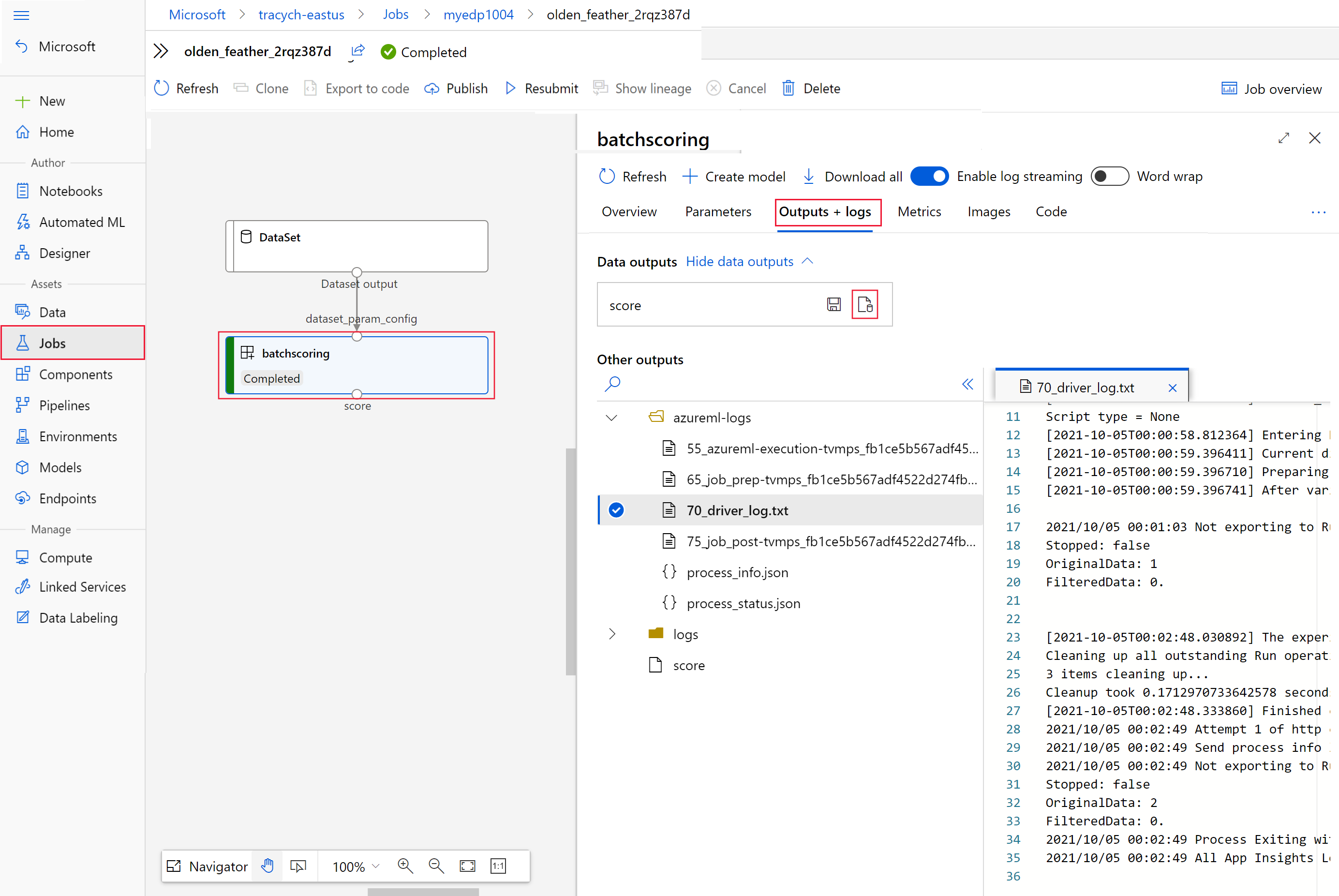
invokeals Wert voninteractionEndpoints.Studio.endpointenthalten.az ml job show -n $JOB_NAME --webWählen Sie im Auftragsgraph den Schritt
batchscoringaus.Wählen Sie die Registerkarte Ausgaben und Protokolle und dann Datenausgaben anzeigen aus.
Wählen Sie unter Datenausgabendas entsprechende Symbol aus, um Storage-Explorer zu öffnen.
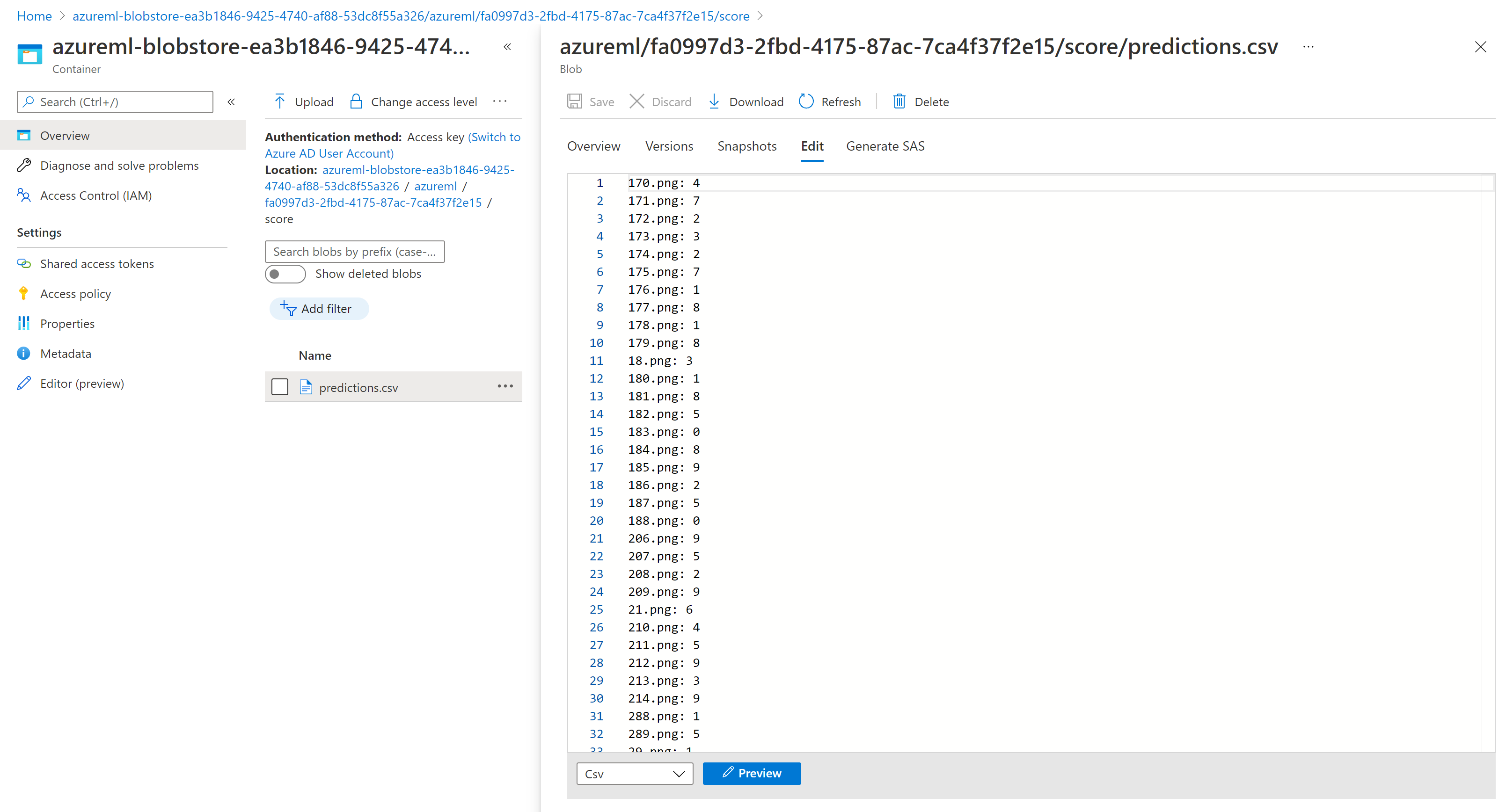
Die Bewertungsergebnisse in Storage-Explorer ähneln der folgenden Beispielseite:


Konfigurieren des Ausgabespeicherorts
Die Ergebnisse der Batchbewertung werden standardmäßig im Standardblobspeicher des Arbeitsbereichs in einem nach dem Auftrag benannten Ordner gespeichert. Bei dem Auftragsnamen handelt es sich um eine systemseitig generierte GUID. Beim Aufrufen eines Batchendpunkts können Sie konfigurieren, wo die Bewertungsausgaben gespeichert werden sollen.
Verwenden Sie output-path, um einen beliebigen Ordner in einem registrierten Azure Machine Learning-Datenspeicher zu konfigurieren. Die Syntax für --output-path ist dieselbe wie für --input, wenn Sie einen Ordner angeben, also azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Verwenden Sie --set output_file_name=<your-file-name>, um einen neuen Ausgabedateinamen zu konfigurieren.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Warnung
Der Ausgabespeicherort muss eindeutig sein. Ist die Ausgabedatei bereits vorhanden, tritt für den Batchbewertungsauftrag ein Fehler auf.
Wichtig
Im Gegensatz zu Eingaben können Ausgaben nur in Azure Machine Learning-Datenspeichern gespeichert werden, die unter Blob Storage-Konten ausgeführt werden.
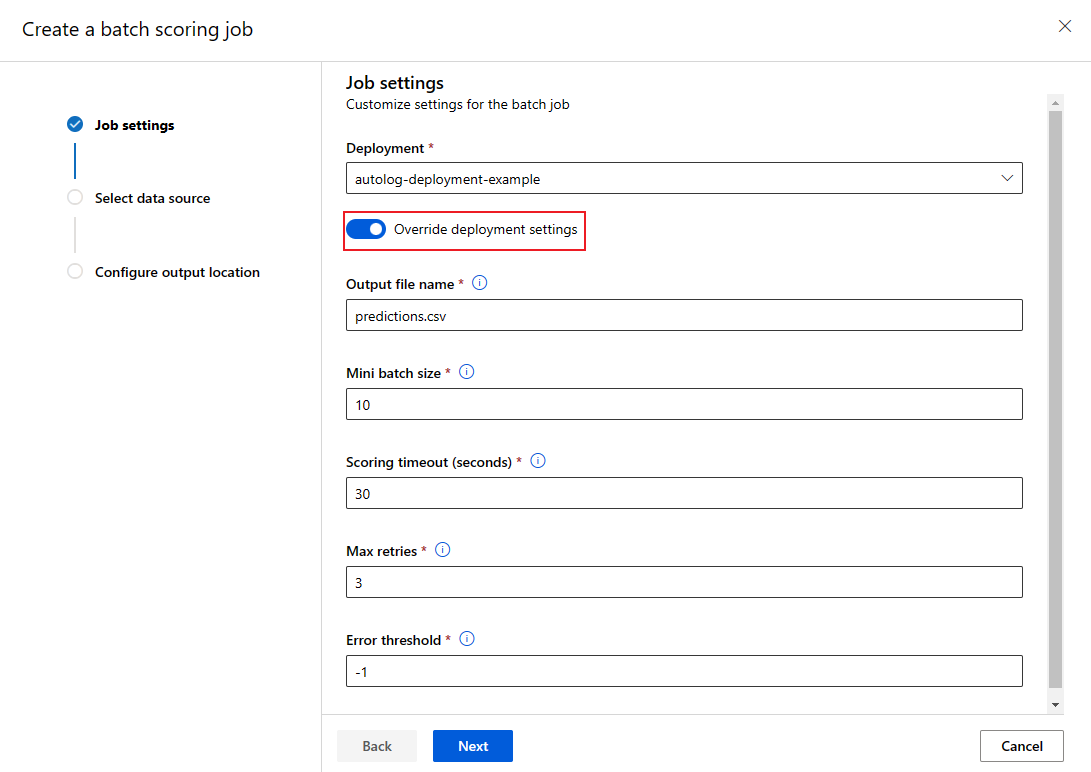
Außerkraftsetzen der Bereitstellungskonfiguration pro Auftrag
Wenn Sie einen Batchendpunkt aufrufen, können Sie einige Einstellungen außer Kraft setzen, um die Computeressourcen optimal zu nutzen und die Leistung zu verbessern. Die folgenden Einstellungen können auftragsbezogen konfiguriert werden:
- Instanzanzahl: Verwenden Sie diese Einstellung, um die Anzahl Instanzen zu überschreiben, die vom Computecluster anzufordern sind. Für eine größere Menge von Dateneingaben empfiehlt es sich beispielsweise, mehr Instanzen zu verwenden, um die End-to-End-Batchbewertung zu beschleunigen.
- Minibatchgröße: Verwenden Sie diese Einstellung, um die Anzahl Dateien zu überschreiben, die in jeden Minibatch eingeschlossen werden sollen. Die Anzahl der Minibatches wird durch die Gesamtanzahl der Eingabedateien und durch die Größe des Minibatches bestimmt. Bei einer kleineren Minibatchgröße werden mehr Minibatches generiert. Minibatches können zwar parallel ausgeführt werden, aber es kann zu zusätzlichem Zeitplanungs- und Aufrufaufwand kommen.
- Andere Einstellungen wie Max. Wiederholungen, Timeout und Fehlerschwellenwert können außer Kraft gesetzt werden. Diese Einstellungen können sich auf die End-to-End-Batchbewertungszeit für verschiedene Workloads auswirken.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Hinzufügen von Bereitstellungen zu einem Endpunkt
Sobald Sie über einen Batchendpunkt mit einer Bereitstellung verfügen, können Sie Ihr Modell weiter optimieren und neue Bereitstellungen hinzufügen. Batchendpunkte stellen weiterhin die Standardbereitstellung bereit, während Sie neue Modelle unter demselben Endpunkt entwickeln und bereitstellen. Bereitstellungen wirken sich nicht aufeinander aus.
In diesem Beispiel fügen Sie eine zweite Bereitstellung hinzu, die ein mit Keras und TensorFlow erstelltes Modell verwendet, um dasselbe MNIST-Problem zu lösen.
Hinzufügen einer zweiten Bereitstellung
Erstellen Sie eine Umgebung, in der Ihre Batchbereitstellung ausgeführt wird. Fügen Sie in die Umgebung alle Abhängigkeiten ein, die Ihr Code für die Ausführung benötigt. Sie müssen auch die Bibliothek
azureml-corehinzufügen, da sie erforderlich ist, damit Batchbereitstellungen funktionieren. Die folgende Umgebungsdefinition enthält die erforderlichen Bibliotheken, um ein Modell mit TensorFlow auszuführen.Die Umgebungsdefinition wird als anonyme Umgebung in die Bereitstellungsdefinition selbst aufgenommen.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlDie verwendete Conda-Datei sieht wie folgt aus:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Erstellen eines Bewertungsskripts für das Modell:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Neue Bereitstellungsdefinition erstellen
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvErstellen Sie die Bereitstellung:
Führen Sie den folgenden Code aus, um eine Batchbereitstellung unter dem Batchendpunkt zu erstellen und diese als Standardbereitstellung festzulegen.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMETipp
Der
--set-default-Parameter fehlt in diesem Fall. Als bewährte Methode für Produktionsszenarien wird empfohlen, eine neue Bereitstellung zu erstellen, ohne sie als Standard festzulegen. Überprüfen Sie sie zunächst, und aktualisieren Sie die Standardbereitstellung später.
Testen einer nicht standardmäßigen Batchbereitstellung
Um die neue nicht standardmäßige Bereitstellung zu testen, müssen Sie den Namen der auszuführenden Bereitstellung kennen.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Beachten Sie, dass für die Angabe der auszuführenden Bereitstellung --deployment-name verwendet wird. Mit diesem Parameter können Sie eine nicht standardmäßige Bereitstellung aufrufen (invoke), ohne die Standardbereitstellung des Batchendpunkts zu aktualisieren.
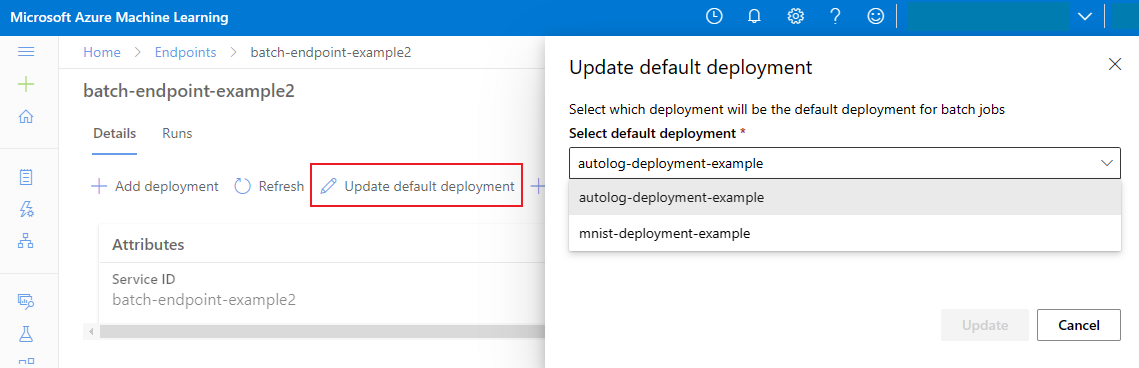
Aktualisieren der Standard-Batchbereitstellung
Sie können zwar eine bestimmte Bereitstellung innerhalb eines Endpunkts aufrufen, in der Regel rufen Sie jedoch den Endpunkt selbst auf und überlassen diesem die Entscheidung, welche Bereitstellung verwendet werden soll. Der Endpunkt verwendet dann die Standardbereitstellung. Sie können die Standardbereitstellung (und damit das Modell für die Bereitstellung) ändern, ohne Ihren Vertrag mit dem Benutzer oder der Benutzerin zu ändern, der bzw. die den Endpunkt aufruft. Verwenden Sie den folgenden Code, um die Standardbereitstellung zu ändern:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Löschen des Batchendpunkts und der Bereitstellung
Wenn Sie die alte Batchbereitstellung nicht weiter verwenden möchten, löschen Sie sie, indem Sie den folgenden Code ausführen. --yes wird verwendet, um den Löschvorgang zu bestätigen.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Führen Sie den folgenden Code aus, um den Batchendpunkt und alle seine zugrunde liegenden Bereitstellungen zu löschen. Batchbewertungsaufträge werden nicht gelöscht.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes