Tutorial: Nachfrageprognose mit automatisiertem maschinellem Lernen ohne Schreiben von Code in Azure Machine Learning Studio
Hier erfahren Sie, wie Sie unter Verwendung von automatisiertem maschinellem Lernen in Azure Machine Learning Studio ein Zeitreihen-Vorhersagemodell erstellen, ohne eine einzige Codezeile zu schreiben. Mit diesem Modell wird die Mietnachfrage für einen Bike-Sharing-Dienst vorhergesagt.
In diesem Tutorial schreiben Sie keinen Code. Sie verwenden die Studio-Benutzeroberfläche für das Trainieren. Dabei lernen Sie Folgendes:
- Erstellen und Laden eines Datasets
- Konfigurieren und Ausführen eines Experiments mit automatisiertem maschinellem Lernen
- Angeben der Vorhersageeinstellungen
- Untersuchen der Ergebnisse des Experiments
- Bereitstellen des besten Modells
Probieren Sie auch automatisiertes maschinelles Lernen für diese anderen Modelltypen aus:
- Ein Beispiel ohne Code für ein Klassifizierungsmodell finden Sie unter Tutorial: Erstellen eines Klassifizierungsmodells mit automatisiertem maschinellem Lernen in Azure Machine Learning.
- Ein erstes Codebeispiel eines Objekterkennungsmodells finden Sie im Tutorial: Trainieren eines Objekterkennungsmodells mit automatisierter ML und Python.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Siehe Erstellen von Arbeitsbereichsressourcen.
Laden Sie die Datendatei bike-no.csv herunter.
Anmelden bei Studio
In diesem Tutorial wird ein Experiment mit automatisiertem maschinellem Lernen in Azure Machine Learning Studio erstellt. Bei Azure Machine Learning Studio handelt es sich um eine konsolidierte Webumgebung mit ML-Tools für Data Science-Szenarien, die von Data Scientists jeglicher Qualifikation verwendet werden kann. Studio wird in Internet Explorer-Browsern nicht unterstützt.
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie Ihr Abonnement und den erstellten Arbeitsbereich aus.
Wählen Sie Erste Schritte aus.
Wählen Sie im linken Bereich im Abschnitt Ersteller die Option Automatisiertes maschinelles Lernen aus.
Wählen Sie + Neuer automatisierter ML-Auftrag aus.
Erstellen und Laden des Datasets
Laden Sie vor dem Konfigurieren Ihres Experiments Ihre Datendatei in Form eines Azure Machine Learning-Datasets in Ihren Arbeitsbereich hoch. Dadurch wird die ordnungsgemäße Formatierung der Daten für Ihr Experiment sichergestellt.
Wählen Sie im Formular Dataset auswählen in der Dropdownliste + Dataset erstellen die Option Aus lokalen Dateien aus.
Geben Sie Ihrem Dataset im Formular Grundlegende Informationen einen Namen, und geben Sie optional eine Beschreibung an. Der Datasettyp sollte standardmäßig auf Tabellarisch festgelegt sein, da für das automatisierte maschinelle Lernen in Azure Machine Learning Studio derzeit nur tabellarische Datasets unterstützt werden.
Wählen Sie links unten die Option Weiter aus.
Wählen Sie im Formular Datenspeicher- und Dateiauswahl den Standarddatenspeicher aus, der im Zuge der Erstellung Ihres Arbeitsbereichs automatisch eingerichtet wurde: workspaceblobstore (Azure Blob Storage) . Hierbei handelt es sich um den Speicherort, in den Sie Ihre Datendatei hochladen.
Wählen Sie im Upload-Dropdownmenü den Eintrag Dateien hochladen aus.
Wählen Sie auf Ihrem lokalen Computer die Datei bike-no.csv aus. Dies ist die Datei, die Sie als Voraussetzung heruntergeladen haben.
Wählen Sie Weiter aus.
Wenn der Upload abgeschlossen ist, wird das Formular „Einstellungen und Vorschau“ basierend auf dem Dateityp vorab aufgefüllt.
Überprüfen Sie, ob das Formular Einstellungen und Vorschau wie folgt ausgefüllt ist, und klicken Sie auf Weiter.
Feld BESCHREIBUNG Wert für das Tutorial Dateiformat Definiert das Layout und den Typ der in einer Datei gespeicherten Daten. Durch Trennzeichen getrennt Trennzeichen Mindestens ein Zeichen zum Angeben der Grenze zwischen separaten, unabhängigen Regionen in Nur-Text- oder anderen Datenströmen. Komma Codieren Gibt an, welche Bit-zu-Zeichen-Schematabelle verwendet werden soll, um Ihr Dataset zu lesen. UTF-8 Spaltenüberschriften Gibt an, wie die Header des Datasets, sofern vorhanden, behandelt werden. Nur erste Datei enthält Header Zeilen überspringen Gibt an, wie viele Zeilen im Dataset übersprungen werden. Keine Das Formular Schema ermöglicht eine weitere Konfiguration der Daten für dieses Experiment.
Wählen Sie für dieses Beispiel aus, dass die Spalten casual und registered ignoriert werden sollen. Diese Spalten werden nicht eingeschlossen, da es sich bei ihnen um eine Aufschlüsselung der Spalte cnt handelt.
Übernehmen Sie für dieses Beispiel außerdem die Standardwerte für Eigenschaften und Typ.
Wählen Sie Weiter aus.
Überprüfen Sie im Formular Details bestätigen die zuvor in die Formulare Grundlegende Infos und Einstellungen und Vorschau eingetragenen Informationen.
Wählen Sie Erstellen aus, um die Erstellung Ihres Datasets abzuschließen.
Wählen Sie Ihr Dataset aus, sobald es in der Liste angezeigt wird.
Wählen Sie Weiter aus.
Auftrag konfigurieren
Nachdem Sie Ihre Daten geladen und konfiguriert haben, müssen Sie das Remotecomputeziel einrichten und auswählen, für welche Spalte in Ihren Daten Vorhersagen erstellt werden sollen.
- Füllen Sie das Formular Auftrag konfigurieren wie folgt aus:
Geben Sie einen Experimentnamen ein:
automl-bikeshareWählen Sie cnt als Zielspalte aus. (Hierbei handelt es sich um die Spalte, für die Vorhersagen erstellt werden sollen.) Diese Spalte gibt die Gesamtanzahl von Bike-Sharing-Vermietungen an.
Wählen Sie Computecluster als Computetyp aus.
Wählen Sie +Neu aus, um Ihr Computeziel zu konfigurieren. Von automatisiertem maschinellem Lernen wird nur Azure Machine Learning-Compute unterstützt.
Füllen Sie das Formular VM auswählen aus, um Ihre Compute-Instanz einzurichten.
Feld BESCHREIBUNG Wert für das Tutorial Stufe der VM Wählen Sie aus, welche Priorität ihr Experiment aufweisen soll. Dediziert Typ des virtuellen Computers Wählen Sie den VM-Typ für Ihre Compute-Umgebung aus. CPU (Zentralprozessor) Größe des virtuellen Computers Wählen Sie die Größe für Ihren Computes aus. Eine Liste der empfohlenen Größen wird auf der Grundlage Ihrer Daten und des Experimenttyps bereitgestellt. Standard_DS12_V2 Wählen Sie Weiter aus, um das Formular Einstellungen konfigurieren auszufüllen.
Feld BESCHREIBUNG Wert für das Tutorial Computename Ein eindeutiger Name, der Ihren Computekontext identifiziert. bike-compute Min/Max nodes (Min./Max. Knoten) Um ein Datenprofil zu erstellen, müssen Sie mindestens einen Knoten angeben. Min. Knoten: 1
Max. Knoten: 6Leerlauf in Sekunden vor dem Herunterskalieren Leerlaufzeit vor dem automatischen Herunterskalieren des Clusters auf die minimale Knotenanzahl 120 (Standardwert) Erweiterte Einstellungen Einstellungen zum Konfigurieren und Autorisieren eines virtuellen Netzwerks für Ihr Experiment Keine Wählen Sie Erstellen aus, um das Computeziel abzurufen.
Dieser Vorgang nimmt einige Minuten in Anspruch.
Wählen Sie nach der Erstellung in der Dropdownliste Ihr neues Computeziel aus.
Wählen Sie Weiter aus.
Auswählen von Vorhersageeinstellungen
Schließen Sie die Einrichtung Ihres Experiments mit automatisiertem maschinellem Lernen ab, indem Sie den ML-Aufgabentyp und die Konfigurationseinstellungen angeben.
Wählen Sie im Formular Vorhersagetask auswählen den ML-Aufgabentyp Time series forecasting (Zeitreihenvorhersage) aus.
Wählen Sie date als Zeitspalte aus, und lassen Sie Time series identifiers (Zeitreihenbezeichner) leer.
Die Häufigkeit gibt an, wie oft Ihre Verlaufsdaten gesammelt werden. Lassen Sie Automatische Erkennung ausgewählt.
Forecast horizon (Vorhersagehorizont) ist die Zeitspanne für die Zukunftsprognose. Deaktivieren Sie Automatische Erkennung und geben Sie „14“ in das Feld ein.
Klicken Sie auf Zusätzliche Konfigurationseinstellungen anzeigen, und füllen Sie die Felder wie folgt aus. Mit diesen Einstellungen können Sie den Trainingsauftrag besser steuern und Einstellungen für die Vorhersage angeben. Andernfalls werden die Standardwerte auf Basis der Experimentauswahl und -daten angewendet.
Zusätzliche Konfigurationen BESCHREIBUNG Wert für das Tutorial Primary metric (Primäre Metrik) Auswertungsmetrik, die zur Messung des Machine Learning-Algorithmus verwendet wird. Wurzel der mittleren Fehlerquadratsumme (RMSE), normalisiert Explain best model (Bestes Modell erläutern) Zeigt automatisch die Erklärbarkeit für das beste Modell an, das durch automatisiertes ML erstellt wurde. Aktivieren Blockierte Algorithmen Algorithmen, die Sie aus den Trainingsauftrag ausschließen möchten. „Extreme Random Trees“ (Extreme Zufallsstrukturen) Zusätzliche Vorhersageeinstellungen Diese Einstellungen tragen dazu bei, die Genauigkeit des Modells zu verbessern.
Zielverzögerungen für Prognose: Angabe, wie weit die Verzögerungen für die Zielvariable zurückreichen sollen
Zielgröße für rollierendes Zeitfenster: gibt die Größe des rollierenden Zeitfensters an, in dem Features wie max, min und sum generiert werden sollen.
Zielverzögerungen für Prognose: Keine
Zielgröße für rollierendes Zeitfenster: KeineBeendigungskriterium Wenn ein Kriterium erfüllt ist, wird der Trainingsauftrag angehalten. Trainingsauftragszeit (Stunden): 3
Metrischer Bewertungsschwellenwert: keinerParallelität Die maximale Anzahl paralleler Iterationen pro Iteration Maximale Anzahl gleichzeitiger Iterationen: 6 Wählen Sie Speichern aus.
Wählen Sie Weiter aus.
Wählen Sie im Formular [Optional] Validieren und Testen
- „k-fache Kreuzvalidierung“ als Validierungstyp aus.
- Wählen Sie 5 als Anzahl der Kreuzvalidierungen aus.
Ausführen des Experiments
Wählen Sie Fertig stellen aus, um Ihr Experiment auszuführen. Im daraufhin geöffneten Bildschirm Auftragsdetails wird oben neben der Auftragsnummer der Auftragsstatus angezeigt. Dieser Status wird während des Experimentausführung entsprechend aktualisiert. Außerdem werden in der rechten oberen Ecke des Studios Benachrichtigungen angezeigt, die Sie über den Status Ihres Experiments informieren.
Wichtig
Die Vorbereitung des Auftragexperiments nimmt 10 –15 Minuten in Anspruch.
Sobald es ausgeführt wird, dauert jede Iteration mindestens zwei bis drei Minuten.
In einer Produktionsumgebung würden Sie sich an dieser Stelle wahrscheinlich anderen Dingen zuwenden, da der Prozess eine Weile dauert. Während Sie warten, können Sie sich schon mal mit den getesteten Algorithmen auf der Registerkarte Modelle vertraut machen.
Untersuchen von Modellen
Navigieren Sie zur Registerkarte Modelle, um die getesteten Algorithmen (Modelle) anzuzeigen. Standardmäßig werden die Modelle nach ihrem Abschluss nach der Metrikbewertung sortiert. In diesem Tutorial befindet sich das Modell, das für die ausgewählte Metrik Wurzel der mittleren Fehlerquadratsumme (RMSE), normalisiert die höchste Bewertung erhält, ganz oben auf der Liste.
Während Sie auf den Abschluss aller Experimentmodelle warten, können Sie den Algorithmusnamen eines abgeschlossenen Modells auswählen und sich die zugehörigen Leistungsdetails ansehen.
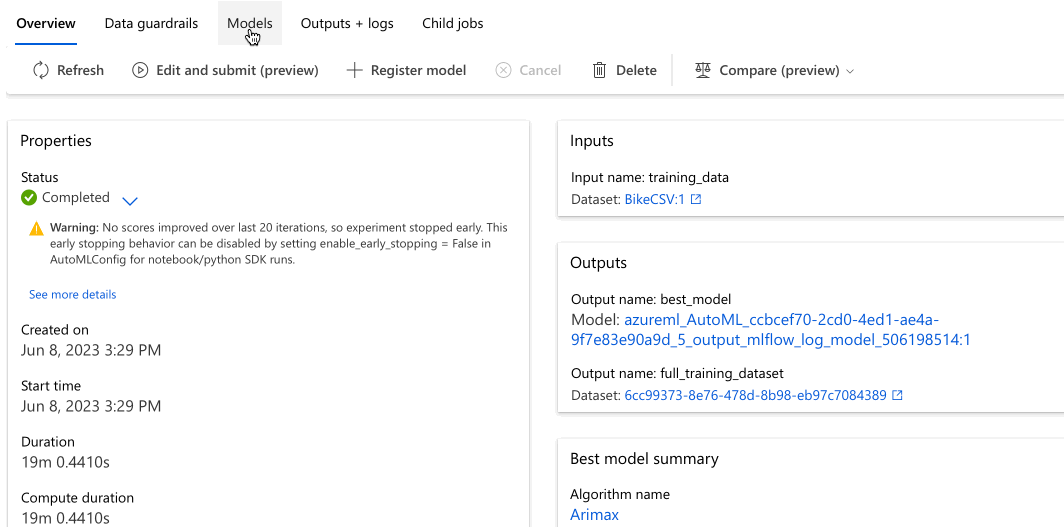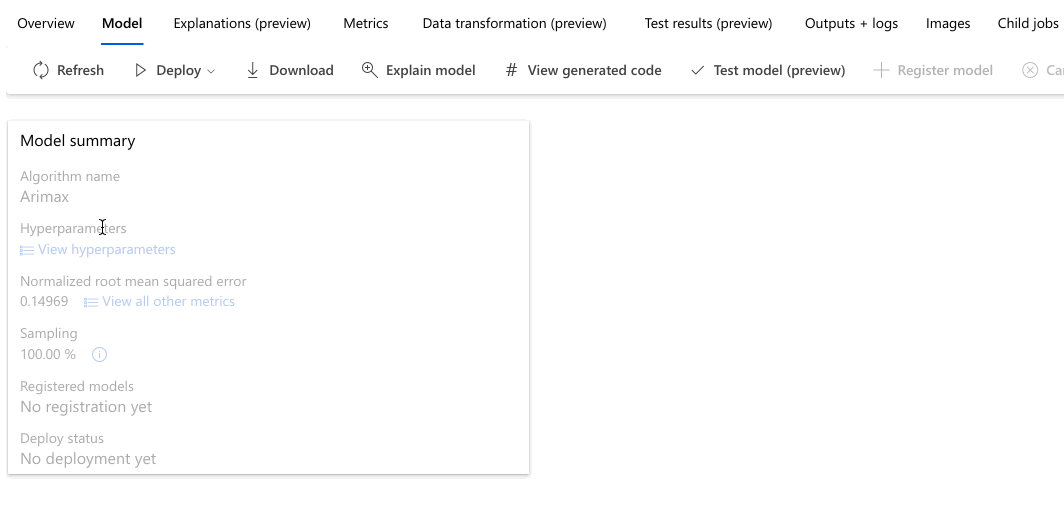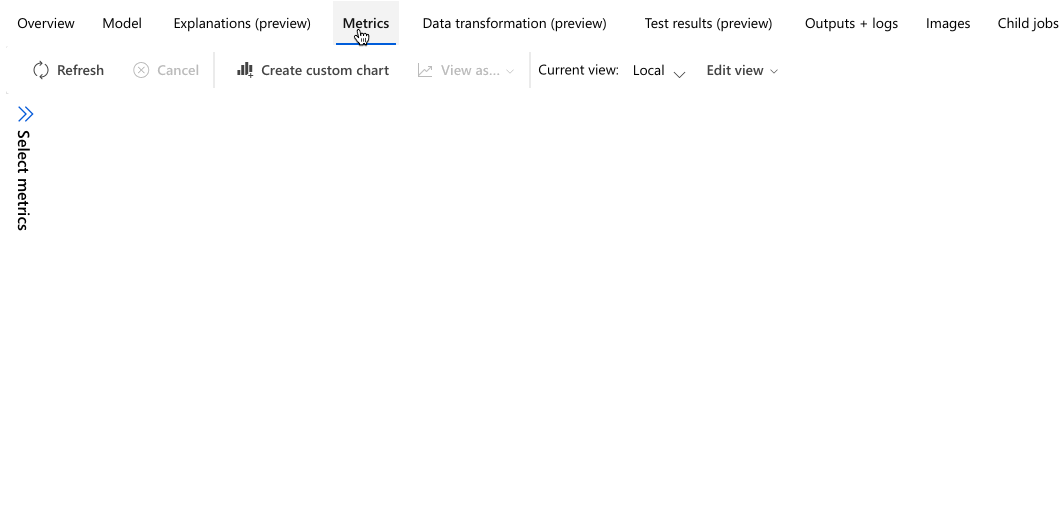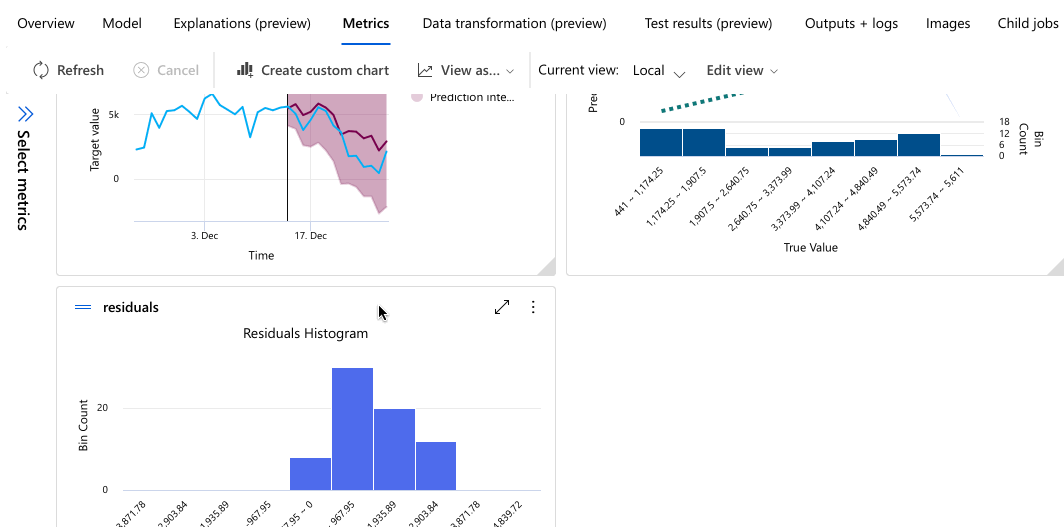
Das folgende Beispiel navigiert, um ein Modell aus der Liste der Modelle auszuwählen, die der Auftrag erstellt hat. Anschließend wählen Sie die Registerkarten Übersicht und Metriken aus, um die Eigenschaften, Metriken und Leistungsdiagramme des ausgewählten Modells anzuzeigen.
Bereitstellen des Modells
Durch die Verwendung von automatisiertem maschinellen Lernen im Azure Machine Learning-Studio können Sie das beste Modell in wenigen Schritten als Webdienst bereitstellen. Bei der Bereitstellung handelt es sich um die Integration des Modells, sodass neue Daten vorhergesagt und potenzielle Verkaufschancen identifiziert werden können.
Bei diesem Experiment bedeutet die Bereitstellung für einen Webdienst, dass das Bike-Sharing-Unternehmen nun über eine iterative und skalierbare Webanwendung für die Vorhersage der Mietnachfrage im Bike-Sharing-Bereich verfügt.
Navigieren Sie nach Abschluss des Auftrag zurück zur Seite mit dem übergeordneten Auftrag, indem Sie oben auf dem Bildschirm Auftrag 1 auswählen.
Im Abschnitt Zusammenfassung des besten Modells wird basierend auf der Metrik Wurzel der mittleren Fehlerquadratsumme (RMSE), normalisiert das beste Modell im Kontext dieses Experiments ausgewählt.
Wir stellen dieses Modell bereit. Die Bereitstellung dauert jedoch etwa 20 Minuten. Der Bereitstellungsprozess umfasst mehrere Schritte, einschließlich der Registrierung des Modells, der Erstellung von Ressourcen und der Konfiguration dieser Ressourcen für den Webdienst.
Wählen Sie das beste Modell aus, um die modellspezifische Seite zu öffnen.
Wählen Sie die Schaltfläche Bereitstellen aus, die sich im oberen linken Bereich des Bildschirms befindet.
Füllen Sie den Bereich Modell bereitstellen wie folgt aus:
Feld Wert „Deployment name“ (Bereitstellungsname) bikeshare-deploy „Deployment description“ (Bereitstellungsbeschreibung) bike share demand deployment Computetyp Azure-Compute-Instanz (ACI) auswählen Authentifizierung aktivieren Deaktivieren Sie diese Option. Use custom deployment assets (Benutzerdefinierte Bereitstellungsressourcen verwenden) Deaktivieren Sie diese Option. Dies ermöglicht die automatische Erstellung der Standardtreiberdatei (Bewertungsskript) und der Umgebungsdatei. In diesem Beispiel werden die im Menü Erweitert angegebenen Standardwerte verwendet.
Klicken Sie auf Bereitstellen.
Am oberen Rand des Bildschirms Auftrag wird eine grüne Erfolgsmeldung mit dem Hinweis angezeigt, dass die Bereitstellung erfolgreich gestartet wurde. Der Status der Bereitstellung wird unter Bereitstellungsstatus im Bereich Modellzusammenfassung angezeigt.
Nach erfolgreichem Abschluss der Bereitstellung verfügen Sie über einen funktionierenden Webdienst zum Generieren von Vorhersagen.
Fahren Sie mit den nächsten Schritten fort, um weitere Informationen zur Verwendung Ihres neuen Webdiensts zu erhalten, und testen Sie Ihre Vorhersagen mithilfe der integrierten Azure Machine Learning-Unterstützung von Power BI.
Bereinigen von Ressourcen
Bereitstellungsdateien sind größer als Daten- und Experimentdateien, sodass ihre Speicherung teurer ist. Löschen Sie nur die Bereitstellungsdateien, um die Kosten für Ihr Konto zu minimieren, oder wenn Sie den Arbeitsbereich und die Experimentdateien beibehalten möchten. Löschen Sie andernfalls die gesamte Ressourcengruppe, wenn Sie keine der Dateien verwenden möchten.
Löschen der Bereitstellungsinstanz
Löschen Sie nur die Bereitstellungsinstanz aus dem Azure Machine Learning-Studio, wenn Sie die Ressourcengruppe und den Arbeitsbereich für andere Tutorials und Untersuchungen beibehalten möchten.
Wechseln Sie zum Azure Machine Learning-Studio. Navigieren Sie zu Ihrem Arbeitsbereich, und wählen Sie links unter dem Bereich Ressourcen die Option Endpunkte aus.
Wählen Sie die zu löschende Bereitstellung aus, und klicken Sie auf Delete (Löschen).
Wählen Sie Proceed (Fortfahren) aus.
Löschen der Ressourcengruppe
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Geben Sie im Azure-Portal den Suchbegriff Ressourcengruppen in das Suchfeld ein, und wählen Sie in den Ergebnissen die entsprechende Option aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie auf der Seite Übersicht die Option Ressourcengruppe löschen aus.
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Nächste Schritte
In diesem Tutorial haben Sie automatisiertes ML in Azure Machine Learning Studio verwendet, um ein Zeitreihenvorhersagemodell zur Vorhersage der Mietnachfrage im Bike-Sharing-Bereich zu erstellen und bereitzustellen.
- Weitere Informationen zu automatisiertem Machine Learning.
- Weitere Informationen zu Klassifizierungsmetriken und Diagrammen finden Sie im Artikel Grundlegendes zu den Ergebnissen des automatisierten maschinellen Lernens.
- Weitere Informationen finden Sie unter Häufig gestellte Fragen zu Vorhersagen in AutoML.
Hinweis
Dieses Bike-Sharing-Dataset wurde für das Tutorial angepasst. Dieses Dataset wurde im Rahmen eines Kaggle-Wettbewerbs zur Verfügung gestellt und war ursprünglich über Capital Bikeshare verfügbar. Es ist auch in der Machine Learning-Datenbank von UCI enthalten.
Quelle: Fanaee-T, Hadi und Gama, Joao, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): Seiten 1–15, Springer Berlin Heidelberg.