Tutorial: Training eines Modells in Azure Machine Learning
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Erfahren Sie, wie ein Data Scientist Azure Machine Learning verwendet, um ein Modell zu trainieren. In diesem Beispiel wird anhand eines Kreditkartendatasets veranschaulicht, wie Azure Machine Learning für ein Klassifizierungsproblem verwendet wird. Das Ziel besteht darin, vorherzusagen, ob die Kreditkartenzahlung eines Kunden mit hoher Wahrscheinlichkeit ausfällt. Das Trainingsskript bereitet die Daten auf. Anschließend trainiert und registriert das Skript ein Modell.
Dieses Tutorial führt Sie durch die Schritte zum Übermitteln eines cloudbasierten Trainingsauftrags (Befehlsauftrag).
- Abrufen eines Handles für Ihren Azure Machine Learning-Arbeitsbereich
- Erstellen Ihrer Computeressource und der Auftragsumgebung
- Erstellen Ihres Trainingsskripts
- Erstellen und Ausführen Ihres Befehlsauftrags zum Ausführen des Trainingsskripts in der Computeressource
- Anzeigen der Ausgabe Ihres Trainingsskripts
- Bereitstellen des neu trainierten Modells als Endpunkt
- Aufrufen des Azure Machine Learning-Endpunkts für Rückschlüsse
Wenn Sie mehr darüber erfahren möchten, wie Sie Ihre Daten in Azure laden können, sehen Sie sich das Tutorial: Hochladen, Zugreifen und Untersuchen Ihrer Daten in Azure Machine Learning an.
Dieses Video zeigt Ihnen, wie Sie mit Azure Machine Learning Studio loslegen, um den Schritten des Tutorials folgen zu können. Das Video zeigt, wie Sie ein Notebook erstellen, eine Computeinstanz erstellen und das Notebook klonen. Die Schritte sind in den folgenden Abschnitten beschrieben.
Voraussetzungen
-
Für die Verwendung von Azure Machine Learning benötigen Sie einen Arbeitsbereich. Wenn Sie noch keinen haben, schließen Sie Erstellen von Ressourcen, die Sie für die ersten Schritte benötigen ab, um einen Arbeitsbereich zu erstellen, und mehr über dessen Verwendung zu erfahren.
Wichtig
Wenn Ihr Azure Machine Learning-Arbeitsbereich mit einem verwalteten virtuellen Netzwerk konfiguriert ist, müssen Sie möglicherweise Ausgangsregeln hinzufügen, um den Zugriff auf die öffentlichen Python-Paketrepositorys zu ermöglichen. Weitere Informationen finden Sie unter Szenario: Zugreifen auf öffentliche Machine Learning-Pakete.
-
Melden Sie sich bei Studio an, und wählen Sie Ihren Arbeitsbereich aus, falls dieser noch nicht geöffnet ist.
-
Öffnen oder erstellen Sie ein neues Notebook in Ihrem Arbeitsbereich:
- Wenn Sie Code kopieren und in Zellen einfügen möchten, erstellen Sie ein neues Notebook.
- Alternativ öffnen Sie im Abschnitt Beispiele von Studio die Datei tutorials/get-started-notebooks/train-model.ipynb. Wählen Sie dann Klonen aus, um das Notebook zu Ihren Dateien hinzuzufügen. Informationen zum Suchen nach Beispielnotebooks finden Sie unter Lernen anhand von Beispiel-Notebooks.
Festlegen des Kernels und Öffnen in Visual Studio Code (VS Code)
Erstellen Sie auf der oberen Leiste über Ihrem geöffneten Notizbuch eine Compute-Instanz, falls Sie noch keine besitzen.

Wenn die Compute-Instanz beendet wurde, wählen Sie Compute starten aus, und warten Sie, bis sie ausgeführt wird.

Warten Sie, bis die Compute-Instanz ausgeführt wird. Vergewissern Sie sich dann, dass sich rechts oben der Kernel
Python 3.10 - SDK v2befindet. Falls nicht, verwenden Sie die Dropdownliste, um diesen Kernel auszuwählen.
Falls dieser Kernel nicht angezeigt wird, überprüfen Sie, ob Ihre Compute-Instanz ausgeführt wird. Falls ja, wählen Sie rechts oben im Notebook die Schaltfläche Aktualisieren aus.
Wenn Sie ein Banner mit dem Hinweis sehen, dass Sie authentifiziert werden müssen, wählen Sie Authentifizieren aus.
Sie können das Notebook hier ausführen oder es in VS Code öffnen, um eine vollständig integrierte Entwicklungsumgebung (Integrated Development Environment, IDE) mit der Leistungsfähigkeit von Azure Machine Learning-Ressourcen nutzen zu können. Wählen Sie In VS Code öffnen und dann unter „In VS Code bearbeiten“ entweder die Option „Web“ oder „Desktop“ aus. Wenn Sie den VS Code-Editor auf diese Weise starten, wird er an Ihre Compute-Instanz, den Kernel und das Dateisystem des Arbeitsbereichs angefügt.





Wichtig
Der Rest dieses Tutorials enthält Zellen des Tutorial-Notebooks. Kopieren Sie diese, und fügen Sie sie in Ihr neues Notebook ein, oder wechseln Sie jetzt zum Notebook, wenn Sie es geklont haben.
Verwenden eines Befehlsauftrags zum Trainieren eines Modells in Azure Machine Learning
Zum Trainieren eines Modells müssen Sie einen Auftrag übermitteln. Azure Machine Learning bietet verschiedene Typen von Aufträgen zum Trainieren von Modellen. Benutzer können ihre Trainingsmethode basierend auf der Komplexität des Modells, der Datengröße und den Anforderungen an die Trainingsgeschwindigkeit auswählen. In diesem Tutorial erfahren Sie, wie Sie einen Befehlsauftrag übermitteln, um ein Trainingsskript auszuführen.
Ein Befehlsauftrag ist eine Funktion, mit deren Hilfe Sie ein benutzerdefiniertes Trainingsskript zum Trainieren Ihres Modells übermitteln können. Dieser Auftrag kann auch als benutzerdefinierter Trainingsauftrag definiert werden. Ein Befehlsauftrag in Azure Machine Learning ist ein Auftragstyp, der ein Skript oder einen Befehl in einer angegebenen Umgebung ausführt. Sie können Befehlsaufträge verwenden, um Modelle zu trainieren sowie um Daten oder anderen benutzerdefinierten Code zu verarbeiten, den Sie in der Cloud ausführen möchten.
Dieses Tutorial konzentriert sich auf die Verwendung eines Befehlsauftrags zum Erstellen eines benutzerdefinierten Trainingsauftrags, der zum Trainieren eines Modells verwendet wird. Für jeden benutzerdefinierten Trainingsauftrag werden folgende Elemente benötigt:
- Umgebung
- data
- Befehlsauftrag
- Trainingsskript
In diesem Tutorial werden diese Elemente für das folgende Beispiel bereitgestellt: Erstellen eines Klassifizierers, um vorherzusagen, bei welchen Kunden Kreditkartenzahlungen mit hoher Wahrscheinlichkeit ausfallen.
Erstellen eines Handles für den Arbeitsbereich
Bevor Sie sich genauer mit dem Code befassen, benötigen Sie eine Möglichkeit, um auf Ihren Arbeitsbereich zu verweisen. Erstellen Sie ml_client als Handle für den Arbeitsbereich. Verwenden Sie dann ml_client zum Verwalten von Ressourcen und Aufträgen.
Geben Sie in der nächsten Zelle Ihre Abonnement-ID, den Namen der Ressourcengruppe und den Namen des Arbeitsbereichs ein. So finden Sie diese Werte:
- Wählen Sie auf der oben rechts angezeigten Azure Machine Learning Studio-Symbolleiste den Namen Ihres Arbeitsbereichs aus.
- Kopieren Sie den Wert für Arbeitsbereich, Ressourcengruppe und Abonnement-ID in den Code. Sie müssen einen Wert kopieren, den Bereich schließen und einfügen und den Vorgang dann für den nächsten wiederholen.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Hinweis
Beim Erstellen von MLClient wird keine Verbindung mit dem Arbeitsbereich hergestellt. Die Clientinitialisierung erfolgt verzögert. Es wird gewartet, bis das erste Mal ein Aufruf erforderlich ist. Dies passiert in der nächsten Codezelle.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Erstellen der Auftragsumgebung
Um Ihren Azure Machine Learning-Auftrag auf Ihrer Computeressource auszuführen, benötigen Sie eine Umgebung. Eine Umgebung listet die Softwareruntime und Bibliotheken auf, die Sie in der Computeressource installieren möchten, in der das Training durchgeführt wird. Sie ist vergleichbar mit der Python-Umgebung auf Ihrem lokalen Computer. Weitere Informationen finden Sie unter Was sind Azure Machine Learning-Umgebungen?.
Azure Machine Learning bietet viele kuratierte oder vordefinierte Umgebungen, die für allgemeine Trainings- und Rückschlussszenarien nützlich sind.
In diesem Beispiel erstellen Sie mithilfe einer Conda-YAML-Datei eine Conda-Umgebung für Ihre Aufträge.
Zunächst erstellen Sie ein Verzeichnis, in dem die Datei gespeichert wird.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
In der nächsten Zelle wird die Conda-Datei mithilfe eines IPython-Magic-Befehls in das von Ihnen erstellte Verzeichnis geschrieben.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
Die Spezifikation enthält einige übliche Pakete, die Sie in Ihrem Auftrag verwenden (zum Beispiel numpy und pip).
Verweisen Sie auf diese YAML-Datei, um diese benutzerdefinierte Umgebung in Ihrem Arbeitsbereich zu erstellen und zu registrieren:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Konfigurieren eines Trainingsauftrags mithilfe der Befehlsfunktion
Sie erstellen einen Azure Machine Learning-Befehlsauftrag, um ein Modell für die Kreditausfallvorhersage zu trainieren. Der Befehlsauftrag wird verwendet, um ein Trainingsskript in einer angegebenen Umgebung und auf einer angegebenen Computeressource auszuführen. Sie haben bereits die Umgebung und die Computeressource erstellt. Erstellen Sie als Nächstes das Trainingsskript. In diesem Fall trainieren Sie das Dataset, um mithilfe des GradientBoostingClassifier-Modells einen Klassifizierer zu erstellen.
Das Trainingsskript übernimmt die Datenaufbereitung, das Training und die Registrierung des trainierten Modells. Die train_test_split-Methode unterteilt das Dataset in Test- und Trainingsdaten. In diesem Tutorial erstellen Sie ein Python-Trainingsskript.
Befehlsaufträge können über die Befehlszeilenschnittstelle, das Python SDK oder die Studio-Benutzeroberfläche ausgeführt werden. Verwenden Sie in diesem Tutorial das Azure Machine Learning Python SDK v2, um den Befehlsauftrag zu erstellen und auszuführen.
Erstellen des Trainingsskripts
Erstellen Sie zunächst das Trainingsskript: die Python-Datei main.py. Erstellen Sie zunächst einen Quellordner für das Skript:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Dieses Skript bereitet die Daten auf und unterteilt sie in Test- und Trainingsdaten. Anschließend werden die Daten verwendet, um ein strukturbasiertes Modell zu trainieren und das Ausgabemodell zurückzugeben.
MLFlow wird verwendet, um die Parameter und Metriken während der Auftragsausführung zu protokollieren. Mit dem MLFlow-Paket können Sie Metriken und Ergebnisse des Trainings jedes Azure-Modells nachverfolgen. Verwenden Sie MLFlow, um das beste Modell für Ihre Daten zu erhalten. Sehen Sie sich dann die Metriken des Modells in Azure Studio an. Weitere Informationen finden Sie unter MLflow und Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
In diesem Skript wird die Modelldatei gespeichert und im Arbeitsbereich registriert, nachdem das Modell trainiert wurde. Das Registrieren Ihres Modells ermöglicht es Ihnen, Ihre Modelle in der Azure-Cloud in Ihrem Arbeitsbereich zu speichern und zu versionieren. Nachdem Sie ein Modell registriert haben, finden Sie alle anderen registrierten Modelle in Azure Studio am selben Ort. Dieser wird als Modellregistrierung bezeichnet. Mithilfe der Modellregistrierung können Sie Ihre trainierten Modelle organisieren und nachverfolgen.
Konfigurieren des Befehls
Da Sie nun über ein Skript verfügen, das den gewünschten Klassifizierungsauftrag ausführen kann, verwenden Sie den universellen Befehl, der Befehlszeilenaktionen ausführen kann. Diese Befehlszeilenaktion kann direkt Systembefehle aufrufen oder dazu ein Skript ausführen.
Erstellen Sie Eingabevariablen, um die Eingabedaten, das Aufteilungsverhältnis, die Lernrate und den Namen des registrierten Modells anzugeben. Für das Befehlsskript gilt Folgendes:
- Es verwendet die zuvor erstellte Umgebung. Verwenden Sie die
@latest-Notation, um die aktuelle Version der Umgebung anzugeben, wenn der Befehl ausgeführt wird. - Es konfiguriert die eigentliche Befehlszeilenaktion (in diesem Fall:
python main.py). Sie können mithilfe der${{ ... }}-Notation auf die Ein- und Ausgaben im Befehl zugreifen. - Da keine Computeressource angegeben wurde, wird das Skript in einem serverlosen Computecluster ausgeführt, der automatisch erstellt wird.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Übermitteln des Auftrags
Übermitteln Sie den in Azure Machine Learning Studio auszuführenden Auftrag. Verwenden Sie diesmal create_or_update für ml_client. „ml_client“ ist eine Clientklasse, mit der Sie mithilfe von Python eine Verbindung mit Ihrem Azure-Abonnement herstellen und mit den Azure Machine Learning-Diensten interagieren können. „ml_client“ ermöglicht es Ihnen, Ihre Aufträge mithilfe von Python zu übermitteln.
ml_client.create_or_update(job)
Anzeigen der Auftragsausgabe und Warten auf den Auftragsabschluss
Wählen Sie den Link in der Ausgabe der vorherigen Zelle aus, um den Auftrag in Azure Machine Learning Studio anzuzeigen. Die Ausgabe dieses Auftrags sieht in Azure Machine Learning Studio wie folgt aus. Sehen Sie sich die Registerkarten für verschiedene Details wie Metriken und Ausgaben an. Nach Abschluss des Auftrags wird als Ergebnis des Trainings ein Modell in Ihrem Arbeitsbereich registriert.
Wichtig
Warten Sie, bis der Status des Auftrags „Abgeschlossen“ lautet, bevor Sie zu diesem Notebook zurückkehren, um den Vorgang fortzusetzen. Die Auftragsausführung dauert zwei bis drei Minuten. Wenn der Computecluster auf null Knoten skaliert wurde und die benutzerdefinierte Umgebung noch erstellt wird, kann die Ausführung bis zu zehn Minuten dauern.
Wenn Sie die Zelle ausführen, wird in der Ausgabe des Notebooks ein Link zur Detailseite des Auftrags in Azure Machine Learning Studio angezeigt. Alternativ können Sie auch im linken Navigationsmenü „Aufträge“ auswählen.
Ein Auftrag ist eine Gruppierung von vielen Ausführungen eines bestimmten Skripts oder Codes. Die Informationen für die Ausführung werden unter diesem Auftrag gespeichert. Die Detailseite bietet einen Überblick über den Auftrag, die Dauer der Ausführung, den Erstellungszeitpunkt und andere Informationen. Die Seite enthält außerdem Registerkarten mit weiteren Informationen zum Auftrag, z. B. Metriken, Ausgaben und Protokolle sowie Code. Folgende Registerkarten sind auf der Detailseite des Auftrags verfügbar:
- Übersicht: Grundlegende Informationen zum Auftrag, einschließlich seines Status, der Start- und Endzeit sowie der Art des ausgeführten Auftrags.
- Eingaben: Die Daten und der Code, die als Eingaben für den Auftrag verwendet wurden. Dieser Abschnitt kann Datasets, Skripte, Umgebungskonfigurationen und andere Ressourcen enthalten, die während des Trainings verwendet wurden.
- Ausgaben und Protokolle: Protokolle, die während der Ausführung des Auftrags generiert wurden. Diese Registerkarte unterstützt Sie bei der Problembehandlung, wenn bei der Erstellung Ihres Trainingsskripts oder Modells ein Problem auftritt.
- Metriken: Wichtige Leistungsmetriken Ihres Modells wie Trainingsbewertung, f1-Bewertung und Genauigkeitsbewertung.
Bereinigen von Ressourcen
Wenn Sie jetzt mit anderen Tutorials fortfahren möchten, können Sie direkt zu Verwandte Inhalte springen.
Beenden der Compute-Instanz
Wenn Sie die Compute-Instanz jetzt nicht verwenden möchten, beenden Sie sie:
- Wählen Sie im Studio im linken Navigationsbereich Compute aus.
- Wählen Sie auf den oberen Registerkarten die Option Compute-Instanzen aus.
- Wählen Sie in der Liste die Compute-Instanz aus.
- Wählen Sie auf der oberen Symbolleiste Beenden aus.
Löschen aller Ressourcen
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Geben Sie im Azure-Portal den Suchbegriff Ressourcengruppen in das Suchfeld ein, und wählen Sie in den Ergebnissen die entsprechende Option aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie auf der Seite Übersicht die Option Ressourcengruppe löschen aus.
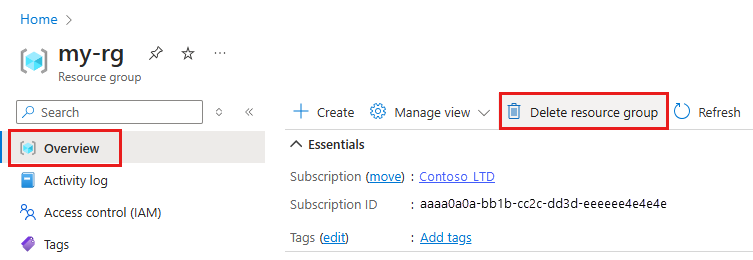
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Zugehöriger Inhalt
Weitere Informationen zum Bereitstellen eines Modells:
In diesem Tutorial wurde eine Onlinedatendatei verwendet. Weitere Informationen zu anderen Datenzugriffsmöglichkeiten finden Sie unter Tutorial: Hochladen, Zugreifen und Untersuchen Ihrer Daten in Azure Machine Learning.
Automatisiertes Maschinelles Lernen (AutoML) ist ein zusätzliches Tool, das dazu beiträgt, die Zeit zu reduzieren, die ein Data Scientist für die Suche nach einem Modell aufwenden muss, das am besten mit seinen jeweiligen Daten funktioniert. Weitere Informationen finden Sie unter Was ist automatisiertes maschinelles Lernen (AutoML)?.
Weitere Beispiele wie in diesem Tutorial finden Sie unter Lernen anhand von Beispiel-Notebooks. Diese Beispiele sind auf der GitHub-Beispielseite verfügbar. Sie umfassen vollständige Python-Notebooks, mit deren Hilfe Sie Code ausführen und sich mit dem Trainieren eines Modells vertraut machen können. Sie können vorhandene Skripte aus den Beispielen ändern und ausführen. Diese enthalten Szenarien wie Klassifizierung, linguistische Datenverarbeitung und Anomalieerkennung.