Verwenden von Indexempfehlungen der Indexoptimierung in Azure Database for PostgreSQL – Flexibler Server
Die Indexoptimierung speichert die von ihr erzeugten Empfehlungen in einer Reihe von Tabellen unter dem intelligentperformance-Schema in der azure_sys-Datenbank.
Derzeit können diese Informationen auf zwei Arten gelesen werden: über die zu diesem Zweck erstellte Seite im Azure-Portal oder durch Ausführen von Abfragen, um Daten aus zwei Sichten abzurufen, die innerhalb des intelligent performance-Schemas der azure_sys-Datenbank verfügbar sind.
Nutzen von Indexempfehlungen über das Azure-Portal
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihre Azure Database for PostgreSQL Flexible Server-Instanz aus.
Wählen Sie im Abschnitt Intelligente Leistung des Menüs die Option Indexoptimierung aus.
Wenn das Feature aktiviert ist, aber noch keine Empfehlungen erzeugt wurden, sieht der Bildschirm wie folgt aus:
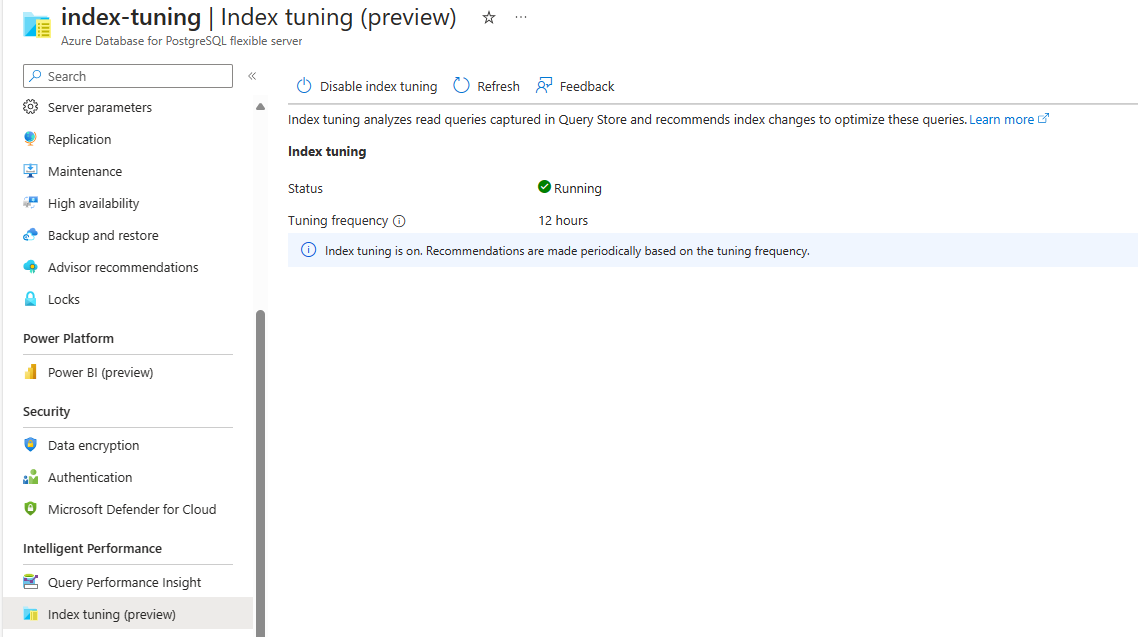
Wenn das Feature derzeit deaktiviert ist und bislang noch keine Empfehlungen erstellt wurden, sieht der Bildschirm wie folgt aus:
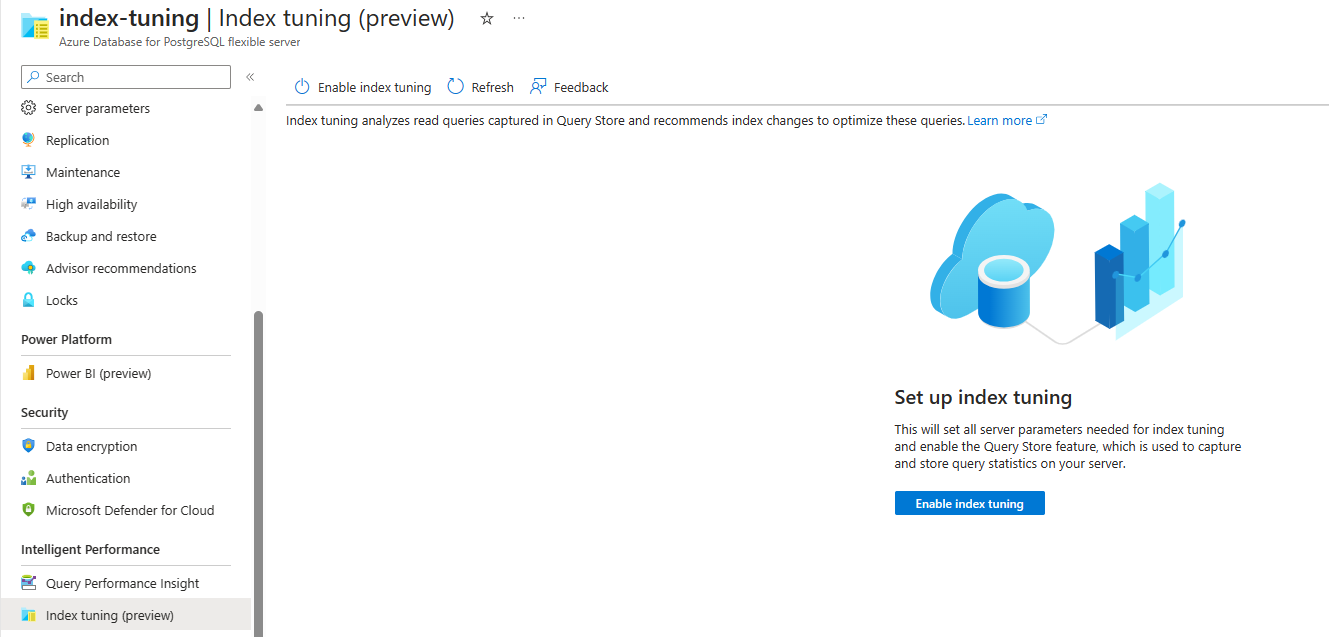
Wenn das Feature aktiviert ist und noch keine Empfehlungen erzeugt wurden, sieht der Bildschirm wie folgt aus:
Wenn das Feature deaktiviert ist, aber bereits Empfehlungen erzeugt wurden, sieht der Bildschirm wie folgt aus:
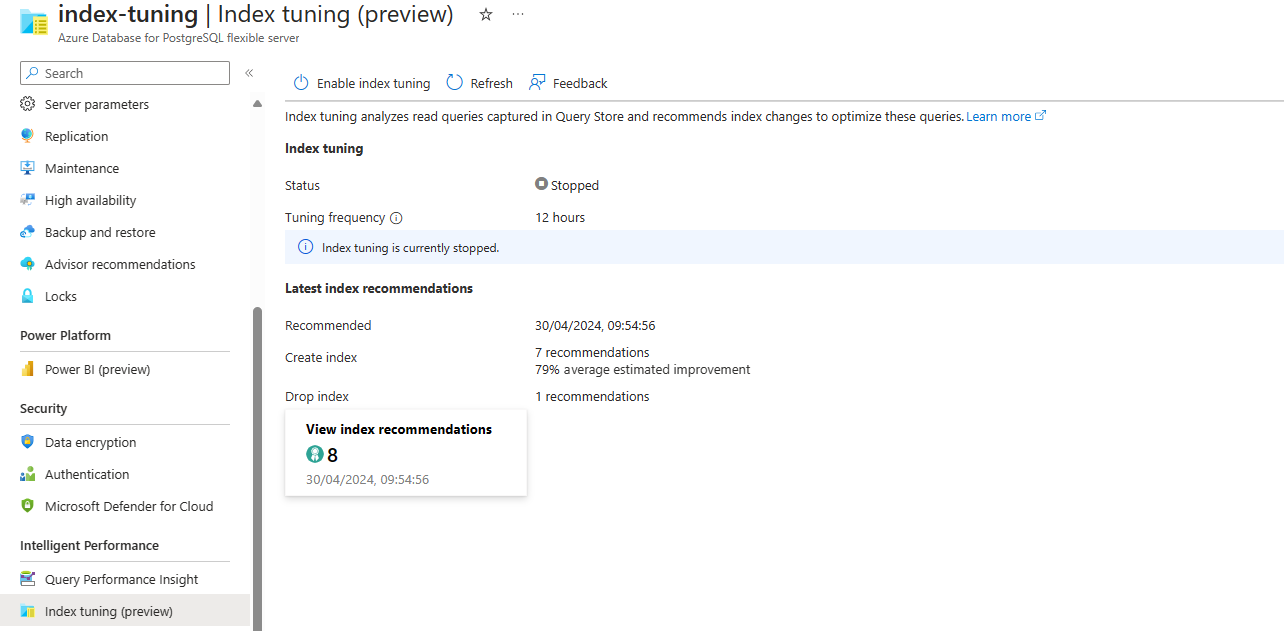
Wenn Empfehlungen verfügbar sind, wählen Sie die Zusammenfassung Indexempfehlungen anzeigen aus, um auf die vollständige Liste zuzugreifen:
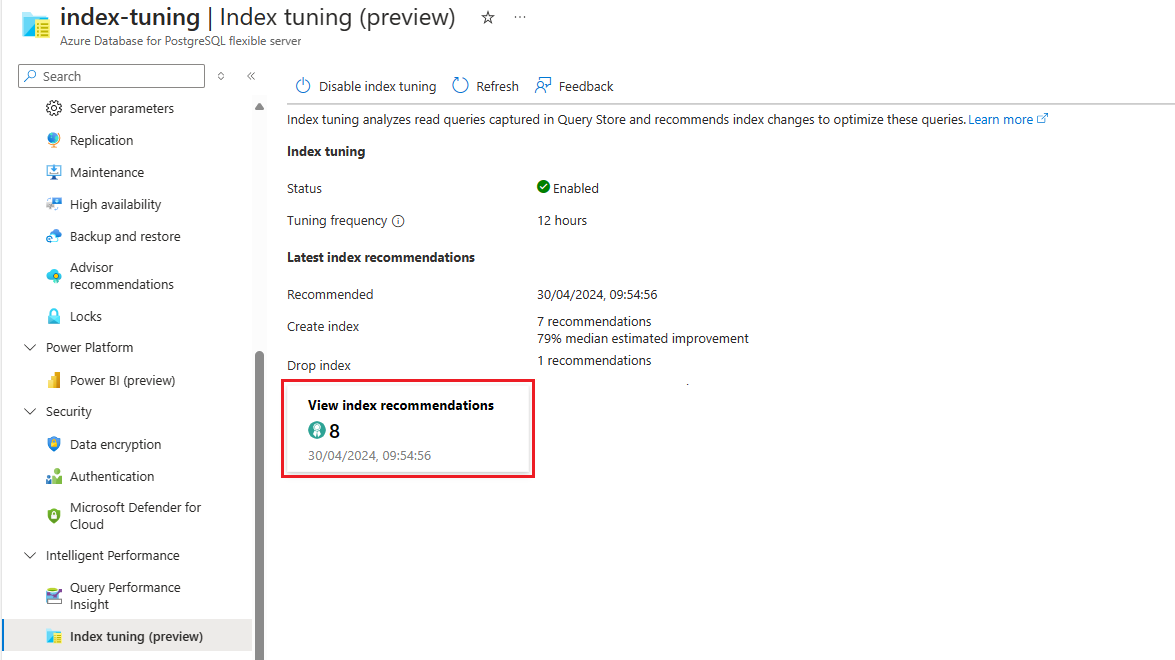
In der Liste werden alle verfügbaren Empfehlungen mit jeweils einigen Details aufgeführt. Standardmäßig wird die Liste nach Zuletzt empfohlen in absteigender Reihenfolge sortiert, sodass die neuesten Empfehlungen am Anfang der Liste angezeigt werden. Sie können die Liste jedoch nach einer beliebigen anderen Spalte sortieren und das Filterfeld verwenden, um die Liste der angezeigten Elemente auf die Elemente einzugrenzen, deren Datenbank-, Schema- oder Tabellennamen den angegebenen Text enthalten:
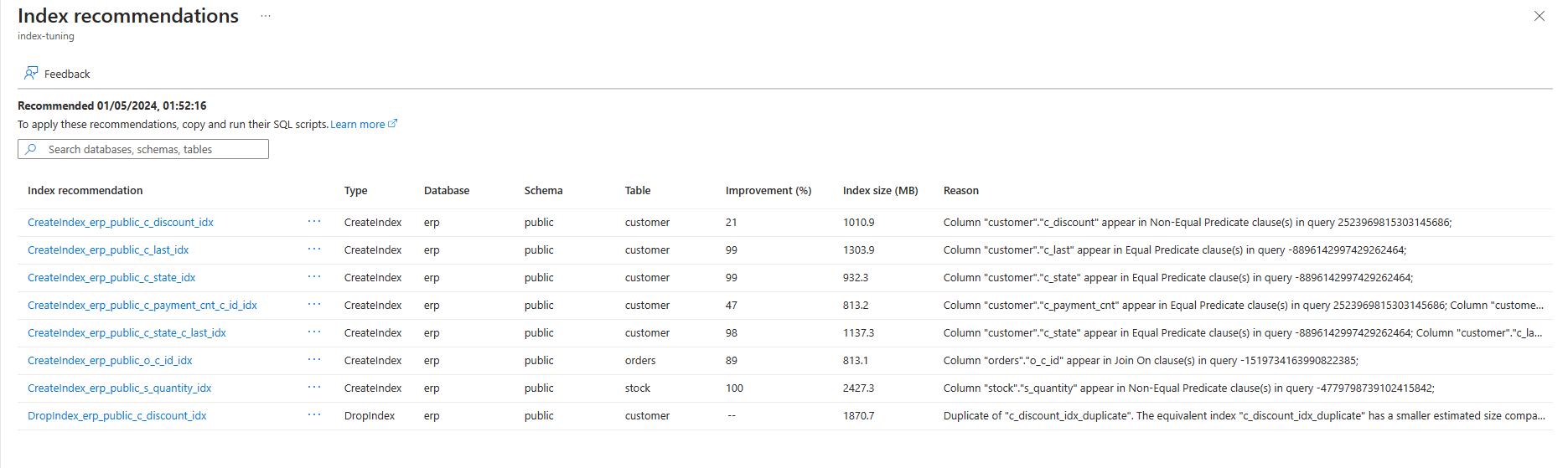
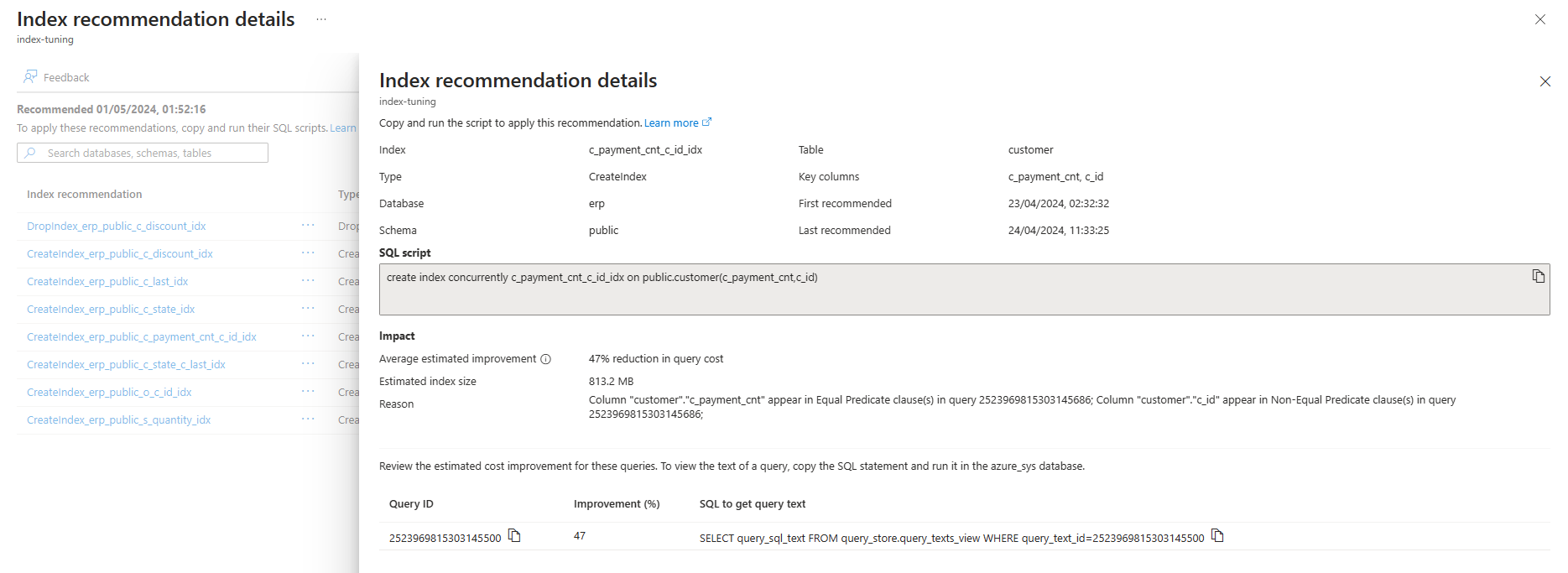
Wenn Sie weitere Informationen zu einer bestimmten Empfehlung anzeigen möchten, können Sie den Namen der gewünschten Empfehlung auswählen. Daraufhin wird auf der rechten Seite des Bildschirms der Bereich Indexempfehlungsdetails mit allen verfügbaren Details zu der Empfehlung geöffnet:






Nutzen von Indexempfehlungen über verfügbare Sichten aus der azure_sys-Datenbank
- Stellen Sie unter Verwendung einer beliebigen Rolle, die zum Herstellen einer Verbindung mit der Instanz berechtigt ist, eine Verbindung mit der auf Ihrem Server verfügbaren
azure_sys-Datenbank her. Mitglieder derpublic-Rolle können aus diesen Sichten lesen. - Führen Sie Abfragen in der
sessions-Ansicht aus, um die Details zu Empfehlungssitzungen abzurufen. - Führen Sie Abfragen in der
recommendations-Ansicht aus, um die Empfehlungen abzurufen, die durch die Indexoptimierung für CREATE INDEX und DROP INDEX erstellt wurden.
Ansichten
Sichten in der azure_sys-Datenbank sind eine komfortable Möglichkeit zum Zugreifen auf und Abrufen von Indexempfehlungen, die von der Indexoptimierung generiert wurden. Die Sichten createindexrecommendations und dropindexrecommendations enthalten insbesondere ausführliche Informationen zu CREATE INDEX- bzw. DROP INDEX-Empfehlungen. Diese Sichten machen Daten wie die Sitzungs-ID, den Datenbanknamen, den Ratgebertyp, Start- und Stoppzeiten der Optimierungssitzung, die Empfehlungs-ID, den Empfehlungstyp, den Grund für die Empfehlung und andere relevante Details verfügbar. Durch Abfragen dieser Sichten können Benutzer ganz einfach auf die von der Indexoptimierung erzeugten Indexempfehlungen zugreifen und sie analysieren.
intelligentperformance.sessions
Die sessions-Ansicht macht alle Details für alle Indexoptimierungssitzungen verfügbar.
| Spaltenname | Datentyp | BESCHREIBUNG |
|---|---|---|
| session_id | uuid | Jeder neuen Optimierungssitzung, die initiiert wird, wird ein global eindeutiger Bezeichner zugewiesen. |
| database_name | varchar(64) | Name der Datenbank, in deren Kontext die Indexoptimierungssitzung ausgeführt wurde. |
| session_type | intelligentperformance.recommendation_type | Gibt die Arten von Empfehlungen an, die diese Indexoptimierungssitzung erzeugen könnte. Mögliche Werte sind: CreateIndex, DropIndex. Sitzungen vom Typ CreateIndex können Empfehlungen vom Typ CreateIndex liefern. Sitzungen vom Typ DropIndex können Empfehlungen der Typen DropIndex oder ReIndex liefern. |
| run_type | intelligentperformance.recommendation_run_type | Gibt die Art und Weise an, in der diese Sitzung initiiert wurde. Mögliche Werte: Scheduled. Sitzungen, die automatisch gemäß dem Wert von index_tuning.analysis_interval ausgeführt werden, werden einem Ausführungstyp von Scheduled zugewiesen. |
| state | intelligentperformance.recommendation_state | Zeigt den aktuellen Zustand der Sitzung an. Mögliche Werte: Error, Success, InProgress. Sitzungen, deren Ausführung fehlgeschlagen ist, werden mit Error angegeben. Sitzungen, die ihre Ausführung ordnungsgemäß abgeschlossen haben, unabhängig davon, ob sie Empfehlungen generiert haben, werden mit Success angegeben. Sitzungen, die noch ausgeführt werden, werden mit InProgress angegeben. |
| start_time | Zeitstempel ohne Zeitzone | Zeitstempel, zu dem die Optimierungssitzung gestartet wurde, die diese Empfehlung erzeugt hat. |
| stop_time | Zeitstempel ohne Zeitzone | Zeitstempel, zu dem die Optimierungssitzung gestartet wurde, die diese Empfehlung erzeugt hat. NULL, wenn die Sitzung gerade ausgeführt wird oder aufgrund eines Fehlers abgebrochen wurde. |
| recommendations_count | integer | Die Gesamtzahl der Empfehlungen, die in dieser Sitzung erstellt wurden. |
intelligentperformance.recommendations
Über die recommendations-Ansicht werden alle Details für alle Empfehlungen verfügbar gemacht, die in einer beliebigen Optimierungssitzung generiert wurden, deren Daten noch in den zugrunde liegenden Tabellen verfügbar sind.
| Spaltenname | Datentyp | Beschreibung |
|---|---|---|
| recommendation_id | integer | Zahl, die eine Empfehlung auf den gesamten Server eindeutig identifiziert. |
| last_known_session_id | uuid | Jeder Indexoptimierungssitzung wird ein global eindeutiger Bezeichner zugewiesen. Der Wert in dieser Spalte stellt die Sitzung dar, die diese Empfehlung zuletzt erstellt hat. |
| database_name | varchar(64) | Name der Datenbank, in deren Kontext die Empfehlung erzeugt wurde. |
| recommendation_type | intelligentperformance.recommendation_type | Gibt den Typ der erstellten Empfehlung an. Mögliche Werte: CreateIndex, DropIndex, ReIndex. |
| initial_recommended_time | Zeitstempel ohne Zeitzone | Zeitstempel, zu dem die Optimierungssitzung gestartet wurde, die diese Empfehlung erzeugt hat. |
| last_recommended_time | Zeitstempel ohne Zeitzone | Zeitstempel, zu dem die Optimierungssitzung gestartet wurde, die diese Empfehlung erzeugt hat. |
| times_recommended | integer | Zeitstempel, zu dem die Optimierungssitzung gestartet wurde, die diese Empfehlung erzeugt hat. |
| reason | Text | Grund für die Erzeugung dieser Empfehlung. |
| recommendation_context | json | Enthält die Liste der Abfragebezeichner für die Abfragen, die von der Empfehlung betroffen sind, den Typ des empfohlenen Index, den Namen des Schemas und den Namen der Tabelle, für das bzw. für die der Index empfohlen wird, die Indexspalten, den Indexnamen und die geschätzte Größe des empfohlenen Index in Bytes. |
Gründe für das Erstellen von Indexempfehlungen
Wenn die Indexoptimierung die Erstellung eines Indexes empfiehlt, fügt sie mindestens einen der folgenden Gründe hinzu:
| Ursache |
|---|
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Gründe für Dropindexempfehlungen
Wenn die Indexoptimierung Indizes identifiziert, die als ungültig gekennzeichnet sind, schlägt sie vor, sie aus dem folgenden Grund zu löschen:
The index is invalid and the recommended recovery method is to reindex.
Weitere Informationen dazu, warum und wann Indizes als ungültig gekennzeichnet sind, finden Sie in der offiziellen Dokumentation zu REINDEX in PostgreSQL.
Gründe für Dropindexempfehlungen
Wenn die Indexoptimierung einen Index erkennt, der mindestens für die Anzahl der in index_tuning.unused_min_period festgelegten Tage nicht mehr verwendet wurde, schlägt sie vor, ihn mit dem folgenden Grund zu löschen:
The index is unused in the past <days_unused> days.
Wenn die Indexoptimierung doppelte Indizes erkennt, bleibt eines der Duplikate erhalten, und sie schlägt vor, das andere zu löschen. Der angegebene Grund hat immer den folgenden Anfangstext:
Duplicate of <surviving_duplicate>.
Gefolgt von einem anderen Text, der den Grund für die Auswahl zur Löschung der Duplikate erläutert:
| Ursache |
|---|
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Wenn der Index nicht nur aufgrund einer Duplizierung zu löschen ist, sondern auch seit mindestens der in index_tuning.unused_min_period festgelegten Anzahl von Tagen nicht verwendet wurde, wird der folgende Text an den Grund angefügt:
Also, the index is unused in the past <days_unused> days.
Anwenden von Indexempfehlungen
Indexempfehlungen enthalten die SQL-Anweisung, die Sie ausführen können, um die Empfehlung zu implementieren.
In den folgenden Abschnitten wird gezeigt, wie diese Anweisung für eine bestimmte Empfehlung abgerufen werden kann.
Wenn Sie über die Anweisung verfügen, können Sie einen beliebigen PostgreSQL-Client verwenden, um eine Verbindung mit Ihrem Server herzustellen und die Empfehlung anzuwenden.
Abrufen einer SQL-Anweisung über die Seite Indexoptimierungsseite im Azure-Portal
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihre Azure Database for PostgreSQL Flexible Server-Instanz aus.
Wählen Sie im Abschnitt Intelligente Leistung des Menüs die Option Indexoptimierung aus.
Sofern die Indexoptimierung bereits Empfehlungen erstellt hat, können Sie die Zusammenfassung Indexempfehlungen anzeigen auswählen, um auf die Liste der verfügbaren Empfehlungen zuzugreifen.
Führen Sie in der Liste der Empfehlungen eine der folgenden Aktionen aus:
Wählen Sie die Auslassungspunkte rechts neben der Empfehlung aus, für die Sie die SQL-Anweisung abrufen möchten, und wählen Sie SQL-Skript kopieren aus.
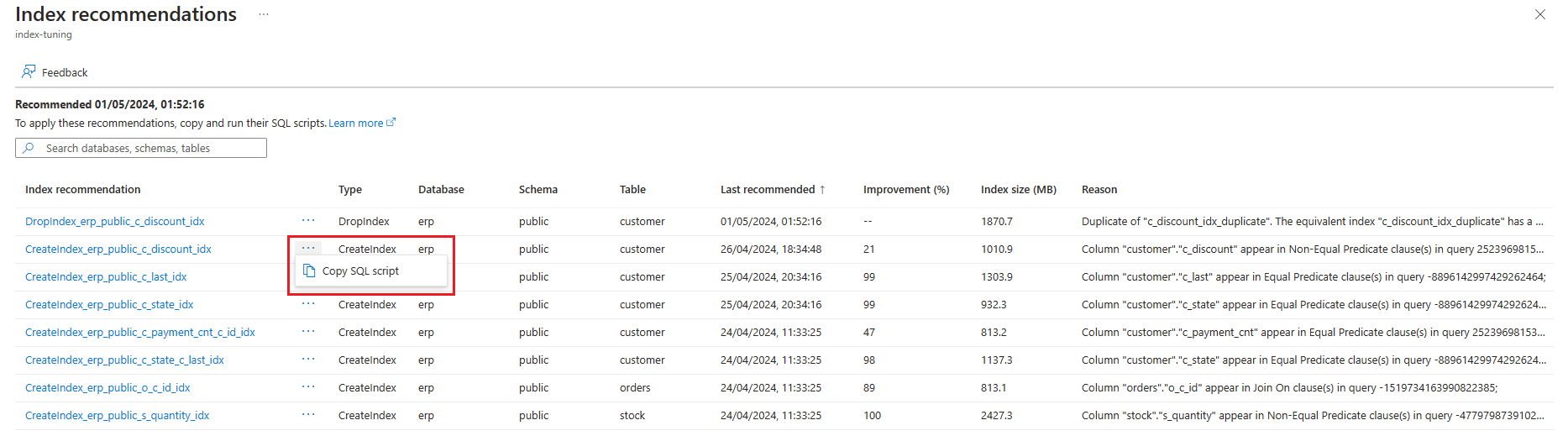
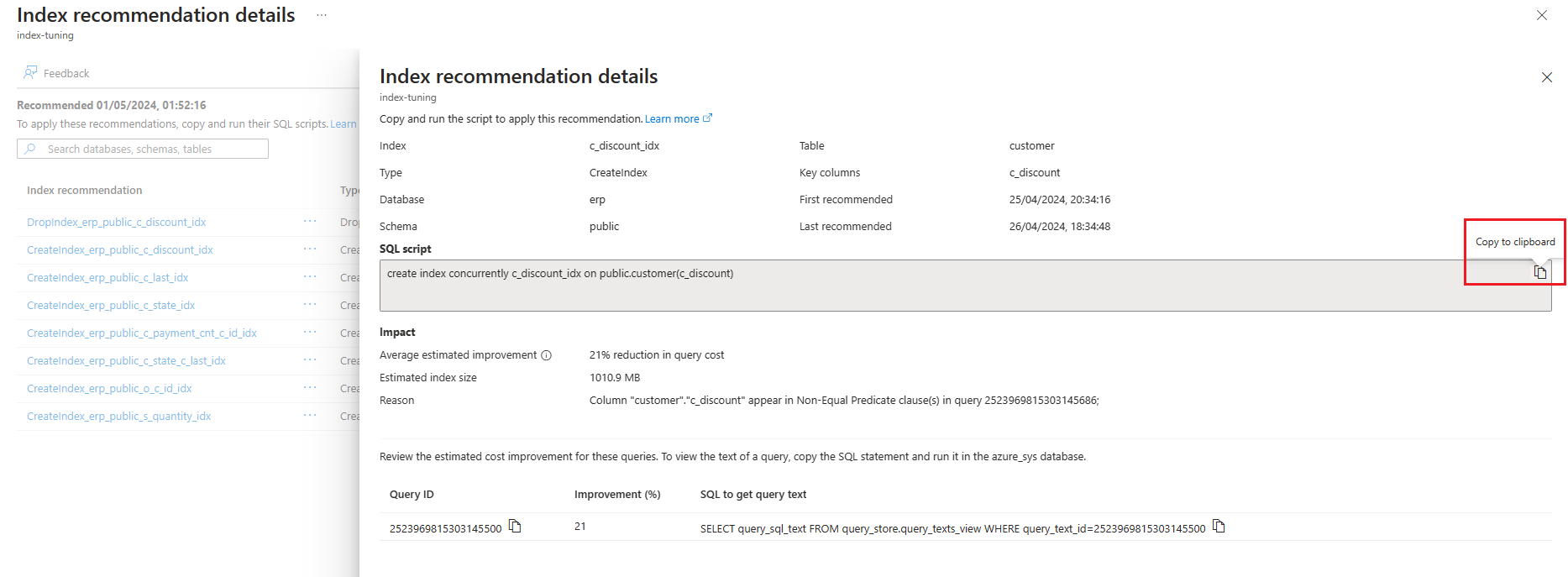
Alternativ können Sie den Namen der Empfehlung auswählen, um die Indexempfehlungsdetails anzuzeigen, und anschließend im Textfeld SQL-Skript das Symbol „In Zwischenablage kopieren“ auswählen, um die SQL-Anweisung zu kopieren.

Zugehöriger Inhalt
- Indexoptimierung in Azure Database for PostgreSQL – Flexibler Server
- Konfigurieren der Indexoptimierung in Azure Database for PostgreSQL – Flexibler Server
- Überwachen der Leistung mit dem Abfragespeicher
- Verwendungsszenarien für den Abfragespeicher: Azure Database for PostgreSQL – Flexibler Server
- Bewährte Methoden für den Abfragespeicher: Azure Database for PostgreSQL – Flexibler Server
- Query Performance Insight für Azure Database for PostgreSQL – Flexible Server