Hochverfügbarkeit der SAP HANA-Hochskalierung mit Azure NetApp Files unter SUSE Linux Enterprise Server
In diesem Artikel erfahren Sie, wie Sie die SAP HANA-Systemreplikation in einer Hochskalierungsbereitstellung mithilfe von Azure NetApp Files konfigurieren, wenn die HANA-Dateisysteme über NFS eingebunden sind. In den Beispielkonfigurationen und Installationsbefehlen werden die Instanznummer 03 und die HANA-System-ID HN1 verwendet. Die SAP HANA-Replikation umfasst einen primären Knoten und mindestens einen sekundären Knoten.
Einige Schritte in diesem Dokument sind mit Präfixen gekennzeichnet. Diese bedeuten Folgendes:
- [A] : Der Schritt gilt für alle Knoten.
- [1]: Der Schritt gilt nur für Knoten 1.
- [2]: Der Schritt gilt nur für Knoten 2.
Lesen Sie zuerst die folgenden SAP-Hinweise und -Dokumente:
- Der SAP-Hinweis 1928533 enthält Folgendes:
- Liste der Azure-VM-Größen, die für die Bereitstellung von SAP-Software unterstützt werden
- Wichtige Kapazitätsinformationen für die Größen virtueller Azure-Computer (Virtual Machines, VMs)
- Die unterstützte SAP-Software sowie die unterstützten Kombinationen aus Betriebssystem (Operating System, OS) und Datenbank
- Die erforderliche SAP-Kernelversion für Windows und Linux in Azure
- In SAP-Hinweis 2015553 sind die Voraussetzungen für Bereitstellungen von SAP-Software in Azure aufgeführt, die von SAP unterstützt werden.
- Im SAP-Hinweis 405827 wird das empfohlene Dateisystem für die HANA-Umgebung aufgeführt
- Der SAP-Hinweis 2684254 enthält empfohlene Betriebssystemeinstellungen für SLES 15 (SUSE Linux Enterprise Server) bzw. für SLES for SAP Applications 15.
- Der SAP-Hinweis 1944799 enthält SAP HANA-Richtlinien für die SLES-Betriebssysteminstallation.
- SAP-Hinweis 2178632 enthält ausführliche Informationen zu allen Überwachungsmetriken, die für SAP in Azure gemeldet werden.
- SAP-Hinweis 2191498 enthält die erforderliche SAP Host Agent-Version für Linux in Azure.
- SAP-Hinweis 2243692 enthält Informationen zur SAP-Lizenzierung unter Linux in Azure.
- SAP-Hinweis 1999351 enthält Informationen zur Problembehandlung für die Azure Enhanced Monitoring-Erweiterung für SAP.
- Der SAP-Hinweis 1900823 enthält Informationen zu Speicheranforderungen von SAP HANA.
- Leitfäden zu bewährten Methoden für Hochverfügbarkeit von SUSE SAP enthalten alle erforderlichen Informationen zur lokalen Einrichtung von NetWeaver-Hochverfügbarkeit und SAP HANA-Systemreplikation (als allgemeine Baseline). Sie bieten wesentlich mehr Informationen.
- Das SAP-Community-Wiki enthält alle erforderlichen SAP-Hinweise für Linux.
- Azure Virtual Machines – Planung und Implementierung für SAP unter Linux
- Bereitstellung von Azure Virtual Machines für SAP unter Linux
- Azure Virtual Machines – DBMS-Bereitstellung für SAP unter Linux
- Allgemeine SLES-Dokumentation:
- Einrichten eines SAP HANA-Clusters
- SLES High Availability Extension 15 SP3 Release Notes (Versionshinweise zur SLES-Hochverfügbarkeitserweiterung 15 SP3)
- Handbuch zur Sicherheitshärtung des Betriebssystems für SAP HANA für SUSE Linux Enterprise Server 15
- SUSE Linux Enterprise Server for SAP Applications 15 SP3 Guide (Leitfaden zu SUSE Linux Enterprise Server for SAP Applications 15 SP3)
- SUSE Linux Enterprise Server for SAP Applications 15 SP3 Automation (Automatisierung für SUSE Linux Enterprise Server for SAP Applications 15 SP3)
- SUSE Linux Enterprise Server for SAP Applications 15 SP3 Monitoring (Überwachung für SUSE Linux Enterprise Server for SAP Applications 15 SP3)
- Azure-spezifische SLES-Dokumentation:
- Erste Schritte mit SAP HANA Hochverfügbarkeits-Clusterautomatisierung in Azure
- SUSE and Microsoft Solution Templates for SAP Applications Simplified Deployment on Microsoft(SUSE- und Microsoft-Lösungsvorlagen für die vereinfachte Bereitstellung von SAP-Anwendungen auf Microsoft)
- NetApp-SAP-Anwendungen in Microsoft Azure mithilfe von Azure NetApp Files
- NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA
- Azure Virtual Machines – Planung und Implementierung für SAP unter Linux
Hinweis
In diesem Artikel wird ein Begriff verwendet, der von Microsoft nicht mehr genutzt wird. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Übersicht
In einer Hochskalierungsumgebung werden üblicherweise alle Dateisysteme für SAP HANA aus dem lokalen Speicher eingebunden. Informationen zum Einrichten der Hochverfügbarkeit der SAP HANA-Systemreplikation unter SUSE Linux Enterprise Server wurden unter Einrichten der SAP HANA-Systemreplikation unter SLES veröffentlicht.
Um Hochverfügbarkeit von SAP HANA bei einem Hochskalierungssystem auf NFS-Freigaben in Azure NetApp Files zu erreichen, ist eine zusätzliche Ressourcenkonfiguration im Cluster erforderlich. Durch diese Konfiguration wird sichergestellt, dass HANA-Ressourcen wiederhergestellt werden können, wenn ein Knoten keinen Zugriff mehr auf die NFS-Freigaben in Azure NetApp Files hat.
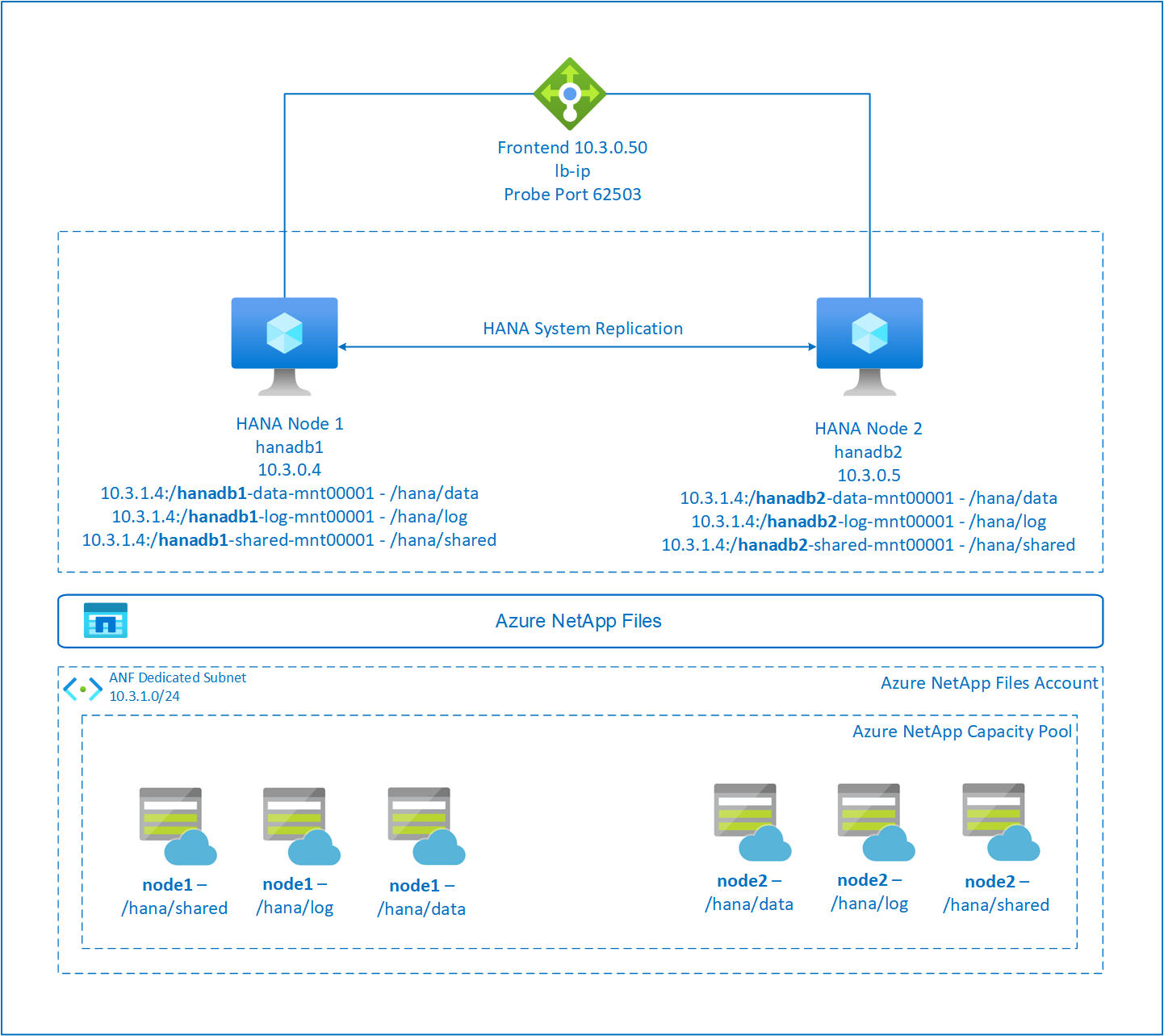
SAP HANA-Dateisysteme werden mithilfe von Azure NetApp Files auf NFS-Freigaben auf den einzelnen Knoten eingebunden. Die Dateisystempfade „/hana/data“, „/hana/log“ und „/hana/shared“ sind für jeden Knoten eindeutig.
Eingebunden auf „node1“ (hanadb1):
- 10.3.1.4:/hanadb1-data-mnt00001 on /hana/data
- 10.3.1.4:/hanadb1-log-mnt00001 on /hana/log
- 10.3.1.4:/hanadb1-shared-mnt00001 on /hana/shared
Eingebunden auf „node2“ (hanadb2):
- 10.3.1.4:/hanadb2-data-mnt00001 on /hana/data
- 10.3.1.4:/hanadb2-log-mnt00001 on /hana/log
- 10.3.1.4:/hanadb2-shared-mnt0001 on /hana/shared
Hinweis
Die Dateisystempfade „/hana/data“, „/hana/log“ und „/hana/shared“ werden von den beiden Knoten nicht gemeinsam genutzt. Jeder Clusterknoten besitzt eigene, separate Dateisysteme.
Die Hochverfügbarkeitskonfiguration der SAP HANA-Systemreplikation verwendet einen dedizierten virtuellen Hostnamen und virtuelle IP-Adressen. Für die Verwendung einer virtuellen IP-Adresse ist in Azure ein Lastenausgleich erforderlich. Die dargestellte Konfiguration zeigt einen Lastenausgleich mit:
- IP-Adresse der Front-End-Konfiguration: 10.3.0.50 für „hn1-db“
- Testport: 62503
Einrichten der Infrastruktur für Azure NetApp Files
Bevor Sie mit der Einrichtung der Azure NetApp Files-Infrastruktur fortfahren, sollten Sie sich mit der Azure NetApp Files-Dokumentation vertraut machen.
Azure NetApp Files ist in verschiedenen Azure-Regionen verfügbar. Überprüfen Sie, ob Azure NetApp Files in Ihrer ausgewählten Azure-Region angeboten wird.
Informationen zur Verfügbarkeit von Azure NetApp Files in den einzelnen Azure-Regionen finden Sie unter Verfügbarkeit von Azure NetApp Files nach Azure-Region.
Wichtige Hinweise
Beachten Sie beim Erstellen Ihrer Azure NetApp Files-Instanz für SAP HANA-Hochskalierungssysteme die wichtigen Überlegungen, die in NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA dokumentiert sind.
Dimensionierung einer HANA-Datenbank in Azure NetApp Files
Der Durchsatz eines Azure NetApp Files-Volumes ist eine Funktion der Volumegröße und der Dienstebene, wie in Dienstebenen für Azure NetApp Files beschrieben.
Beachten Sie beim Entwerfen der Infrastruktur für SAP HANA in Azure mit Azure NetApp Files die Empfehlungen in NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA.
Für die Konfiguration in diesem Artikel werden einfache Azure NetApp Files-Volumes verwendet.
Wichtig
Für Produktionssysteme, bei denen Leistung wichtig ist, empfiehlt es sich, Azure NetApp Files-Anwendungsvolumegruppen für SAP HANA zu evaluieren und zu verwenden.
Alle Befehle zum Einbinden von „/hana/shared“ in diesem Artikel gelten für /hana/shared-Volumes in NFSv4.1. Wenn Sie die /hana/shared-Volumes als NFSv3-Volumes bereitgestellt haben, vergessen Sie nicht, die Einbindebefehle für „/hana/shared“ auf NFSv3 anzupassen.
Bereitstellen von Azure NetApp Files-Ressourcen
In der folgenden Anleitung wird davon ausgegangen, dass Sie bereits Ihr virtuelles Azure-Netzwerk bereitgestellt haben. Die Azure NetApp Files-Ressourcen und die virtuellen Computer, auf denen die Azure NetApp Files-Ressourcen eingebunden werden, müssen im gleichen virtuellen Azure-Netzwerk oder in mittels Peering verknüpften virtuellen Azure-Netzwerken bereitgestellt werden.
Erstellen Sie entsprechend den Anweisungen in Erstellen eines NetApp-Kontos ein NetApp-Konto in der ausgewählten Azure-Region.
Richten Sie entsprechend den Anweisungen in Einrichten eines Kapazitätspools einen Azure NetApp Files-Kapazitätspool ein.
Die in diesem Artikel gezeigte HANA-Architektur verwendet einen einzelnen Azure NetApp Files-Kapazitätspool auf der Dienstebene „Ultra“. Für HANA-Workloads in Azure wird die Verwendung der Dienstebene „Ultra“ oder „Premium“ für Azure NetApp Files empfohlen.
Delegieren Sie ein Subnetz an Azure NetApp Files, wie in den Anweisungen in Delegieren eines Subnetzes an Azure NetApp Files beschrieben.
Stellen Sie Azure NetApp Files-Volumes entsprechend den Anweisungen in Erstellen eines NFS-Volumes für Azure NetApp Files bereit.
Stellen Sie beim Bereitstellen der Volumes sicher, dass Sie die Version NFSv4.1 auswählen. Stellen Sie die Volumes im festgelegten Subnetz für Azure NetApp Files bereit. Die IP-Adressen der Azure NetApp Files-Volumes werden automatisch zugewiesen.
Die Azure NetApp Files-Ressourcen und die virtuellen Azure-Computer müssen sich im gleichen virtuellen Azure-Netzwerk oder in mittels Peering verknüpften virtuellen Azure-Netzwerken befinden. Beispielsweise sind „hanadb1-data-mnt00001“, „hanadb1-log-mnt00001“ usw. die Volumenamen und „nfs://10.3.1.4/hanadb1-data-mnt00001“, „nfs://10.3.1.4/hanadb1-log-mnt00001“ usw. die Dateipfade für die Azure NetApp Files-Volumes.
Für hanadb1:
- Volume „hanadb1-data-mnt00001“ (nfs://10.3.1.4:/hanadb1-data-mnt00001)
- Volume „hanadb1-log-mnt00001“ (nfs://10.3.1.4:/hanadb1-log-mnt00001)
- Volume „hanadb1-shared-mnt00001“ (nfs://10.3.1.4:/hanadb1-shared-mnt00001)
Für hanadb2:
- Volume „hanadb2-data-mnt00001“ (nfs://10.3.1.4:/hanadb2-data-mnt00001)
- Volume „hanadb2-log-mnt00001“ (nfs://10.3.1.4:/hanadb2-log-mnt00001)
- Volume „hanadb2-shared-mnt00001“ (nfs://10.3.1.4:/hanadb2-shared-mnt00001)
Vorbereiten der Infrastruktur
Der Ressourcen-Agent für SAP HANA ist im SUSE Linux Enterprise Server für SAP-Anwendungen enthalten. Ein Image für SUSE Linux Enterprise Server for SAP Applications 12 oder 15 ist in Azure Marketplace verfügbar. Sie können das Image verwenden, um neue virtuelle Computer bereitzustellen.
Manuelles Bereitstellen von Linux-VMs über das Azure-Portal
In diesem Dokument wird davon ausgegangen, dass Sie bereits eine Ressourcengruppe, ein virtuelles Azure-Netzwerk und ein Subnetz bereitgestellt haben.
Stellen Sie VMs für SAP HANA bereit. Wählen Sie ein geeignetes SLES-Image aus, das für das HANA-System unterstützt wird. Sie können eine VM mit einer der folgenden Verfügbarkeitsoptionen bereitstellen: Skalierungsgruppe, Verfügbarkeitszone oder Verfügbarkeitsgruppe.
Wichtig
Vergewissern Sie sich, dass das von Ihnen gewählte Betriebssystem für SAP HANA auf den VM-Typen, die Sie verwenden möchten, SAP-zertifiziert ist. Sie können für SAP HANA zertifizierte VM-Typen und deren Betriebssystemversionen unter Für SAP HANA zertifizierte IaaS-Plattformen nachschlagen. Stellen Sie sicher, dass Sie sich die Details des jeweils aufgeführten VM-Typs ansehen, um die vollständige Liste der von SAP HANA unterstützten Betriebssystemversionen für den spezifischen VM-Typ zu erhalten.
Konfigurieren von Azure Load Balancer
Im Rahmen der VM-Konfiguration können Sie im Abschnitt „Netzwerk“ einen Lastenausgleich erstellen oder einen bereits vorhandenen Lastenausgleich auswählen. Führen Sie die nächsten Schritte aus, um einen Standardlastenausgleich für das Hochverfügbarkeitssetup der HANA-Datenbank einzurichten.
Führen Sie die unter Erstellen eines Lastenausgleichs beschriebenen Schritte aus, um über das Azure-Portal einen Standardlastenausgleich für ein SAP-Hochverfügbarkeitssystem einzurichten. Berücksichtigen Sie beim Einrichten des Lastenausgleichs die folgenden Punkte:
- Front-End-IP-Konfiguration: Erstellen Sie eine IP-Adresse für das Front-End. Wählen Sie dasselbe virtuelle Netzwerk und Subnetz aus wie für Ihre Datenbank-VMs.
- Back-End-Pool: Erstellen Sie einen Back-End-Pool, und fügen Sie Datenbank-VMs hinzu.
- Regeln für eingehenden Datenverkehr: Erstellen Sie eine Lastenausgleichsregel. Führen Sie die gleichen Schritte für beide Lastenausgleichsregeln aus.
- Front-End-IP-Adresse: Wählen Sie eine Front-End-IP-Adresse aus.
- Back-End-Pool: Wählen Sie einen Back-End-Pool aus.
- Hochverfügbarkeitsports: Wählen Sie diese Option aus.
- Protokoll: Wählen Sie TCP.
- Integritätstest: Erstellen Sie einen Integritätstest mit folgenden Details:
- Protokoll: Wählen Sie TCP.
- Port: Beispielsweise 625<Instanznr.>
- Intervall: Geben Sie 5 ein.
- Testschwellenwert: Geben Sie 2 ein.
- Leerlauftimeout (Minuten): Geben Sie 30 ein.
- Floating IP aktivieren: Wählen Sie diese Option aus.
Hinweis
Die Konfigurationseigenschaft numberOfProbes für Integritätstests (im Portal als Fehlerschwellenwert bezeichnet) wird nicht berücksichtigt. Legen Sie die probeThreshold-Eigenschaft auf 2 fest, um die Anzahl erfolgreicher oder nicht erfolgreicher aufeinanderfolgender Integritätstests zu steuern. Diese Eigenschaft kann derzeit nicht über das Azure-Portal festgelegt werden. Verwenden Sie daher entweder die Azure-Befehlszeilenschnittstelle (Command Line Interface, CLI) oder den PowerShell-Befehl.
Weitere Informationen zu den erforderlichen Ports für SAP HANA finden Sie im Kapitel zu Verbindungen mit Mandantendatenbanken im Handbuch zu SAP HANA-Mandantendatenbanken oder im SAP-Hinweis 2388694.
Wenn VMs ohne öffentliche IP-Adressen im Back-End-Pool einer internen Standard-Instanz von Azure Load Balancer (Instanz ohne öffentliche IP-Adresse) platziert werden, besteht keine ausgehende Internetkonnektivität, es sei denn, es werden weitere Konfigurationen vorgenommen, um Routing zu öffentlichen Endpunkten zu ermöglichen. Weitere Informationen zur Erzielung von ausgehender Konnektivität finden Sie unter Konnektivität öffentlicher Endpunkte für VMs, die Azure Load Balancer Standard in SAP-Hochverfügbarkeitsszenarien verwenden.
Wichtig
- Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancer befinden. Die Aktivierung von TCP-Zeitstempeln führt dazu, dass die Health Probes fehlschlagen. Setzen Sie den Parameter
net.ipv4.tcp_timestampsauf0. Weitere Informationen finden Sie unter Azure Load Balancer-Integritätstests sowie im SAP-Hinweis 2382421. - Um zu verhindern, dass saptune den manuell festgelegten
net.ipv4.tcp_timestamps-Wert von0wieder in1ändert, muss saptune mindestens auf die Version 3.1.1 aktualisiert werden. Weitere Informationen finden Sie unter saptune 3.1.1: Muss ich ein Update durchführen?.
Einbinden des Azure NetApp Files-Volumes
[A] Erstellen Sie Bereitstellungspunkte für die HANA-Datenbankvolumes.
sudo mkdir -p /hana/data/HN1/mnt00001 sudo mkdir -p /hana/log/HN1/mnt00001 sudo mkdir -p /hana/shared/HN1[A] Überprüfen Sie die Einstellung für die NFS-Domäne. Stellen Sie sicher, dass die Domäne als Azure NetApp Files-Standarddomäne (also defaultv4iddomain.com) konfiguriert und die Zuordnung auf nobody festgelegt ist.
sudo cat /etc/idmapd.confBeispielausgabe:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyWichtig
Stellen Sie sicher, dass die NFS-Domäne in „/etc/idmapd.conf“ auf der VM so festgelegt ist, dass sie mit der Standarddomänenkonfiguration für Azure NetApp Files übereinstimmt: defaultv4iddomain.com. Im Fall eines Konflikts zwischen der Domänenkonfiguration auf dem NFS-Client (also der VM) und dem NFS-Server (also der Azure NetApp Files-Konfiguration) werden die Berechtigungen für Dateien auf Azure NetApp Files-Volumes, die auf den VMs eingebunden sind, als nobody angezeigt.
[A] Bearbeiten Sie
/etc/fstabauf beiden Knoten, um die für jeden Knoten relevanten Volumes dauerhaft einzubinden. Im folgenden Beispiel wird gezeigt, wie Sie die Volumes dauerhaft einbinden.sudo vi /etc/fstabFügen Sie die folgenden Einträge auf beiden Knoten in
/etc/fstabhinzu.Beispiel für „hanadb1“:
10.3.1.4:/hanadb1-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Beispiel für „hanadb2“:
10.3.1.4:/hanadb2-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0Binden Sie alle Volumes ein.
sudo mount -aFür Workloads, die einen höheren Durchsatz erfordern, empfiehlt sich die Verwendung der Einbindungsoption
nconnect, wie unter NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA beschrieben. Überprüfen Sie, obnconnectvon Azure NetApp Files in Ihrer Linux-Version unterstützt wird.[A] Überprüfen Sie, ob alle HANA-Volumes mit der NFS-Protokollversion „NFSv4“ eingebunden wurden.
sudo nfsstat -mVergewissern Sie sich, dass das Flag
versauf 4.1 festgelegt ist.Beispiel aus „hanadb1“:
/hana/log/HN1/mnt00001 from 10.3.1.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/data/HN1/mnt00001 from 10.3.1.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/shared/HN1 from 10.3.1.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4[A] Überprüfen Sie nfs4_disable_idmapping. Diese Angabe sollte auf Y (Ja) festgelegt sein. Führen Sie den Einbindungsbefehl aus, um die Verzeichnisstruktur zu erstellen, in der sich nfs4_disable_idmapping befindet. Sie können das Verzeichnis nicht manuell unter
/sys/moduleserstellen, da der Zugriff für den Kernel bzw. für Treiber reserviert ist.#Check nfs4_disable_idmapping sudo cat /sys/module/nfs/parameters/nfs4_disable_idmapping #If you need to set nfs4_disable_idmapping to Y sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping #Make the configuration permanent sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf
SAP HANA-Installation
[A] Richten Sie die Hostnamensauflösung für alle Hosts ein.
Sie können entweder einen DNS-Server verwenden oder die Datei
/etc/hostsauf allen Knoten ändern. In diesem Beispiel wird die Verwendung der Datei/etc/hostsgezeigt. Ersetzen Sie in den folgenden Befehlen die IP-Adresse und den Hostnamen:sudo vi /etc/hostsFügen Sie in der Datei
/etc/hostsdie folgenden Zeilen ein. Ändern Sie die IP-Adresse und den Hostnamen entsprechend Ihrer Umgebung.10.3.0.4 hanadb1 10.3.0.5 hanadb2[A] Bereiten Sie das Betriebssystem für die Ausführung von SAP HANA in Azure NetApp mit NFS vor, wie im SAP-Hinweis 3024346 – Linux-Kerneleinstellungen für NetApp NFS beschrieben. Erstellen Sie die Konfigurationsdatei
/etc/sysctl.d/91-NetApp-HANA.conffür die NetApp-Konfigurationseinstellungen.sudo vi /etc/sysctl.d/91-NetApp-HANA.confFügen Sie in der Konfigurationsdatei die folgenden Einträge hinzu:
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Erstellen Sie die Konfigurationsdatei
/etc/sysctl.d/ms-az.confmit weiteren Optimierungseinstellungen.sudo vi /etc/sysctl.d/ms-az.confFügen Sie in der Konfigurationsdatei die folgenden Einträge hinzu:
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Tipp
Legen Sie
net.ipv4.ip_local_port_rangeundnet.ipv4.ip_local_reserved_portsin den sysctl-Konfigurationsdateien nicht explizit fest, damit der SAP-Host-Agent die Portbereiche verwalten kann. Weitere Informationen finden Sie im SAP-Hinweis 2382421.[A] Passen Sie die
sunrpc-Einstellungen wie im SAP-Hinweis 3024346 – Linux-Kerneleinstellungen für NetApp NFS empfohlen an.sudo vi /etc/modprobe.d/sunrpc.confFügen Sie die folgende Zeile ein:
options sunrpc tcp_max_slot_table_entries=128[A] Konfigurieren Sie SLES für HANA.
Konfigurieren Sie SLES wie in den folgenden SAP-Hinweisen beschrieben (basierend auf Ihrer SLES-Version):
- 2684254 Recommended OS settings for SLES 15 / SLES for SAP Applications 15 (Empfohlene Betriebssystemeinstellungen für SLES 15 / SLES for SAP Applications 15)
- 2205917 Recommended OS settings for SLES 12 / SLES for SAP Applications 12 (Empfohlene Betriebssystemeinstellungen für SLES 15 / SLES for SAP Applications 15)
- 2455582 Linux: Running SAP applications compiled with GCC 6.x (Linux: Ausführen von mit GCC 6.x kompilierten SAP-Anwendungen)
- 2593824 Linux: Running SAP applications compiled with GCC 7.x (Linux: Ausführen von mit GCC 7.x kompilierten SAP-Anwendungen)
- 2886607 Linux: Running SAP applications compiled with GCC 9.x (Linux: Ausführen von mit GCC 9.x kompilierten SAP-Anwendungen)
[A] Installieren Sie SAP HANA.
Ab HANA 2.0 SPS 01 sind mehrinstanzenfähige Datenbankcontainer (Multitenant Database Containers, MDC) die Standardoption. Wenn Sie das HANA-System installieren, werden SYSTEMDB und ein Mandant mit der gleichen SID zusammen erstellt. In einigen Fällen möchten Sie vielleicht nicht den Standardmandaten verwenden. Wenn Sie den anfänglichen Mandanten nicht im Rahmen der Installation erstellen möchten, halten Sie sich an die Anweisungen im SAP-Hinweis 2629711.
Starten Sie das Programm
hdblcmaus dem Verzeichnis der HANA-Installationssoftware../hdblcmGeben Sie an der Eingabeaufforderung folgende Werte ein:
- Für Choose installation: Geben Sie 1 (für die Installation) ein.
- Für Select additional components for installation: Geben Sie 1 ein.
- Für Enter Installation Path [/hana/shared]“: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter Local Host Name [..]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Unter Do you want to add additional hosts to the system? (y/n) [n]: Wählen Sie n aus.
- Für Enter SAP HANA System ID: Geben Sie HN1 ein.
- Für Enter Instance number [00]: Geben Sie 03 ein.
- Für Select Database Mode / Enter Index [1]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Select System Usage / Enter index [4]: Geben Sie 4 (für „Benutzerdefiniert“) ein.
- Für Enter Location of Data Volumes [/hana/data]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter Location of Log Volumes [/hana/log]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Restrict maximum memory allocation? [n]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter Certificate Host Name For Host '...' [...]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter SAP Host Agent User (sapadm) Password: Geben Sie das Benutzerkennwort des Host-Agents ein.
- Für Confirm SAP Host Agent User (sapadm) Password: Geben Sie das Benutzerkennwort des Host-Agents erneut ein, um es zu bestätigen.
- Für Enter System Administrator (hn1adm) Password: Geben Sie das Systemadministratorkennwort ein.
- Für Confirm System Administrator (hn1adm) Password: Geben Sie das Systemadministratorkennwort erneut ein, um es zu bestätigen.
- Für Enter System Administrator Home Directory [/usr/sap/HN1/home]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter System Administrator Login Shell [/bin/sh]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter System Administrator User ID [1001]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter ID of User Group (sapsys) [79]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Enter Database User (SYSTEM) Password: Geben Sie das Kennwort des Datenbankbenutzers ein.
- Für Confirm Database User (SYSTEM) Password: Geben Sie das Kennwort des Datenbankbenutzers erneut ein, um es zu bestätigen.
- Für Restart system after machine reboot? [n]: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Für Do you want to continue? (y/n): Überprüfen Sie die Zusammenfassung. Geben Sie y ein, um fortzufahren.
[A] Führen Sie ein Upgrade für den SAP-Host-Agent durch.
Laden Sie das aktuelle SAP-Host-Agent-Archiv vom SAP Software Center herunter, und führen Sie den folgenden Befehl zum Aktualisieren des Agents aus. Ersetzen Sie den Pfad zum Archiv, sodass er auf die Datei verweist, die Sie heruntergeladen haben.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>
Konfigurieren der SAP HANA-Systemreplikation
Konfigurieren Sie die SAP HANA-Systemreplikation, wie hier beschrieben.
Clusterkonfiguration
In diesem Abschnitt werden die Schritte beschrieben, die für einen reibungslosen Clusterbetrieb erforderlich sind, wenn SAP HANA unter Verwendung von Azure NetApp Files auf NFS-Freigaben installiert wird.
Erstellen eines Pacemaker-Clusters
Führen Sie die Schritte in Einrichten von Pacemaker auf SUSE Linux Enterprise Server in Azure zum Erstellen eines grundlegenden Pacemaker-Clusters für diesen HANA-Server aus.
Implementieren der HANA-Hooks SAPHanaSR und susChkSrv
Dieser wichtige Schritt optimiert die Integration in den Cluster und ermöglicht eine bessere Erkennung eines erforderlichen Clusterfailovers. Es wird dringend empfohlen, sowohl SAPHanaSR- als auch susChkSrv-Python-Hooks zu konfigurieren. Führen Sie die Schritte aus, die unter Implementieren der HANA-Hooks SAPHanaSR/SAPHanaSR-angi und susChkSrv beschrieben sind.
Konfigurieren von SAP HANA-Clusterressourcen
In diesem Abschnitt werden die erforderlichen Schritte zum Konfigurieren der SAP HANA-Clusterressourcen beschrieben.
Erstellen von SAP HANA-Clusterressourcen
Führen Sie die unter Erstellen von SAP HANA-Clusterressourcen beschriebenen Schritte aus, um die Clusterressourcen für den HANA-Server zu erstellen. Nachdem die Ressourcen erstellt wurden, können Sie den Status des Clusters mit dem folgenden Befehl anzeigen:
sudo crm_mon -r
Beispielausgabe:
# Online: [ hn1-db-0 hn1-db-1 ]
# Full list of resources:
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Erstellen von Dateisystemressourcen
Das Dateisystem /hana/shared/SID ist sowohl für den HANA-Betrieb als auch für Pacemaker-Überwachungsaktionen erforderlich, die den Zustand von HANA bestimmen. Implementieren Sie Ressourcen-Agents, die bei Fehlern die Überwachung und Maßnahmen beginnen. Der Abschnitt enthält zwei Optionen, eine für SAPHanaSR und eine für SAPHanaSR-angi.
Erstellen Sie eine Dummy-Dateisystemclusterressource. Sie dient zur Überwachung und meldet Fehler, wenn beim Zugriff auf das in NFS eingebundene Dateisystem „/hana/shared“ ein Problem auftritt. So kann der Cluster ein Failover auslösen, wenn beim Zugriff auf „/hana/shared“ ein Problem auftritt. Weitere Informationen hierzu finden Sie unter Handling failed NFS share in SUSE HA cluster for HANA system replication (Behandeln fehlerhafter NFS-Freigaben im SUSE-Hochverfügbarkeitscluster für die HANA-Systemreplikation).
[A] Erstellen Sie die Verzeichnisstruktur auf beiden Knoten.
sudo mkdir -p /hana/shared/HN1/check sudo mkdir -p /hana/shared/check[1] Konfigurieren Sie den Cluster so, dass die Verzeichnisstruktur für die Überwachung hinzugefügt wird.
sudo crm configure primitive rsc_fs_check_HN1_HDB03 Filesystem params \ device="/hana/shared/HN1/check/" \ directory="/hana/shared/check/" fstype=nfs \ options="bind,defaults,rw,hard,rsize=262144,wsize=262144,proto=tcp,noatime,_netdev,nfsvers=4.1,lock,sec=sys" \ op monitor interval=120 timeout=120 on-fail=fence \ op_params OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 \ op stop interval=0 timeout=120[1] Klonen und überprüfen Sie das neu konfigurierte Volume im Cluster.
sudo crm configure clone cln_fs_check_HN1_HDB03 rsc_fs_check_HN1_HDB03 meta clone-node-max=1 interleave=trueBeispielausgabe:
sudo crm status # Cluster Summary: # Stack: corosync # Current DC: hanadb1 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Tue Nov 2 17:57:39 2021 # Last change: Tue Nov 2 17:57:38 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb1 (Monitoring) # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb2 (Monitoring) # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # rsc_SAPHana_HN1_HDB03 (ocf::suse:SAPHana): Master hanadb1 (Monitoring) # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Das Attribut
OCF_CHECK_LEVEL=20wird dem Überwachungsvorgang hinzugefügt, sodass Überwachungsvorgänge einen Lese-/Schreibtest für das Dateisystem durchführen. Ohne dieses Attribut überprüft der Überwachungsvorgang nur, ob das Dateisystem eingebunden ist. Dies kann ein Problem darstellen, denn wenn die Verbindung unterbrochen wird, kann das Dateisystem eingehängt bleiben, obwohl es nicht zugänglich ist.Das Attribut
on-fail=fencewird auch dem Überwachungsvorgang hinzugefügt. Durch diese Option wird ein Knoten sofort eingegrenzt, wenn beim Überwachungsvorgang für diesen Knoten ein Fehler auftritt.
Wichtig
Timeouts in der obigen Konfiguration müssen ggf. an das spezifische HANA-System angepasst werden, um unnötige Fence-Aktionen zu vermeiden. Legen Sie die Timeouts nicht auf einen zu niedrigen Wert fest. Beachten Sie, dass der Dateisystemmonitor nicht mit der HANA-Systemreplikation zusammenhängt. Weitere Informationen finden Sie in der SUSE-Dokumentation.
Testen der Clustereinrichtung
In diesem Abschnitt wird beschrieben, wie Sie Ihre Einrichtung testen können.
Vergewissern Sie sich vor dem Starten eines Tests, dass für Pacemaker keine fehlerhaften Aktionen vorhanden sind (mithilfe von „crm status“) und auch keine unerwarteten Speicherorteinschränkungen vorliegen (z. B. durch Reste eines Migrationstests). Stellen Sie außerdem sicher, dass sich die HANA-Systemreplikation im synchronen Zustand befindet (z. B. mithilfe von
systemReplicationStatus).sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Überprüfen Sie den Status der HANA-Ressourcen mithilfe des folgenden Befehls:
SAPHanaSR-showAttr # You should see something like below # hanadb1:~ SAPHanaSR-showAttr # Global cib-time maintenance # -------------------------------------------- # global Mon Nov 8 22:50:30 2021 false # Sites srHook # ------------- # SITE1 PRIM # SITE2 SOK # Site2 SOK # Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost # -------------------------------------------------------------------------------------------------------------------------------------------------------------- # hanadb1 PROMOTED 1636411810 online logreplay hanadb2 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.058.00.1634122452 hanadb1 # hanadb2 DEMOTED 30 online logreplay hanadb1 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.058.00.1634122452 hanadb2Überprüfen Sie die Clusterkonfiguration auf ein Fehlerszenario, wenn ein Knoten heruntergefahren wird. Das folgende Beispiel zeigt das Herunterfahren des Knotens 1:
sudo crm status sudo crm resource move msl_SAPHana_HN1_HDB03 hanadb2 force sudo crm resource cleanupBeispielausgabe:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:25:36 2021 # Last change: Mon Nov 8 23:25:19 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Beenden Sie HANA auf dem Knoten 1:
sudo su - hn1adm sapcontrol -nr 03 -function StopWait 600 10Registrieren Sie den Knoten 1 als sekundären Knoten, und überprüfen Sie den Status.
hdbnsutil -sr_register --remoteHost=hanadb2 --remoteInstance=03 --replicationMode=sync --name=SITE1 --operationMode=logreplayBeispielausgabe:
#adding site ... #nameserver hanadb1:30301 not responding. #collecting information ... #updating local ini files ... #done.sudo crm statussudo SAPHanaSR-showAttrÜberprüfen Sie die Clusterkonfiguration auf ein Fehlerszenario, wenn ein Knoten den Zugriff auf die NFS-Freigabe (/hana/shared) verliert.
Die SAP HANA-Ressourcen-Agents benötigen in „/hana/shared“ gespeicherte Binärdateien, um Vorgänge während eines Failovers ausführen zu können. Das Dateisystem „/hana/shared“ ist in diesem Szenario über NFS eingebunden.
Es ist schwierig, einen Fehler zu simulieren, bei dem einer der Server den Zugriff auf die NFS-Freigabe verliert. Zum Testen können Sie das Dateisystem als schreibgeschütztes Dateisystem erneut einbinden. Auf diese Weise lässt sich überprüfen, ob der Cluster ein Failover ausführen kann, wenn der Zugriff auf „/hana/shared“ auf dem aktiven Knoten verloren geht.
Erwartetes Ergebnis: Wenn „/hana/shared“ zu einem schreibgeschützten Dateisystem gemacht wird, ist das Attribut
OCF_CHECK_LEVELder Ressourcehana_shared1, die Lese-/Schreibvorgänge im Dateisystem durchführt, fehlerhaft. Das liegt daran, dass nichts mehr in das Dateisystem geschrieben werden kann. Daher wird ein HANA-Ressourcenfailover ausgeführt. Dasselbe Ergebnis ist zu erwarten, wenn der HANA-Knoten den Zugriff auf die NFS-Freigaben verliert.Zustand der Ressource vor dem Starten des Tests:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:01:27 2021 # Last change: Mon Nov 8 23:00:46 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb1 ] # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Sie können „/hana/shared“ mithilfe des folgenden Befehls auf dem aktiven Clusterknoten in den schreibgeschützten Modus versetzen:
sudo mount -o ro 10.3.1.4:/hanadb1-shared-mnt00001 /hana/sharedbJe nach festgelegter Aktion wird der Server
hanadb1entweder neu gestartet oder ausgeschaltet. Wenn der Serverhanadb1nicht mehr verfügbar ist, wechselt die HANA-Ressource zuhanadb2. Sie können den Status des Clusters überhanadb2überprüfen.sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Wed Nov 10 22:00:27 2021 # Last change: Wed Nov 10 21:59:47 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Es wird empfohlen, die SAP HANA-Clusterkonfiguration sorgfältig zu testen. Führen Sie dazu die Tests durch, die unter Testen der Clustereinrichtung beschrieben sind.