Hochverfügbarkeit von SAP HANA auf Azure-VMs unter Red Hat Enterprise Linux
Für die lokale Entwicklung können Sie entweder die HANA-Systemreplikation oder freigegebenen Speicher verwenden, um Hochverfügbarkeit (High Availability, HA) für SAP HANA einzurichten. Die HANA-Systemreplikation in Azure ist derzeit die einzige auf Azure-VMs unterstützte Hochverfügbarkeitsfunktion.
Die SAP HANA-Replikation umfasst primären Knoten und mindestens einen sekundären Knoten. Änderungen an den Daten auf dem primären Knoten werden synchron oder asynchron an den sekundären Knoten repliziert.
In diesem Artikel werden das Bereitstellen und Konfigurieren der VMs, das Installieren des Clusterframeworks sowie das Installieren und Konfigurieren der SAP HANA-Systemreplikation beschrieben.
In den Beispielkonfigurationen und Installationsbefehlen werden die Instanznummer 03 und HANA-System-ID HN1 verwendet.
Voraussetzungen
Lesen Sie zuerst die folgenden SAP-Hinweise und -Dokumente:
- SAP-Hinweis 1928533 mit folgenden Informationen:
- Liste der Azure-VM-Größen, die für die Bereitstellung von SAP-Software unterstützt werden
- Wichtige Kapazitätsinformationen für Azure-VM-Größen
- Unterstützte Kombinationen von SAP-Software, Betriebssystem und Datenbank.
- Erforderliche SAP-Kernelversion für Windows und Linux in Microsoft Azure
- In SAP-Hinweis 2015553 sind die Voraussetzungen für Bereitstellungen von SAP-Software in Azure aufgeführt, die von SAP unterstützt werden.
- SAP-Hinweis 2002167 enthält empfohlene Betriebssystemeinstellungen für Red Hat Enterprise Linux.
- SAP-Hinweis 2009879 enthält SAP HANA-Richtlinien für Red Hat Enterprise Linux.
- Der SAP-Hinweis 3108302 enthält SAP HANA-Leitfäden für Red Hat Enterprise Linux 9.x.
- SAP-Hinweis 2178632 enthält ausführliche Informationen zu allen Überwachungsmetriken, die für SAP in Azure gemeldet werden.
- SAP-Hinweis 2191498 enthält die erforderliche SAP Host Agent-Version für Linux in Azure.
- SAP-Hinweis 2243692 enthält Informationen zur SAP-Lizenzierung unter Linux in Azure.
- SAP-Hinweis 1999351 enthält Informationen zur Problembehandlung für die Azure Enhanced Monitoring-Erweiterung für SAP.
- Das WIKI der SAP-Community enthält alle erforderlichen SAP-Hinweise für Linux.
- Azure Virtual Machines – Planung und Implementierung für SAP unter Linux
- Azure Virtual Machines – Bereitstellung für SAP unter Linux (dieser Artikel)
- Azure Virtual Machines – DBMS-Bereitstellung für SAP unter Linux
- SAP HANA-Systemreplikation in einem Pacemaker-Cluster
- Allgemeine RHEL-Dokumentation:
- Azure-spezifische RHEL-Dokumentation:
- Unterstützungsrichtlinien für RHEL-Hochverfügbarkeitscluster – Virtuelle Microsoft Azure-Computer als Clustermitglieder
- Installieren und Konfigurieren eines Red Hat Enterprise Linux 7.4-Hochverfügbarkeitclusters (und höher) in Microsoft Azure
- Installieren von SAP HANA unter Red Hat Enterprise Linux für die Verwendung in Microsoft Azure
Übersicht
Um Hochverfügbarkeit zu erreichen, wird SAP HANA auf zwei VMs installiert. Die Daten werden mit der HANA-Systemreplikation repliziert.
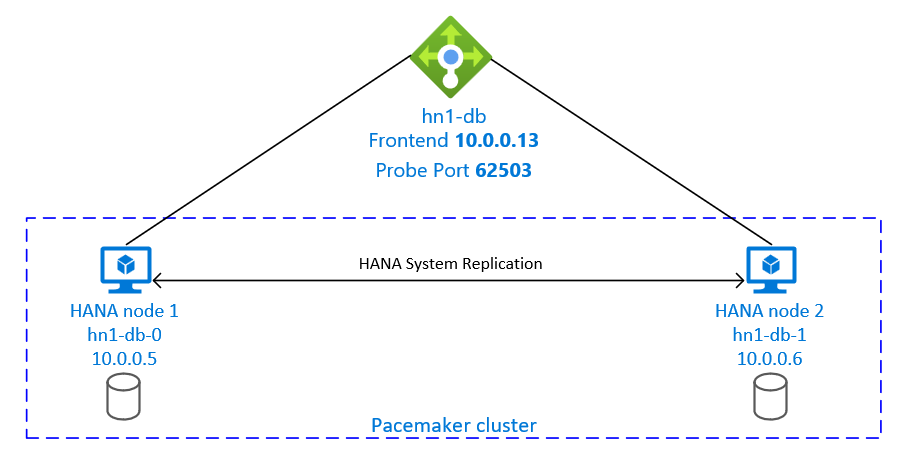
Das Setup der SAP HANA-Systemreplikation verwendet einen dedizierten virtuellen Hostnamen und virtuelle IP-Adressen. Für die Verwendung einer virtuellen IP-Adresse ist in Azure ein Lastenausgleich erforderlich. Die dargestellte Konfiguration zeigt einen Lastenausgleich mit:
- Front-End-IP-Adresse: 10.0.0.13 für hn1-db
- Testport: 62503
Vorbereiten der Infrastruktur
Im Azure Marketplace finden Sie Images, die für SAP HANA mit dem Add-On für Hochverfügbarkeit qualifiziert sind und Ihnen das Bereitstellen neuer VMs mithilfe verschiedener Versionen von Red Hat ermöglichen.
Manuelles Bereitstellen von Linux-VMs über das Azure-Portal
In diesem Dokument wird davon ausgegangen, dass Sie bereits eine Ressourcengruppe, ein virtuelles Azure-Netzwerk und ein Subnetz bereitgestellt haben.
Stellen Sie VMs für SAP HANA bereit. Wählen Sie ein geeignetes RHEL-Image aus, das für das HANA-System unterstützt wird. Sie können eine VM mit einer der folgenden Verfügbarkeitsoptionen bereitstellen: Skalierungsgruppe, Verfügbarkeitszone oder Verfügbarkeitsgruppe.
Wichtig
Vergewissern Sie sich, dass das von Ihnen gewählte Betriebssystem für SAP HANA auf den VM-Typen, die Sie verwenden möchten, SAP-zertifiziert ist. Sie können für SAP HANA zertifizierte VM-Typen und deren Betriebssystemversionen unter Für SAP HANA zertifizierte IaaS-Plattformen nachschlagen. Stellen Sie sicher, dass Sie sich die Details des jeweils aufgeführten VM-Typs ansehen, um die vollständige Liste der von SAP HANA unterstützten Betriebssystemversionen für den spezifischen VM-Typ zu erhalten.
Konfigurieren von Azure Load Balancer
Während der VM-Konfiguration können Sie im Abschnitt „Netzwerk“ einen Lastenausgleich erstellen oder einen vorhandenen Lastenausgleich auswählen. Führen Sie die folgenden Schritte aus, um den Standardlastenausgleich für das Hochverfügbarkeitssetup der HANA-Datenbank einzurichten.
Führen Sie die unter Erstellen eines Lastenausgleichs beschriebenen Schritte aus, um über das Azure-Portal einen Standardlastenausgleich für ein SAP-Hochverfügbarkeitssystem einzurichten. Berücksichtigen Sie beim Einrichten des Lastenausgleichs die folgenden Punkte:
- Front-End-IP-Konfiguration: Erstellen Sie eine IP-Adresse für das Front-End. Wählen Sie dasselbe virtuelle Netzwerk und Subnetz aus wie für Ihre Datenbank-VMs.
- Back-End-Pool: Erstellen Sie einen Back-End-Pool, und fügen Sie Datenbank-VMs hinzu.
- Regeln für eingehenden Datenverkehr: Erstellen Sie eine Lastenausgleichsregel. Führen Sie die gleichen Schritte für beide Lastenausgleichsregeln aus.
- Front-End-IP-Adresse: Wählen Sie eine Front-End-IP-Adresse aus.
- Back-End-Pool: Wählen Sie einen Back-End-Pool aus.
- Hochverfügbarkeitsports: Wählen Sie diese Option aus.
- Protokoll: Wählen Sie TCP.
- Integritätstest: Erstellen Sie einen Integritätstest mit folgenden Details:
- Protokoll: Wählen Sie TCP.
- Port: Beispielsweise 625<Instanznr.>
- Intervall: Geben Sie 5 ein.
- Testschwellenwert: Geben Sie 2 ein.
- Leerlauftimeout (Minuten): Geben Sie 30 ein.
- Floating IP aktivieren: Wählen Sie diese Option aus.
Hinweis
Die Konfigurationseigenschaft numberOfProbes für Integritätstests (im Portal als Fehlerschwellenwert bezeichnet) wird nicht berücksichtigt. Legen Sie die probeThreshold-Eigenschaft auf 2 fest, um die Anzahl erfolgreicher oder nicht erfolgreicher aufeinanderfolgender Integritätstests zu steuern. Diese Eigenschaft kann derzeit nicht über das Azure-Portal festgelegt werden. Verwenden Sie daher entweder die Azure-Befehlszeilenschnittstelle (Command Line Interface, CLI) oder den PowerShell-Befehl.
Weitere Informationen zu den erforderlichen Ports für SAP HANA finden Sie im Kapitel zu Verbindungen mit Mandantendatenbanken im Handbuch zu SAP HANA-Mandantendatenbanken oder im SAP-Hinweis 2388694.
Hinweis
Wenn VMs ohne öffentliche IP-Adressen in den Back-End-Pool einer internen (keine öffentliche IP-Adresse) Azure Load Balancer Standard-Instanz platziert werden, gibt es keine ausgehende Internetkonnektivität, es sei denn, es werden weitere Konfigurationen vorgenommen, um das Routing zu öffentlichen Endpunkten zu ermöglichen. Weitere Informationen zur Erzielung von ausgehender Konnektivität finden Sie unter Konnektivität öffentlicher Endpunkte für VMs, die Azure Load Balancer Standard in SAP-Hochverfügbarkeitsszenarien verwenden.
Wichtig
Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancer befinden. Das Aktivieren von TCP-Zeitstempeln kann zu Fehlern bei Integritätstests führen. Setzen Sie den Parameter net.ipv4.tcp_timestamps auf 0. Weitere Informationen finden Sie unter Azure Load Balancer-Integritätstests sowie im SAP-Hinweis 2382421.
Installieren von SAP HANA
Für die Schritte in diesem Abschnitt werden die folgenden Präfixe verwendet:
- [A] : Der Schritt gilt für alle Knoten.
- [1] : Der Schritt gilt nur für den Knoten 1.
- [2] : Der Schritt gilt nur für den Knoten 2 des Pacemaker-Clusters.
[A] Richten Sie das Datenträgerlayout Logical Volume Management (LVM) (Logische Volumeverwaltung) ein.
Es wird empfohlen, LVM für Volumes zu verwenden, die Daten- und Protokolldateien speichern. Im folgenden Beispiel wird davon ausgegangen, dass die VMs über vier angefügte Datenträger verfügen, die zum Erstellen von zwei Volumes verwendet werden.
Listen Sie alle verfügbaren Datenträger auf:
ls /dev/disk/azure/scsi1/lun*Beispielausgabe:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Erstellen Sie physische Volumes für alle Datenträger, die Sie verwenden möchten:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Erstellen Sie eine Volumegruppe für die Datendateien. Erstellen Sie eine Volumegruppe für Protokolldateien und eine für das freigegebene Verzeichnis von SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3Erstellen Sie die logischen Volumes. Ein lineares Volume wird erstellt, wenn Sie
lvcreateohne den Schalter-iverwenden. Für eine bessere E/A-Leistung wird empfohlen, ein Striped-Volume zu erstellen. Passen Sie die Stripe-Größen an die in SAP HANA VM-Speicherkonfigurationen dokumentierten Werte an. Das-i-Argument sollte die Anzahl der zugrunde liegenden physischen Volumes und das-I-Argument die Bereichsstreifengröße sein.In diesem Dokument werden zwei physische Volumes für das Datenvolume verwendet, daher wird das Argument für den Schalter
-iauf 2 festgelegt. Die Stripegröße für das Datenvolume beträgt 256 KiB. Für das Protokollvolume wird ein physisches Volume verwendet, sodass keine-i- oder-I-Schalter explizit für die Protokollvolumebefehle verwendet werden.Wichtig
Verwenden Sie den Schalter
-i, und ändern Sie die Zahl in die Anzahl der zugrunde liegenden physischen Volumes, wenn Sie für die einzelnen Daten-, Protokoll- oder freigegebenen Volumes mehrere physische Datenträger verwenden. Verwenden Sie den Schalter-I, um die Stripe-Größe anzugeben, wenn Sie ein Striping-Volume erstellen. Informationen zu empfohlenen Speicherkonfigurationen, einschließlich Stripegrößen und Anzahl der Datenträger, finden Sie unter SAP HANA VM-Speicherkonfigurationen. Die folgenden Layoutbeispiele erfüllen nicht unbedingt die Leistungsrichtlinien für eine bestimmte Systemgröße. Sie dienen nur zur Veranschaulichung.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedBinden Sie die Verzeichnisse nicht mithilfe von Bereitstellungsbefehlen ein. Geben Sie stattdessen die Konfigurationen in
fstabein, und geben Sie abschließendmount -aein, um die Syntax zu überprüfen. Erstellen Sie zunächst die Bereitstellungsverzeichnisse für jedes Volume:sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/sharedErstellen Sie als Nächstes
fstab-Einträge für die drei logischen Volumes, indem Sie die folgenden Zeilen in die Datei/etc/fstabeinfügen:/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
Binden Sie zum Schluss die neuen Volumes gleichzeitig ein:
sudo mount -a[A] Richten Sie die Hostnamensauflösung für alle Hosts ein.
Sie können entweder einen DNS-Server verwenden oder die Datei
/etc/hostsauf allen Knoten ändern, indem Sie wie folgt Einträge für alle Knoten in/etc/hostserstellen:10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Führen Sie die Konfiguration von RHEL für HANA aus.
Konfigurieren Sie RHEL wie in den folgenden Hinweisen beschrieben:
- 2447641 – Zusätzliche Pakete, die für die Installation SAP HANA SPS 12 unter RHEL 7.X erforderlich sind
- 2292690 – SAP HANA DB: Recommended OS Settings for RHEL 7 (2292690 – SAP HANA DB: Empfohlene Betriebssystemeinstellungen für RHEL 7)
- 2777782 – SAP HANA DB: Empfohlene Betriebssystemeinstellungen für RHEL 8
- 2455582 – Linux: Running SAP applications compiled with GCC 6.x (Linux – Ausführen von mit GCC 6.x kompilierten SAP-Anwendungen)
- 2593824 – Linux: Ausführen von mit GCC 7.x kompilierten SAP-Anwendungen
- 2886607 – Linux: Ausführen von mit GCC 9.x kompilierten SAP-Anwendungen
[A] Installieren Sie SAP HANA nach der Dokumentation von SAP.
[A] Konfigurieren Sie die Firewall.
Erstellen Sie die Firewallregel für den Testport von Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
Konfigurieren der SAP HANA 2.0-Systemreplikation
Für die Schritte in diesem Abschnitt werden die folgenden Präfixe verwendet:
- [A] : Der Schritt gilt für alle Knoten.
- [1] : Der Schritt gilt nur für den Knoten 1.
- [2] : Der Schritt gilt nur für den Knoten 2 des Pacemaker-Clusters.
[A] Konfigurieren Sie die Firewall.
Erstellen Sie Firewallregeln, um die HANA-Systemreplikation und Clientdatenverkehr zuzulassen. Die erforderlichen Ports finden Sie unter TCP/IP-Ports aller SAP-Produkte. Die folgenden Befehle sind nur ein Beispiel für die Genehmigung der HANA 2.0-Systemreplikation und des Clientdatenverkehrs zu den Datenbanken SYSTEMDB, HN1 und NW1.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] Erstellen Sie die Mandantendatenbank.
Führen Sie den folgenden Befehl als <hanasid>adm aus:
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] Konfigurieren Sie die Systemreplikation auf dem ersten Knoten.
Sichern Sie die Datenbanken als „<hanasid>adm“:
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"Kopieren Sie die PKI-Systemdateien auf den sekundären Standort:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Erstellen Sie den primären Standort:
hdbnsutil -sr_enable --name=SITE1[2] Konfigurieren Sie die Systemreplikation auf dem zweiten Knoten.
Registrieren Sie den zweiten Knoten zum Starten der Replikation. Führen Sie den folgenden Befehl als <hanasid>adm aus:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[2] Starten Sie HANA.
Führen Sie den folgenden Befehl als „<hanasid>adm“ aus, um HANA zu starten:
sapcontrol -nr 03 -function StartSystem[1] Überprüfen Sie den Replikationsstatus.
Überprüfen Sie den Replikationsstatus, und warten Sie, bis alle Datenbanken synchronisiert wurden. Wenn der Status weiterhin „Unbekannt“ lautet, überprüfen Sie die Firewalleinstellungen.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Erstellen eines Pacemaker-Clusters
Führen Sie die Schritte in Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure aus, um ein grundlegendes Pacemaker-Cluster für diesen HANA-Server zu erstellen.
Wichtig
Mit dem auf systemd basierenden SAP Startup Framework können SAP HANA-Instanzen jetzt von systemd verwaltet werden. Die mindestens erforderliche Red Hat Enterprise Linux(RHEL)-Version ist RHEL 8 für SAP. Wie in SAP-Hinweis 3189534 beschrieben, wird das SAP Startup Framework bei alle neuen Installationen von SAP HANA SPS07 Revision 70 oder höher sowie bei Updates von HANA-Systemen auf HANA 2.0 SPS07 Revision 70 oder höher automatisch bei systemd registriert.
Bei Verwendung von Hochverfügbarkeitslösungen zur Verwaltung der SAP HANA-Systemreplikation in Kombination mit systemd-fähigen SAP HANA-Instanzen (siehe SAP-Hinweis 3189534) sind zusätzliche Schritte erforderlich, um sicherzustellen, dass der Hochverfügbarkeitscluster die SAP-Instanz ohne Störungen durch systemd verwalten kann. Für ein mit systemd integriertes SAP HANA-System müssen Sie daher die zusätzlichen Schritte in Red Hat KBA 7029705 auf allen Clusterknoten ausführen.
Implementieren des SAP HANA-Systemreplikationshooks
Dieser wichtige Schritt optimiert die Integration in den Cluster und ermöglicht eine bessere Erkennung eines erforderlichen Clusterfailovers. Es ist obligatorisch für den richtigen Clusterbetrieb, den SAPHanaSR-Hook zu aktivieren. Es wird dringend empfohlen, sowohl SAPHanaSR- als auch ChkSrv-Python-Hooks zu konfigurieren.
[A] Installieren Sie die SAP HANA-Ressourcen-Agents auf allen Knoten. Achten Sie darauf, dass Sie ein Repository aktivieren, das das Paket enthält. Wenn Sie ein RHEL 8.x-Image oder höher mit Hochverfügbarkeit verwenden, müssen Sie keine weiteren Repositorys aktivieren.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo dnf install -y resource-agents-sap-hanaHinweis
Überprüfen Sie für RHEL 8.x und RHEL 9.x, ob das installierte resource-agents-sap-hana-Paket die Version 0.162.3-5 oder höher ist.
[A] Installieren Sie den HANA-
system replication hooks. Die Konfiguration für die Replikationshooks muss auf beiden HANA DB-Knoten installiert werden.Beenden Sie HANA auf beiden Knoten. Starten Sie die Ausführung als „<sid>adm“.
sapcontrol -nr 03 -function StopSystemPassen Sie die Datei
global.iniauf jedem Clusterknoten an.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/srHook execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR/srHook execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Wenn Sie den Parameter
pathauf den Standardspeicherort/usr/share/SAPHanaSR/srHookverweisen, wird der Code des Python-Hooks automatisch über Betriebssystemupdates oder Paketupdates aktualisiert. HANA verwendet beim nächsten Neustart die Codeupdates für den Hook. Bei einem optionalen eigenen Pfad wie/hana/shared/myHookskönnen Sie Betriebssystemupdates von der von HANA verwendeten Hook-Version entkoppeln.Sie können das Verhalten von
ChkSrvmithilfe desaction_on_lost-Parameters anpassen. Gültige Werte sind: [ignore|stop|kill].[A] Der Cluster erfordert die Konfiguration von
sudoersauf jedem Clusterknoten für „<sid>adm“. In diesem Beispiel wird dies durch das Erstellen einer neuen Datei erreicht. Verwenden Sie den Befehlvisudo, um die Drop-In-Datei20-saphanaalsrootzu bearbeiten.sudo visudo -f /etc/sudoers.d/20-saphanaFügen Sie die folgenden Zeilen ein, und speichern Sie dann Ihre Änderungen:
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] Starten Sie SAP HANA auf beiden Knoten. Starten Sie die Ausführung als „<sid>adm“.
sapcontrol -nr 03 -function StartSystem[1] Überprüfen Sie die Installation des SRHanaSR-Hooks. Starten Sie die Ausführung als „<sid>adm“ am aktiven HANA-Systemreplikationsstandort.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK[1] Überprüfen Sie die Installation des ChkSrv-Hooks. Starten Sie die Ausführung als „<sid>adm“ am aktiven HANA-Systemreplikationsstandort.
cdtrace tail -20 nameserver_chksrv.trc
Weitere Informationen zur Implementierung der SAP HANA-Hooks finden Sie unter Aktivieren des SAP HANA srConnectionChanged()-Hooks und Aktivieren des SAP HANA srServiceStateChanged()-Hooks für hdbindexserver-Prozessfehleraktion (optional).
Erstellen von SAP HANA-Clusterressourcen
Erstellen Sie die HANA-Topologie. Führen Sie die folgenden Befehle auf einem der Pacemaker-Clusterknoten aus. Achten Sie in diesen Anweisungen darauf, Ihre Werte für Instanznummer, HANA-System-ID, IP-Adressen und Systemnamen ggf. zu ersetzen.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
Erstellen Sie als Nächstes die HANA-Ressourcen.
Hinweis
In diesem Artikel wird ein Begriff verwendet, der von Microsoft nicht mehr genutzt wird. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Wenn Sie einen Cluster auf RHEL 7.x aufbauen, verwenden Sie die folgenden Befehle:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
Wenn Sie einen Cluster auf RHEL 8.x/9.x aufbauen, verwenden Sie die folgenden Befehle:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
Um priority-fencing-delay für SAP HANA (gilt nur für pacemaker-2.0.4-6.el8 oder höher) zu konfigurieren, müssen Sie die folgenden Befehle ausführen.
Hinweis
Wenn Sie über einen Cluster mit zwei Knoten verfügen, können Sie die Clustereigenschaft priority-fencing-delay konfigurieren. Diese Eigenschaft führt im Fall eines Split-Brain-Szenarios zu einer Verzögerung beim Umgrenzen eines Knotens mit einer höheren Gesamtressourcenpriorität. Weitere Informationen finden Sie unter Kann Pacemaker den Clusterknoten mit den wenigsten ausgeführten Ressourcen einfassen?.
Die Eigenschaft priority-fencing-delay gilt für Pacemaker-2.0.4-6.el8 Version oder höher. Wenn Sie priority-fencing-delay in einem vorhandenen Cluster einrichten, stellen Sie sicher, dass Sie die Option pcmk_delay_max auf dem Fencing-Gerät deaktivieren.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Wichtig
Es ist eine gute Idee, AUTOMATED_REGISTER auf false zu setzen, während Sie Failover-Tests durchführen, um zu verhindern, dass sich eine ausgefallene primäre Instanz automatisch als sekundäre registriert. Legen Sie nach dem Test am besten AUTOMATED_REGISTER auf true fest, damit die Systemreplikation nach der Übernahme automatisch fortgesetzt werden kann.
Stellen Sie sicher, dass der Clusterstatus „OK“ ist und alle Ressourcen gestartet wurden. Es ist nicht wichtig, auf welchem Knoten die Ressourcen ausgeführt werden.
Hinweis
Die Zeitüberschreitungen in der obigen Konfiguration sind nur Beispiele und müssen möglicherweise an das spezifische HANA-Setup angepasst werden. Sie müssen beispielsweise den Start-Timeout erhöhen, wenn es länger dauert, die SAP HANA-Datenbank zu starten.
Verwenden Sie den Befehl sudo pcs status, um den Status der erstellten Clusterressourcen zu überprüfen:
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Konfigurieren der HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“ in einem Pacemaker-Cluster
Ab SAP HANA 2.0 SPS 01 ermöglicht SAP Setups im Modus „Aktiv/Lesezugriff“ für die SAP HANA-Systemreplikation, bei denen die sekundären Systeme der SAP HANA-Systemreplikation aktiv für Workloads mit vielen Lesevorgängen verwendet werden können.
Zur Unterstützung eines solchen Setups in einem Cluster ist eine zweite virtuelle IP-Adresse erforderlich, mit der Clients auf die sekundäre SAP HANA-Datenbank mit aktivierten Lesevorgängen zugreifen können. Damit nach einer Übernahme weiterhin auf die sekundäre Replikationswebsite zugegriffen werden kann, muss der Cluster die virtuelle IP-Adresse zusammen mit der sekundären SAP HANA-Ressource verschieben.
In diesem Abschnitt werden die zusätzlichen Schritte beschrieben, die zum Verwalten der HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“ in einem Red Hat-Hochverfügbarkeitscluster mit einer zweiten virtuellen IP erforderlich sind.
Bevor Sie fortfahren, stellen Sie sicher, dass Sie den Red Hat-Hochverfügbarkeitscluster, der eine SAP HANA-Datenbank verwaltet, vollständig wie in den vorherigen Abschnitten der Dokumentation beschrieben konfiguriert haben.
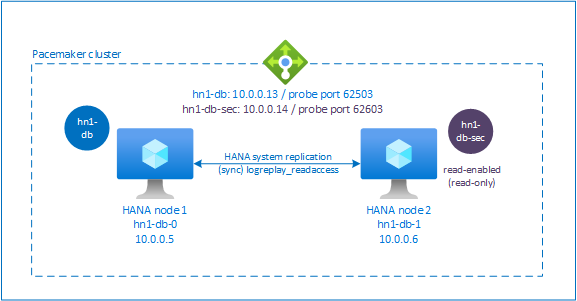
Zusätzliche Einrichtung in Azure Load Balancer für aktive/lesefähige Einrichtung
Um die zusätzlichen Schritte zum Bereitstellen der zweiten virtuellen IP-Adresse auszuführen, müssen Sie sicherstellen, dass Sie Azure Load Balancer wie im Abschnitt Manuelles Bereitstellen von Linux-VMs über das Azure-Portal beschrieben konfiguriert haben.
Für Load Balancer Standard führen Sie die folgenden Schritte in dem Lastenausgleich aus, den Sie im vorherigen Abschnitt erstellt haben.
a. Erstellen eines zweiten Front-End-IP-Pools:
- Öffnen Sie den Lastenausgleich, und wählen Sie den Front-End-IP-Pool und dann Hinzufügen aus.
- Geben Sie den Namen des zweiten Front-End-IP-Pools ein (z. B. hana-secondaryIP).
- Legen Sie Zuweisung auf Statisch fest, und geben Sie die IP-Adresse ein (z. B. 10.0.0.14).
- Klicken Sie auf OK.
- Notieren Sie nach Erstellen des neuen Front-End-IP-Pools dessen IP-Adresse.
b. Erstellen eines Integritätstests:
- Öffnen Sie den Lastenausgleich, und wählen Sie Integritätstests und dann Hinzufügen aus.
- Geben Sie den Namen des neuen Integritätstests ein (z. B. hana-secondaryhp).
- Wählen Sie TCP als Protokoll und den Port 62603 aus. Behalten Sie für das Intervall den Wert 5 und als Fehlerschwellenwert 2 bei.
- Klicken Sie auf OK.
c. Erstellen Sie die Lastenausgleichsregeln:
- Öffnen Sie den Lastenausgleich, und wählen Sie Lastenausgleichsregeln und dann Hinzufügen aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z. B. hana-secondarylb).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und die zuvor erstellte Integritätsprüfung aus (zum Beispiel hana-secondaryIP, hana-backend und hana-secondaryhp).
- Wählen Sie HA-Ports aus.
- Achten Sie darauf, dass Sie „Floating IP“ aktivieren.
- Klicken Sie auf OK.
Konfigurieren Sie die aktive/lesefähige Systemreplikation von HANA
Die Schritte zum Konfigurieren der HANA-Systemreplikation werden im Abschnitt Konfigurieren der SAP HANA 2.0-Systemreplikation beschrieben. Wenn Sie ein lesefähiges sekundäres Szenario einrichten, führen Sie während der Konfiguration der Systemreplikation auf dem zweiten Knoten den folgenden Befehl als „hanasidadm“ aus:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
Hinzufügen einer sekundären virtuellen IP-Adressressressressource für eine aktive/leseaktivierte Einrichtung
Die zweite virtuelle IP-Adresse und die geeignete Zusammenstellungseinschränkung können mit den folgenden Befehlen konfiguriert werden:
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
# Set the priority to primary IPaddr2 and azure-lb resource if priority-fencing-delay is configured
sudo pcs resource update vip_HN1_03 meta priority=5
sudo pcs resource update nc_HN1_03 meta priority=5
pcs property set maintenance-mode=false
Stellen Sie sicher, dass der Clusterstatus „OK“ ist und alle Ressourcen gestartet wurden. Die zweite virtuelle IP wird zusammen mit der sekundären SAPHana-Ressource am sekundären Standort ausgeführt.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Im nächsten Abschnitt finden Sie eine Reihe typischer Failover-Tests, die Sie durchführen können.
Beachten Sie beim Testen eines mit lesbarem sekundärem Replikat konfigurierten HANA-Clusters das Verhalten der zweiten virtuellen IP:
Wenn Sie die Clusterressource SAPHana_HN1_03 zum sekundären Standort hn1-db-1 migrieren, wird die zweite virtuelle IP weiterhin am gleichen Standort hn1-db-1 ausgeführt. Wenn Sie für die Ressource
AUTOMATED_REGISTER="true"festgelegt haben und die HANA-Systemreplikation automatisch an hn1-db-0 registriert wurde, wird Ihre zweite virtuelle IP ebenfalls an den Standort hn1-db-0 verschoben.Wenn Sie einen Serverabsturz testen, werden die zweite virtuelle IP-Ressource (secvip_HN1_03) und die Azure Load Balancer-Portressource (secnc_HN1_03) auf dem primären Server parallel zu den primären virtuellen IP-Ressourcen ausgeführt. Bis also der sekundäre Server ausgefallen ist, stellen die Anwendungen, die mit einer HANA-Datenbank mit Lesezugriff verbunden sind, eine Verbindung mit der primären HANA-Datenbank her. Dieses Verhalten wird erwartet, da Sie nicht möchten, dass auf Anwendungen, die mit einer HANA-Datenbank mit Lesezugriff verbunden sind, nicht zugegriffen werden kann, während der sekundäre Server nicht verfügbar ist.
Bei einem Failover und Fallback der zweiten virtuellen IP-Adresse kann es vorkommen, dass vorhandene Verbindungen mit Anwendungen unterbrochen werden, die für die Verbindung mit der HANA-Datenbank die zweite virtuelle IP verwenden.
Dieses Setup maximiert die Zeit, in der die zweite virtuelle IP-Ressource einem Knoten zugewiesen wird, auf dem eine fehlerfreie SAP HANA-Instanz ausgeführt wird.
Testen der Clustereinrichtung
In diesem Abschnitt wird beschrieben, wie Sie Ihre Einrichtung testen können. Bevor Sie den Test starten, stellen Sie sicher, dass Pacemaker keine fehlerhaften Aktionen enthält (mit „pcs status“), dass keine unerwarteten Standorteinschränkungen bestehen (z. B. durch zurückgebliebene Elemente vom Migrationstest) und dass HANA synchron ist (z. B. mit systemReplicationStatus).
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
Testen der Migration
Zustand der Ressource vor dem Starten des Tests:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Sie können den SAP HANA-Masterknoten migrieren, indem Sie den folgenden Befehl als root ausführen:
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
Dieses Cluster hat den SAP HANA-Masterknoten und die Gruppe migriert, die die virtuelle IP-Adresse zu hn1-db-1 enthält.
Nach Abschluss der Migration sieht die Ausgabe von sudo pcs status wie folgt aus:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Mit AUTOMATED_REGISTER="false" hat der Cluster die fehlerhafte HANA-Datenbank nicht neu gestartet oder sie für die neue primäre auf hn1-db-0 registriert. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl als hn1adm ausführen:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Die Migration erstellt Speicherorteinschränkungen, die erneut gelöscht werden müssen. Führen Sie den folgenden Befehl als root aus oder mit sudo aus:
pcs resource clear SAPHana_HN1_03-master
Überwachen Sie den Zustand der HANA-Ressource mithilfe von pcs status. Nachdem HANA auf hn1-db-0 gestartet wurde, sollte die Ausgabe wie folgt aussehen:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Blockieren der Netzwerkkommunikation
Zustand der Ressource vor dem Starten des Tests:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Führen Sie die Firewallregel aus, um die Kommunikation auf einem der Knoten zu blockieren.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Wenn Clusterknoten nicht miteinander kommunizieren können, besteht das Risiko eines Split-Brain-Szenarios. In solchen Situationen versuchen Clusterknoten, sich gleichzeitig zu umgrenzen, was ein Fence Race auslöst. Um eine solche Situation zu vermeiden, sollten Sie die priority-fencing-delay-Eigenschaft in der Clusterkonfiguration festlegen (gilt nur für pacemaker-2.0.4-6.el8 oder höher).
Durch Aktivieren der priority-fencing-delay-Eigenschaft fügt der Cluster eine Verzögerung in der Fencing-Aktion speziell für den Knoten hinzu, der die HANA-Masterressource hostet, sodass der Knoten das Fence Race gewinnen kann.
Führen Sie den folgenden Befehl aus, um die Firewallregel zu löschen:
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testen des Azure-Umgrenzungs-Agents
Hinweis
In diesem Artikel wird ein Begriff verwendet, der von Microsoft nicht mehr genutzt wird. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Zustand der Ressource vor dem Starten des Tests:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Sie können die Einrichtung des Azure-Umgrenzungs-Agent testen, indem Sie die Netzwerkschnittstelle auf dem Knoten deaktivieren, auf dem SAP HANA als Master ausgeführt wird. Im Red Hat-Knowledgebase-Artikel 79523 wird beschrieben, wie ein Netzwerkfehler simuliert wird.
In diesem Beispiel wird das net_breaker-Skript als root ausgefüht, um den gesamten Zugriff auf das Netzwerk zu blockieren:
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
Die VM sollte jetzt abhängig von Ihrer Clusterkonfiguration neu gestartet oder beendet werden.
Wenn Sie die stonith-action-Einstellung auf off festlegen, wird die VM beendet, und die Ressourcen werden zur ausgeführten VM migriert.
Wenn Sie die VM erneut starten, wird die SAP HANA-Ressource nicht als sekundär gestartet, wenn Sie AUTOMATED_REGISTER="false" festlegen. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl als hn1adm ausführen:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Wechseln Sie zurück zum Stamm, und bereinigen Sie den fehlerhaften Zustand:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Zustand der Ressource nach dem Test:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Testen eines manuellen Failovers
Zustand der Ressource vor dem Starten des Tests:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Sie können ein manuelles Failover testen, indem Sie den Cluster auf dem Knoten hn1-db-0 als root testen:
pcs cluster stop
Nach dem Failover können Sie den Cluster erneut starten. Wenn Sie AUTOMATED_REGISTER="false" festlegen, wird die SAP HANA-Ressource auf dem Knoten hn1-db-0 nicht als sekundär gestartet. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl als root ausführen:
pcs cluster start
Führen Sie Folgendes als hn1adm aus:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Führen anschließend als root Folgendes aus:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Zustand der Ressource nach dem Test:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1