Schnellstart: Vektorisieren von Text und Bildern mithilfe des Azure-Portals
Dieser Schnellstart hilft Ihnen bei den ersten Schritten mit der integrierten Vektorisierung mithilfe des Assistenten zum Importieren und Vektorisieren von Daten im Azure-Portal. Dieser Assistent teilt Ihren Inhalt auf und ruft ein Einbettungsmodell auf, um Inhalte während der Indizierung und für Abfragen zu vektorisieren.
Voraussetzungen
Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
Ein Dienst Azure KI-Suche in derselben Region wie Azure KI. Wir empfehlen den Tarif „Basic“ oder höher.
Eine unterstützte Datenquelle mit PDF-Beispieldokumenten für den Integritätsplan
Vertrautheit mit dem Assistenten. Weitere Informationen finden Sie unter Importieren von Daten-Assistenten im Azure-Portal.
Unterstützte Datenquellen
Der Assistent zum Importieren und Vektorisieren von Daten unterstützt eine Vielzahl von Azure-Datenquellen. Diese Schnellstartanleitung bietet jedoch nur Schritte für die Datenquellen, die mit ganzen Dateien arbeiten:
Azure Blob Storage für Blobs und Tabellen. Azure Storage muss ein Konto mit Standardleistung (universell v2) sein. Sie können die heiße oder kalte Zugriffsebene oder eine Zugriffsebene vom Typ „Cold“ verwenden.
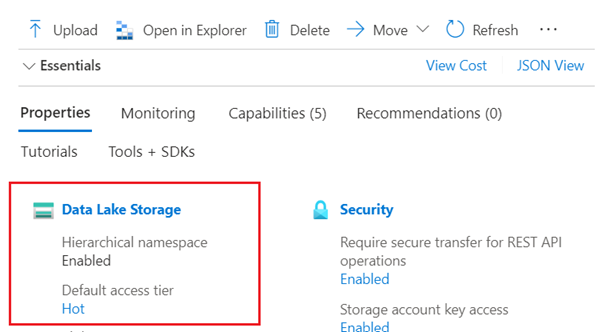
Azure Data Lake Storage (ADLS) Gen2 (ein Azure Storage-Konto mit einem aktivierten hierarchischen Namespace). Sie können bestätigen, dass Sie über Data Lake Storage verfügen, indem Sie die Registerkarte Eigenschaften auf der Seite Übersicht überprüfen.
Unterstützte Einbettungsmodelle
Verwenden Sie ein Einbettungsmodell auf einer Azure KI-Plattform in der gleichen Region wie Azure KI-Suche. Eine Bereitstellungsanleitung finden Sie in diesem Artikel.
| Anbieter | Unterstützte Modelle |
|---|---|
| Azure OpenAI Service | text-embedding-ada-002 text-embedding-3-large text-embedding-3-small |
| Modellkatalog von Azure KI Foundry | Für Text: Cohere-embed-v3-english Cohere-embed-v3-multilingual Für Bilder: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Azure KI Services mit mehreren Diensten | Multimodale Azure KI Vision-Instanz für die Bild- und Textvektorisierung, verfügbar in ausgewählten Regionen. Je nachdem, wie Sie die Multi-Service-Ressource anfügen, muss sich das Mehrdienstkonto möglicherweise in derselben Region wie Azure KI-Suche befinden. |
Wenn Sie den Azure OpenAI-Dienst verwenden, muss der Endpunkt über eine zugeordnete benutzerdefinierte Unterdomäne verfügen. Eine benutzerdefinierte Unterdomäne ist ein Endpunkt, der einen eindeutigen Namen enthält (z. B. https://hereismyuniquename.cognitiveservices.azure.com). Wenn der Dienst über das Azure-Portal erstellt wurde, wird diese Unterdomäne automatisch im Rahmen Ihres Dienstsetups generiert. Stellen Sie sicher, dass Ihr Dienst eine benutzerdefinierte Unterdomäne enthält, bevor Sie ihn mit der Integration der Azure KI-Suche verwenden.
In KI Foundry erstellte Azure OpenAI Service-Ressourcen (mit Zugriff auf Einbettungsmodelle) werden nicht unterstützt. Nur die im Azure-Portal erstellten Azure OpenAI Service-Ressourcen sind mit der Skillintegration Azure OpenAI-Einbettung kompatibel.
Anforderungen an öffentliche Endpunkte
Für diesen Schnellstart muss für alle vorherigen Ressourcen der öffentliche Zugriff aktiviert sein, damit die Azure-Portal-Knoten darauf zugreifen können. Andernfalls tritt im Assistenten ein Fehler auf. Sobald der Assistent ausgeführt wird, können Sie Firewalls und private Endpunkte für die Integrationskomponenten für die Sicherheit aktivieren. Weitere Informationen finden Sie unter Sichere Verbindungen in den Import-Assistenten.
Wenn private Endpunkte bereits vorhanden sind und Sie diese nicht deaktivieren können, besteht die alternative Option darin, den entsprechenden End-to-End-Flow von einem Skript oder Programm auf einer VM auszuführen. Die VM muss sich im selben virtuellen Netzwerk wie der private Endpunkt befinden. Hier ist ein Python-Codebeispiel für die integrierte Vektorisierung. Im gleichen GitHub-Repository gibt es Beispiele in anderen Programmiersprachen.
Berechtigungen
Sie können Schlüsselauthentifizierung und Vollzugriffsverbindungszeichenfolgen oder Microsoft Entra ID mit Rollenzuweisungen verwenden. Wir empfehlen Rollenzuweisungen für Suchdienstverbindungen mit anderen Ressourcen.
Aktivieren Sie Rollen in Azure KI-Suche.
Konfigurieren Sie Ihren Suchdienst für die Verwendung einer verwalteten Identität.
Erstellen Sie auf Ihrer Datenquellenplattform und beim Anbieter des Einbettungsmodells Rollenzuweisungen, mit denen der Suchdienst auf Daten und Modelle zugreifen kann. Der Abschnitt Aufbereiten von Beispieldaten bietet Anweisungen zum Einrichten von Rollen für jede unterstützte Datenquelle.
Ein kostenloser Suchdienst unterstützt rollenbasierte Verbindungen zu Azure KI-Suche, jedoch keine verwalteten Identitäten bei ausgehenden Verbindungen zu Azure Storage oder Azure KI Vision. Diese Ebene des Supports bedeutet, dass Sie die schlüsselbasierte Authentifizierung für Verbindungen zwischen einem kostenlosen Suchdienst und anderen Azure-Diensten verwenden müssen.
Für sicherere Verbindungen:
- Verwenden Sie den Tarif „Basic“ oder höher.
- Konfigurieren Sie eine verwaltete Identität, und verwenden Sie Rollen für den autorisierten Zugriff.
Hinweis
Wenn Sie den Assistenten nicht durchlaufen können, da Optionen nicht verfügbar sind (beispielsweise können Sie keine Datenquelle oder kein Einbettungsmodell auswählen), überprüfen Sie die Rollenzuweisungen. Fehlermeldungen deuten darauf hin, dass Modelle oder Bereitstellungen nicht vorhanden sind, obwohl die eigentliche Ursache darin besteht, dass der Suchdienst für sie über keine Zugriffsberechtigung verfügt.
Überprüfen des Speicherplatzes
Wenn Sie mit dem kostenlosen Dienst beginnen, können Sie maximal drei Indizes, Datenquellen, Skillsets und Indexer verwenden. Beim Basic-Tarif ist die Einschränkung auf 15 festgelegt. Stellen Sie sicher, dass Sie über ausreichend Platz für zusätzliche Elemente verfügen, bevor Sie beginnen. In diesem Schnellstart wird jeweils eines dieser Objekte erstellt.
Vorbereiten der Beispieldaten
Dieser Abschnitt verweist auf den Inhalt, der für diese Schnellstartanleitung funktioniert.
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an und wechseln Sie zu Ihrem Azure Storage-Konto.
Wählen Sie im linken Bereich unter Datenspeicher die Option Container aus.
Erstellen Sie einen neuen Container, und laden Sie dann die PDF-Dokumente für den Integritätsplan hoch, die für diese Schnellstartanleitung verwendet werden.
Weisen Sie im linken Bereich unter Zugriffssteuerung der Identität des Suchdiensts die Rolle Storage-Blobdatenleser zu. Oder rufen Sie eine Verbindungszeichenfolge mit dem Speicherkonto von der Access-Schlüsselseite ab.
Synchronisieren Sie optional die Löschvorgänge in Ihrem Container mit Löschvorgängen im Suchindex. Mit den folgenden Schritten können Sie den Indexer für die Löscherkennung konfigurieren:
Aktivieren Sie das vorläufige Löschen für Ihr Speicherkonto.
Wenn Sie das native vorläufige Löschen verwenden, sind keine weiteren Schritte in Azure Storage erforderlich.
Andernfalls fügen Sie benutzerdefinierte Metadaten hinzu, die ein Indexer überprüfen kann, um zu bestimmen, welche Blobs zum Löschen markiert sind. Weisen Sie Ihrer benutzerdefinierten Eigenschaft einen beschreibenden Namen zu. Sie können die Eigenschaft z. B. „IsDeleted“ nennen und auf FALSE festlegen. Führen Sie dies für jedes Blob im Container aus. Wenn Sie das Blob später löschen möchten, ändern Sie die Eigenschaft in „true“. Weitere Informationen finden Sie unter Änderungs- und Löscherkennung beim Indizieren von Azure Storage.
Einrichten von Einbettungsmodellen
Der Assistent kann Einbettungsmodelle verwenden, die aus Azure OpenAI, Azure KI Vision oder aus dem Modellkatalog im Azure KI Foundry-Portal bereitgestellt werden.
Der Assistent unterstützt die Modelle text-embedding-ada-002, text-embedding-3-large und text-embedding-3-small. Intern ruft der Assistent den Skill AzureOpenAIEmbedding auf, um eine Verbindung mit Azure OpenAI herzustellen.
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an und wechseln Sie zu Ihrer Azure OpenAI-Ressource.
Richten Sie Berechtigungen ein:
Wählen Sie im linken Menü Zugriffssteuerung aus.
Wählen Sie Hinzufügen und dann Rollenzuweisung hinzufügen aus.
Wählen Sie unter Stellenfunktionsrolle die Option Cognitive Services OpenAI-Benutzer und dann Weiter aus.
Wählen Sie unter Mitglieder die Option Verwaltete Identität und dann Mitglieder aus.
Filtern Sie nach Abonnement und Ressourcentyp (Suchdienste), und wählen Sie dann die verwaltete Identität Ihres Suchdiensts aus.
Wählen Sie Überprüfen und zuweisen aus.
Wählen Sie auf der Seite Übersicht die Option Klicken Sie hier, um Endpunkte anzuzeigen oder Klicken Sie hier, um Schlüssel zu verwalten aus, wenn Sie einen Endpunkt- oder API-Schlüssel kopieren müssen. Sie können diese Werte in den Assistenten einfügen, wenn Sie eine Azure OpenAI-Ressource mit schlüsselbasierter Authentifizierung verwenden.
Wählen Sie unter Ressourcenverwaltung und Modellbereitstellungen die Option Bereitstellungen verwalten aus, um Azure KI Foundry zu öffnen.
Kopieren Sie den Bereitstellungsnamen von
text-embedding-ada-002oder eines anderen unterstützten Einbettungsmodells. Wenn Sie kein Einbettungsmodell haben, stellen Sie jetzt eins bereit.
Starten des Assistenten
Melden Sie sich mit Ihrem Azure-Konto beim Azure Portal an und wechseln Sie zu Ihrem Azure AI Search-Dienst.
Wählen Sie auf der Seite Übersicht die Option Importieren und Vektorisieren von Daten aus.

Herstellen einer Verbindung mit Ihren Daten
Der nächste Schritt besteht darin, eine Verbindung mit einer Datenquelle herzustellen, die für den Suchindex verwendet werden soll.
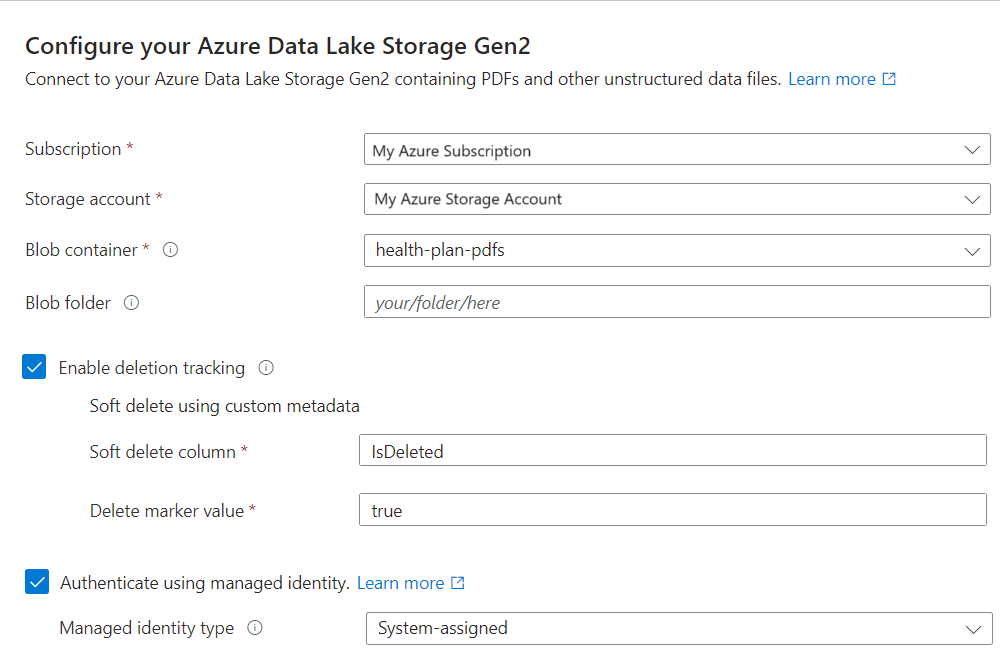
Wählen Sie auf Verbindung mit Ihren Daten herstellen Azure Blob Storage aus.
Geben Sie das Azure-Abonnement an.
Wählen Sie das Speicherkonto und den Container aus, die die Daten bereitstellen.
Geben Sie an, ob Löscherkennung unterstützt werden soll. Bei nachfolgenden Indizierungsläufen wird der Suchindex aktualisiert, um alle Suchdokumente basierend auf vorläufig gelöschten Blobs in Azure Storage zu entfernen.
- Blobs unterstützen entweder das native vorläufige Löschen von Blobs oder das vorläufige Löschen mit benutzerdefinierten Daten.
- Sie müssen zuvor die Option für das vorläufige Löschen in Azure Storage aktiviert haben und optional benutzerdefinierte Metadaten hinzugefügt haben, die die Indizierung als Löschkennzeichnung erkennen kann. Weitere Informationen zu diesen Schritten finden Sie unter Vorbereiten der Beispieldaten.
- Wenn Sie Ihre Blobs für das vorläufige Löschen mit benutzerdefinierten Daten konfiguriert haben, geben Sie in diesem Schritt das Name/Wert-Paar für die Metadateneigenschaft an. Wir empfehlen „IsDeleted“. Wenn „IsDeleted“ für ein Blob auf „true“ festgelegt ist, übergeht der Indexer das entsprechende Suchdokument bei der nächsten Indexerausführung.
Der Assistent überprüft Azure Storage nicht auf gültige Einstellungen, und er löst keinen Fehler aus, wenn die Anforderungen nicht erfüllt sind. Stattdessen funktioniert die Löscherkennung nicht, und Ihr Suchindex sammelt im Laufe der Zeit wahrscheinlich verwaiste Dokumente.
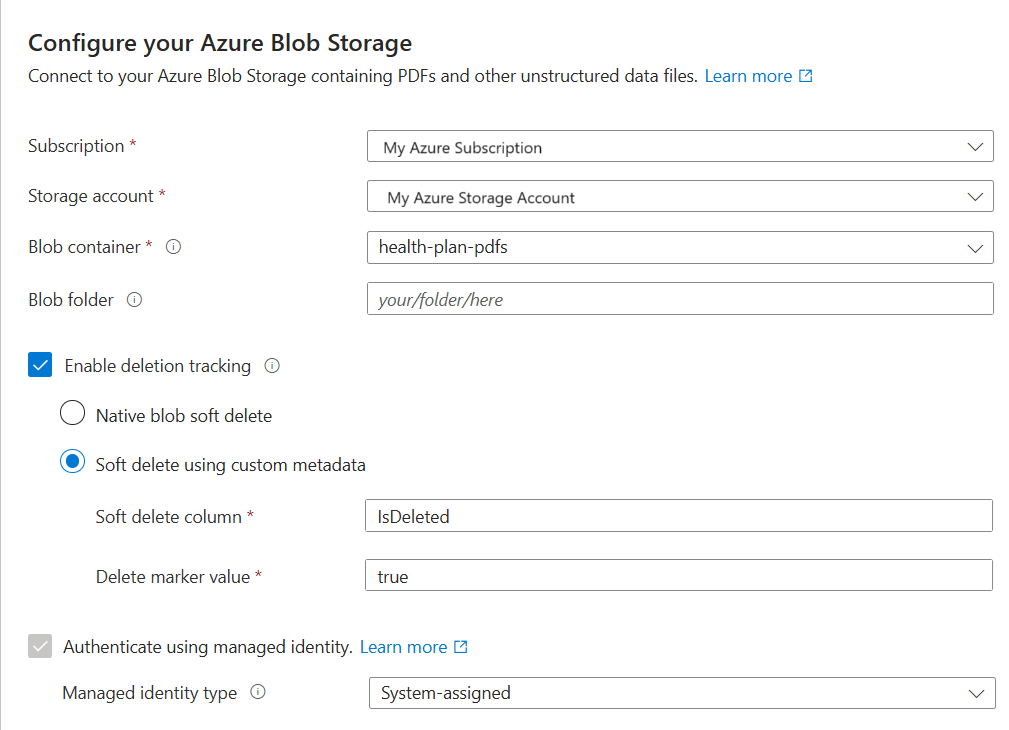
Geben Sie an, ob Ihr Suchdienst mithilfe seiner verwalteten Identität eine Verbindung mit Azure Storage herstellen soll.
- Sie werden dazu aufgefordert, eine systemseitig oder kundenseitig verwaltete Identität auszuwählen.
- Die Identität sollte in Azure Storage über die Rolle Storage-Blobdatenleser verfügen.
- Überspringen Sie diesen Schritt nicht. Während der Indizierung tritt ein Verbindungsfehler auf, wenn der Assistent keine Verbindung mit Azure Storage herstellen kann.
Wählen Sie Weiter aus.
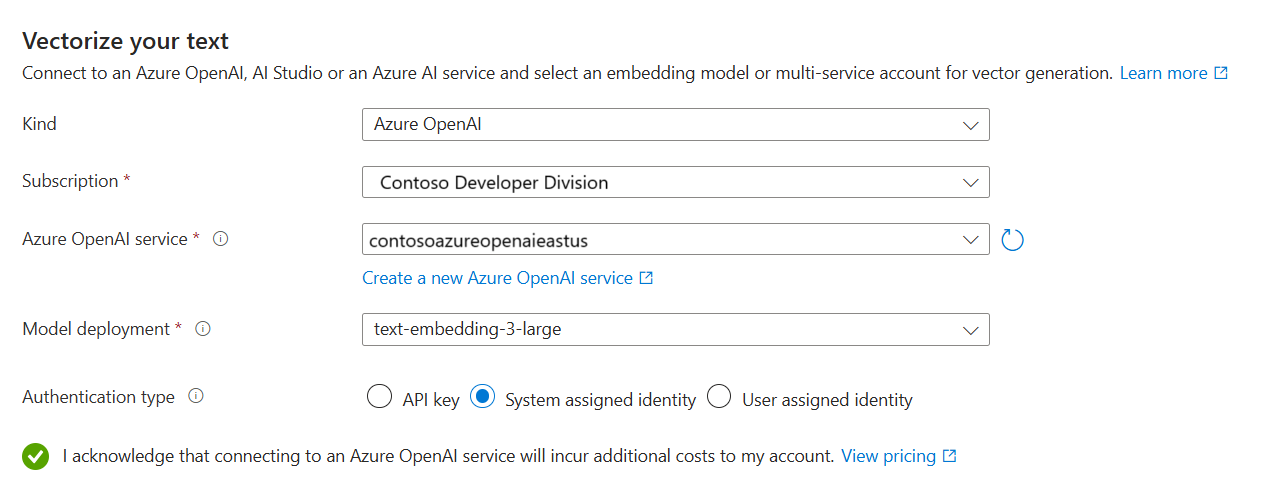
Vektorisieren Ihres Texts
Geben Sie in diesem Schritt das Einbettungsmodell für die Vektorisierung der in Blöcke aufgeteilten Daten an.
Eine Segmentierung ist integriert und kann nicht konfiguriert werden. Die effektiven Einstellungen sind:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
Wählen Sie auf der Seite Ihren Text vektorisieren die Quelle des Einbettungsmodells aus:
- Azure OpenAI
- Modellkatalog von Azure KI Foundry
- Eine vorhandene multimodale Azure KI Vision-Ressource in derselben Region wie Azure KI-Suche. Sollte kein Azure KI Services-Konto mit mehreren Diensten in derselben Region vorhanden sein, ist diese Option nicht verfügbar.
Wählen Sie das Azure-Abonnement.
Treffen Sie die Auswahlen entsprechend der Ressource:
Wählen Sie für Azure OpenAI eine vorhandene Bereitstellung von text-embedding-ada-002, text-embedding-3-large oder text-embedding-3-small aus.
Wählen Sie für den KI Foundry-Katalog eine vorhandene Bereitstellung eines Azure- oder Cohere-Einbettungsmodells aus.
Wählen Sie für multimodale KI Vision-Einbettungen das Konto aus.
Weitere Informationen finden Sie weiter oben in diesem Artikel unter Einrichten von Einbettungsmodellen.
Geben Sie an, ob sich Ihr Suchdienst mithilfe eines API-Schlüssels oder einer verwalteten Identität authentifizieren soll.
- Die Identität sollte für das Azure KI-Konto mit mehreren Diensten über die Rolle Cognitive Services OpenAI-Benutzer verfügen.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
Wählen Sie Weiter aus.
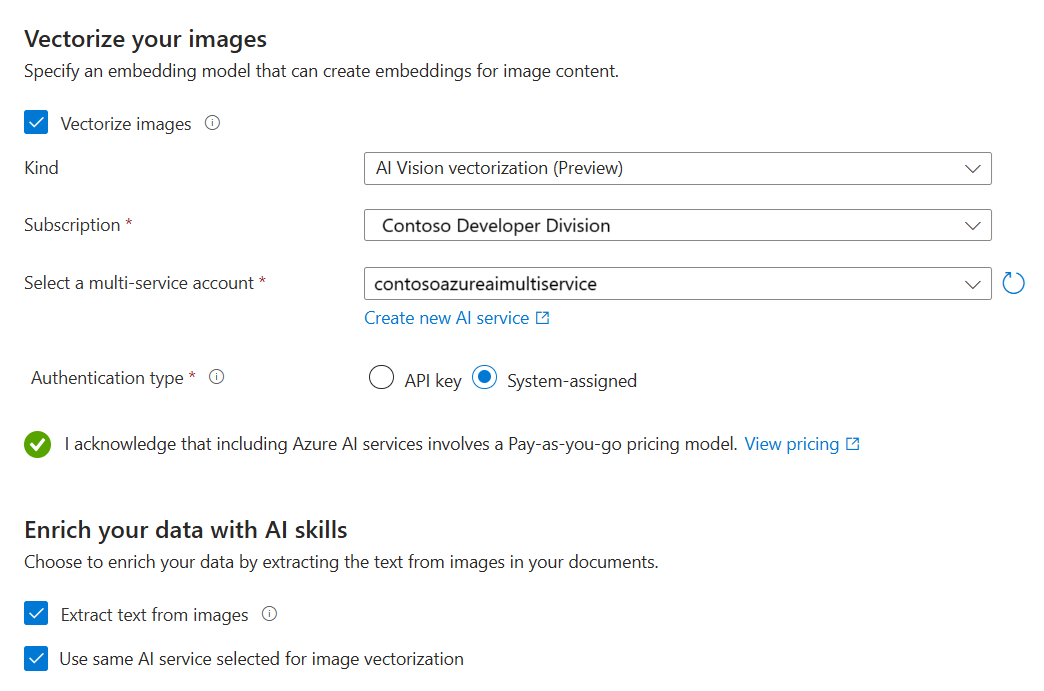
Vektorisieren und Anreichern Ihrer Bilder
Die PDFs für den Integritätsplan enthalten ein Unternehmenslogo, aber darüber hinaus keine weiteren Bilder. Sie können diesen Schritt überspringen, wenn Sie die Beispieldokumente verwenden.
Wenn Sie jedoch mit Inhalten arbeiten, die hilfreiche Bilder enthalten, können Sie KI auf zwei Arten anwenden:
Verwenden Sie ein unterstütztes Bildeinbettungsmodell aus dem Katalog, oder wählen Sie die Azure KI Vision-API für multimodale Einbettungen aus, um Bilder zu vektorisieren.
Verwenden Sie die optische Zeichenerkennung (Optical Character Recognition, OCR), um Text in Bildern zu erkennen. Diese Option ruft den Skill OCR zum Lesen von Text aus Bildern auf.
Azure KI-Suche und Ihre Azure KI-Ressource müssen sich in derselben Region befinden oder für schlüssellose Abrechnungsverbindungen konfiguriert sein.
Geben Sie auf der Seite Vektorisieren Ihrer Bilder die Art der Verbindung an, die der Assistent erstellen soll. Für die Bildvektorisierung kann der Assistent eine Verbindung mit Einbettungsmodellen im Azure KI Foundry-Portal oder in Azure KI Vision herstellen.
Geben Sie das Abonnement an.
Geben Sie für den Azure KI Foundry-Modellkatalog das Projekt und die Bereitstellung an. Weitere Informationen finden Sie weiter oben in diesem Artikel unter Einrichten von Einbettungsmodellen.
Optional können Sie binäre Bilder (z. B. gescannte Dokumentdateien) knacken und OCR verwenden, um Text zu erkennen.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
Wählen Sie Weiter aus.
Hinzufügen der Zuweisung einer semantischen Rangfolge
Auf der Seite Erweiterte Einstellungen können Sie optional eine semantische Rangfolge hinzufügen, um die Ergebnisse am Ende der Abfrageausführung erneut zu rangieren. Die erneute Rangierung verschiebt die semantisch relevantesten Übereinstimmungen nach oben.
Zuordnen neuer Felder
Wichtige Informationen zu diesem Schritt:
- Das Indexschema bietet Vektor- und Nichtvektorfelder für aufgeteilte Daten.
- Sie können Felder hinzufügen, aber keine generierten Felder löschen oder ändern.
- Der Modus „Dokumentanalyse“ erstellt Blöcke (ein Suchdokument pro Block).
Auf der Seite Erweiterte Einstellungen können Sie optional neue Felder hinzufügen, sofern die Datenquelle Metadaten oder Felder bereitstellt, die beim ersten Durchlauf nicht erfasst wurden. Standardmäßig generiert der Assistent die folgenden Felder mit diesen Attributen:
| Feld | Gilt für: | Beschreibung |
|---|---|---|
| chunk_id | Text- und Bildvektoren | Generiertes Zeichenfolgenfeld. Durchsuchbar, abrufbar, sortierbar. Dies ist der Dokumentschlüssel für den Index. |
| text_parent_id | Textvektoren | Generiertes Zeichenfolgenfeld. Abrufbar, filterbar. Gibt das übergeordnete Dokument an, aus dem der Block stammt. |
| Block | Text- und Bildvektoren | Zeichenfolgenfeld. Eine für Menschen lesbare Version des Datenblocks. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
| title | Text- und Bildvektoren | Zeichenfolgenfeld. Lesbarer Dokumenttitel oder Seitentitel oder Seitenzahl. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
| text_vector | Textvektoren | Collection(Edm.single). Vektordarstellung des Blocks. Durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar. |
Sie können die generierten Felder oder deren Attribute nicht ändern, aber Sie können neue Felder hinzufügen, wenn ihre Datenquelle sie bereitstellt. Beispielsweise stellt Azure Blob Storage eine Sammlung von Metadatenfeldern bereit.
Wählen Sie Neue hinzufügen aus.
Wählen Sie ein Quellfeld aus der Liste der verfügbaren Felder aus, geben Sie einen Feldnamen für den Index ein, und übernehmen Sie den Standarddatentyp, oder überschreiben Sie Ihn nach Bedarf.
Metadatenfelder sind durchsuchbar und abrufbar, aber nicht filterbar, facettierbar oder sortierbar.
Wählen Sie Zurücksetzen aus, wenn Sie das Schema auf die ursprüngliche Version wiederherstellen möchten.
Planen der Indizierung
Auf der Seite Erweiterte Einstellungen können Sie optional einen Ausführungszeitplan für den Indexer angeben.
- Wählen Sie Weiter aus, wenn Sie mit der Seite Erweiterte Einstellungen fertig sind.
Beenden Sie den Assistenten.
Geben Sie auf der Seite Überprüfen Ihrer Konfiguration ein Präfix für die Objekte an, die der Assistent erstellt. Ein allgemeines Präfix hilft Ihnen, den Überblick zu behalten.
Klicken Sie auf Erstellen.
Wenn der Assistent die Konfiguration abschließt, erstellt er die folgenden Objekte:
Datenquellenverbindung
Index mit Vektorfeldern, Vektorisierern, Vektorprofilen, Vektoralgorithmen. Sie können den Standardindex während des Assistentenworkflows nicht entwerfen oder ändern. Indizes entsprechen der REST-API „2024-05-01-preview“.
Skillset mit dem Skill „Textaufteilung“ für die Blockerstellung und dem Skill „Einbettung“ für die Vektorisierung. Der Skill „Einbettung“ ist entweder der AzureOpenAIEmbeddingModel-Skill für Azure OpenAI oder der AML-Skill für den Azure KI Foundry-Modellkatalog. Das Skillset verfügt außerdem über die Indexprojektionen-Konfiguration, mit der Daten aus einem Dokument in der Datenquelle den entsprechenden Blöcken in einem untergeordneten Index zugeordnet werden können.
Indexer mit Feldzuordnungen und Ausgabefeldzuordnungen (falls zutreffend).
Überprüfen der Ergebnisse
Der Suchexplorer akzeptiert Textzeichenfolgen als Eingabe und vektorisiert dann den Text für die Ausführung von Vektorabfragen.
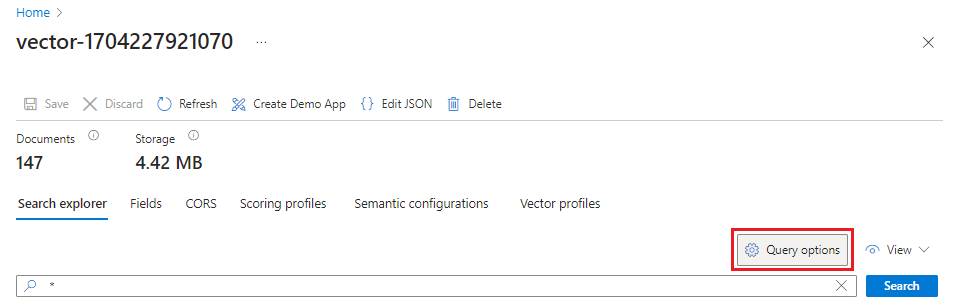
Wechseln Sie im Azure-Portal zu Suchverwaltung>Indizes, und wählen Sie dann den von Ihnen erstellten Index aus.
Wählen Sie Abfrageoptionen aus, und blenden Sie Vektorwerte in den Suchergebnissen aus. Durch diesen Schritt werden die Suchergebnisse übersichtlicher.
Wählen Sie im Menü Ansicht die JSON-Ansicht aus, damit Sie Text für Ihre Vektorabfrage im Vektorabfrageparameter
texteingeben können.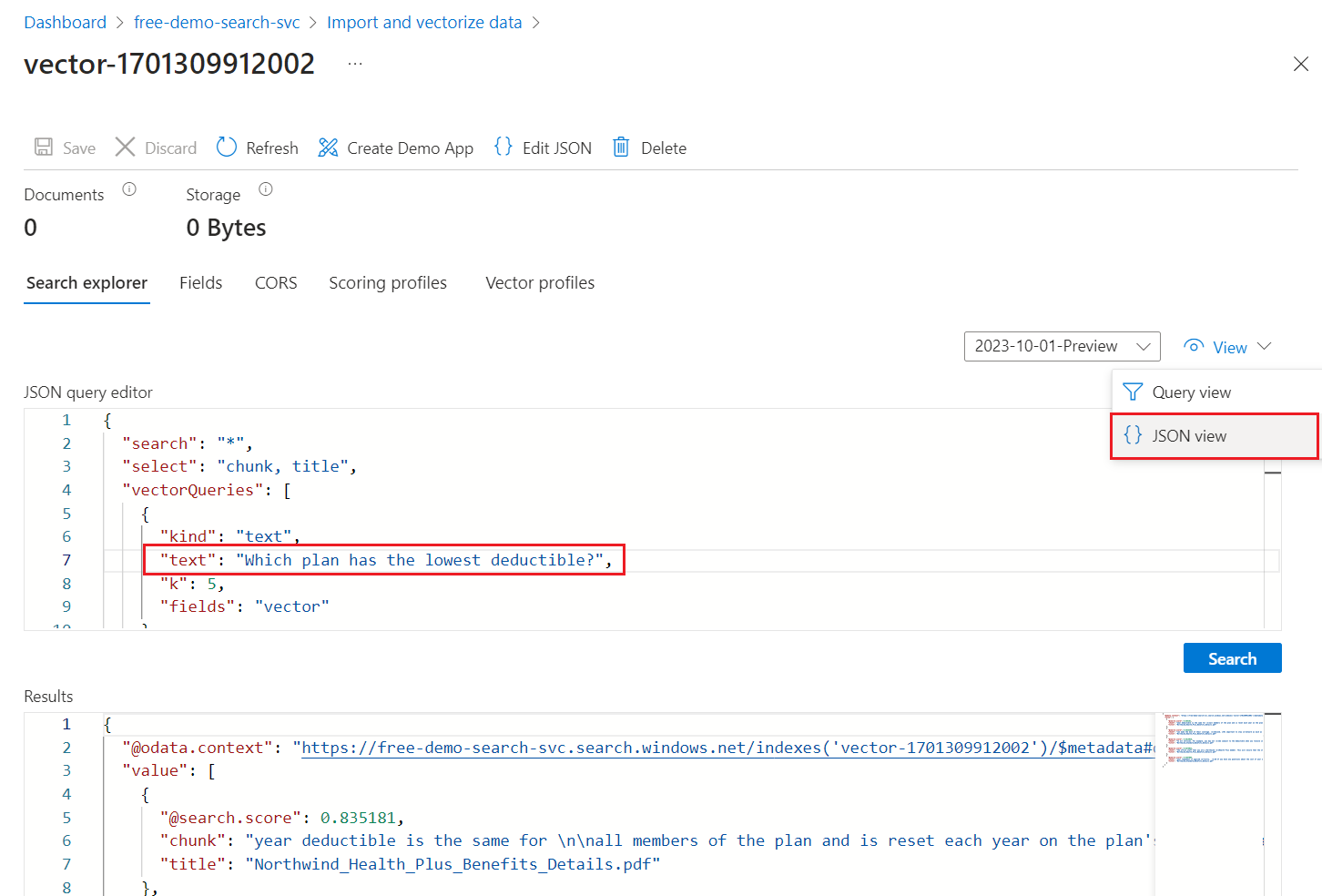
Die Standardabfrage ist eine leere Suche (
"*"), die jedoch Parameter für das Zurückgeben der Anzahl von Übereinstimmungen enthält. Es handelt sich um eine Hybridabfrage, die Text- und Vektorabfragen parallel ausführt. Sie umfasst eine semantische Sortierung. Es gibt an, welche Felder in den Ergebnissen derselect-Anweisung zurückgegeben werden sollen.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Ersetzen Sie beide Sternchenplatzhalter (
*) durch eine Frage im Zusammenhang mit Integritätsplänen, z. B.Which plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Wählen Sie Suchen aus, um die Abfrage auszuführen.
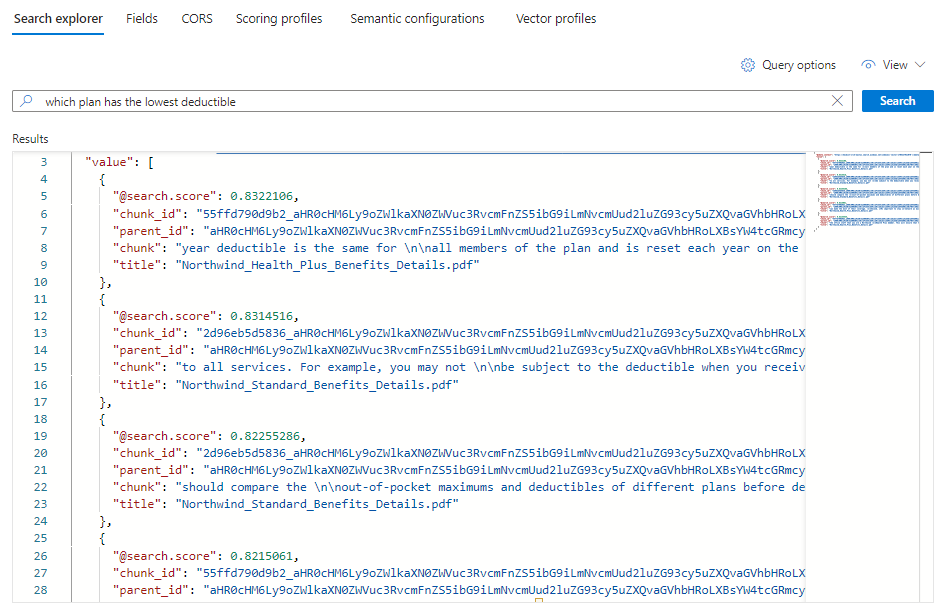
Jedes Dokument ist ein Block der ursprünglichen PDF-Datei. Das Feld
titlezeigt an, aus welcher PDF-Datei der Block stammt. Jederchunkist relativ lang. Sie können einen kopieren und in einen Text-Editor einfügen, um den gesamten Wert zu lesen.Um alle Blöcke aus einem bestimmten Dokument anzuzeigen, fügen Sie einen Filter für das Feld
title_parent_idfür eine bestimmte PDF-Datei hinzu. Auf der Registerkarte Felder Ihres Index können Sie überprüfen, ob dieses Feld gefiltert werden kann.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Bereinigung
Azure AI Search ist eine abrechenbare Ressource. Wenn Sie dies nicht mehr benötigen, löschen Sie es aus Ihrem Abonnement, um Gebühren zu vermeiden.
Nächster Schritt
In diesem Schnellstart haben Sie den Assistenten zum Importieren und Vektorisieren von Daten kennengelernt, der alle für die integrierte Vektorisierung erforderlichen Objekte erstellt. Wenn Sie jeden Schritt im Detail untersuchen möchten, probieren Sie eines der integrierten Vektorisierungsbeispiele aus.