Indexer in Azure KI Search
Ein Indexer in Azure KI Search ist ein Crawler, der durchsuchbare Inhalte aus Clouddatenquellen extrahiert und einen Suchindex mithilfe von Feld-zu-Feld-Zuordnungen zwischen Quelldaten und einen Suchindex auffüllt. Dieser Ansatz wird auch als „Pullmodell“ bezeichnet, weil der Suchdienst Daten abruft, ohne dass Sie Code schreiben müssen, der einem Index Daten hinzufügt.
Indexer fördern auch die Skillsetausführung und die KI-Anreicherung, wo Sie Skills konfigurieren können, um zusätzliche Verarbeitung von Inhalten zu integrieren, die an einen Index weitergeleitet werden. Einige Beispiele sind OCR über Bilddateien, Textaufteilungsskills für Datenblöcke und das Aufrufen von Einbettungsmodellen zum Generieren von Vektoren für die Vektorsuche.
Indexer zielen auf unterstützte Datenquellenab. Eine Indexerkonfiguration gibt eine Datenquelle (Ursprung) und einen Suchindex (Ziel) an. Bei einigen Quellen wie Azure Blob Storage gibt es mehrere Indexierkonfigurationseigenschaften speziell für diesen Inhaltstyp.
Sie können Indexer bei Bedarf oder nach einem Zeitplan für die regelmäßige Datenaktualisierung ausführen (z. B. alle fünf Minuten). Häufigere Updates schließen die Verwendung von Indexern aus, sodass Sie ein Pushmodell implementieren müssen, das Daten zur Datensynchronisierung gleichzeitig an Azure KI-Suche und Ihre externe Datenquelle überträgt.
Ein Suchdienst führt einen Indexerauftrag pro Sucheinheit aus. Wenn Sie die gleichzeitige Verarbeitung benötigen, stellen Sie sicher, dass Sie über ausreichende Replikate verfügen. Indexer werden nicht im Hintergrund ausgeführt, sodass Sie möglicherweise eine höhere Abfragedrosselung erkennen als üblich, wenn der Dienst stark ausgelastet ist.
Indexerszenarien und Anwendungsfälle
Sie können einen Indexer als alleiniges Mittel für die Datenerfassung oder in Kombination mit anderen Techniken verwenden. In der folgenden Tabelle werden die Hauptszenarios zusammengefasst.
| Szenario | Strategie |
|---|---|
| Einzelne Datenquelle | Dieses Muster ist das einfachste: eine einzige Datenquelle ist der einzige Inhaltsanbieter für einen Suchindex. Die meisten unterstützten Datenquellen bieten eine Form der Änderungserkennung, sodass nachfolgende Indexerausführungen den Unterschied übernehmen, wenn Inhalte in der Quelle hinzugefügt oder aktualisiert werden. |
| Mehrere Datenquellen | Eine Indexerspezifikation kann nur eine einzige Datenquelle haben, aber der Suchindex selbst kann Inhalte aus mehreren Quellen akzeptieren, wobei jeder Indexerauftrag neue Inhalte von einem anderen Datenanbieter liefert. Jede Quelle kann ihren Anteil an vollständigen Dokumenten beitragen oder ausgewählte Felder in jedem Dokument auffüllen. Einen genaueren Blick auf dieses Szenario finden Sie unter Tutorial: Indizieren von mehreren Datenquellen mithilfe des .NET SDK. |
| Mehrere Indexer | Mehrere Datenquellen werden in der Regel mit mehreren Indexern gekoppelt, wenn Sie Laufzeitparameter, den Zeitplan oder Feldzuordnungen anpassen müssen. Regionübergreifendes Aufskalieren von Azure KI-Suche ist eine Variation dieses Szenarios. Es kann sein, dass sich mehrere Kopien des gleichen Suchindex in unterschiedlichen Regionen befinden. Zum Synchronisieren des Suchindexinhalts können mehrere Indexer vorhanden sein, die Daten aus derselben Datenquelle pullen und in jeder Region jeweils einen anderen Suchindex als Ziel verwenden. Für die parallele Indizierung besonders großer Datasets ist ebenfalls eine Strategie mit mehreren Indexern erforderlich, wobei jedem Indexer eine Teilmenge der Daten zugeordnet ist. |
| Inhaltstransformation | Indexer fördern die Skillsetausführung und die KI-Anreicherung. Inhaltstransformationen werden in einem Skillset definiert, das Sie dem Indexer anfügen. Mithilfe von Skills können Sie Datensegmentierung und Vektorisierung implementieren. |
Sie sollten jeweils einen Indexer pro Kombination aus Zielindex und Datenquelle erstellen. Sie können mehrere Indexer erstellen, die in denselben Index schreiben, und dieselbe Datenquelle für mehrere Indexer verwenden. Ein Indexer kann jedoch jeweils nur eine Datenquelle auf einmal nutzen und nur in einen einzelnen Index schreiben. Wie die folgende Abbildung veranschaulicht, bietet eine Datenquelle die Eingabe für einen Indexer, der dann einen einzelnen Index füllt:

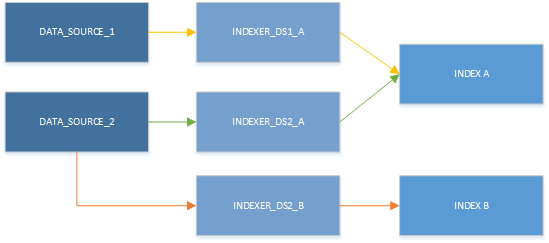
Obwohl Sie zurzeit nur einen Indexer verwenden können, ist es möglich, Ressourcen in verschiedenen Kombinationen zu verwenden. Die wichtigsten Informationen in der nächsten Abbildung sind die Tatsachen, dass eine Datenquelle mit mehreren Indexern gekoppelt werden kann, während mehrere Indexer in denselben Index schreiben können.
Unterstützte Datenquellen
Die Indexer durchforsten die Datenspeicher in und außerhalb von Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL-Datenbank
- Azure Table Storage
- Verwaltete Azure SQL-Datenbank-Instanz
- SQL Server auf virtuellen Azure-Computern
- Azure Files (in der Vorschau)
- Azure MySQL (in der Vorschau)
- SharePoint in Microsoft 365 (Vorschau)
- Azure Cosmos DB for MongoDB (Vorschau)
- Azure Cosmos DB for Apache Gremlin (Vorschau)
Azure Cosmos DB für Cassandra wird nicht unterstützt.
Indexer akzeptieren flache Zeilensätze, z. B. eine Tabelle oder Ansicht, oder Elemente in einem Container oder Ordner. In den meisten Fällen wird ein Suchdokument pro Zeile, Datensatz oder Element erstellt.
Indexerverbindungen mit Remotedatenquellen können über Internetstandardverbindungen (öffentlich) oder über verschlüsselte private Verbindungen hergestellt werden, sofern Sie eine freigegebene private Verbindung nutzen. Sie können auch Verbindungen mit Authentifizierung über eine verwaltete Identität einrichten. Weitere Informationen zu sicheren Verbindungen finden Sie unter Indexerzugriff auf Datenquellen mit Azure-Netzwerksicherheitsfeatures und Herstellen einer Verbindung zu einer Datenquelle mithilfe einer verwalteten Identität.
Phasen der Indizierung
Bei einer anfänglichen Ausführung, bei der der Index leer ist, liest ein Indexer alle Daten, die in der Tabelle oder im Container bereitgestellt werden. Bei nachfolgenden Ausführungen kann der Indexer in der Regel nur die geänderten Daten erkennen und abrufen. Bei Blobdaten erfolgt die Änderungserkennung automatisch. Bei anderen Datenquellen wie Azure SQL oder Azure Cosmos DB muss die Änderungserkennung aktiviert sein.
Für jedes empfangene Dokument implementiert oder koordiniert der Indexer mehrere Schritte – vom Abrufen des Dokuments bis hin zur Übergabe an eine Suchmaschine für die Indizierung. Optional initiiert ein Indexer auch Skillsetausführungen und -ausgaben, vorausgesetzt, dass ein Skillset definiert ist.

Phase 1: Dokumentriss
Dokumententschlüsselung ist der Vorgang des Öffnens von Dateien und des Extrahierens von Inhalt. Textbasierte Inhalte können aus Dateien in einem Dienst, Zeilen in einer Tabelle oder Elementen in Containern oder Sammlungen extrahiert werden. Wenn Sie einem Indexer ein Skillset und Bildanalyseskills hinzufügen, kann die Dokumententschlüsselung auch Bilder extrahieren und zur Verarbeitung in die Warteschlange einreihen.
Abhängig von der Datenquelle führt der Indexer verschiedene Vorgänge aus, um potenziell indizierbare Inhalte zu extrahieren:
Wenn das Dokument eine Datei mit eingebetteten Bildern ist, wie z. B. eine PDF, extrahiert der Indexer Text, Bilder und Metadaten. Indexer können Dateien aus Azure Blob Storage, Azure Data Lake Storage Gen2 und SharePoint öffnen.
Wenn es sich bei dem Dokument um einen Datensatz in Azure SQL handelt, extrahiert der Indexer die nicht binären Inhalte aus jedem Feld in jedem Datensatz.
Handelt es sich bei dem Dokument um einen Datensatz in Azure Cosmos DB, extrahiert der Indexer die nicht binären Inhalte aus Feldern und Unterfeldern des Azure Cosmos DB-Dokuments.
Phase 2: Feldzuordnungen
Ein Indexer extrahiert Text aus einem Quellfeld und sendet ihn an ein Zielfeld in einem Index oder Wissensspeicher. Wenn Feldnamen und -typen übereinstimmen, ist der Pfad klar. Möglicherweise möchten Sie aber unterschiedliche Namen oder Typen in der Ausgabe, in welchem Fall Sie dem Indexer mitteilen müssen, wie das Feld zugeordnet werden soll.
Um Feldzuordnungen anzugeben,geben Sie die Quell- und Zielfelder in die Indexerdefinition ein.
Dieser Schritt erfolgt nach der Dokumententschlüsselung, aber vor Transformationen, wenn der Indexer aus den Quelldokumenten liest. Wenn Sie eine Feldzuordnung definieren, wird der Wert des Quellfelds unverändert an das Zielfeld gesendet.
Phase 3: Skillset-Ausführung
Skillset-Ausführung ist ein optionaler Schritt, der die integrierte oder benutzerdefinierte KI-Verarbeitung aufruft. Skillsets können optische Zeichenerkennung (OCR) oder andere Formen der Bildanalyse hinzufügen, wenn der Inhalt binär ist. Darüber hinaus können Skillsets natürliche Sprachverarbeitung hinzufügen. Beispielsweise können Sie Textübersetzung oder Schlüsselbegriffserkennung hinzufügen.
Wie auch immer die Transformation aussieht, die Skillset-Ausführung ist der Zeitpunkt, an dem eine Anreicherung erfolgt. Wenn ein Indexer eine Pipeline ist, können Sie sich einen Skillset als „Pipeline innerhalb der Pipeline“ vorstellen.
Phase 4: Ausgabefeldzuordnungen
Wenn Sie ein Skillset einbeziehen, müssen Sie Ausgabefeldzuordnungen in der Indexerdefinition angeben. Die Ausgabe eines Skillsets wird intern als Struktur manifestiert, die als angereichertes Dokumentbezeichnet wird. Mithilfe von Ausgabefeldzuordnungen können Sie auswählen, welche Teile dieser Struktur Feldern in Ihrem Index zugeordnet werden sollen.
Trotz der Ähnlichkeit bei Namen erstellen Ausgabefeldzuordnungen und Feldzuordnungen Zuordnungen aus verschiedenen Quellen. Feldzuordnungen ordnen den Inhalt des Quellfelds einem Zielfeld in einem Suchindex zu. Ausgabefeld-Zuordnungen ordnen den Inhalt eines internen angereicherten Dokuments (Skill-Outputs) den Zielfeldern im Index zu. Anders als bei Feldzuordnungen, die als optional gelten, wird für jeden transformierten Inhalt, der Teil des Indexes sein soll, eine Ausgabefeldzuordnung benötigt.
Die nächste Abbildung zeigt eine Beispieldarstellung einer Indexer-Debugsitzungder Indexerphasen: Dokumententschlüsselung, Feldzuordnungen, Skillset-Ausführung und Ausgabefeldzuordnungen.

Grundlegender -Workflow
Indexer können Features bereitstellen, die für die Datenquelle eindeutig sind. In dieser Hinsicht variieren einige Aspekte von Indexern oder der Datenquellenkonfiguration nach Indexertyp. Für alle Indexer werden aber die gleiche grundlegende Zusammenstellung und die gleichen Anforderungen verwendet. Die Schritte, die für alle Indexer gelten, sind unten beschrieben.
Schritt 1: Erstellen einer Datenquelle
Indexer benötigen ein Datenquellenobjekt mit einer Verbindungszeichenfolge und ggf. Anmeldeinformationen. Datenquellen sind unabhängige Objekte. Mehrere Indexer können dasselbe Datenquellenobjekt verwenden, um mehrere Indizes gleichzeitig zu laden.
Sie können eine Datenquelle mit einem der folgenden Ansätze erstellen:
- Wählen Sie im Azure-Portal auf der Registerkarte Datenquellen der Seiten Ihrer Suchdienste Datenquelle hinzufügen aus, um die Datenquellendefinition anzugeben.
- Im Azure-Portal gibt der Datenimport-Assistent eine Datenquelle aus.
- Wenn Sie REST-APIs nutzen, rufen Sie Datenquelle erstellen auf.
- Im Azure SDK für .NET rufen Sie die SearchIndexerDataSourceConnection-Klasse auf
Schritt 2: Erstellen eines Index
Mit einem Indexer werden einige Aufgaben in Bezug auf die Datenerfassung automatisiert, aber das Erstellen eines Index gehört im Allgemeinen nicht dazu. Als Voraussetzung müssen Sie über einen vordefinierten Index verfügen, der entsprechende Zielfelder für alle Quellfelder in Ihrer externen Datenquelle enthält. Felder müssen nach Name und Datentyp übereinstimmen. Andernfalls können Sie Feldzuordnungen definieren, um die Zuordnung einzurichten.
Weitere Informationen finden Sie unter Erstellen eines Index.
Schritt 3: Erstellen und Ausführen (oder Planen) des Indexers
Eine Indexerdefinition besteht aus Eigenschaften, die den Indexer eindeutig identifizieren, angeben, welche Datenquelle und welcher Index verwendet werden sollen, und weitere Konfigurationsoptionen mit Einfluss auf das Laufzeitverhalten bieten, etwa ob der Indexer bei Bedarf oder nach einem Zeitplan ausgeführt wird.
Fehler oder Warnungen zu Datenzugriffs- oder Skillsetprüfungen treten während der Indexerausführung auf. Bis zum Start der Indexerausführung sind abhängige Objekte wie Datenquellen, Indizes und Skillsets im Suchdienst inaktiv.
Weitere Informationen finden Sie unter Erstellen eines Indexers
Sie können einen Indexer nach der ersten Ausführung bei Bedarf erneut ausführen oder einen Zeitplan einrichten.
Sie können den Indexerstatus im Azure-Portal oder über die API zum Abrufen des Indexer-Status überwachen. Sie sollten auch Abfragen für den Index ausführen, um zu überprüfen, ob das Ergebnis Ihren Erwartungen entspricht.
Indexer verfügen nicht über dedizierte Verarbeitungsressourcen. Daher kann es sein, dass der Status des Indexers als im Leerlauf angezeigt wird, ehe er ausgeführt wird (abhängig von anderen Aufträgen in der Warteschlange), und dass Laufzeiten nicht vorhersehbar sind. Auch andere Faktoren bestimmen die Leistung des Indexers, wie z. B. Größe und Komplexität des Dokuments und Bildanalyse.
Nächste Schritte
Nach dieser Einführung können Sie sich als Nächstes mit Indexereigenschaften und -parametern sowie mit der Planung und Überwachung von Indexern vertraut machen. Alternativ können Sie zur Liste mit den unterstützten Datenquellen zurückkehren und sich ausführlicher über eine bestimmte Quelle informieren.