Tipps für eine bessere Leistung in Azure KI Search
Dieser Artikel enthält eine Sammlung von Tipps und bewährten Methoden zum Erhöhen der Abfrage- und Indizierungsleistung für die Stichwortsuche. Wenn Sie wissen, durch welche Faktoren die Suchleistung am wahrscheinlichsten beeinträchtigt wird, können Sie Ineffizienzen besser vermeiden und Ihren Suchdienst optimal nutzen. Zu den Schlüsselfaktoren zählen unter anderem folgende:
- Indexzusammensetzung (Schema und Größe)
- Abfragedesign
- Dienstkapazität (Tarif sowie Anzahl von Replikaten und Partitionen)
Hinweis
Suchen Sie nach Strategien für die Indizierung großer Datenmengen? Siehe Indizieren großer Datasets in Azure KII Search.
Indexgröße und Schema
Abfragen sind mit kleineren Indizes schneller. Das liegt zum einen daran, dass weniger Felder überprüft werden müssen, hängt aber auch damit zusammen, wie Inhalte für zukünftige Abfragen zwischengespeichert werden. Nach der ersten Abfrage bleibt ein Teil des Inhalts im Arbeitsspeicher, wo er effizienter durchsucht werden kann. Da der Index in der Regel im Laufe der Zeit immer größer wird, empfiehlt es sich, die Indexzusammensetzung (Schema und Dokumente) regelmäßig auf Möglichkeiten zur Inhaltsreduzierung zu überprüfen. Ist der Index ordnungsgemäß dimensioniert, haben Sie nur noch die Möglichkeit, die Kapazität zu erhöhen, indem Sie entweder Replikate hinzufügen oder die Dienstebene upgraden. Der Abschnitt Tipp: Upgraden Sie auf einen Tarif vom Typ „Standard S2“ behandelt die Entscheidung zwischen Hochskalieren und Aufskalieren.
Die Schemakomplexität kann sich ebenfalls negativ auf Indizierung und Abfrageleistung auswirken. Übermäßige Feldzuordnungen führen zu Einschränkungen und Verarbeitungsanforderungen. Bei komplexen Typen dauern Indizierung und Abfragen länger. In den nächsten Abschnitten wird auf die einzelnen Bedingungen eingegangen.
Tipp: Nutzen Sie Feldzuordnungen mit Bedacht.
Administratoren und Entwickler machen bei der Suchindexerstellung häufig den Fehler, alle verfügbaren Eigenschaften für die Felder zu verwenden, anstatt nur die tatsächlich benötigten Eigenschaften auszuwählen. Muss ein Feld beispielsweise nicht für die Volltextsuche verfügbar sein, lassen Sie dieses Feld aus, wenn Sie das Attribut für die Durchsuchbarkeit festlegen.
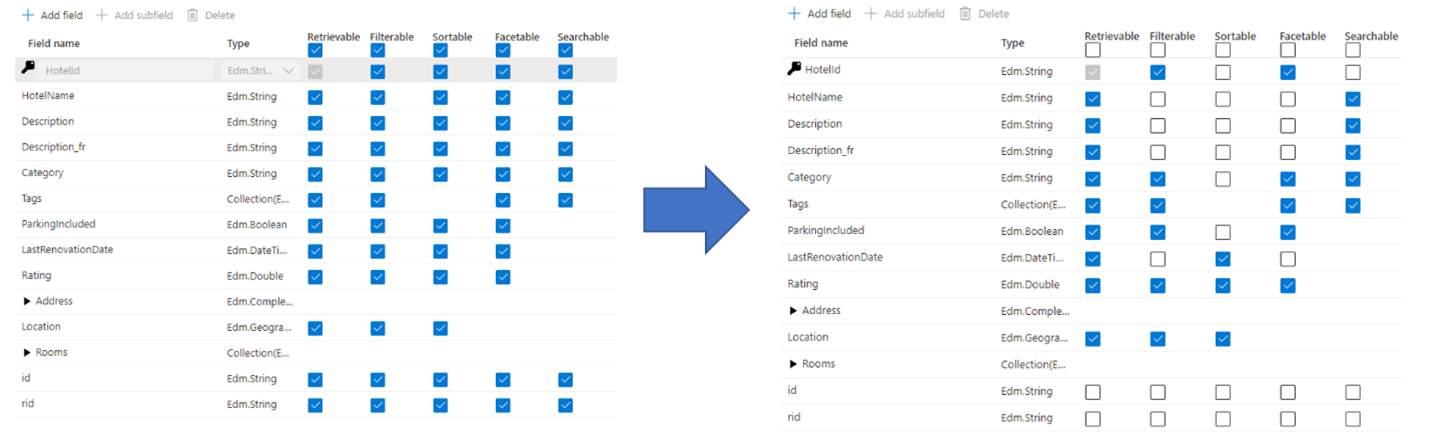
Durch die Unterstützung von Filtern, Facetten und Sortierung können sich die Speicheranforderungen vervierfachen. Mit Vorschlagsfunktionen erhöhen sich die Speicheranforderungen sogar noch weiter. Die Auswirkungen von Attributen auf den Speicher werden unter Attribute und Indexgröße (Auswirkungen auf den Speicher) veranschaulicht.
Zusammengefasst führen übermäßige Zuordnungen unter anderem zu Folgendem:
Sie beeinträchtigen die Indizierungsleistung aufgrund des Zusatzaufwands, der erforderlich ist, um den Inhalt des Felds zu verarbeiten und anschließend im invertierten Suchindex zu speichern. (Legen Sie das Attribut „searchable“ nur für Felder fest, die durchsuchbaren Inhalt enthalten.)
Sie sorgt dafür, dass bei jeder Abfrage ein größerer Bereich abgedeckt werden muss. Alle als durchsuchbar markierten Felder werden in einer Volltextsuche überprüft.
Sie erhöht die Betriebskosten durch zusätzlichen Speicherbedarf. Zum Filtern und Sortieren wird zusätzlicher Speicherplatz für ursprüngliche (nicht analysierte) Zeichenfolgen benötigt. Legen Sie „filterable“ und „sortable“ möglichst nicht für Felder fest, die diese Attribute nicht benötigen.
In vielen Fällen werden durch übermäßige Zuordnungen die Funktionen des Felds eingeschränkt. Wenn ein Feld beispielsweise facettenreich, filterbar und durchsuchbar ist, können darin nur 16 KB an Text gespeichert werden. Ein durchsuchbares Feld kann dagegen bis zu 16 MB an Text enthalten.
Hinweis
Unnötige Zuordnungen sollten zwar vermieden werden, Filter und Facetten sind jedoch häufig für die Suche wichtig. Außerdem ist in Fällen, in denen Filter verwendet werden, häufig auch eine Sortierung der Ergebnisse erforderlich. (Beim Filtern allein werden die Ergebnisse unsortiert zurückgegeben.)
Tipp: Erwägen Sie Alternativen zu komplexen Typen.
Komplexe Datentypen sind bei Daten mit einer komplizierten geschachtelten Struktur nützlich – also etwa bei den über- und untergeordneten Elementen in JSON-Dokumenten. Der Nachteil komplexer Typen (im Vergleich zu nicht komplexen Datentypen) besteht in den zusätzlichen Speicheranforderungen und zusätzlichen Ressourcen, die für die Indizierung des Inhalts erforderlich sind.
In bestimmten Fällen lassen sich diese Nachteile vermeiden, indem Sie eine komplexe Datenstruktur einem einfacheren Feldtyp (beispielsweise einer Sammlung) zuordnen. Alternativ können Sie ggf. eine Feldhierarchie vereinfachen und stattdessen einzelne Felder auf Stammebene verwenden.

Abfragedesign
Komposition und Komplexität der Abfrage gehören zu den wichtigsten Faktoren für die Leistung, und durch die Optimierung der Abfrage lässt sich die Leistung erheblich verbessern. Berücksichtigen Sie beim Entwerfen von Abfragen die folgenden Punkte:
Anzahl durchsuchbarer Felder: Jedes zusätzliche durchsuchbare Feld führt zu mehr Arbeit für den Suchdienst. Die zur Abfragezeit durchsuchten Felder können mithilfe des Parameters „searchFields“ eingeschränkt werden. Zur Verbesserung der Leistung empfiehlt es sich, nur die wirklich relevanten Felder anzugeben.
Menge der zurückgegebenen Daten: Das Abrufen großer Inhaltsmengen kann zur Verlangsamung von Abfragen führen. Achten Sie beim Strukturieren einer Abfrage darauf, dass nur Felder zurückgegeben werden, die auf der Ergebnisseite gerendert werden sollen, und rufen Sie die verbleibenden Felder mithilfe der Lookup-API ab, wenn ein Benutzer einen Treffer auswählt.
Suche nach Teilausdrücken: Die Suche nach Teilausdrücken (z. B. Präfixsuche, Fuzzysuche und Suche mit regulären Ausdrücken) ist rechenintensiver als eine typische Schlüsselwortsuche, da sie eine vollständige Indexüberprüfung erfordert, um Ergebnisse zu generieren.
Anzahl von Facetten: Das Hinzufügen von Facetten zu Abfragen erfordert Aggregationen für jede Abfrage. Das Anfordern einer höheren Anzahl von Facetten führt auch zu einem höheren Verarbeitungsaufwand für Ihren Dienst. Fügen Sie im Allgemeinen nur die Facetten hinzu, die Sie in Ihrer App rendern möchten, und fordern Sie nur dann eine hohe Anzahl von Facetten an, wenn dies erforderlich ist.
Hohe $skip-Werte: Das Festlegen des
$skip-Parameters auf einen hohen Wert (z. B. im Tausenderbereich) erhöht die Suchlatenz, da die Engine für jede Anforderung eine größere Anzahl von Dokumenten abruft und nach Rang sortiert. Aus Leistungsgründen sollten hohe$skip-Werte vermieden und stattdessen andere Techniken wie z. B. eine Filterung verwendet werden, um eine große Anzahl von Dokumenten abzurufen.Begrenzen von Feldern mit hoher Kardinalität: Ein Feld mit hoher Kardinalität ist ein Feld, in dem Facetten oder Filter verwendet werden können und das eine beträchtliche Anzahl von eindeutigen Werten besitzt. Daher werden bei der Berechnung von Ergebnissen erhebliche Ressourcen beansprucht. Wenn Sie z. B. ein Feld mit einer Produkt-ID oder einer Beschreibung als facettenreich und filterbar einrichten, ist die Kardinalität hoch, da die meisten Werte von Dokument zu Dokument eindeutig sind.
Tipp: Verwenden Sie Suchfunktionen, anstatt Filterkriterien zu überladen.
Bei einer Abfrage mit zunehmend komplexen Filterkriterien verschlechtert sich die Leistung der Suchabfrage. Im folgenden Beispiel wird die Verwendung von Filtern veranschaulicht, um Ergebnisse basierend auf einer Benutzeridentität einzuschränken:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
In diesem Fall werden die Filterausdrücke verwendet, um zu überprüfen, ob ein einzelnes Feld in jedem Dokument einem von zahlreichen möglichen Werten einer Benutzeridentität entspricht. Dieses Muster wird in erster Linie in Anwendungen mit Einschränkungen aus Sicherheitsgründen verwendet. Bei diesen Einschränkungen wird ein Feld, das eine oder mehrere Prinzipal-IDs enthält, mit einer Liste von Prinzipal-IDs verglichen, die den Benutzer darstellen, von dem die Abfrage stammt.
Eine effizientere Möglichkeit zum Ausführen von Filtern mit einer großen Anzahl von Werten ist die Verwendung der Funktion search.in, wie im folgenden Beispiel zu sehen:
search.in(userid, '123,234,345,456,567', ',')
Tipp: Fügen Sie Partitionen für langsame Einzelabfragen hinzu.
Eine allgemeine Verschlechterung der Abfrageleistung lässt sich häufig durch Hinzufügen weiterer Replikate beheben. Doch was ist, wenn das Problem auf eine einzelne Abfrage zurückzuführen ist, die zu lange dauert? In diesem Fall hilft es nicht, weitere Replikate hinzuzufügen. Weitere Partitionen können jedoch hilfreich sein. Eine Partition teilt Daten auf zusätzliche Computeressourcen auf. Zwei Partitionen halbieren die Daten, eine dritte Partition führt zu einer Aufteilung in drei Teile und so weiter.
Ein positiver Nebeneffekt zusätzlicher Partitionen ist, dass langsamere Abfragen aufgrund der parallelen Datenverarbeitung manchmal schneller durchgeführt werden. Wir haben eine Parallelisierung bei Abfragen mit geringer Selektivität festgestellt, z. B. Abfragen, die vielen Dokumenten entsprechen, oder Facetten, bei denen Zählungen über eine große Anzahl von Dokumenten erfolgen. Da für die Bewertung der Relevanz von Dokumenten oder die Ermittlung der Anzahl von Dokumenten eine umfassende Berechnung erforderlich ist, können durch das Hinzufügen weiterer Partitionen Abfragen schneller abgeschlossen werden.
Partitionen können über das Azure-Portal, mithilfe von PowerShell, über die Azure CLI oder mithilfe eines Verwaltungs-SDK hinzugefügt werden.
Dienstkapazität
Ein Dienst wird überlastet, wenn Abfragen zu lange dauern oder wenn der Dienst mit dem Löschen von Anforderungen beginnt. In diesem Fall können Sie das Problem behandeln, indem Sie den Dienst upgraden oder Kapazität hinzufügen.
Der Tarif Ihres Suchdiensts und die Anzahl von Replikaten/Partitionen haben ebenfalls großen Einfluss auf die Leistung. Jeder progressiv höhere Tarif bietet schnellere CPUs und mehr Arbeitsspeicher, was sich jeweils positiv auf die Leistung auswirkt.
Tipp: Erstellen Sie einen neuen Suchdienst mit hoher Kapazität
Grundlegende und Standarddienste, die nach dem 3. April 2024 in unterstützten Regionen erstellt wurden, verfügen über mehr Speicher pro Partition als ältere Dienste. Bevor Sie eine Aktualisierung auf eine höhere Ebene und eine höhere abrechnende Rate durchführen, überprüfen Sie die Dienstebenen-Grenzwerte, um festzustellen, ob Ihnen die gleiche Ebene in einem neueren Dienst den erforderlichen Speicher bietet.
Tipp: Upgraden Sie auf einen Tarif vom Typ „Standard S2“.
Kunden starten häufig mit dem Suchtarif „Standard S1“. Ein gängiges Muster bei S1-Diensten ist die Zunahme der Indexgröße im Laufe der Zeit, was mehr Partitionen erfordert. Mehr Partitionen führen zu langsameren Antworten, woraufhin mehr Replikate hinzugefügt werden, um die Abfragelast zu bewältigen. Wie Sie sich vorstellen können, sind die Betriebskosten für einen S1-Dienst nun weit von den Kosten der anfänglichen Konfiguration entfernt.
An diesem Punkt stellt sich die wichtige Frage, ob es sich möglicherweise lohnt, zu einem höheren Tarif zu wechseln, anstatt immer wieder die Anzahl der Partitionen oder Replikate des aktuellen Diensts zu erhöhen.
Sehen Sie sich die folgende Topologie als Beispiel für einen Dienst an, dessen Kapazität immer weiter erhöht wurde:
- Tarif „Standard S1“
- Indexgröße: 190 GB
- Partitionsanzahl: 8 (bei S1 beträgt die Partitionsgröße 25 GB pro Partition)
- Replikatanzahl: 2
- Sucheinheiten gesamt: 16 (8 Partitionen · 2 Replikate)
- Hypothetischer Einzelhandelspreis: ~4.000 USD/Monat (bei angenommenen 250 USD · 16 Sucheinheiten)
Angenommen, der Dienstadministrator beobachtet immer noch höhere Latenzraten und erwägt das Hinzufügen eines weiteren Replikats. Dadurch würde sich die Replikatanzahl von zwei auf drei und die Anzahl von Sucheinheiten auf 24 erhöhen, was einen Preis von 6.000 USD/Monat zur Folge hätte.
Entscheidet sich der Administrator dagegen für den Wechsel zu einem Tarif vom Typ „Standard S2“, sieht die Topologie wie folgt aus:
- Tarif „Standard S2“
- Indexgröße: 190 GB
- Partitionsanzahl: 2 (bei S2 beträgt die Partitionsgröße 100 GB pro Partition)
- Replikatanzahl: 2
- Sucheinheiten gesamt: 4 (2 Partitionen · 2 Replikate)
- Hypothetischer Einzelhandelspreis: ~4.000 USD/Monat (1.000 USD · 4 Sucheinheiten)
Dieses hypothetische Szenario zeigt, dass Konfigurationen mit niedrigeren Tarifen durchaus ähnliche Kosten verursachen können wie Szenarien, in denen von Anfang an ein höherer Tarif verwendet wird. Bei höheren Tarifen profitieren Sie jedoch von Premium-Speicher und somit von einer schnelleren Indizierung. In höheren Tarifen stehen zudem wesentlich mehr Rechenleistung sowie zusätzlicher Arbeitsspeicher zur Verfügung. Für die gleichen Kosten können Sie also eine leistungsfähigere Infrastruktur für den gleichen Index erhalten.
Ein wichtiger Vorteil von zusätzlichem Arbeitsspeicher besteht darin, dass ein größerer Teil des Index zwischengespeichert werden kann, was zu einer niedrigeren Suchlatenz und zu einer höheren Anzahl von Abfragen pro Sekunde führt. Mit dieser zusätzlichen Leistung muss der Administrator unter Umständen nicht einmal die Replikatanzahl erhöhen und zahlt ggf. sogar weniger als bei weiterer Verwendung des S1-Diensts.
Tipp: Erwägen Sie Alternativen zu Abfragen regulärer Ausdrücke
Abfragen regulärer Ausdrücke oder regex können besonders teuer sein. Obwohl sie für erweiterte Suchvorgänge sehr nützlich sein können, kann die Ausführung eine Menge Verarbeitungsleistung erfordern, insbesondere wenn der reguläre Ausdruck komplex ist oder wenn eine große Menge an Daten durchsucht wird. All diese Faktoren tragen zu einer hohen Suchlatenz bei. Versuchen Sie zur Entschärfung, den regulären Ausdruck zu vereinfachen oder die komplexe Abfrage in kleinere, besser verwaltbare Abfragen aufzuteilen.
Nächste Schritte
Die folgenden Artikel enthalten weitere Informationen zur Leistung des Diensts:
- Leistung analysieren
- Indizieren großer Datasets in Azure KI Search
- Auswählen eines Tarifs für die kognitive Azure-Suche
- Planen oder Hinzufügen von Kapazität
- Case Study: Use Cognitive Search to Support Complex AI Scenarios (Fallstudie: Verwenden von Cognitive Search zur Unterstützung komplexer KI-Szenarien)