Tutorial: Indizieren großer Datenmengen aus Apache Spark mithilfe von SynapseML und Azure KI Search
In diesem Azure KI Search-Tutorial erfahren Sie, wie Sie große Datenmengen, die aus einem Spark-Cluster geladen wurden, indizieren und abfragen. Richten Sie ein Jupyter Notebook ein, das die folgenden Aktionen ausführt:
- Laden Sie verschiedene Formulare (Rechnungen) in einen Datenrahmen in einer Apache Spark-Sitzung
- Analysieren sie, um ihre Eigenschaften zu bestimmen
- Zusammenführen der resultierenden Ausgabe in eine tabellarische Datenstruktur
- Schreiben der Ausgabe in einen in Azure KI Search gehosteten Suchindex
- Erkunden und Abfragen der von Ihnen erstellten Inhalte
Dieses Tutorial basiert auf SynapseML, einer Open-Source-Bibliothek, die massiv paralleles maschinelles Lernen über Big Data unterstützt. In SynapseML werden Suchindizierungen und maschinelles Lernen durch Transformatoren verfügbar gemacht, die spezielle Aufgaben ausführen. Transformatoren nutzen eine breite Palette von KI-Funktionen. Verwenden Sie in dieser Übung die AzureSearchWriter-APIs für die Analyse und KI-Anreicherung.
Obwohl Azure KI Search über eine native KI-Anreicherung verfügt, wird Ihnen in diesem Tutorial gezeigt, wie Sie auf KI-Funktionen außerhalb von Azure KI Search zugreifen können. Durch die Verwendung von SynapseML anstelle von Indexern oder Fähigkeiten unterliegen Sie keinen Datengrenzen oder anderen Einschränkungen, die mit diesen Objekten verbunden sind.
Tipp
Sehen Sie sich ein kurzes Video zu dieser Demo unter https://www.youtube.com/watch?v=iXnBLwp7f88 an. Das Video erweitert dieses Tutorial um weitere Schritte und Visualisierungen.
Voraussetzungen
Sie benötigen die synapseml-Bibliothek und mehrere Azure-Ressourcen. Verwenden Sie nach Möglichkeit dasselbe Abonnement und dieselbe Region für Ihre Azure-Ressourcen, und fassen Sie alles in einer Ressourcengruppe zusammen, um später eine einfache Bereinigung zu ermöglichen. Die folgenden Links sind für Portalinstallationen. Die Beispieldaten werden von einer öffentlichen Website importiert.
- SynapseML-Paket 1
- Azure KI Search (beliebige Dienstebene) 2
- Azure AI Services (beliebige Ebene) 3
- Azure Databricks (beliebige Ebene) 4
1 Dieser Link führt zu einem Tutorial zum Laden des Pakets.
2 Zum Indizieren der Beispieldaten kann der kostenlose Search-Tarif verwendet werden. Für umfangreiche Daten wird allerdings ein höherer Tarif benötigt. Geben Sie für gebührenpflichtige Dienstebenen den API-Schlüssel für die Suche im Schritt Einrichten von Abhängigkeiten weiter unten an.
3 In diesem Tutorial werden Azure AI Document Intelligence und Azure AI Translator verwendet. Geben Sie in den folgenden Anweisungen einen Schlüssel für mehrere Dienste und die Region an. Derselbe Schlüssel funktioniert für beide Dienste.
4 In diesem Tutorial stellt Azure Databricks die Spark-Computingplattform bereit. Wir haben die Portalanweisungen zum Einrichten des Arbeitsbereichs verwendet.
Hinweis
Alle oben genannten Ressourcen unterstützen Sicherheitsfunktionen in der Microsoft Identity-Plattform. Der Einfachheit halber wird bei diesem Tutorial von einer schlüsselbasierten Authentifizierung ausgegangen, wobei Endpunkte und Schlüssel verwendet werden, die von den Azure-Portalseiten der einzelnen Dienste kopiert wurden. Wenn Sie diesen Workflow in einer Produktionsumgebung implementieren oder die Lösung mit anderen teilen, denken Sie daran, fest codierte Schlüssel durch integrierte Sicherheitsschlüssel oder verschlüsselte Schlüssel zu ersetzen.
Schritt 1: Erstellen eines Spark-Clusters und -Notebooks
Erstellen Sie in diesem Abschnitt einen Cluster, installieren Sie die synapseml-Bibliothek, und erstellen Sie ein Notebook zum Ausführen des Codes.
Suchen Sie im Azure-Portal nach Ihrem Azure Databricks-Arbeitsbereich, und wählen Sie Arbeitsbereich starten aus.
Wählen Sie im linken Menü Berechnen aus.
Wählen Sie Compute-Instanz erstellen aus.
Übernehmen Sie die Standardkonfiguration. Die Erstellung des Clusters dauert einige Minuten.
Installieren Sie die
synapseml-Bibliothek, nachdem der Cluster erstellt wurde:Wählen Sie auf den Registerkarten oben auf der Seite des Clusters Bibliotheken aus.
Wählen Sie Neu installieren.
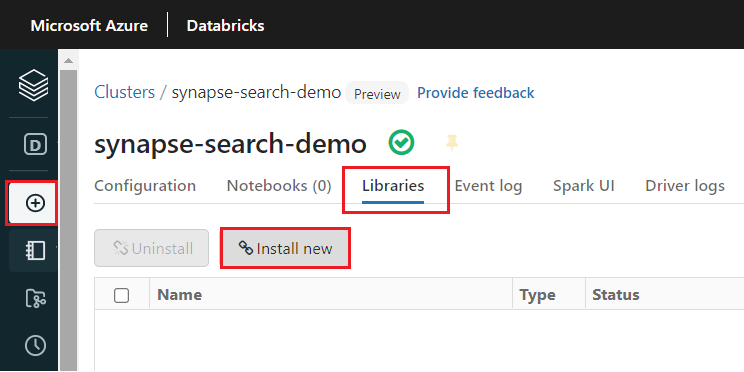
Wählen Sie Maven aus.
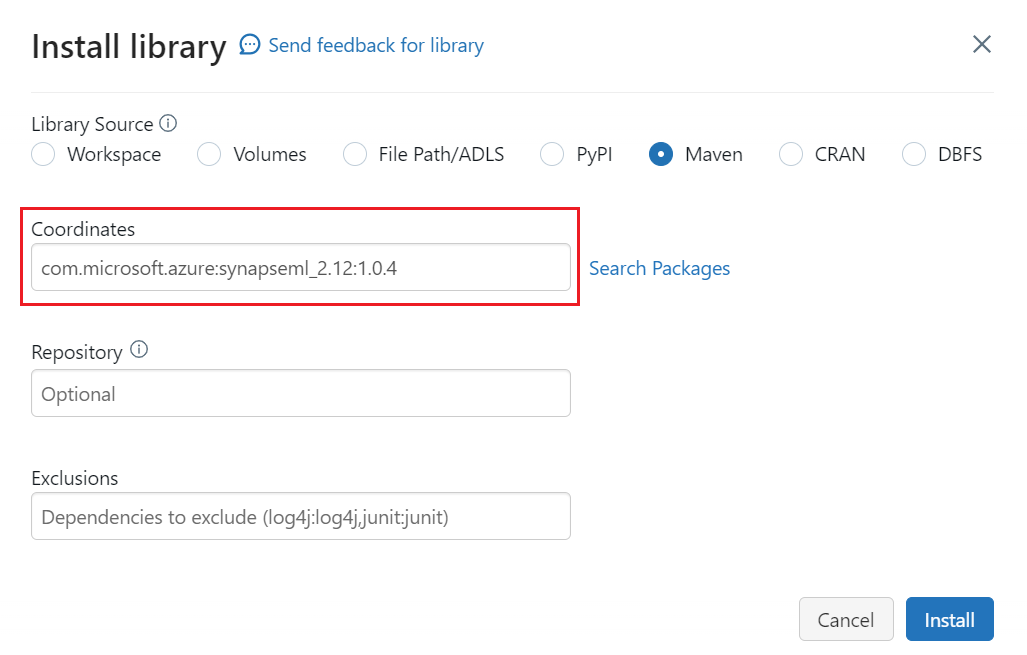
Geben Sie unter Koordinaten
com.microsoft.azure:synapseml_2.12:1.0.4einWählen Sie Installieren aus.
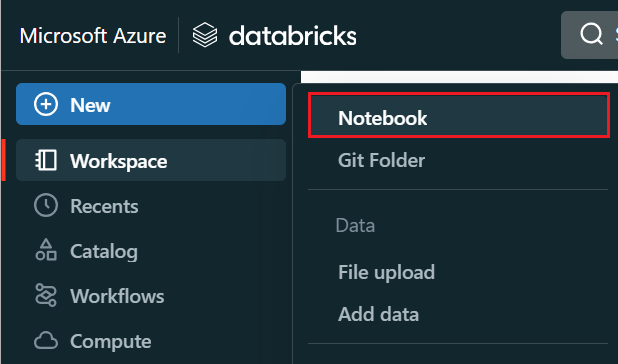
Wählen Sie im linken Menü Erstellen ein>Notizbuch aus.
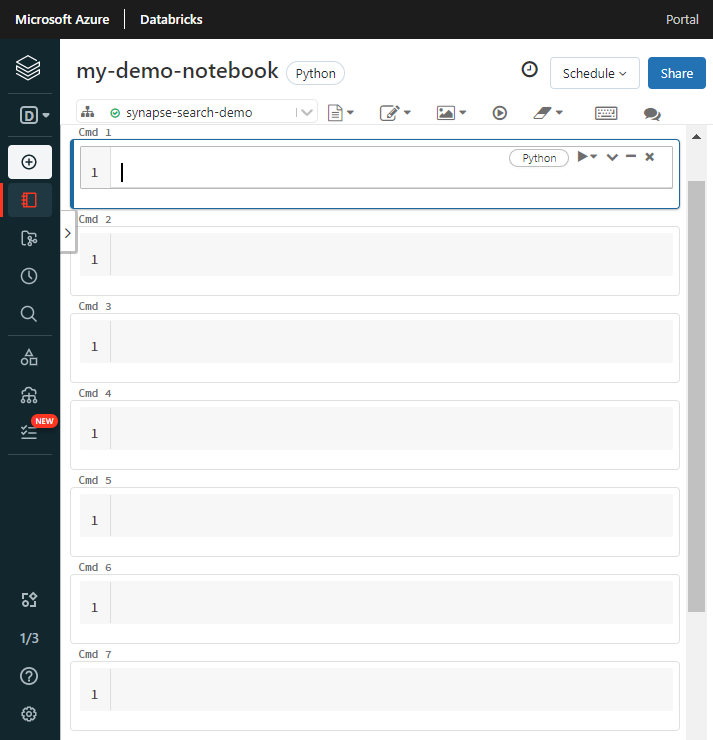
Geben Sie dem Notebook einen Namen, wählen Sie Python als Standardsprache und den Cluster mit der
synapsemlBibliothek aus.Erstellen Sie sieben aufeinanderfolgende Zellen. Fügen Sie Code in jede Zelle ein.
Schritt 2: Einrichten von Abhängigkeiten
Fügen Sie den folgenden Code in die erste Zelle Ihres Notizbuchs ein.
Ersetzen Sie die Platzhalter durch Endpunkte und Zugriffsschlüssel für jede Ressource. Geben Sie einen Namen für einen neuen Suchindex an. Es sind keine weiteren Änderungen erforderlich, also führen Sie den Code aus, wenn Sie bereit sind.
Dieser Code importiert mehrere Pakete und richtet den Zugriff auf die in diesem Workflow verwendeten Azure-Ressourcen ein.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Schritt 3: Laden von Daten in Spark
Fügen Sie den folgenden Code in die zweite Zelle ein. Es sind keine Änderungen erforderlich, also führen Sie den Code aus, wenn Sie bereit sind.
Dieser Code lädt ein paar externe Dateien aus einem Azure-Speicherkonto. Die Dateien sind verschiedene Rechnungen und werden in einen Datenrahmen eingelesen.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Schritt 4: Hinzufügen von Dokument Intelligenz
Fügen Sie den folgenden Code in die dritte Zelle ein. Es sind keine Änderungen erforderlich, also führen Sie den Code aus, wenn Sie bereit sind.
Dieser Code lädt den AnalyzeInvoices-Transformer und übergibt einen Verweis auf den Datenrahmen, der die Rechnungen enthält. Das vordefinierte Rechnungsmodell von Azure KI Dokument Intelligenz wird aufgerufen, um Informationen aus den Rechnungen zu extrahieren.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
Die Ausgabe aus diesem Schritt sollte ähnlich wie der nächste Screenshot aussehen. Beachten Sie, dass die Formularanalyse in eine dicht strukturierte Spalte gepackt ist, die schwer zu bearbeiten ist. Die nächste Transformation löst dieses Problem auf, indem die Spalte in Zeilen und Spalten geparst wird.
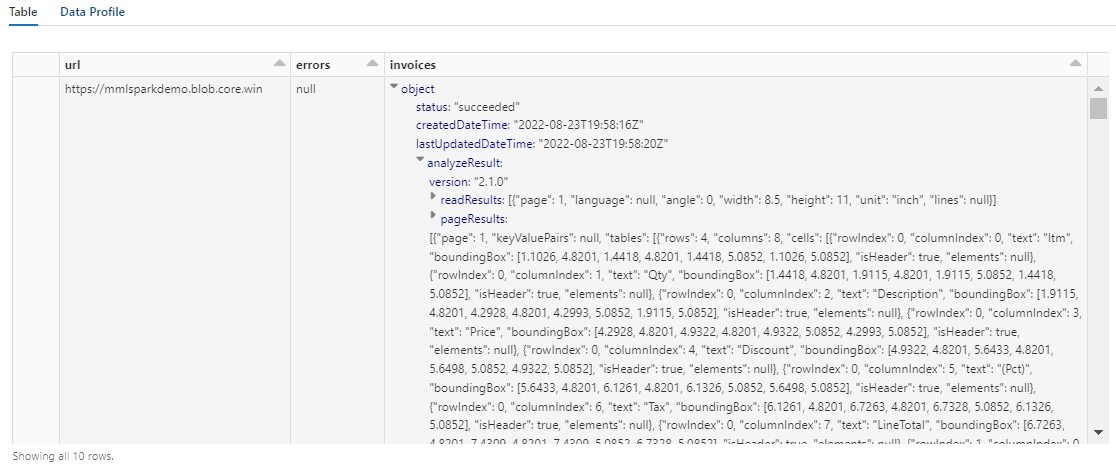
Schritt 5: Neustrukturieren der Ausgabe von Dokument Intelligenz
Fügen Sie den folgenden Code in die vierte Zelle ein und führen Sie ihn aus. Es sind keine Änderungen erforderlich.
Dieser Code lädt FormOntologyLearner, einen Transformer, der die Ausgabe von Document Intelligence-Transformern analysiert und eine tabellarische Datenstruktur ableitet. Die Ausgabe von AnalyzeInvoices ist dynamisch und variiert je nach den in Ihren Inhalten erkannten Funktionen. Darüber hinaus konsolidiert der Transformator die Ausgabe in einer einzigen Spalte. Da die Ausgabe dynamisch und konsolidiert ist, lässt sie sich nur schwer in nachgelagerten Transformationen verwenden, die mehr Struktur erfordern.
FormOntologyLearner erweitert den Nutzen des Transformers AnalyzeInvoices, indem es nach Mustern sucht, die zum Erstellen einer tabellarischen Datenstruktur verwendet werden können. Das Organisieren der Ausgabe in mehreren Spalten und Zeilen macht den Inhalt in anderen Transformern wie AzureSearchWriter nutzbar.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Beachten Sie, wie diese Transformation die geschachtelten Felder wieder in eine Tabelle umwandelt, die die nächsten beiden Transformationen ermöglicht. Dieser Screenshot ist der Kürze halber zugeschnitten. Wenn Sie den Vorgang in Ihrem eigenen Notebook nachverfolgen, verfügen Sie über 19 Spalten und 26 Zeilen.
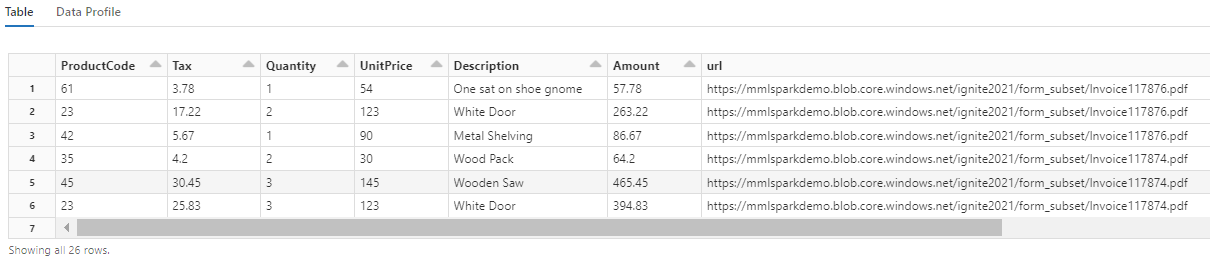
Schritt 6: Hinzufügen von Übersetzungen
Fügen Sie den folgenden Code in die fünfte Zelle ein. Es sind keine Änderungen erforderlich, also führen Sie den Code aus, wenn Sie bereit sind.
Dieser Code lädt Übersetzen, einen Transformer, der den Azure AI Translator-Dienst in Azure AI Services aufruft. Der englische Originaltext in der Spalte „Beschreibung“ wird maschinell in verschiedene Sprachen übersetzt. Die gesamte Ausgabe wird im Array „output.translations“ konsolidiert.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Tipp
Um nach übersetzten Zeichenfolgen zu suchen, scrollen Sie zum Ende der Zeilen.
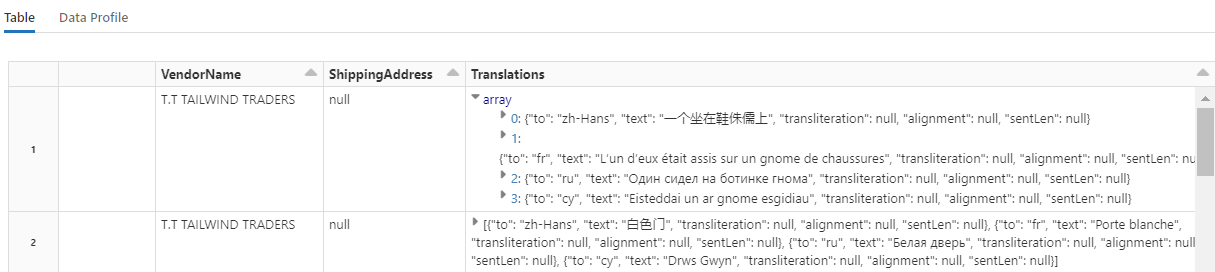
Schritt 7: Hinzufügen eines Suchindex mit AzureSearchWriter
Fügen Sie den folgenden Code in die sechste Zelle ein und führen Sie ihn aus. Es sind keine Änderungen erforderlich.
Dieser Code lädt AzureSearchWriter. Es verwendet einen tabellarischen Datensatz und schließt ein Suchindexschema ab, das ein Feld für jede Spalte definiert. Da es sich bei der Übersetzungsstruktur um ein Array handelt, wird sie im Index als komplexe Sammlung mit Unterfeldern für jede Sprachübersetzung artikuliert. Der generierte Index verfügt über einen Dokumentenschlüssel und verwendet die Standardwerte für Felder, die mit der REST-API für die Indexerstellung erstellt wurden.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Sie können die Suchdienstseiten im Azure-Portal überprüfen, um die von AzureSearchWriter erstellte Indexdefinition zu untersuchen.
Hinweis
Wenn Sie den Standardsuchindex nicht verwenden können, können Sie eine externe benutzerdefinierte Definition in JSON bereitstellen und den URI als Zeichenfolge in der Eigenschaft „indexJson“ übergeben. Generieren Sie zuerst den Standardindex, damit Sie wissen, welche Felder angegeben werden sollen. Fahren Sie anschließend mit benutzerdefinierten Eigenschaften fort, wenn Sie beispielsweise bestimmte Analysetools benötigen.
Schritt 8: Abfragen des Index
Fügen Sie den folgenden Code in die siebte Zelle ein und führen Sie ihn dann aus. Es sind keine Änderungen erforderlich, außer dass Sie möglicherweise die Syntax ändern oder mehr Beispiele ausprobieren möchten, um Ihren Inhalt weiter zu untersuchen:
Es gibt keine Transformatoren oder Module, die Abfragen ausgeben. Diese Zelle ist ein einfacher Aufruf der REST-API für Suchdokumente.
Dieses spezielle Beispiel ist die Suche nach dem Wort „Tür“ ("search": "door"). Es wird außerdem die „Anzahl“ der übereinstimmenden Dokumente zurückgegeben, und es wird nur der Inhalt der Felder „Beschreibung“ und „Übersetzungen“ als Ergebnisse ausgegeben. Wenn Sie die vollständige Liste der Felder sehen möchten, entfernen Sie den „Auswählen“-Parameter.
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Der folgende Screenshot zeigt die Zellenausgabe für das Beispielskript:
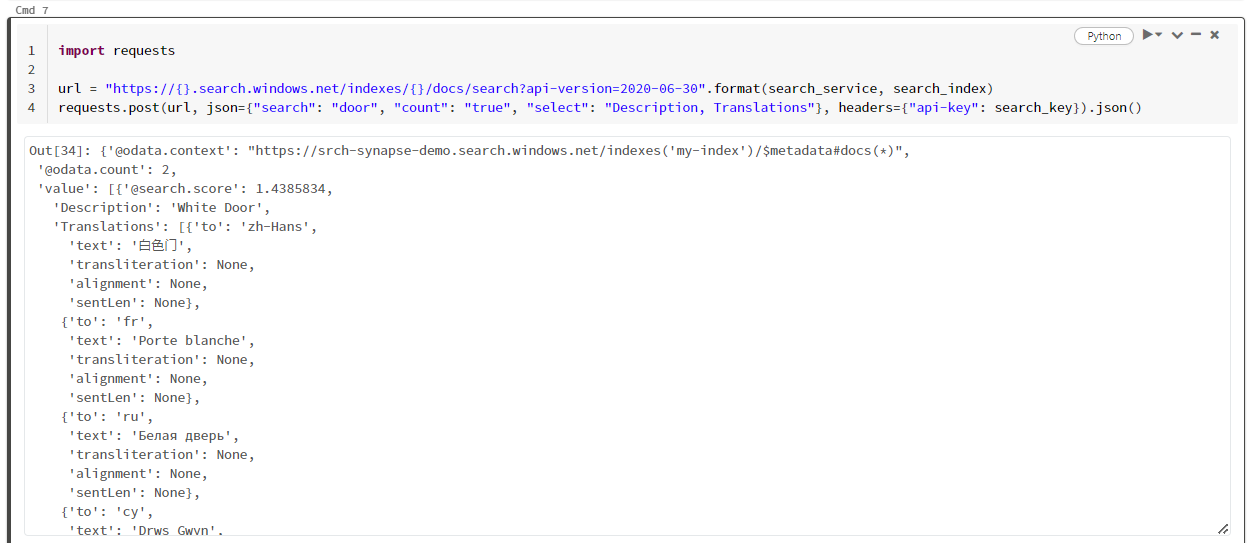
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können einzelne Ressourcen oder die gesamte Ressourcengruppe mit allen darin enthaltenen Ressourcen löschen.
Sie können Ressourcen im Azure-Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich suchen und verwalten.
Nächste Schritte
In diesem Tutorial haben Sie den AzureSearchWriter-Transformator in SynapseML kennengelernt, der eine neue Methode zum Erstellen und Laden von Suchindizes in Azure KI Search darstellt. Der Transformer nimmt strukturiertes JSON als Eingabe. Der FormOntologyLearner kann die notwendige Struktur für die Ausgabe bereitstellen, die von den Document Intelligence-Transformatoren in SynapseML erzeugt wird.
Sehen Sie sich als nächsten Schritt die anderen SynapseML-Tutorials an, die transformierte Inhalte erzeugen, die Sie möglicherweise über die Azure KI Search erkunden möchten: