Tutorial: Zugreifen auf Azure Synapse ADLS Gen2-Daten in Azure Machine Learning
In diesem Tutorial führen wir Sie durch den Prozess des Zugriffs auf in Azure Synapse Azure Data Lake Storage Gen2 (ADLS Gen2) gespeicherte Daten aus Azure Machine Learning (Azure Machine Learning). Diese Funktion ist besonders nützlich, wenn Sie ihren maschinellen Lernworkflow optimieren möchten, indem Sie Tools wie automatisierte ML, integrierte Modell- und Experimentverfolgung oder spezielle Hardware wie GPUs nutzen, die in Azure Machine Learning verfügbar sind.
Um auf ADLS Gen2-Daten in Azure Machine Learning zuzugreifen, erstellen wir einen Azure Machine Learning-Datenspeicher, der auf das Azure Synapse ADLS Gen2-Speicherkonto verweist.
Voraussetzungen
- Ein Azure Synapse Analytics-Arbeitsbereich. Er muss über ein Azure Data Lake Storage Gen2-Speicherkonto verfügen, das als Standardspeicher konfiguriert ist. Für das hier verwendete Data Lake Storage Gen2-Dateisystem müssen Sie über die Rolle Mitwirkender an Storage-Blobdaten verfügen.
- Ein Azure Machine Learning-Arbeitsbereich.
Installieren von Bibliotheken
Zuerst installieren wir das azure-ai-ml-Paket.
%pip install azure-ai-ml
Erstellen eines Datenspeichers
Azure Machine Learning bietet ein Feature namens „Datenspeicher“, das als Verweis auf Ihr vorhandenes Azure-Speicherkonto fungiert. Wir erstellen einen Datenspeicher, der auf unser Azure Synapse ADLS Gen2-Speicherkonto verweist.
In diesem Beispiel erstellen wir einen Datenspeicher, der mit unserem Azure Synapse ADLS Gen2-Speicher verknüpft ist. Nach dem Initialisieren eines MLClient-Objekts können Sie Verbindungsdetails zu Ihrem ADLS Gen2-Konto bereitstellen. Schließlich können Sie den Code ausführen, um den Datenspeicher zu erstellen oder zu aktualisieren.
from azure.ai.ml.entities import AzureDataLakeGen2Datastore
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
# Provide the connection details to your Azure Synapse ADLSg2 storage account
store = AzureDataLakeGen2Datastore(
name="",
description="",
account_name="",
filesystem=""
)
ml_client.create_or_update(store)
Weitere Informationen zum Erstellen und Verwalten von Azure Machine Learning-Datenspeichern finden Sie in diesem Tutorial zu Azure Machine Learning-Datenspeichern.
Einbinden Ihres ADLS Gen2-Speicherkontos
Nachdem Sie Ihren Datenspeicher eingerichtet haben, können Sie auf diese Daten zugreifen, indem Sie eine Einbindung für Ihr ADLSg2-Konto erstellen. In Azure Machine Learning besteht die Erstellung einer Einbindung in Ihrem ADLS Gen2-Konto darin, eine direkte Verbindung zwischen Ihrem Arbeitsbereich und dem Speicherkonto herzustellen, sodass nahtlos auf die darin gespeicherten Daten zugegriffen werden kann. Im Wesentlichen fungiert eine Einbindung als Pfad, mit dem Azure Machine Learning mit den Dateien und Ordnern in Ihrem ADLS Gen2-Konto interagieren kann, als wären sie Teil des lokalen Dateisystems innerhalb Ihres Arbeitsbereichs.
Sobald das Speicherkonto eingebunden wurde, können Sie Daten, die in ADLS Gen2 gespeichert sind, mühelos lesen, schreiben und bearbeiten, indem Sie vertraute Dateisystemvorgänge direkt in Ihrer Azure Machine Learning-Umgebung verwenden, die Datenvorverarbeitung vereinfachen, Training modellieren und Experimentieren vereinfachen.
Gehen Sie hierzu folgendermaßen vor:
Starten Sie das Computemodul.
Wählen Sie Datenaktionen und dann Einbindung aus.
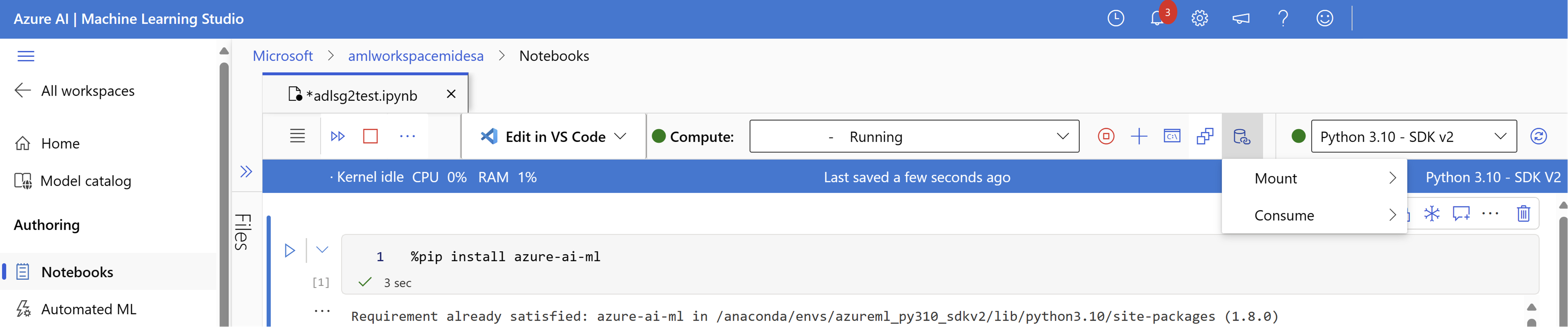
Hier sollten Sie Ihren ADLSg2-Speicherkontonamen sehen und auswählen. Es kann einige Momente dauern, bis Ihre Einbindung erstellt wird.
Sobald die Einbindung fertig ist, können Sie Datenaktionen und dann Nutzen auswählen. Unter Daten können Sie dann die Einbindung auswählen, aus der Sie Daten nutzen möchten.
Jetzt können Sie Ihre bevorzugten Bibliotheken verwenden, um Daten direkt aus Ihrem eingebundenen Azure Data Lake Storage-Konto zu lesen.
Lesen von Daten aus Ihrem Speicherkonto
import os
# List the files in the mounted path
print(os.listdir("/home/azureuser/cloudfiles/data/datastore/{name of mount}"))
# Get the path of your file and load the data using your preferred libraries
import pandas as pd
df = pd.read_csv("/home/azureuser/cloudfiles/data/datastore/{name of mount}/{file name}")
print(df.head(5))