Cheatsheet für dedizierte SQL-Pools (ehemals SQL DW) in Azure Synapse Analytics
Dieses Cheatsheet enthält praktische Tipps und bewährte Methoden zur Erstellung von Lösungen mit dediziertem SQL-Pool (ehemals SQL DW).
Die folgende Grafik zeigt den Entwurfsprozess für ein Data Warehouse mit dediziertem SQL-Pool (ehemals SQL DW):
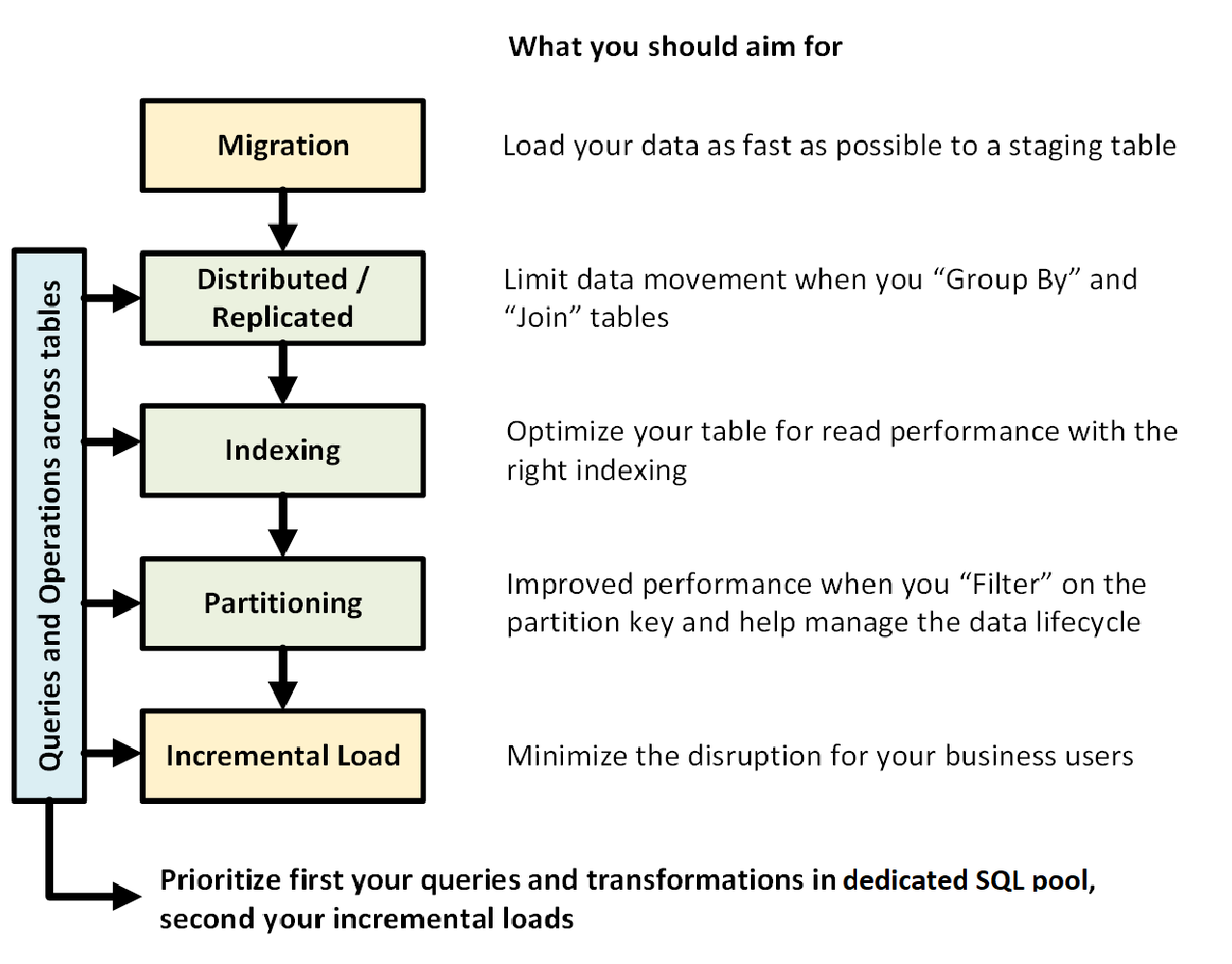
Tabellenübergreifende Abfragen und Vorgänge
Wenn Sie im Voraus die primären Vorgänge und Abfragen wissen, die in Ihrer Data Warehouse-Datenbank ausgeführt werden sollen, können Sie die Architektur der Data Warehouse-Datenbank hinsichtlich dieser Vorgänge priorisieren. Diese Abfragen und die Vorgänge können Folgendes umfassen:
- Verknüpfen von einer oder zwei Faktentabellen mit Dimensionstabellen, Filtern der kombinierten Tabelle und dann Anfügen der Ergebnisse an einen Data Mart
- Durchführen von umfangreichen oder geringfügigen Updates in der Faktenumsatztabelle
- Anfügen von ausschließlich Daten an Tabellen
Wenn Sie im Voraus wissen, welche Arten von Vorgängen vorhanden sind, können Sie Ihre Tabellen optimal entwerfen.
Datenmigration
Laden Sie zunächst Ihre Daten in Azure Data Lake Storage oder Azure Blob Storage. Verwenden Sie als Nächstes die COPY-Anweisung, um Ihre Daten in Stagingtabellen zu laden. Verwenden Sie die folgende Konfiguration:
| Entwurf | Empfehlung |
|---|---|
| Distribution | Roundrobin |
| Indizierung | Heap |
| Partitionierung | Keine |
| Ressourcenklasse | largerc oder xlargerc |
Weitere Informationen hierzu finden Sie unter Datenmigration, Laden von Daten und Entwerfen von ELT-Prozessen für Azure SQL Data Warehouse.
Verteilte oder replizierte Tabellen
Abhängig von den Tabelleneigenschaften sollten Sie folgende Strategien verwenden:
| type | Für folgende Fälle empfohlen | In folgenden Fälle mit Vorsicht zu behandeln |
|---|---|---|
| Repliziert | * Kleine Dimensionstabellen in einem Sternschema mit max. 2 GB Speicher nach Komprimierung (ca. 5-facher Komprimierung) | * Viele Schreibtransaktionen für Tabellen (z. B. „insert“, „upsert“, „delete“, „update“) * Häufige Änderungen an der Bereitstellung von DWUs (Data Warehouse-Einheiten) * Nutzung von lediglich 2 bis 3 Spalten, aber die Tabelle hat viele Spalten * Indizierung einer replizierten Tabelle |
| Roundrobin (Standard) | * Temporäre/Stagingtabellen * Fehlen eines eindeutigen Verknüpfungsschlüssels oder einer geeigneten Spalte |
* Schwache Leistung aufgrund von Datenverschiebungen |
| Hash | * Faktentabellen * Umfangreiche Dimensionstabellen |
* Fehlende Möglichkeit zur Aktualisierung des Verteilungsschlüssels |
Tipps:
- Beginnen Sie mit einer Roundrobintabelle, streben Sie aber eine Hashverteilungsstrategie an, um von den Vorteilen einer hochgradig parallelen Architektur profitieren zu können.
- Stellen Sie sicher, dass gemeinsame Hashschlüssel dasselbe Datenformat aufweisen.
- Führen Sie Verteilungen nicht im varchar-Format durch.
- Dimensionstabellen mit einem gemeinsamem Hashschlüssel zu einer Faktentabelle mit häufigen Verknüpfungsvorgängen können mit einer Hashverteilung versehen sein.
- Verwenden Sie sys.dm_pdw_nodes_db_partition_stats , um eine etwaige Schiefe in den Daten zu analysieren.
- Verwenden Sie sys.dm_pdw_request_steps , um Datenverschiebungen nach Abfragen zu analysieren, die Zeitübertragung zu überwachen und Vorgänge zu mischen. Dies ist für die Überprüfung Ihre Verteilungsstrategie hilfreich.
Weitere Informationen finden Sie in den Artikeln zu replizierten Tabellen und verteilten Tabellen.
Indizieren von Tabellen
Indizierung ist für schnelles Lesen von Tabellen nützlich. Es steht Ihnen eine einzigartige Gruppe von Technologien zur Verfügung, die Sie entsprechend Ihren Anforderungen nutzen können:
| type | Für folgende Fälle empfohlen | In folgenden Fälle mit Vorsicht zu behandeln |
|---|---|---|
| Heap | * Staging-/temporäre Tabelle * Kleine Tabellen mit geringfügigen Suchvorgängen |
* Beliebige Suchvorgänge zum Durchsuchen einer gesamten Tabelle |
| Gruppierter Index | * Tabellen mit bis zu 100 Millionen Zeilen * Große Tabellen (mehr als 100 Millionen Zeilen) mit häufiger Nutzung von lediglich 1 bis 2 Spalten |
* Verwendung für eine replizierte Tabelle * Komplexe Abfragen mit mehreren Join- und Group By-Vorgängen * Durchführen von Updates in indizierten Spalten: Arbeitsspeicher wird benötigt |
| Gruppierter Columnstore-Index (CCI) (Standard) | * Große Tabellen (mehr als 100 Millionen Zeilen) | * Verwendung für eine replizierte Tabelle * Umfangreiche Aktualisierungsvorgänge für Ihre Tabelle * Übermäßige Tabellenpartitionierung: Zeilengruppen erstrecken sich nicht über andere Verteilungsknoten und -partitionen |
Tipps:
- Neben einem gruppierten Index empfiehlt es sich, einer häufig zum Filtern verwendeten Spalte einen nicht gruppierten Index hinzuzufügen.
- Achten Sie darauf, wie Sie den Speicher für eine Tabelle mit einem CCI verwalten. Wenn Sie Daten laden, sollte der Benutzer (oder die Abfrage) eine umfangreiche Ressourcenklasse nutzen können. Achten Sie daher darauf, dass Kürzen und Erstellen vieler kleiner komprimierter Zeilengruppen vermieden wird.
- Bei Gen2 werden CCI-Tabellen lokal auf den Computeknoten zwischengespeichert, um die Leistung zu erhöhen.
- Bei einem CCI können aufgrund von unzureichender Komprimierung Ihrer Zeilengruppen Leistungseinbußen auftreten. Ist dies der Fall, sollte der CCI neu erstellt oder neu organisiert werden. Sie sollten mindestens 100.000 Zeilen pro komprimierter Zeilengruppe verwalten. Ideal sind 1 Millionen Zeilen in einer Zeilengruppe.
- Basierend auf der Häufigkeit und der Größe inkrementeller Ladevorgänge empfiehlt es sich, die Neuorganisation oder Neuerstellung von Indizes zu automatisieren. Hier empfiehlt sich immer eine gründliche Bereinigung.
- Denken Sie srategisch, wenn Sie eine Zeilengruppe kürzen möchten. Wie groß sind die offenen Zeilengruppen? Wie viele Daten werden Sie in den kommenden Tagen voraussichtlich laden?
Weitere Informationen finden Sie im Artikel über Indizes.
Partitionierung
Wenn Sie eine große Faktentabellen (mehr als 1 Milliarde Zeilen) haben, empfiehlt sich eventuell eine Partitionierung Ihrer Tabelle. In 99 Prozent der Fälle sollte der Partitionsschlüssel auf dem Datum basieren.
Bei Stagingtabellen, die ELT erfordern, kann eine Partitionierung von Vorteil sein. Sie vereinfacht die Verwaltung des Datenlebenszyklus. Achten Sie darauf, die Partitionierung Ihrer Fakten- und Stagingtabelle nicht zu übertreiben, insbesondere bei einem gruppierten Columnstore-Index.
Weitere Informationen finden Sie im Artikel über Partitionen.
Inkrementelles Laden
Wenn Sie vorhaben, die Daten inkrementell zu laden, müssen Sie zunächst größere Ressourcenklassen zuordnen, die zum Laden der Daten verwendet werden sollen. Dies ist besonders beim Laden in Tabellen mit gruppierten ColumnStore-Indizes wichtig. Weitere Informationen finden Sie unter Workloadverwaltung mit Ressourcenklassen in Azure SQL Data Warehouse.
Wir empfehlen Ihnen, PolyBase und ADF V2 zu verwenden, um die ELT-Pipelines für Ihr Data Warehouse zu automatisieren.
Ziehen Sie bei einer großen Anzahl von Updates an Ihren Verlaufsdaten die Verwendung von CTAS anstelle von INSERT, UPDATE und DELETE in Betracht, um die Daten, die Sie behalten möchten, in eine Tabelle zu schreiben.
Verwalten von Statistiken
Es ist wichtig, Statistiken zu aktualisieren, wenn wesentliche Änderungen an Ihren Daten vorgenommen werden. Sehen Sie unter Statistikaktualisierungen nach, ob bedeutende Änderungen vorgenommen wurden. Mit Statistikaktualisierungen werden Ihre Abfragepläne optimiert. Wenn Sie feststellen, dass die Verwaltung aller Statistiken zu viel Zeit in Anspruch nimmt, grenzen Sie die Auswahl der Spalten ein, die mit Statistiken zu versehen sind.
Sie können auch die Häufigkeit der Updates definieren. Beispielsweise könnte es sein, dass Sie Datumsspalten aktualisieren möchten, zu denen auf täglicher Basis neue Werte hinzugefügt werden sollen. Die größten Vorteile ergeben sich, wenn Sie Statistiken für Spalten in Verknüpfungen, in der WHERE-Klausel verwendete Spalten und Spalten in GROUP BY nutzen.
Weitere Informationen finden Sie im Artikel über Statistiken.
Ressourcenklasse
Ressourcengruppen werden genutzt, um Arbeitsspeicher für Abfragen zuzuweisen. Wenn Sie mehr Speicher zur Beschleunigung von Abfrage- oder Ladevorgängen benötigen, sollten Sie umfangreichere Ressourcenklassen zuordnen. Die Verwendung umfangreicherer Ressourcenklassen hat jedoch auch Nachteile im Hinblick auf die Parallelität zur Folge. Dies sollten Sie berücksichtigen, bevor Sie sämtliche Benutzer in eine umfangreiche Ressourcenklasse verschieben.
Wenn Sie feststellen, dass Abfragen zu lange dauern, stellen Sie sicher, dass Ihre Benutzer keine Vorgänge in umfangreichen Ressourcenklassen ausführen. Umfangreiche Ressourcenklassen beanspruchen viele Parallelitätsslots. Dies kann dazu führen, dass sich andere Abfragen in der Warteschlange ansammeln.
Bei Verwendung von Gen2 des dedizierten SQL-Pools (ehemals SQL DW) erhält jede Ressourcenklasse zudem 2,5-mal mehr Speicher als bei Gen1.
Weitere Informationen finden Sie im Artikel zum Arbeiten mit Ressourcenklassen und Parallelität.
Senkung Ihrer Kosten
Ein wichtiges Feature von Azure Synapse ist die Fähigkeit, Computeressourcen zu verwalten. Sie können Ihren dedizierten SQL-Pool (ehemals SQL DW) anhalten, wenn Sie ihn nicht verwenden. Es werden dann keine Computeressourcen berechnet. Sie können Ressourcen anhand Ihrer Leistungsanforderungen skalieren. Verwenden Sie zum Anhalten das Azure-Portal oder PowerShell. Verwenden Sie zum Skalieren das Azure-Portal, PowerShell, T-SQL oder eine REST-API.
Mit Azure Functions können Sie nun jederzeit eine automatische Skalierung veranlassen:

Optimieren Ihrer Architektur hinsichtlich der Leistung
Es empfiehlt sich, SQL-Datenbank und Azure Analysis Services in einer Hub-and-Spoke-Architektur (Nabe-Speiche-Architektur) zu implementieren. Diese Lösung kann Workloadisolation zwischen unterschiedlichen Benutzergruppen bereitstellen, während gleichzeitig erweiterte Sicherheitsfeatures von SQL-Datenbank sowie Azure Analysis Services verwendet werden. Darüber hinaus bietet eine derartige Lösung grenzenlose Parallelität für Ihre Benutzer.
Weiter Informationen zu typischen Architekturen, die den dedizierten SQL-Pool (ehemals SQL DW) in Azure Synapse Analytics nutzen, finden Sie hier.
Stellen Sie mit nur einem Klick Ihre Spokes in SQL-Datenbanken aus dem dedizierten SQL-Pool (ehemals SQL DW) bereit: