Verschieben von Mainframe-Computing zu Azure
Mainframes sind bekannt für ihre hohe Zuverlässigkeit und Verfügbarkeit und sind nach wie vor das zuverlässige Rückgrat vieler Unternehmen. Ihnen wird oft nahezu unbegrenzte Skalierbarkeit und Rechenleistung zugeschrieben. Für einige Unternehmen reicht die Leistung größten verfügbaren Mainframes jedoch nicht mehr aus. Wenn Ihnen das bekannt vorkommt, bietet Azure Ihnen Flexibilität, Reichweite und Infrastrukturvorteile.
Um Mainframeworkloads auf Microsoft Azure auszuführen, müssen Sie wissen, wie sich die Computingfunktionen Ihres Mainframes im Vergleich zu Azure verhalten. Basierend auf einem IBM z14-Mainframe (das aktuellste Modell zum Zeitpunkt dieses Artikels), erklärt Ihnen dieser Artikel, wie Sie vergleichbare Ergebnisse mit Azure erzielen können.
Um zu beginnen, sollten Sie die Umgebungen nebeneinander betrachten. Die folgende Abbildung vergleicht eine Mainframeumgebung für den Betrieb von Anwendungen mit einer Azure-Hosting-Umgebung.
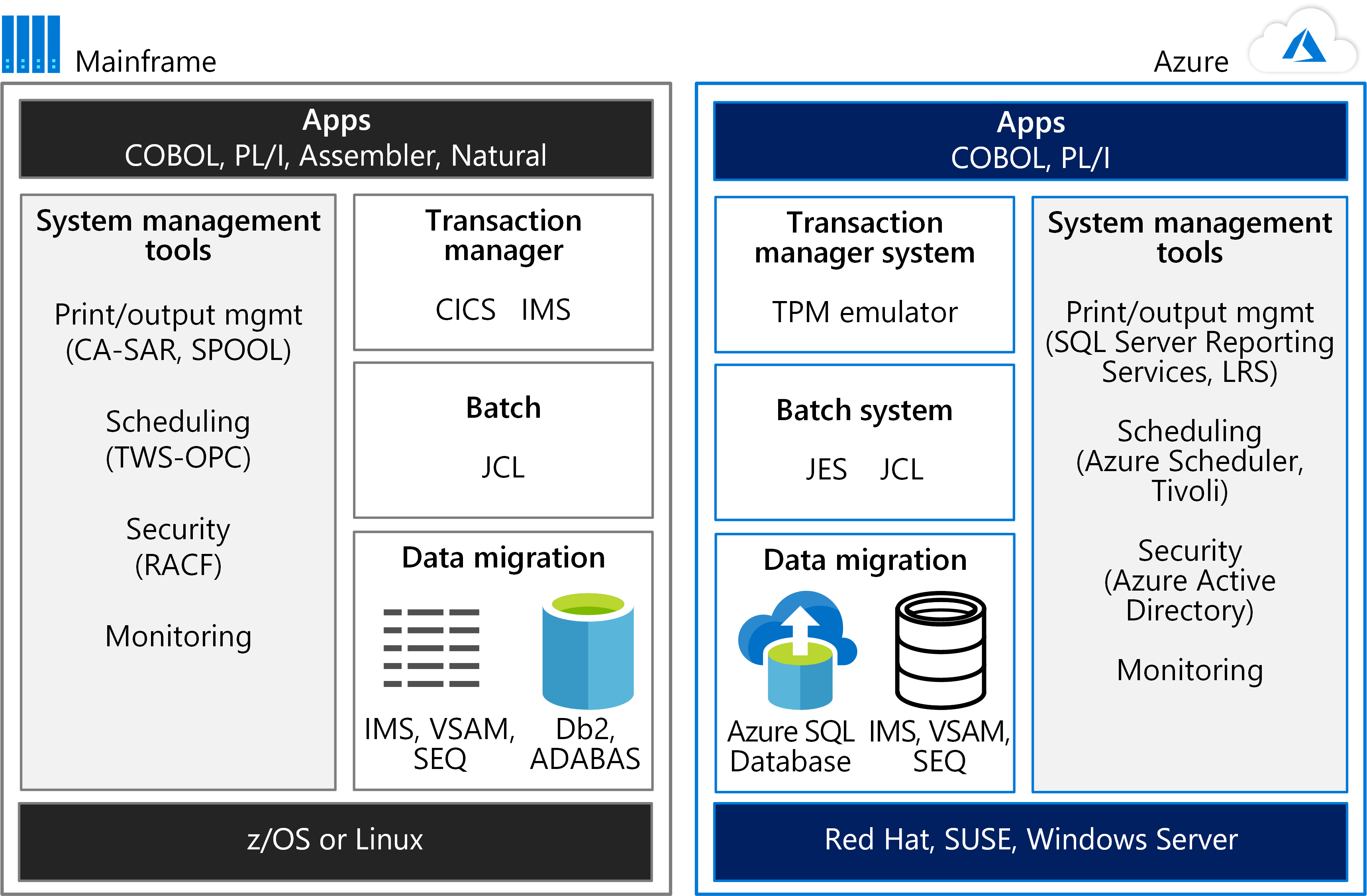
Die Leistungsfähigkeit von Mainframes wird häufig für OLTP-Systeme (Online Transaction Processing) genutzt, die Millionen von Updates für Tausende von Benutzern verwalten. Diese Anwendungen verwenden häufig Software Transaktionsverarbeitung, Bildschirmbearbeitung und die Formularerfassung. Sie verwenden ggf. ein Customer Information Control System (CICS), ein Information Management System (IMS) oder ein Transaction Interface Package (TIP) verwenden.
Wie die Abbildung zeigt, kann ein TPM-Emulator auf Azure CICS- und IMS-Workloads verarbeiten. Ein Batchsystememulator auf Azure übernimmt die Rolle der Job Control Language (JCL). Mainframedaten werden in Azure-Datenbanken, z.B. Azure SQL-Datenbank migriert. Azure-Dienste oder andere Software, die in virtuellen Azure-Computern gehostet wird, können für die Systemverwaltung verwendet werden.
Mainframe-Computing auf einen Blick
Im z14-Mainframe sind die Prozessoren in bis zu vier Drawern angeordnet. Ein Drawer ist einfach ein Cluster mit Prozessoren und Chipsätzen. Jeder Drawer kann sechs aktive CP-Chips (Hauptprozessor) aufweisen, und jeder CP hat 10 SC-Chips (Systemcontroller). In der Intel x86-Terminologie gibt es sechs Sockel pro Drawer, 10 Kerne pro Sockel und vier Drawer. Diese Architektur bietet das ungefähre Äquivalent von maximal 24 Sockeln und 240 Kernen für einen z14.
Der schnelle z14 CP hat eine Taktfrequenz von 5,2 GHz. Üblicherweise wird ein z14 mit allen CPs geliefert. Sie können nach Bedarf aktiviert werden. Einem Kunden werden in der Regel mindestens vier Stunden Rechenzeit pro Monat ungeachtet der tatsächlichen Nutzung berechnet.
Ein Mainframeprozessor kann als einer der folgenden Typen konfiguriert werden:
- GP-Prozessor (General Purpose)
- System z Integrated Information Processor (zIIP)
- Integrated Facility for Linux (IFL)-Prozessor
- System Assist Processor (SAP)
- Integrated Coupling Facility (ICF)-Prozessor
Horizontales und zentrales Hochskalieren von Mainframe-Computing
IBM-Mainframes bieten die Möglichkeit, bis zu 240 Kerne zu skalieren (die aktuelle z14-Größe für ein einzelnes System). Darüber hinaus können IBM-Mainframes durch eine Funktion namens Coupling Facility (CF) horizontal skaliert werden. CF ermöglicht es, dass mehrere Mainframesysteme gleichzeitig auf dieselben Daten zugreifen. Mit CF gruppiert die Parallel-Sysplex-Technologie des Mainframes Mainframeprozessoren in Clustern. Als dieses Handbuch geschrieben wurde, unterstützte die Parallel-Sysplex-Funktion 32 Gruppierungen von je 64 Prozessoren. Auf diese Weise können bis zu 2.048 Prozessoren gruppiert werden, um die Computingleistung horizontal zu skalieren.
Ein CF ermöglicht es den Computingclustern, Daten mit direktem Zugriff gemeinsam zu nutzen. Er dient zum Sperren von Informationen, Zwischenspeichern von Information und zum Erstellen der Liste der freigegebenen Datenressourcen. Ein Parallel-Sysplex mit einem oder mehreren CFs kann als ein Scale-Out-Computeclusterzum Freigeben aller Komponenten betrachtet werden. Weitere Informationen zu diesen Funktionen finden Sie unter Parallel Sysplex on IBM Z auf der IBM-Website.
Anwendungen können diese Funktionen nutzen, um sowohl horizontale Skalierungsleistung als auch Hochverfügbarkeit zu bieten. Um mehr darüber zu erfahren, wie CICS Parallel Sysplex mit CF verwenden kann, laden Sie das Redbook IBM CICS and the Coupling Facility: Beyond the Basics herunter.
Azure-Computing auf einen Blick
Einige Leute denken fälschlicherweise, dass Intel-basierte Server nicht so leistungsfähig sind wie Mainframes. Die neuen Intel-basierten Systeme mit hoher Kerndichte haben jedoch so viel Rechenkapazität wie Mainframes. Dieser Abschnitt beschreibt die Azure Infrastructure-as-a-Service (IaaS)-Optionen für Computing und Speicher. Azure bietet auch Platform-as-a-Service (PaaS)-Optionen, aber dieser Artikel konzentriert sich auf die IaaS-Optionen, die eine vergleichbare Mainframekapazität bieten.
Virtuelle Azure-Computer bieten Computingleistung in einer Vielzahl von Größen und Typen. In Azure entspricht eine virtuelle CPU (vCPU) ungefähr einem Kern auf einem Mainframe.
Derzeit bietet virtuellen Azure-Computer1 bis 128 vCPUs. VM-Typen (virtuelle Coputer) sind für bestimmte Workloads optimiert. Die folgende Liste zeigt beispielsweise die VM-Typen (aktuell zum Zeitpunkt dieses Schreibens des Artikels) und deren empfohlene Verwendung:
| Size | Typ und Beschreibung |
|---|---|
| D-Serie | GP mit 64 vCPUs und einer Taktfrequenz von bis zu zu 3,5 GHz |
| E-Serie | Speicheroptimierte mit bis zu 64 vCPUs |
| F-Serie | Computingoptimiert mit bis zu 64 vCPUs und einer Taktfrequenz von 3,7 GHz |
| H-Serie | Optimiert für High Performance Computing (HPC)-Anwendungen |
| L-Serie | Speicheroptimiert für Anwendungen mit hohem Durchsatz, die durch Datenbanken wie NoSQL unterstützt werden |
| M-Serie | Größte computing- und speicheroptimierte VMs mit bis zu 128 vCPUs |
Informationen zu verfügbaren virtuellen Computern finden Sie unter Serien virtueller Computer.
Ein z14-Mainframe kann bis zu 240-Kerne haben. Allerdings verwenden z14-Mainframes fast nie alle Kerne für eine einzelne Anwendung oder Workload. Stattdessen trennt ein Mainframe Workloads in logische Partitionen (LPARs), und die LPARs haben Bewertungen – MIPS (Millionen Instruktionen pro Sekunde) oder MSU (Millionen Serviceeinheiten). Bei der Bestimmung der vergleichbaren VM-Größe, die benötigt wird, um eine Mainframe-Workload auf Azure auszuführen, ist der Faktor in der MIPS-Bewertung (oder MSU) zu berücksichtigen.
Im Folgenden finden Sie allgemeine Schätzungen:
150 MIPS pro vCPU
1.000 MIPS pro Prozessor
Um die richtige VM-Größe für eine bestimmte Workload in einer LPAR zu ermitteln, optimieren Sie zunächst die VM für die Workload. Ermitteln Sie dann die erforderliche Anzahl von vCPUs. Eine konservative Schätzung wäre 150 MIPS pro vCPU. Basierend auf dieser Schätzung könnte beispielsweise eine VM der F-Serie mit 16 vCPUs leicht eine IBM Db2-Workload von einer LPAR mit 2.400 MIPS unterstützen.
Zentrales Hochskalieren von Azure-Computing
Die VMs der M-Serie können bis zu 128 vCPUs skalieren (zum Zeitpunkt der Erstellung dieses Artikels). Bei der konservativen Schätzung von 150 MIPS pro vCPU entspricht die VM der M-Serie etwa 19.000 MIPS. Die allgemeine Regel für das Schätzen von MIPS für einen Mainframe ist 1.000 MIPS pro Prozessor. Ein z14-Mainframe kann bis zu 24 Prozessoren haben und etwa 24.000 MIPS für ein einziges Mainframesystem bereitstellen.
Der größte einzelne z14-Mainframe hat etwa 5.000 MIPS mehr als die größte in Azure verfügbare VM. Dennoch ist es wichtig, zu vergleichen, wie Workloads bereitgestellt werden. Wenn ein Mainframesystem sowohl eine Anwendung als auch eine relationale Datenbank hat, werden sie typischerweise auf dem gleichen physischen Mainframe bereitgestellt – jeweils in einer eigenen LPAR. Die gleiche Lösung auf Azure wird oft mit einer VM für die Anwendung und einer separaten, entsprechend großen VM für die Datenbank bereitgestellt.
Wenn beispielsweise ein M64-vCPU-System die Anwendung unterstützt und eine M96-vCPU für die Datenbank verwendet wird, werden etwa 150 vCPUs benötigt – oder etwa 24.000 MIPS, wie die folgende Abbildung zeigt.
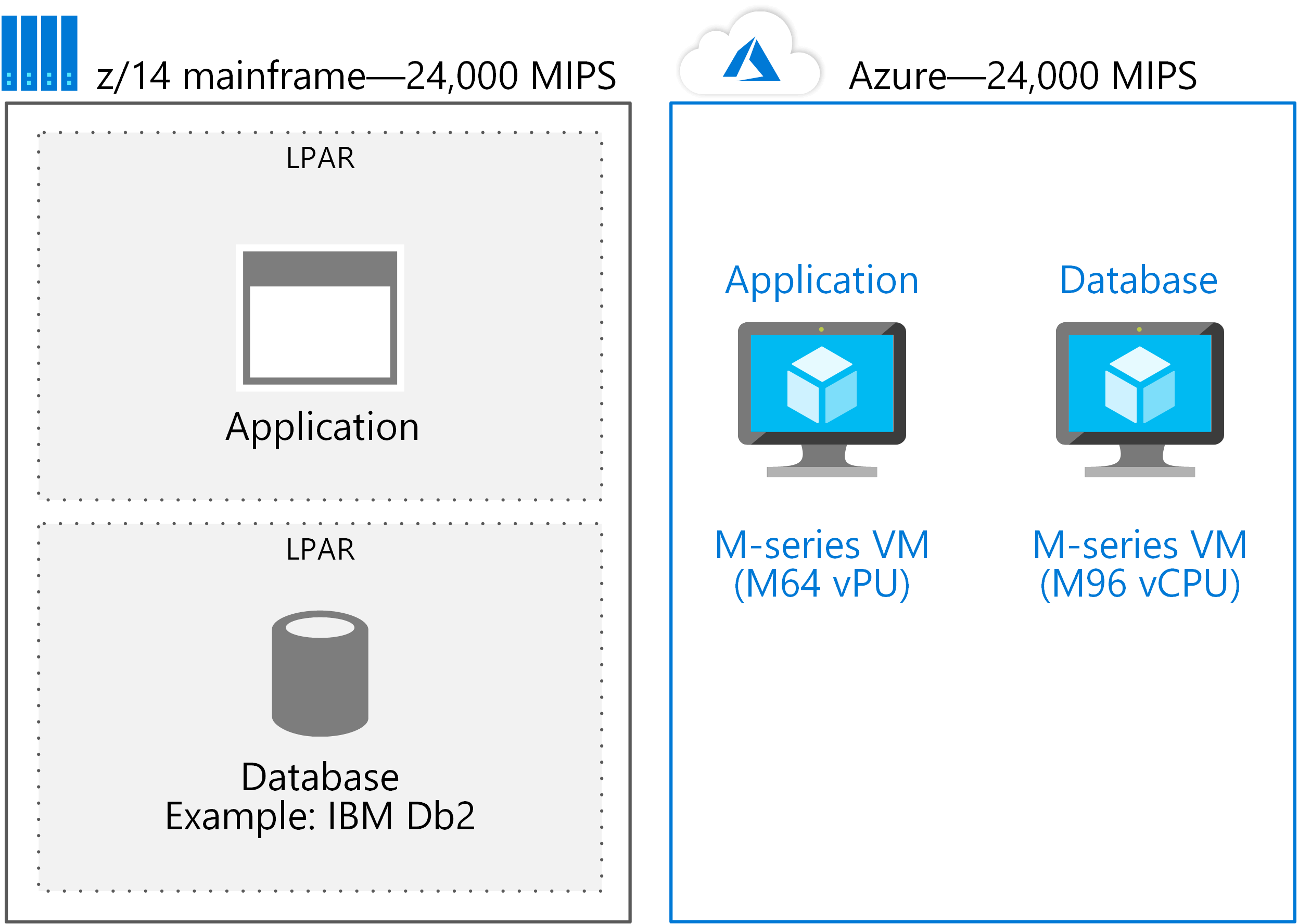
Bei diesem Ansatz werden LPARs auf einzelne VMs migriert. Dann kann Azure problemlos auf die Größe skaliert werden, die für die meisten Anwendungen benötigt wird, die auf einem einzigen Mainframesystem bereitgestellt werden.
Horizontale Skalierung von Azure-Computing
Einer der Vorteile einer Azure-basierten Lösung ist die Möglichkeit der Aufskalierung. Durch die Skalierung steht einer Anwendung eine nahezu unbegrenzte Rechenleistung zur Verfügung. Azure unterstützt mehrere Methoden, um die Rechenleistung zu skalieren:
Lastenausgleich im gesamten Cluster. In diesem Szenario kann eine Anwendung mit einem Load Balancer oder Ressourcenmanager die Workload auf mehrere VMs in einem Cluster verteilen. Wenn Sie mehr Computingkapazität benötigt wird, werden zusätzliche VMs zum Cluster hinzugefügt.
Skalierungsgruppen für virtuelle Computer In diesem Burst-Szenario kann eine Anwendung auf zusätzliche Computingressourcen basierend auf der VM-Nutzung skaliert werden. Wenn der Bedarf sinkt, kann auch die Anzahl der VMs in einer Skalierungsgruppe sinken, was eine effiziente Nutzung der Computingleistung gewährleistet.
PaaS-Skalierung. Azure PaaS ermöglicht das Skalieren von Computingressourcen. So weist beispielsweise Azure Service Fabric Computingressourcen zu, um den Anstieg des Anfragevolumens zu bewältigen.
Kubernetes-Cluster. Anwendungen auf Azure können Kubernetes-Cluster für die Berechnung von Diensten für bestimmte Ressourcen verwenden. Azure Kubernetes Service (AKS) ist ein verwalteter Dienst, der Kubernetes-Knoten, -Pools und -Cluster in Azure orchestriert.
Um die richtige Methode zur horizontalen Skalierung von Computingressourcen zu wählen, ist es wichtig zu verstehen, wie sich Azure und Mainframes unterscheiden. Der Schlüssel ist, wie oder ob Daten von Computingressourcen gemeinsam genutzt werden. In Azure werden Daten (standardmäßig) in der Regel nicht von mehreren VMs gemeinsam genutzt. Wenn die gemeinsame Nutzung von Daten durch mehrere VMs in einem Scale-Out-Computingcluster erforderlich ist, müssen sich die gemeinsamen Daten in einer Ressource befinden, die diese Funktionalität unterstützt. Bei Azure beinhaltet die gemeinsame Nutzung von Daten die Speicherung, wie im folgenden Abschnitt beschrieben.
Optimierung von Azure-Computing
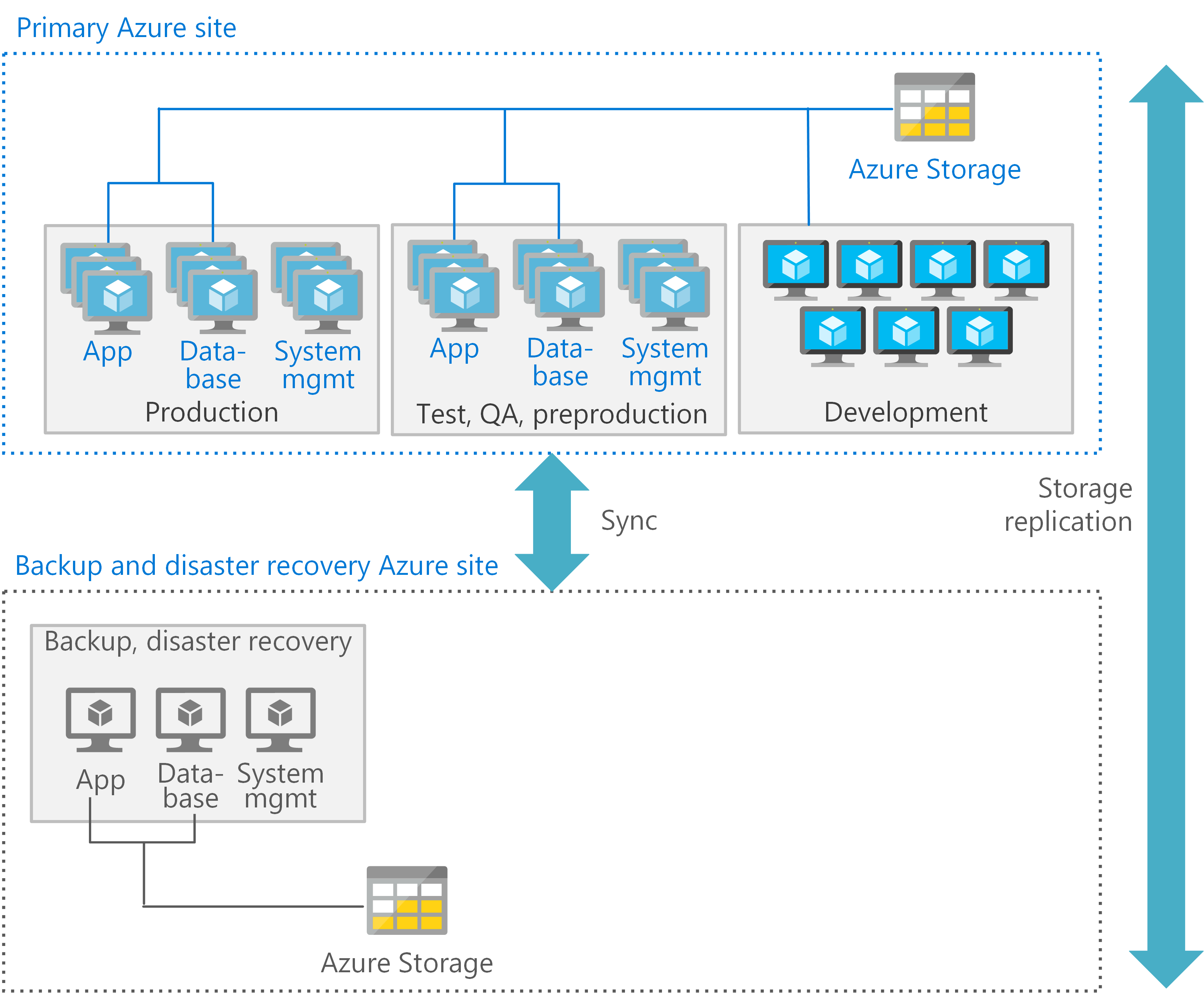
Sie können jede Verarbeitungsebene in einer Azure-Architektur optimieren. Verwenden Sie für jede Umgebung den am besten geeigneten Typ von VMs und Funktionen. Die folgende Abbildung zeigt ein mögliches Muster für die Bereitstellung von VMs in Azure zur Unterstützung einer CICS-Anwendung, die Db2 verwendet. Am primären Standort werden die Produktions-, Präproduktions- und Test-VMs mit hoher Verfügbarkeit bereitgestellt. Der sekundäre Standort wird für die Sicherung und Notfallwiederherstellung verwendet.
Jede Ebene kann auch entsprechende Dienste für die Notfallwiederherstellung bereitstellen. Zum Beispiel ist für Produktions- und Datenbank-VMs möglicherweise eine Wiederherstellung auf heißer oder warmer Ebene erforderlich, während Entwicklungs- und Test-VMs eine Wiederherstellung auf kalter Ebene unterstützen.
Nächste Schritte
- Mainframemigration
- Mainframerehosting auf virtuellen Azure-Computern
- Verschieben von Mainframespeicher zu Azure
IBM-Ressourcen
- Parallel Sysplex on IBM Z (Parallel Sysplex auf IBM Z)
- IBM CICS and the Coupling Facility: Beyond the Basics (IBM CICS und die Coupling Facility: Fortgeschrittene Themen)
- Erstellen der erforderlichen Benutzer für eine Installation von Db2 pureScale Feature
- db2icrt-Instanz erstellen (Befehl)
- Db2 pureScale Clustered Database Solution (Clusterdatenbank-Lösung mit Db2 pureScale)
- IBM Data Studio