Datensouveränität pro Microservice
Tipp
Diese Inhalte sind ein Auszug aus dem eBook „.NET Microservices Architecture for Containerized .NET Applications“, verfügbar unter .NET Docs oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Eine wichtige Regel für die Microservicesarchitektur ist, dass jeder Microservice seine eigenen Domänendaten und Domänenlogik besitzen muss. Ebenso wie eine vollständige Anwendung, die eigene Logik und Daten besitzt, muss jeder Microservice eigene Logik und Daten in einem autonomen Lebenszyklus mit unabhängigen Bereitstellungen pro Microservice besitzen.
Dies bedeutet, dass das konzeptionelle Modell der Domäne sich bei Subsystemen bzw. Microservices unterscheidet. Betrachten Sie z.B. Unternehmensanwendungen, bei denen CRM-Anwendungen (Customer Relationship Management), transaktionsgesteuerte Einkaufssubsysteme und Kundendienstsubsystemen eindeutige Kundenentitätsattribute und Daten in Anspruch nehmen und andere Kontextgrenzen (BC) nutzen.
Dieses Prinzip ist ähnlich bei domänengesteuertem Design (DDD), wobei jeder begrenzte Kontext oder jedes autonome Subsystem oder Dienst sein Domänenmodell (Daten plus Logik und Verhalten) besitzen muss. Jeder begrenzte Kontext von DDD entspricht einem Microservice für Unternehmen (mindestens ein Dienst). Die begrenzten Kontextmuster werden im nächsten Abschnitt ausführlich erläutert.
Andererseits verfügt der herkömmliche (monolithische Daten-)Ansatz, der in vielen Anwendungen verwendet wird, über eine einzelne zentrale Datenbank oder nur wenige Datenbanken. Dabei handelt es sich häufig um eine normalisierte SQL-Datenbank, die für die gesamte Anwendung und alle ihre interne Subsysteme verwendet wird (s. Abbildung 4-7).
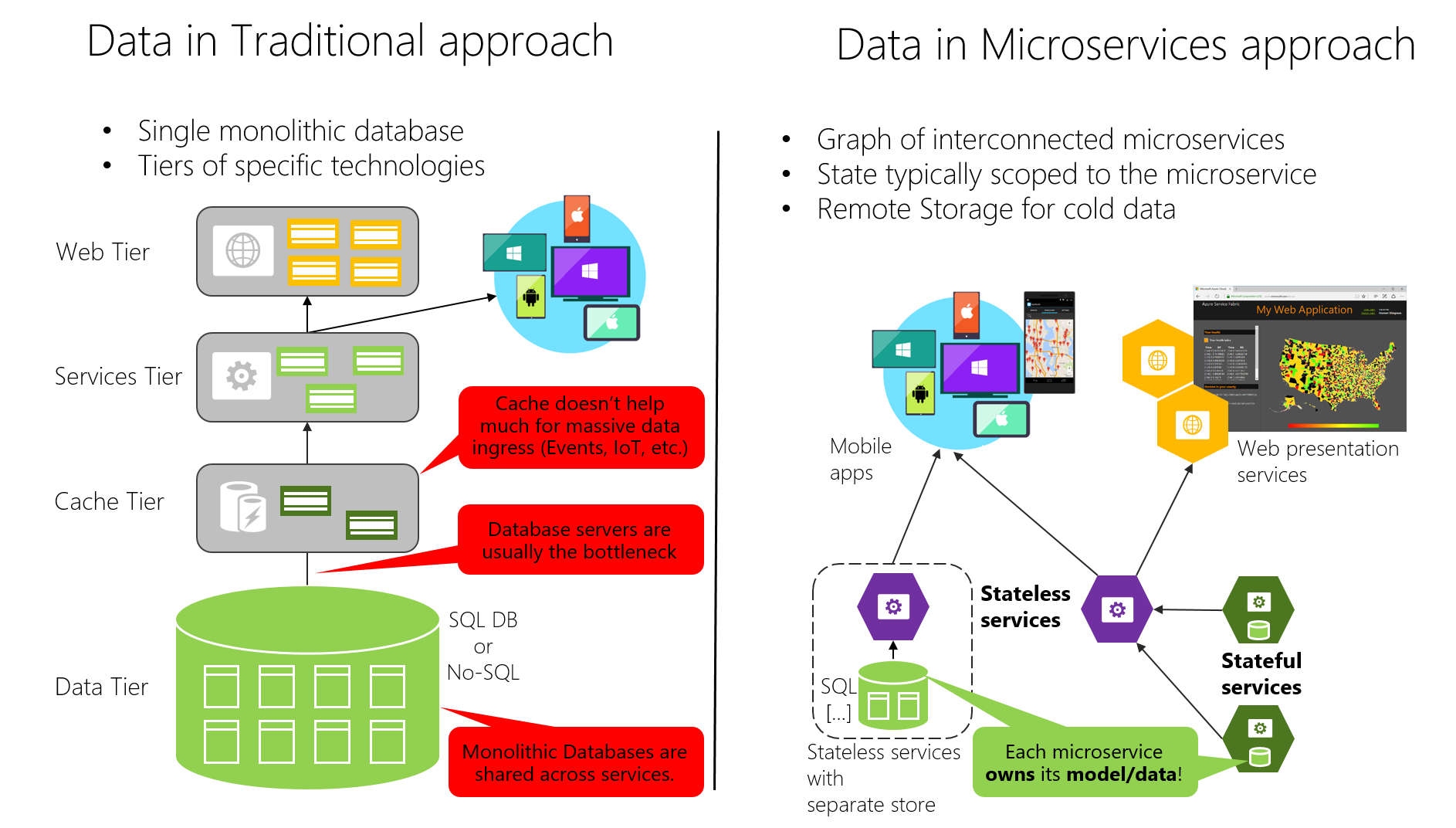
Abbildung 4-7. Vergleich der Datensouveränität: monolithische Datenbank im Vergleich zu Microservices
Der traditionelle Ansatz sieht vor, dass eine einzige Datenbank für alle Dienste gemeinsam genutzt wird, typischerweise in einer mehrstufigen Architektur. Beim Microserviceansatz besitzt jeder Microservice ein eigenes Modell und eigene Daten. Dieser zentralisierte Datenbankansatz sieht anfänglich einfacher aus und scheint die Wiederverwendung von Entitäten in verschiedenen Subsystemen zu ermöglichen, um Konsistenz zu gewährleisten. Doch in Wirklichkeit haben Sie es mit riesigen Tabellen zu tun, die Anforderungen vieler verschiedener Subsysteme erfüllen und Attribute und Spalten enthalten, die in den meisten Fällen nicht nötig sind. Das ist wie der Versuch, dieselbe Karte für eine kurze Wanderung, einen Tagesausflug mit dem Auto und das Erlernen von Topografie zu nutzen.
Eine monolithische Anwendung mit einer einzelnen relationalen Datenbank hat in der Regel zwei wichtige Vorteile: ACID-Transaktionen und die SQL-Sprache. Beide arbeiten in allen Tabellen und Daten im Zusammenhang mit Ihrer Anwendung. Dieser Ansatz bietet eine Möglichkeit zum einfachen Schreiben einer Abfrage, die Daten aus mehreren Tabellen kombiniert.
Der Datenzugriff wird jedoch beim Wechsel zu einer Microservicearchitektur wesentlich komplizierter. Selbst bei der Verwendung von ACID-Transaktionen innerhalb eines Microservice oder einer Kontextgrenze muss berücksichtigt werden, dass die Daten, die sich im Besitz jedes Microservice befinden, für diesen Microservice privat sind und auf diese nur synchron über die API-Endpunkte (REST, gRPC, SOAP usw.) oder asynchron über Messaging (AMQP o. Ä.) zugegriffen werden sollte.
Kapseln von Daten stellt sicher, dass die Microservices locker gekoppelt sind und sich unabhängig voneinander weiterentwickeln können. Wenn mehrere Dienste auf die gleichen Daten zugreifen, benötigen Schemaupdates koordinierte Updates für alle Dienste. Dadurch würde die Autonomie des Lebenszyklus der Microservices unterbrochen. Allerdings bedeuten verteilte Datenstrukturen, dass Sie keine einzelne ACID-Transaktion über Microservices vornehmen können. Dies bedeutet wiederum, dass Sie die letztliche Konsistenz verwenden müssen, wenn ein Geschäftsprozess mehrere Microservices umfasst. Dies ist viel schwieriger zu implementieren als einfache SQL-Joins, da Sie weder Integritätseinschränkungen erstellen noch verteilte Transaktionen zwischen verschiedenen Datenbanken verwenden können, wie später erläutert wird. Ebenso sind viele andere Funktionen der relationalen Datenbank nicht für mehrere Microservices verfügbar.
Darüber hinaus verwenden verschiedene Microservices häufig unterschiedliche Arten von Datenbanken. Moderne Anwendungen speichern und verarbeiten verschiedene Typen von Daten. Eine relationale Datenbank ist nicht immer die beste Wahl. In einigen Anwendungsfällen verfügt eine NoSQL-Datenbank wie Azure CosmosDB oder MongoDB über ein praktischeres Datenmodell und bietet eine bessere Leistung und Skalierbarkeit als eine SQL-Datenbank wie SQL Server oder die Azure SQL-Datenbank. In anderen Fällen ist eine relationale Datenbank immer noch die beste Herangehensweise. Aus diesem Grund verwenden auf Microservices basierende Anwendungen häufig eine Mischung aus SQL- und NoSQL-Datenbanken, was in einigen Fällen auch Polyglot-Persistence-Ansatz genannt wird.
Eine partitionierte, polyglotte, persistente Architektur für die Datenspeicherung weist viele Vorteile auf. Dazu gehören lose miteinander verknüpfte Dienste und eine bessere Leistung, Skalierbarkeit, Kosten und Verwaltbarkeit. Allerdings kann dies einige Herausforderungen für die verteilte Datenverwaltung hervorrufen, wie weiter unten in diesem Kapitel unter Identifizieren von Domänenmodellgrenzen erläutert wird.
Die Beziehung zwischen Microservices und dem BC-Muster
Das Konzept der Microservice leitet sich vom BC-Muster (Begrenzter Kontext) in domänengesteuertem Design (DDD) ab. DDD arbeitet mit großen Modellen, unterteilt diese in mehrere BCs und definiert explizite Umrisslinien. Jeder BC benötigt sein eigenes Modell und seine eigene Datenbank. Ebenso besitzt jeder Microservice seine verwandten Daten. Darüber hinaus verfügt jede BC in der Regel über eine eigene ubiquitäre Sprache zur vereinfachten Kommunikation zwischen Softwareentwickler und Domänenexperten.
Diese Benennungen (v.a. Domänenentitäten) in der ubiquitären Sprache können unterschiedliche Namen in unterschiedlichen begrenzten Kontexten haben, selbst wenn die verschiedenen Domänenentitäten über die gleiche Identität verfügen (d.h. die eindeutige ID, die zum Lesen der Entität aus dem Speicher verwendet wird). In einem begrenzten Kontext in einem Benutzerprofil verfügt die Entität „User domain“ beispielsweise über die gleiche Identität wie die Entität „Buyer domain“ im begrenzten Bestellkontext.
Ein Microservice ist daher wie ein begrenzter Kontext. Aber er gibt auch an, dass es sich um einen verteilten Dienst handelt. Er wird als separater Prozess für jeden begrenzten Kontext erstellt, und muss die oben erwähnten verteilten Protokolle wie HTTP/HTTPS, WebSockets oder AMQP verwenden. Das begrenzte Kontextmuster gibt allerdings nicht an, ob der begrenzte Kontext ein verteilter Dienst oder einfach eine logische Begrenzung (z.B. ein generisches Subsystem) in einer monolithisch bereitgestellten Anwendung ist.
Es ist wichtig hervorzuheben, dass die Definition eines Dienst für jeden begrenzten Kontext ein guter Ausgangspunkt ist. Sie müssen Ihren Entwurf allerdings nicht darauf beschränken. In einigen Fällen müssen Sie einen begrenzten Kontext oder einen Microservice für ein Unternehmen entwerfen, die aus mehreren physischen Diensten bestehen. Aber letztendlich sind beide Muster – begrenzter Kontext und Microservice – eng miteinander verknüpft.
DDD profitiert von Microservices durch echte Grenzen in Form von verteilten Microservices. Aber Sie brauchen auch Ideen in einem begrenzten Kontext, wie die, das Modell nicht zwischen Microservices freizugeben.
Zusätzliche Ressourcen
Chris Richardson. Pattern: Database per service (Muster: Datenbank pro Dienst)
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Strategic Domain Driven Design with Context Mapping (Strategisches domänengesteuertes Design mithilfe der Kontextzuordnung)
https://www.infoq.com/articles/ddd-contextmapping