Was sind Bereitstellungspipelines?
Hinweis
In den Artikeln in diesem Abschnitt wird beschrieben, wie Sie Inhalte in Ihrer App bereitstellen. Informationen zur Versionskontrolle finden Sie in der Dokumentation zur Git-Integration.
Das Fabric-Tool für Bereitstellungspipelines bietet Autor*innen von Inhalten eine Produktionsumgebung, in der sie zusammenarbeiten können, um den Lebenszyklus von Unternehmensinhalten zu verwalten. Mithilfe von Bereitstellungspipelines können Autoren Inhalte innerhalb des Diensts entwickeln und testen, bevor sie für Benutzer bereitgestellt werden. Sehen Sie sich die vollständige Liste der unterstützten Elementtypen an, die Sie bereitstellen können.
Wichtig
- Die neue Benutzeroberfläche der Bereitstellungspipeline befindet sich derzeit in der Vorschau. Informationen zum Aktivieren oder Verwenden der neuen Benutzeroberfläche finden Sie unter Beginnen mit der Verwendung der neuen Benutzeroberfläche.
- Einige der Elemente für Bereitstellungspipelines befinden sich in der Vorschauphase. Weitere Informationen finden Sie in der Liste der unterstützten Elemente.
Informationen zur Verwendung von Bereitstellungspipelines
Unter diesen Links können Sie erfahren, wie Sie das Tool der Bereitstellungspipelines verwenden.
Erstellen und Verwalten einer Bereitstellungspipeline: Ein Learn-Modul, das Sie durch das Erstellen einer Bereitstellungspipeline führt.
Erste Schritte mit Bereitstellungspipelines – In einem Artikel wird erläutert, wie Sie eine Pipeline und wichtige Funktionen wie Bereitstellung erstellen, Inhalte in verschiedenen Phasen vergleichen und Bereitstellungsregeln erstellen.
Unterstützte Elemente
Wenn Sie Inhalte von einer Pipelinephase in einer anderen bereitstellen, können die kopierten Inhalte die folgenden Elemente enthalten:
- Dashboards
- Datenpipelines(Vorschau)
- Dataflows gen2 (Vorschau)
- Datamarts (Vorschau)
- Umwelt
- EventHouse (Vorschau)
- EventStream (Vorschau)
- Lakehouse(Vorschau)
- Eventhouse- und KQL-Datenbank(Vorschau)
- Notebooks
- Organisations-Apps (Vorschau)
- Paginierte Berichte
- Power BI-Dataflows
- Reflex (Vorschau)
- Berichte (basierend auf unterstützten semantischen Modellen)
- Spark-Umgebung(Vorschau)
- Semantische Modelle (die aus PBIX-Dateien stammen und keine PUSH-Datasets sind)
- SQL-Datenbank (Vorschau)
- Warehouses(Vorschau)
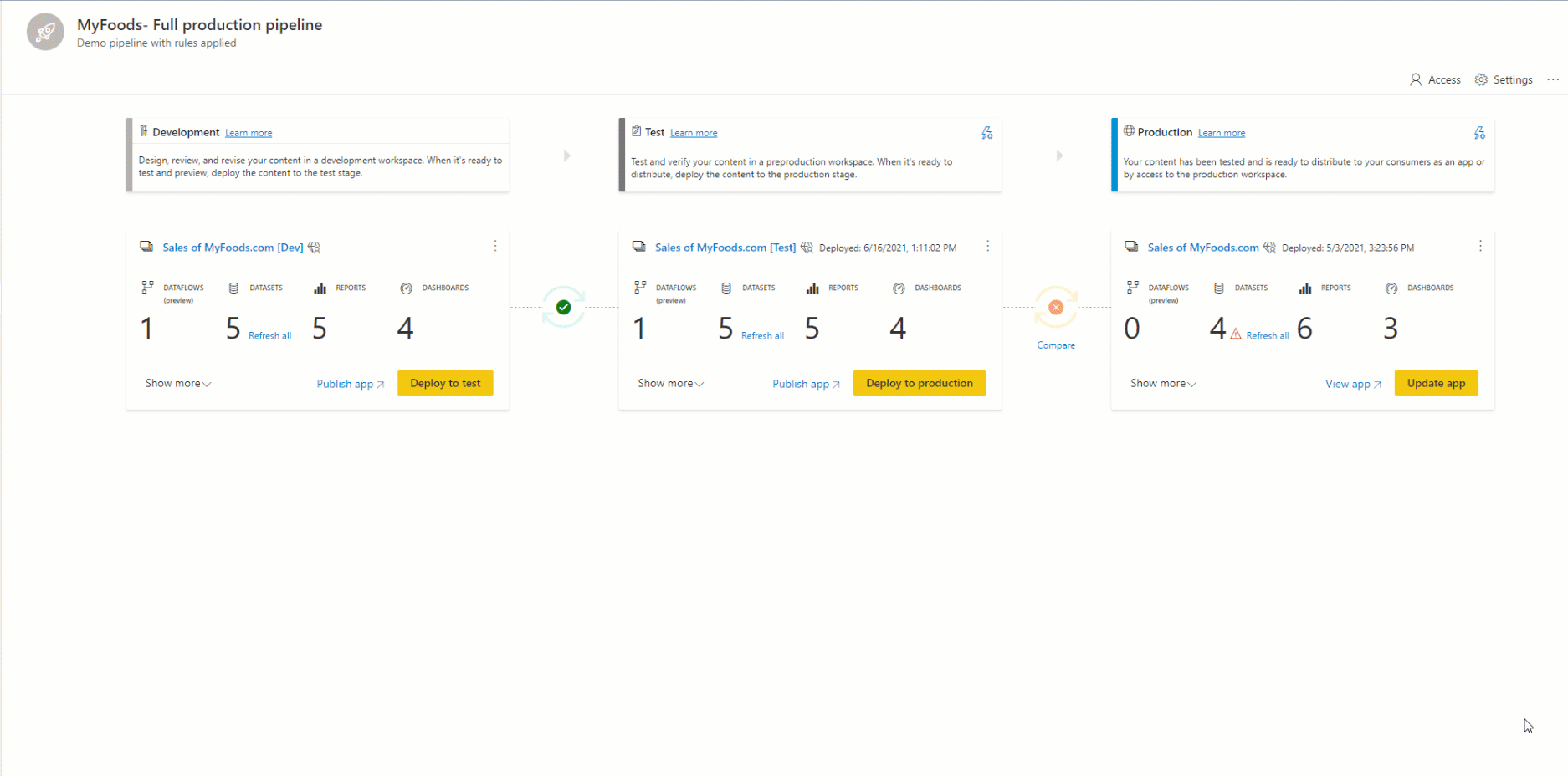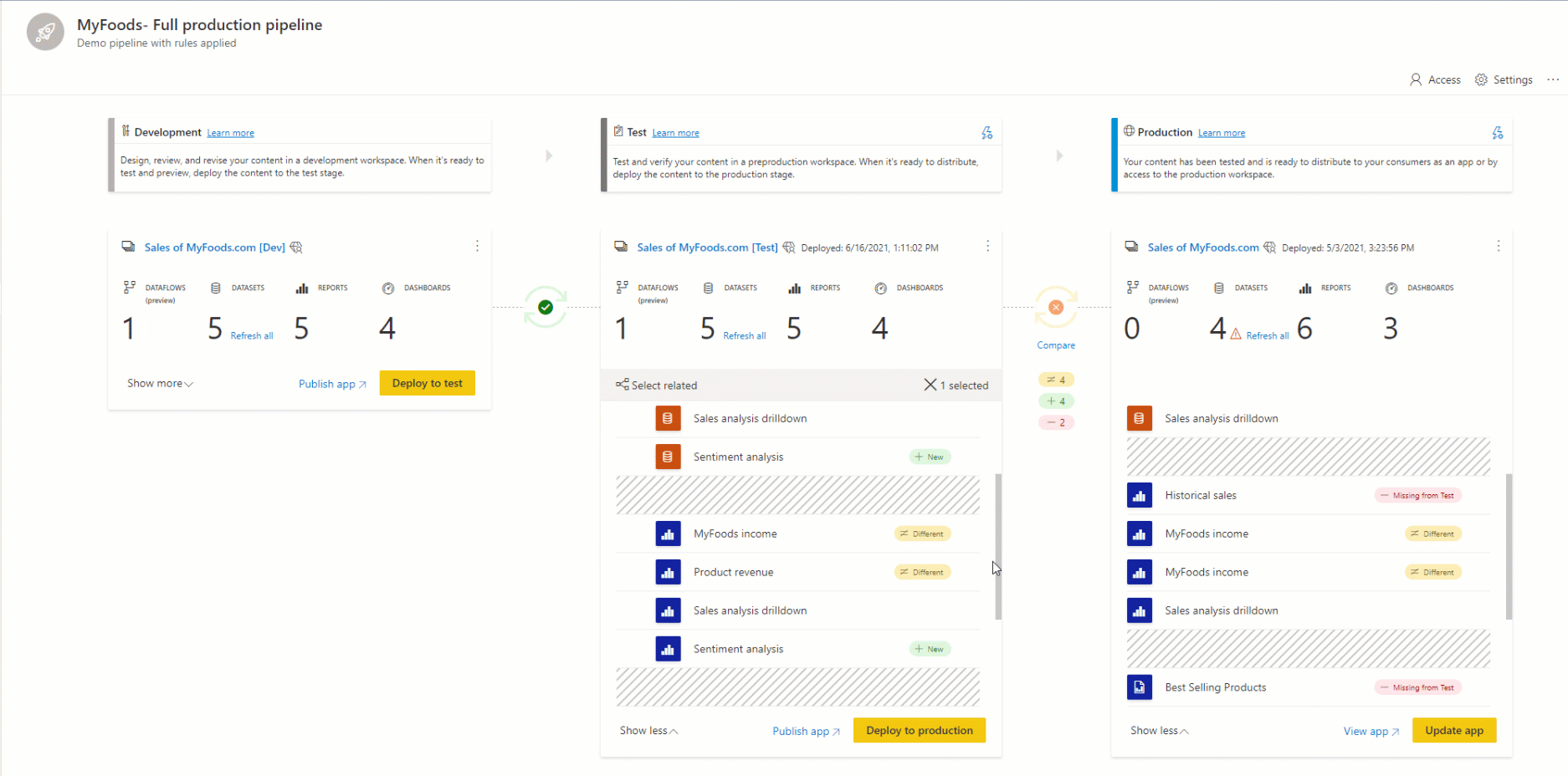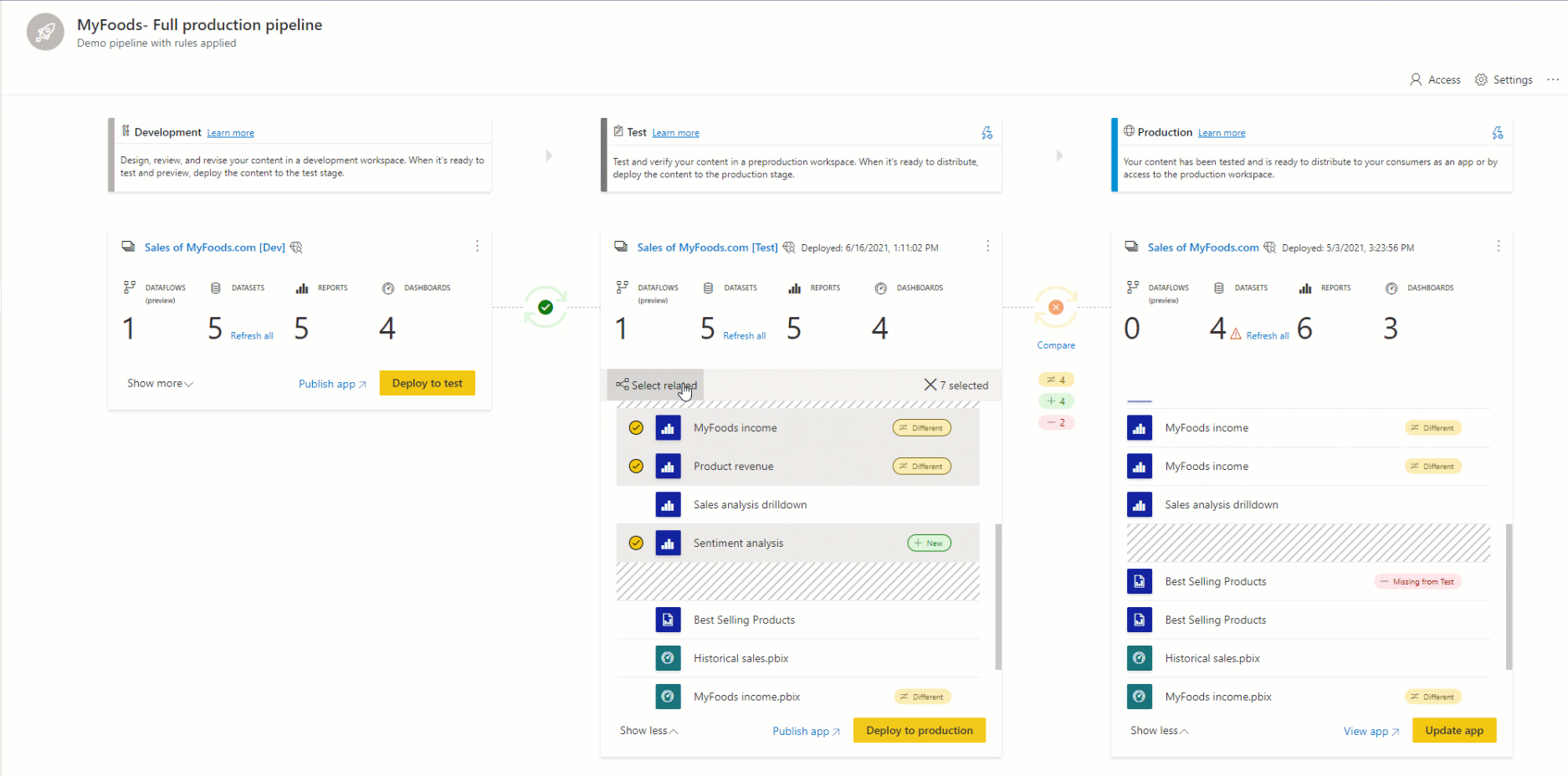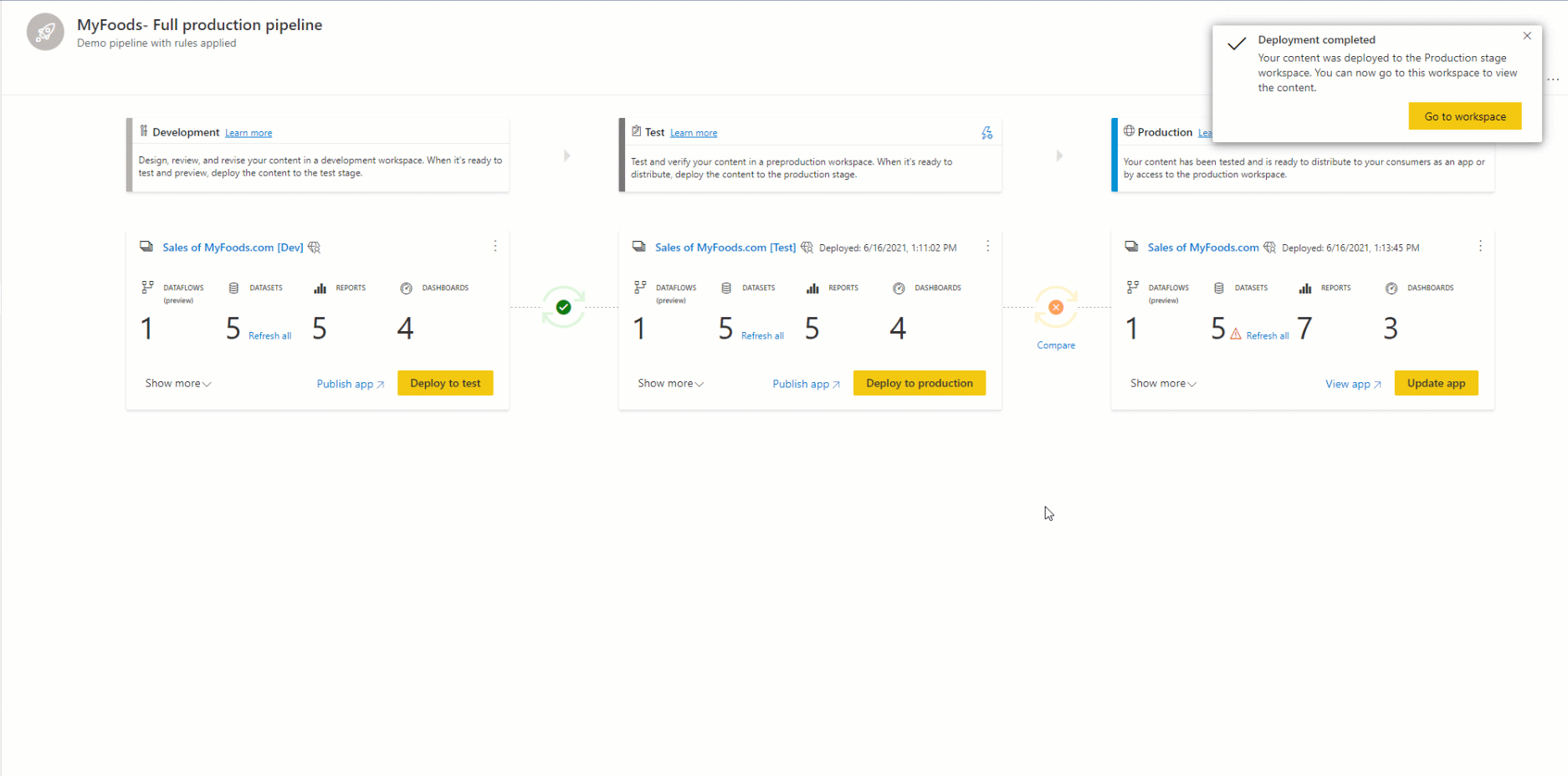
Pipelinestruktur
Sie können entscheiden, wie viele Phasen Sie in Ihrer Bereitstellungspipeline verwenden möchten. Es kann zwischen zwei und zehn Stufen geben. Wenn Sie eine Pipeline erstellen, werden die drei typischen Standardphasen als Ausgangspunkt angegeben. Sie können jedoch Phasen nach Ihren Anforderungen hinzufügen, löschen oder umbenennen. Unabhängig davon, wie viele Phasen Sie verwenden, sind die allgemeinen Konzepte gleich:
-
In der ersten Phase von Bereitstellungspipelines, laden Sie zusammen mit anderen Ersteller*in neue Inhalte hoch. Sie können in dieser oder einer anderen Phase erstellen und entwickeln.
-
Nachdem Sie alle erforderlichen Änderungen an Ihren Inhalten vorgenommen haben, können Sie in die Testphase übergehen. Laden Sie die geänderten Inhalte hoch, damit sie in diese Testphase verschoben werden können. Es folgen drei Beispiele dafür, was in der Testumgebung möglich ist:
Freigeben von Inhalten für Tester und Prüfer
Laden und Ausführen von Tests mit größeren Datenmengen
Testen Ihrer App, um zu prüfen, wie sie für Ihre Endbenutzer aussieht
-
Nachdem Sie den Inhalt getestet haben, können Sie in der Produktionsphase die endgültige Version Ihres Inhalts an Benutzer in den Geschäftsbereichen des Unternehmens weitergeben.
Artikel-Pairing
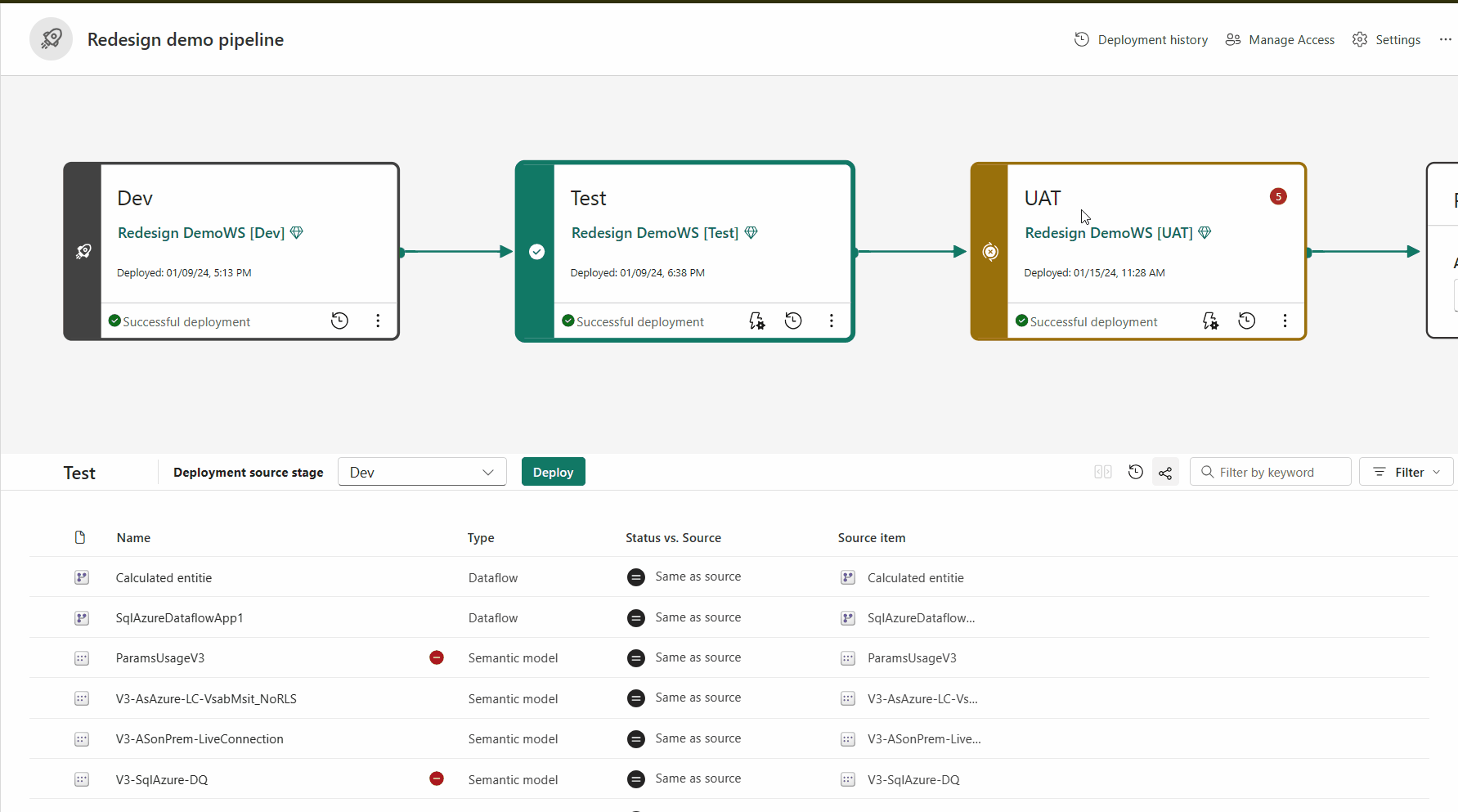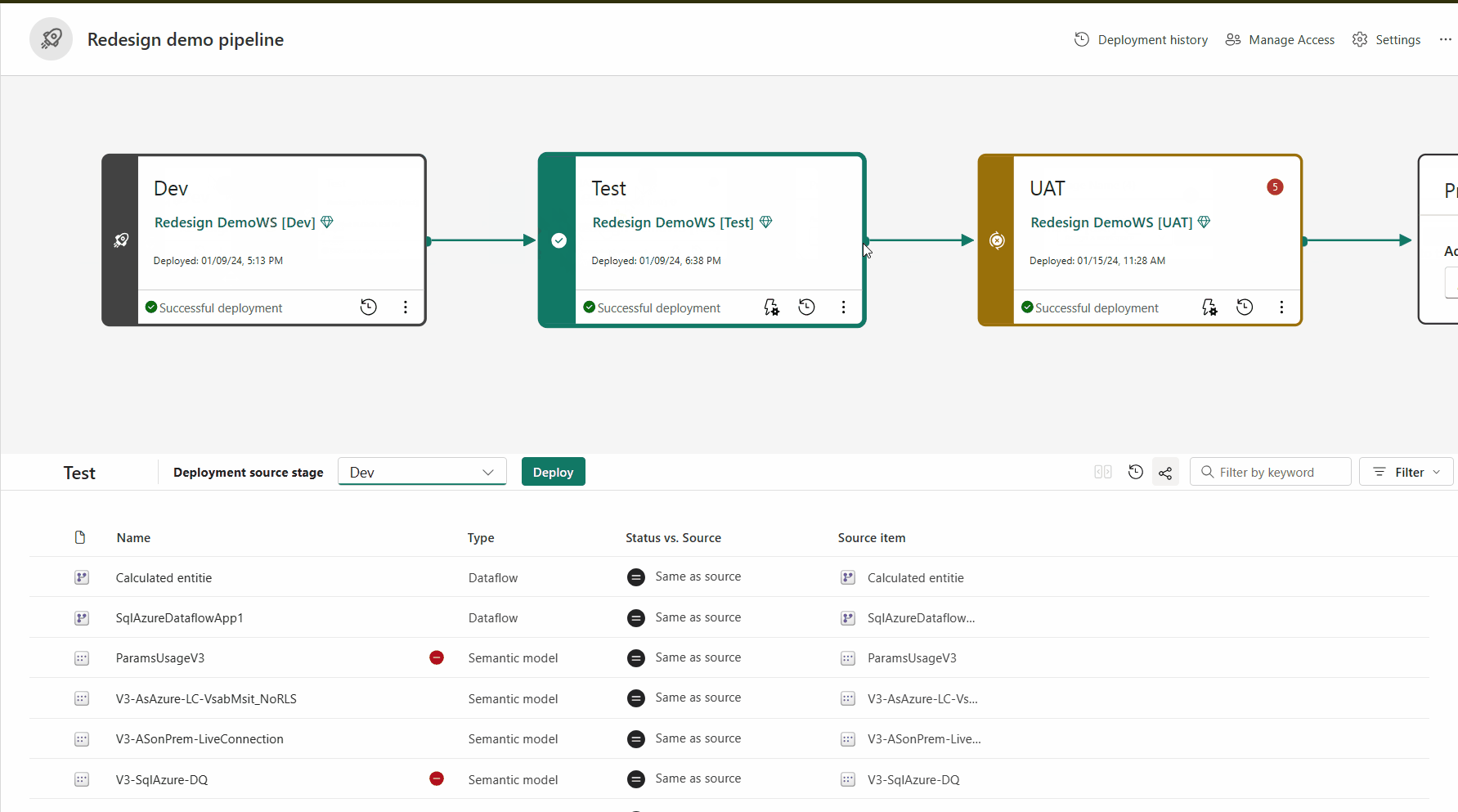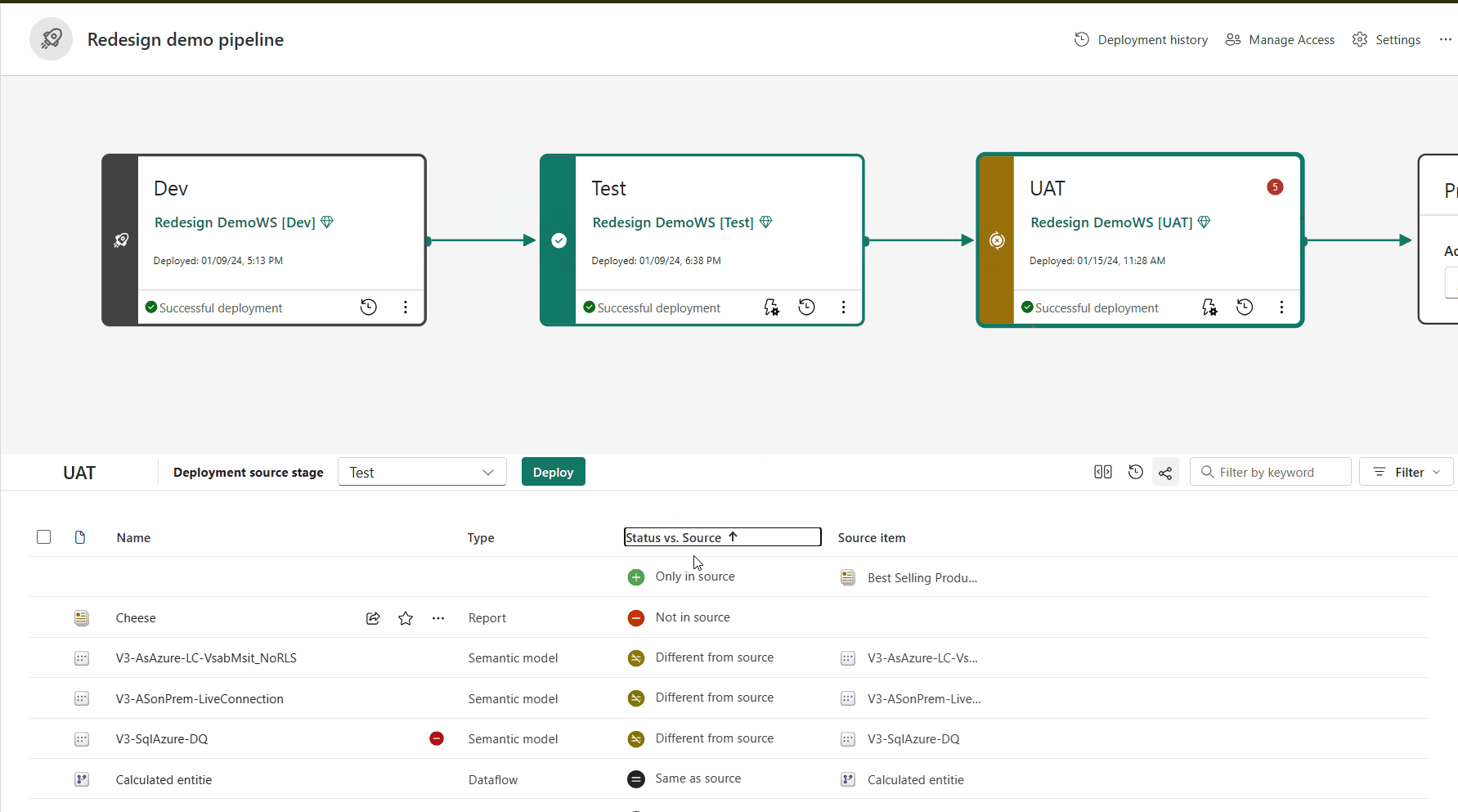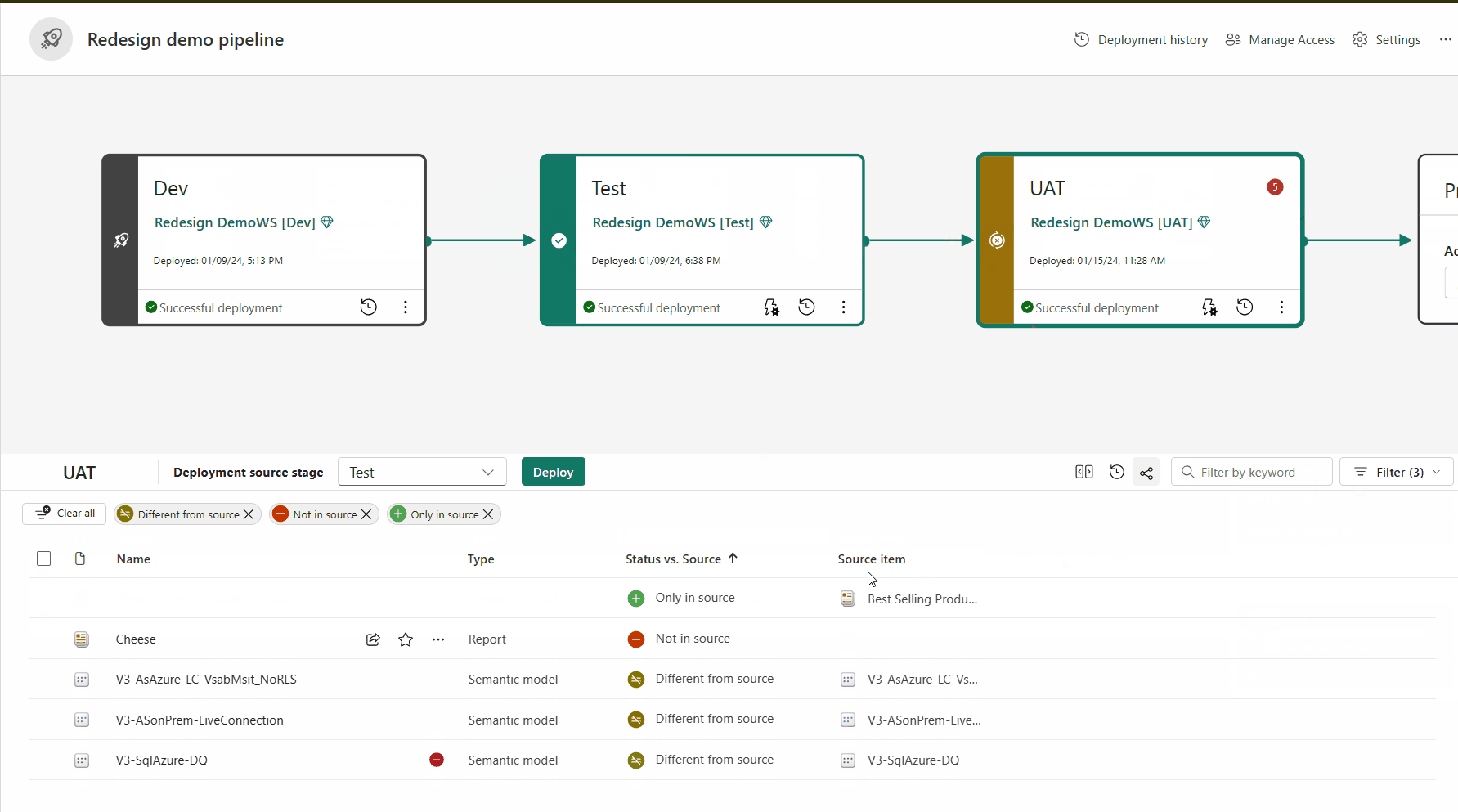
Pairing ist der Prozess, bei dem ein Artikel (z. B. ein Bericht, ein Dashboard oder ein semantisches Modell) in einer Phase der Bereitstellungspipeline mit demselben Artikel in der benachbarten Phase verknüpft wird. Das Pairing findet statt, wenn Sie einen Arbeitsbereich einer Bereitstellungsstufe zuweisen oder wenn Sie neue, nicht gepaarte Inhalte von einer Stufe auf einer anderen bereitstellen (eine saubere Bereitstellung).
Es ist wichtig zu verstehen, wie die Kopplung funktioniert, um zu verstehen, wann Elemente kopiert werden, wann sie überschrieben werden und wenn eine Bereitstellung fehlschlägt, wenn die Bereitstellungsfunktion verwendet wird.
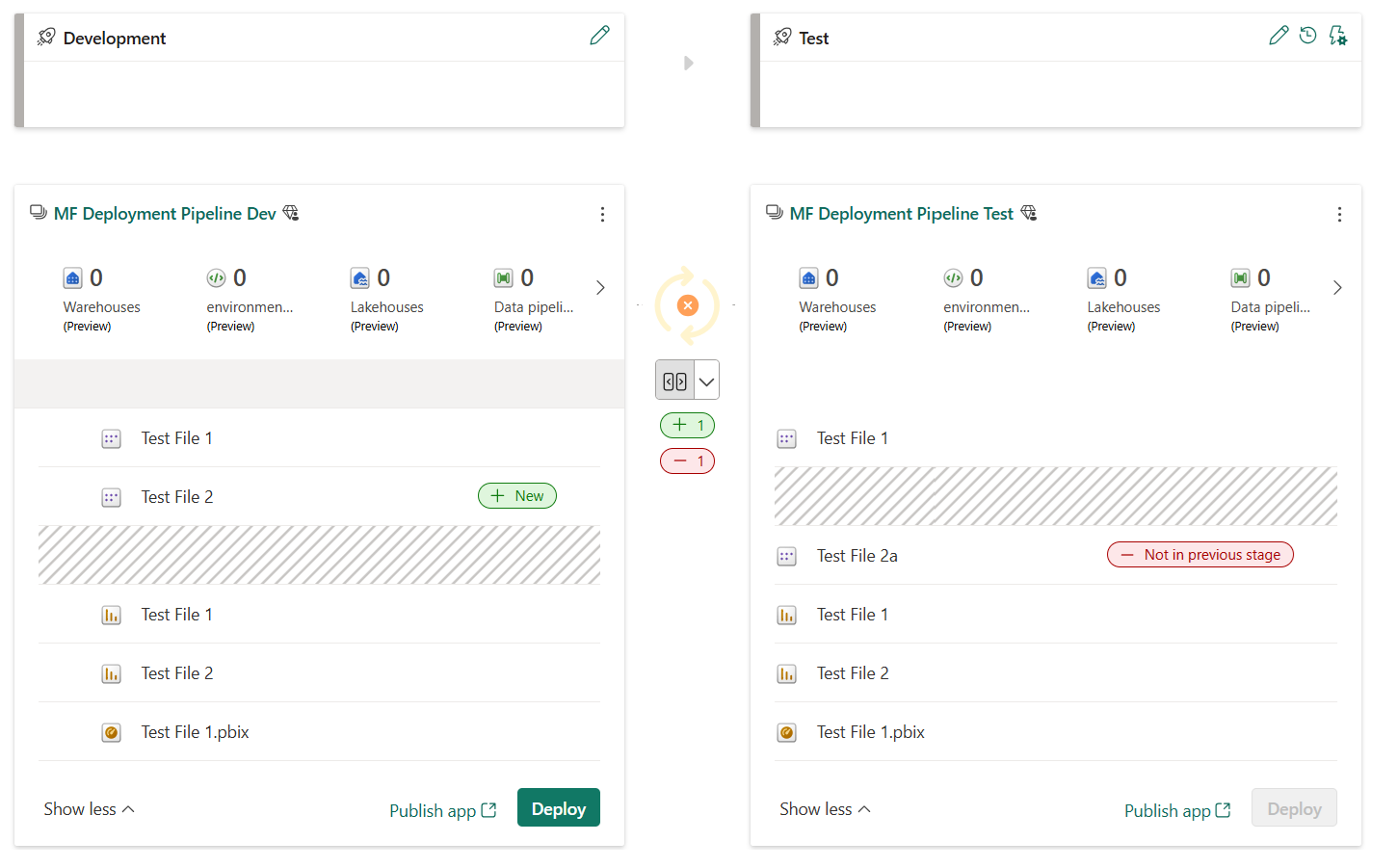
Wenn Elemente nicht gekoppelt sind, auch wenn sie scheinbar identisch sind (denselben Namen, Typ und Ordner aufweisen), überschreiben sie nicht für eine Bereitstellung. Stattdessen wird eine Duplikatkopie erstellt und mit dem Element in der vorherigen Phase gekoppelt.
Gekoppelte Elemente werden in derselben Zeile in der Pipelineinhaltsliste angezeigt. Artikel, die nicht gepaart sind, erscheinen in einer Zeile für sich:
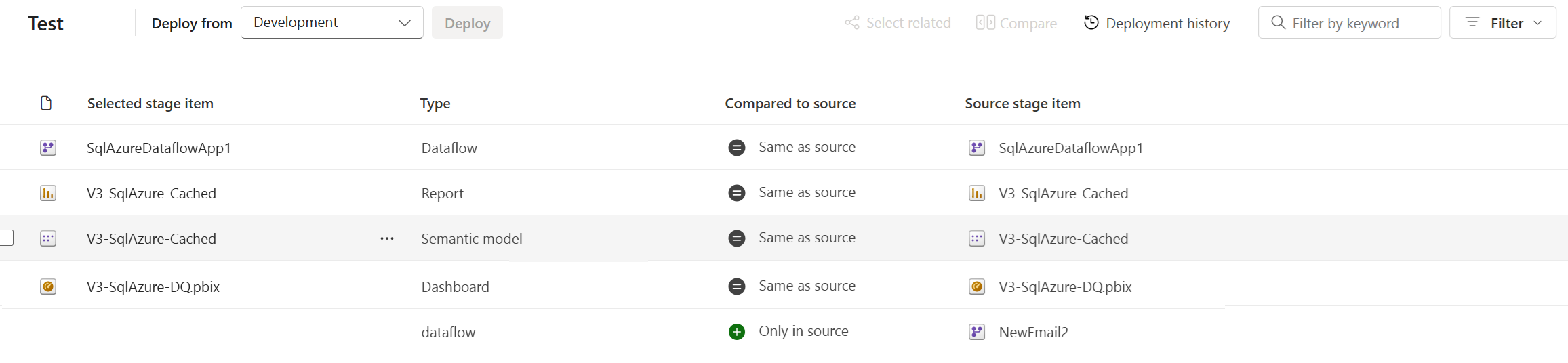
- Gekoppelte Elemente bleiben gekoppelt, auch wenn Sie deren Namen ändern. Daher können gekoppelte Elemente unterschiedliche Namen haben.
- Elemente, die hinzugefügt wurden, nachdem der Arbeitsbereich einer Pipeline zugewiesen wurde, werden nicht automatisch gekoppelt. Daher können Sie identische Elemente in benachbarten Arbeitsbereichen haben, die nicht gekoppelt sind.
Eine ausführliche Erläuterung, welche Elemente gekoppelt sind und wie die Kopplung funktioniert, finden Sie unter Artikel-Pairing.
Bereitstellungsmethode
Um Inhalte in einer anderen Phase bereitzustellen, muss mindestens ein Element ausgewählt werden. Wenn Sie Inhalte aus einer Phase in eine andere bereitstellen, überschreiben die Elemente, die aus der Quellstufe kopiert werden, das gekoppelte Element in der Phase, in der Sie sich gemäß den Kopplungsregelnbefinden. Elemente, die in der Quellstufe nicht vorhanden sind, bleiben wie folgt.
Nachdem Sie Bereitstellen ausgewählthaben, erhalten Sie eine Bestätigungsmeldung.
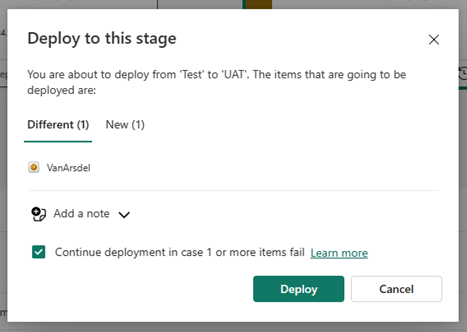
Erfahren Sie mehr darüber , welche Elementeigenschaften in die nächste Phasekopiert werden und welche Eigenschaften nicht kopiert werden, im Bereitstellungsprozessverstehen.
Automation
Sie können Inhalte auch programmgesteuert bereitstellen, indem Sie die REST-APIs für Bereitstellungspipelines verwenden. Weitere Informationen zum Automatisierungsprozess finden Sie unter Automatisieren Ihrer Bereitstellungspipeline mit APIs und DevOps.