Apache Spark-Runtimes in Fabric
Microsoft Fabric Runtime ist eine in Azure integrierte Plattform, die auf Apache Spark basiert und die Ausführung und Verwaltung von Datentechnik- und Data Science-Umgebungen ermöglicht. Sie kombiniert wichtige Komponenten aus internen und Open-Source-Quellen und bietet Kunden eine umfassende Lösung. Der Einfachheit halber bezeichnen wir Microsoft Fabric Runtime unterstützt von Apache Spark als Fabric Runtime.
Hauptkomponenten von Fabric Runtime:
Apache Spark: Eine leistungsstarke verteilte Open-Source-Computingbibliothek, die umfangreiche Datenverarbeitungs- und Analyseaufgaben ermöglicht. Apache Spark bietet eine vielseitige und leistungsstarke Plattform für Data Engineering- und Data Science-Umgebungen.
Delta Lake: Eine Open-Source-Speicherebene, die ACID-Transaktionen und andere Datenzuverlässigkeitsfeatures in Apache Spark zur Verfügung stellt. Delta Lake ist in Fabric Runtime integriert, verbessert die Datenverarbeitungsfunktionen und stellt Datenkonsistenz für mehrere gleichzeitige Vorgänge sicher.
Das Native Execution Engine - ist eine transformative Erweiterung für Apache Spark-Workloads, die erhebliche Leistungsvorteile bieten, indem Spark-Abfragen direkt auf Lakehouse-Infrastruktur ausgeführt werden. Nahtlos integriert erfordert es keine Codeänderungen und vermeidet die Herstellereinsperrung, die sowohl Parquet- als auch Delta-Formate für Apache Spark APIs in Runtime 1.3 (Spark 3.5) unterstützt. Dieses Modul erhöht die Abfragegeschwindigkeiten bis zu viermal schneller als herkömmliches OSS Spark, wie von der TPC-DS 1TB-Benchmark gezeigt, was die Betriebskosten reduziert und die Effizienz in verschiedenen Datenaufgaben verbessert, einschließlich Datenaufnahme, ETL, Analyse und interaktiver Abfragen. Basierend auf Metas Velox und Intels Apache Gluten optimiert es den Ressourceneinsatz bei der Behandlung verschiedener Datenverarbeitungsszenarien.
Pakete auf Standardebene für Java/Scala, Python und R zur Unterstützung verschiedener Programmiersprachen und Umgebungen. Diese Pakete werden automatisch installiert und konfiguriert, sodass Entwickler ihre bevorzugten Programmiersprachen auf Datenverarbeitungsaufgaben anwenden können.
Die Microsoft Fabric Runtime basiert auf einem stabilen Open-Source-Betriebssystem, das die Kompatibilität mit verschiedenen Hardwarekonfigurationen und Systemanforderungen gewährleistet.
Nachfolgend finden Sie einen umfassenden Vergleich der wichtigsten Komponenten, einschließlich Apache Spark-Versionen, unterstützten Betriebssystemen, Java, Scala, Python, Delta Lake und R für Apache Spark-basierte Runtimes innerhalb der Microsoft Fabric-Plattform.
Tipp
Verwenden Sie immer die neueste GA-Laufzeitversion für Ihre Produktionsworkload, die derzeit Runtime 1.3 ist.
| Runtime 1.1 | Runtime 1.2 | Runtime 1.3 | |
|---|---|---|---|
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Betriebssystem | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Besuchen Sie Runtime 1.1, Runtime 1.2 oder Runtime 1.3, um Details, neue Features, Verbesserungen und Migrationsszenarien für die spezifische Laufzeitversion zu erkunden.
Fabric-Optimierungen
In Microsoft Fabric enthalten sowohl das Spark-Modul als auch die Delta Lake-Implementierungen plattformspezifische Optimierungen und Features. Diese Features sind so konzipiert, dass systemeigene Integrationen innerhalb der Plattform verwendet werden. Es ist wichtig zu beachten, dass alle diese Features deaktiviert werden können, um standardmäßige Spark- und Delta Lake-Funktionen zu erreichen. Die Fabric-Runtimes für Apache Spark umfassen:
- Die vollständige Open-Source-Version von Apache Spark.
- Eine Sammlung von fast 100 integrierten, unterschiedlichen Leistungsverbesserungen für Abfragen. Zu diesen Verbesserungen gehören Features wie Partitionszwischenspeicherung (dies ermöglicht dem FileSystem-Partitionscache, Metastoreaufrufe zu reduzieren) und Kreuzprodukt zur geschachtelten Abfrage „Projektion von Skalar“.
- Integrierter intelligenter Cache.
Innerhalb der Fabric-Runtime für Apache Spark und Delta Lake gibt es native Writer-Funktionen, die zwei wichtige Zwecke erfüllen:
- Sie bieten differenzierte Leistung für das Schreiben von Workloads und optimieren den Schreibvorgang.
- Sie werden standardmäßig auf die V-Order-Optimierung von Delta-Parquet-Dateien festgelegt. Die Optimierung von Delta Lake V-Order ist entscheidend für die Bereitstellung überlegener Leseleistung für alle Fabric-Engines. Um ein tieferes Verständnis darüber zu erhalten, wie es funktioniert und wie es verwaltet wird, lesen Sie den dedizierten Artikel zur Optimierung der Delta Lake-Tabelle und V-Order.
Unterstützung mehrerer Runtimes
Fabric unterstützt mehrere Runtimes und bietet Benutzern die Flexibilität, nahtlos zwischen ihnen zu wechseln und das Risiko von Inkompatibilitäten oder Unterbrechungen zu minimieren.
Standardmäßig verwenden alle neuen Arbeitsbereiche die neueste Runtimeversion, die derzeit Runtime 1.3 ist.
Um die Runtimeversion auf Arbeitsbereichsebene zu ändern, wechseln Sie zu „Arbeitsbereichseinstellungen“ > „Data Engineering/Science“ > „Spark Compute“ > „Workspace Level Default“, und wählen Sie Ihre gewünschte Runtime aus den verfügbaren Optionen aus.
Nachdem Sie diese Änderung vorgenommen haben, werden alle vom System erstellten Elemente innerhalb des Arbeitsbereichs, einschließlich Lakehouses, SJDs und Notebooks, mit der neu ausgewählten Runtime-Version auf Arbeitsbereichsebene ab der nächsten Spark-Sitzung ausgeführt. Wenn Sie derzeit ein Notebook mit einer vorhandenen Sitzung für einen Auftrag oder eine Lakehouse-bezogene Aktivität verwenden, wird diese Spark-Sitzung unverändert fortgesetzt. Ab der nächsten Sitzung oder dem nächsten Auftrag wird jedoch die ausgewählte Laufzeitversion angewendet.
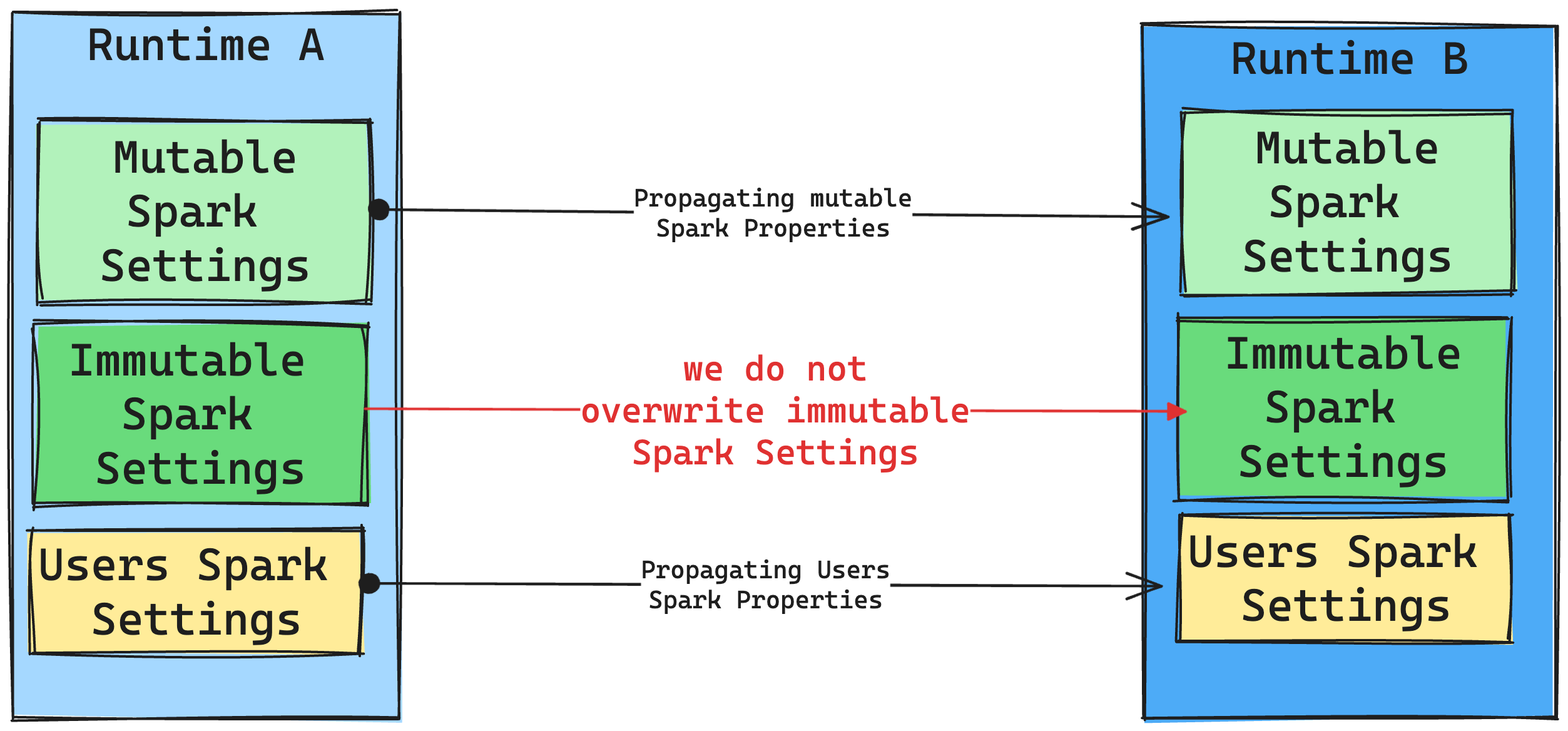
Folgen von Runtime-Änderungen an Spark-Einstellungen
Im Allgemeinen möchten wir alle Spark-Einstellungen migrieren. Wenn wir jedoch feststellen, dass die Spark-Einstellung nicht mit Runtime B kompatibel ist, geben wir eine Warnmeldung aus und verzichten auf die Implementierung der Einstellung.
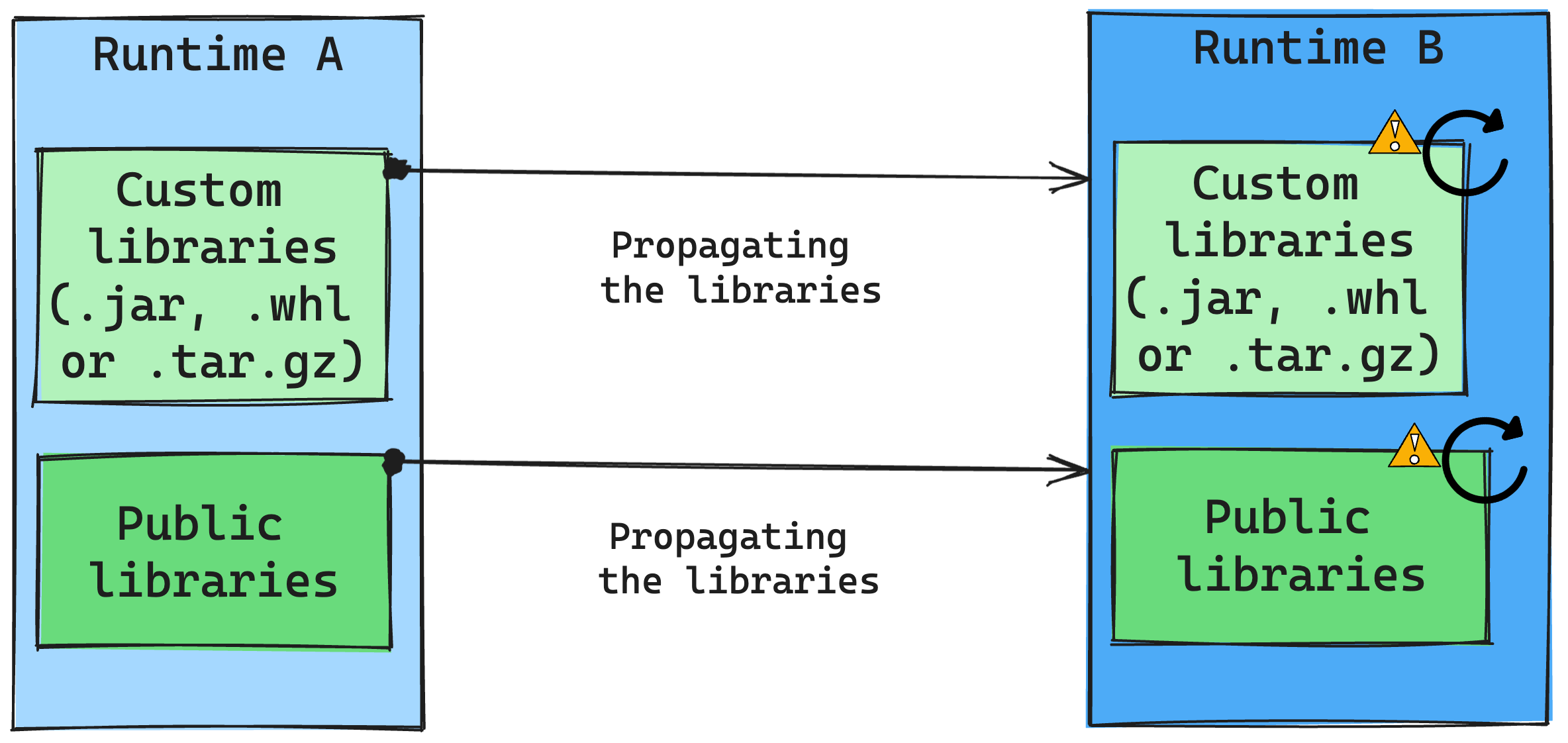
Auswirkungen von Runtime-Änderungen auf die Bibliotheksverwaltung
Im Allgemeinen besteht unser Ansatz darin, alle Bibliotheken von Runtime A zu Runtime B zu migrieren, einschließlich öffentlicher und benutzerdefinierter Runtimes. Wenn die Python- und R-Versionen unverändert bleiben, sollten die Bibliotheken ordnungsgemäß funktionieren. Für Jars gibt es jedoch eine erhebliche Wahrscheinlichkeit, dass sie aufgrund von Änderungen in Abhängigkeiten und anderen Faktoren wie Änderungen in Scala, Java, Spark und dem Betriebssystem möglicherweise nicht funktionieren.
Benutzer*innen sind für das Aktualisieren oder Ersetzen von Bibliotheken verantwortlich, die nicht mit Runtime B funktionieren. Bei einem Konflikt, d. h., wenn Runtime B eine Bibliothek enthält, die ursprünglich in Runtime A definiert wurde, versucht unser Bibliotheksverwaltungssystem, die erforderliche Abhängigkeit für Runtime B basierend auf den Benutzereinstellungen zu erstellen. Der Erstellungsprozess ist jedoch nicht erfolgreich, wenn ein Konflikt auftritt. Im Fehlerprotokoll können Benutzer*innen sehen, welche Bibliotheken Konflikte verursachen und Anpassungen an ihren Versionen oder Spezifikationen vornehmen.
Upgrade des Delta Lake-Protokolls
Delta Lake-Features sind immer abwärtskompatibel und stellen sicher, dass Tabellen, die in einer niedrigeren Delta Lake-Version erstellt wurden, nahtlos mit höheren Versionen interagieren können. Wenn jedoch bestimmte Features aktiviert sind (z. B. mithilfe der delta.upgradeTableProtocol(minReaderVersion, minWriterVersion)-Methode kann die Vorwärtskompatibilität mit niedrigeren Delta Lake-Versionen beeinträchtigt werden. In solchen Fällen ist es wichtig, Workloads zu ändern, die auf die aktualisierten Tabellen verweisen, um sich an eine Delta Lake-Version auszurichten, die die Kompatibilität wahrt.
Jede Delta-Tabelle ist einer Protokollspezifikation zugeordnet, die die von ihr unterstützten Features definiert. Anwendungen, die mit der Tabelle interagieren, entweder zum Lesen oder Schreiben, stützen sich auf diese Protokollspezifikation, um festzustellen, ob sie mit dem Featuresatz der Tabelle kompatibel sind. Wenn eine Anwendung nicht in der Lage ist, ein Feature handzuhaben, das im Protokoll der Tabelle unterstützt wird, kann sie nicht aus dieser Tabelle lesen oder in diese Tabelle schreiben.
Die Protokollspezifikation ist in zwei verschiedene Komponenten unterteilt: das Leseprotokoll und das Schreibprotokoll. Besuchen Sie die Seite „Wie verwaltet Delta Lake die Featurekompatibilität?“, um Details dazu zu lesen.

Benutzer können den Befehl delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) in der PySpark-Umgebung und in Spark SQL und Scala ausführen. Mit diesem Befehl können sie eine Aktualisierung in der Delta-Tabelle initiieren.
Es ist wichtig zu beachten, dass Benutzer beim Ausführen dieses Upgrades eine Warnung erhalten, die angibt, dass das Upgrade der Delta-Protokollversion ein nicht umkehrbarer Prozess ist. Dies bedeutet, dass das Update nach der Ausführung nicht rückgängig gemacht werden kann.
Protokollversionsupgrades können sich möglicherweise auf die Kompatibilität vorhandener Delta Lake-Tabellenleser, -schreiber oder beide auswirken. Daher ist es ratsam, mit Vorsicht vorzugehen und die Protokollversion nur bei Bedarf zu aktualisieren, z. B. bei der Einführung neuer Features in Delta Lake.
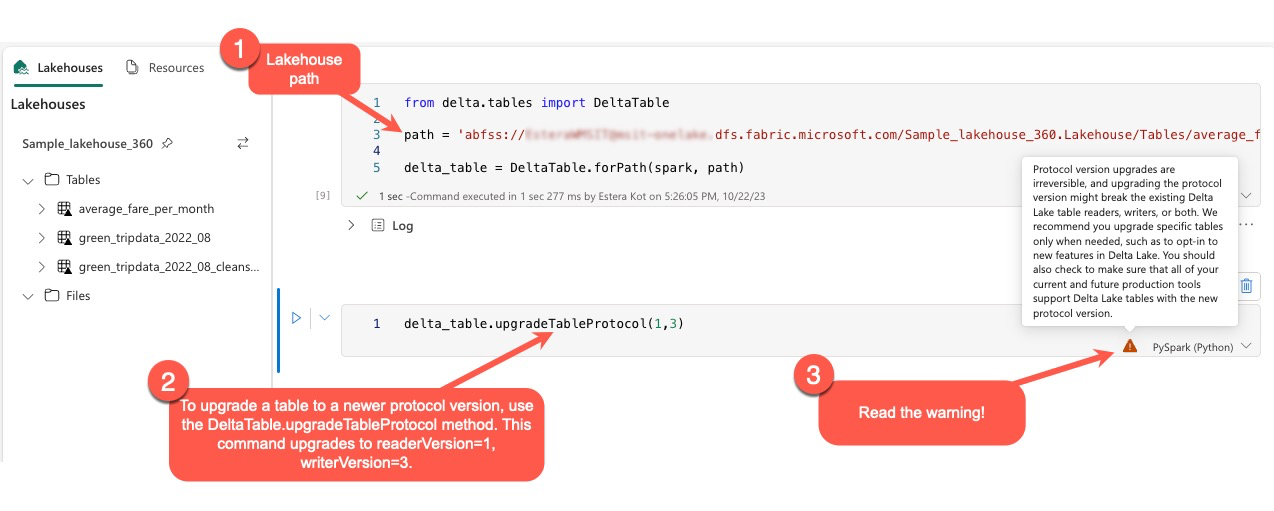
Darüber hinaus sollten Benutzer überprüfen, ob alle aktuellen und zukünftigen Produktionsworkloads und -prozesse mit Delta Lake-Tabellen kompatibel sind, indem sie die neue Protokollversion verwenden, um einen nahtlosen Übergang sicherzustellen und potenzielle Unterbrechungen zu verhindern.
Delta 2.2- vs Delta 2.4-Änderungen
In der neuesten Fabric-Runtime, Version 1.3 und Fabric Runtime, Version 1.2 ist das Standardtabellenformat (spark.sql.sources.default) jetzt delta. In früheren Versionen von Fabric-Runtime, Version 1.1 und auf allen Synapse-Runtimes für Apache Spark mit Spark 3.3 oder darunter, wurde das Standardtabellenformat als parquet definiert. Überprüfen Sie die Tabelle mit Apache Spark-Konfigurationsdetails auf Unterschiede zwischen Azure Synapse Analytics und Microsoft Fabric.
Alle Tabellen, die mit Spark SQL, PySpark, Scala Spark und Spark R erstellt wurden, erstellen die Tabelle standardmäßig als delta, wenn der Tabellentyp nicht angegeben wird. Wenn Skripts das Tabellenformat explizit festlegen, wird dies berücksichtigt. Der Befehl USING DELTA in Spark create table commands wird redundant.
Skripts, die ein Parquet-Tabellenformat erwarten oder annehmen, sollten überarbeitet werden. Die folgenden Befehle werden in Delta-Tabellen nicht unterstützt:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE