series_fir()
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Wendet einen FIR-Filter (Finite Impulse Response) auf eine Datenreihe an.
Die Funktion verwendet einen Ausdruck, der ein dynamisches numerisches Array als Eingabe enthält, und wendet einen Finite Impulse Response-Filter an. Durch Die Angabe der filter Koeffizienten kann sie zum Berechnen eines gleitenden Mittelwerts, Glättung, Änderungserkennung und vieler weiterer Anwendungsfälle verwendet werden. Die Funktion verwendet die Spalte, die das dynamische Array und ein statisches dynamisches Array der Koeffizienten des Filters als Eingabe enthält, und wendet den Filter auf die Spalte an. Sie gibt eine neue dynamische Array-Spalte mit der gefilterten Ausgabe aus.
Syntax
series_fir(Reihenfilter, [, normalisieren[, Mitte]])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| Reihe | dynamic |
✔️ | Ein Array numerischer Werte. |
| filter | dynamic |
✔️ | Ein Array numerischer Werte, die die Koeffizienten des Filters enthalten. |
| normalize | bool |
Gibt an, ob der Filter normalisiert werden soll. Das heißt, dividiert durch die Summe der Koeffizienten. Wenn der Filter negative Werte enthält, muss die Normalisierung als false, andernfalls ergebnis angegeben werden null. Wenn nicht angegeben, wird je nach Vorhandensein negativer Werte im Filter ein Standardwert true angenommen. Wenn der Filter mindestens einen negativen Wert enthält, wird als Normalisierung angenommen false. |
|
| Zentrum | bool |
Gibt an, ob der Filter symmetrisch auf ein Zeitfenster vor und nach dem aktuellen Punkt oder in einem Zeitfenster vom aktuellen Punkt nach hinten angewendet wird. Standardmäßig ist falseCenter , das dem Szenario von Streamingdaten entspricht, sodass wir nur den Filter auf die aktuellen und älteren Punkte anwenden können. Für die Ad-hoc-Verarbeitung können Sie sie truejedoch so festlegen, dass sie mit der Zeitreihe synchronisiert bleibt. Sehen Sie sich hierzu die Beispiele unten an. Dieser Parameter steuert die Gruppenverzögerung des Filters. |
Tipp
Normalisierung ist eine bequeme Möglichkeit, um sicherzustellen, dass die Summe der Koeffizienten 1 ist. Wenn normalisiert ist true, wird der Filter die Datenreihe nicht verstärkt oder abgeschwächt. Beispielsweise könnte der gleitende Mittelwert von vier Bins durch filter=[1,1,1,1] und normalisierttrue= angegeben werden, was einfacher ist als die Eingabe [0,25,0.25.0.25,25,0,25].
Gibt zurück
Eine neue dynamische Arrayspalte, die die gefilterte Ausgabe enthält.
Beispiele
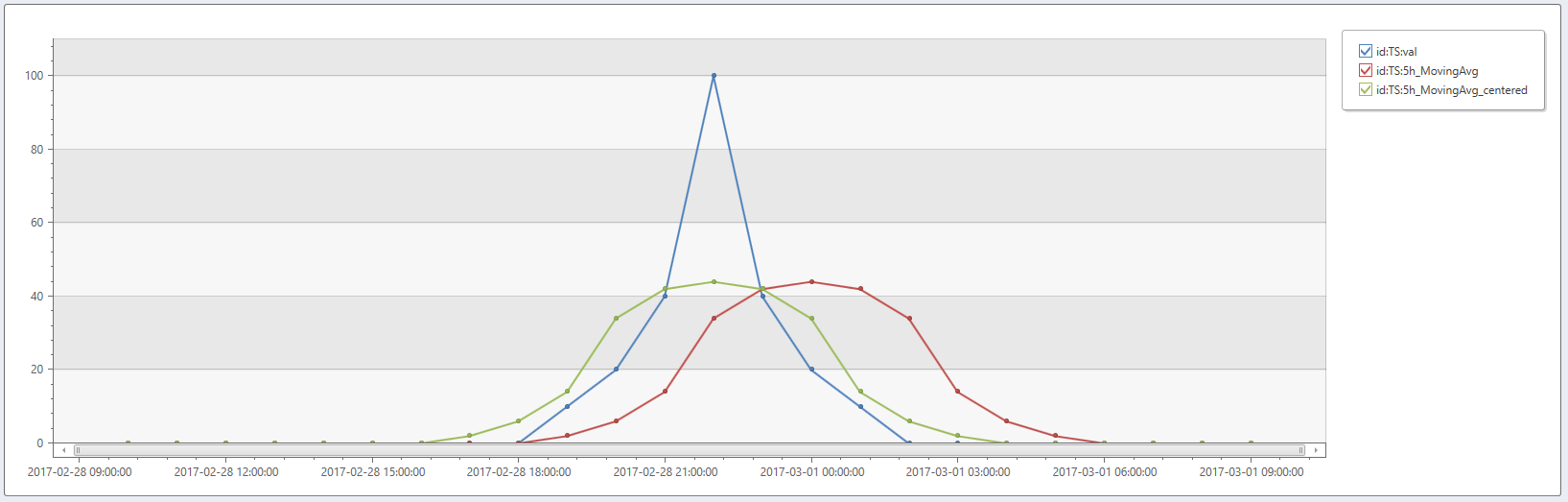
- Berechnen Sie einen gleitenden Durchschnitt von fünf Punkten, indem Sie filter=[1,1,1,1,1] und normalisieren=
true(Standardeinstellung). Beachten Sie den Effekt der Mittefalse= (Standard) vs. :true
range t from bin(now(), 1h) - 23h to bin(now(), 1h) step 1h
| summarize t=make_list(t)
| project
id='TS',
val=dynamic([0, 0, 0, 0, 0, 0, 0, 0, 0, 10, 20, 40, 100, 40, 20, 10, 0, 0, 0, 0, 0, 0, 0, 0]),
t
| extend
5h_MovingAvg=series_fir(val, dynamic([1, 1, 1, 1, 1])),
5h_MovingAvg_centered=series_fir(val, dynamic([1, 1, 1, 1, 1]), true, true)
| render timechart
Diese Abfrage gibt Folgendes zurück:
5h_MovingAvg: Fünf Punkte gleitender Durchschnittfilter. Die Spitze wird geglättet und um (5-1)/2 = 2 Stunden verschoben.
5h_MovingAvg_centered: Identisch, aber durch Festlegen center=truebleibt der Höchstwert an seiner ursprünglichen Position.
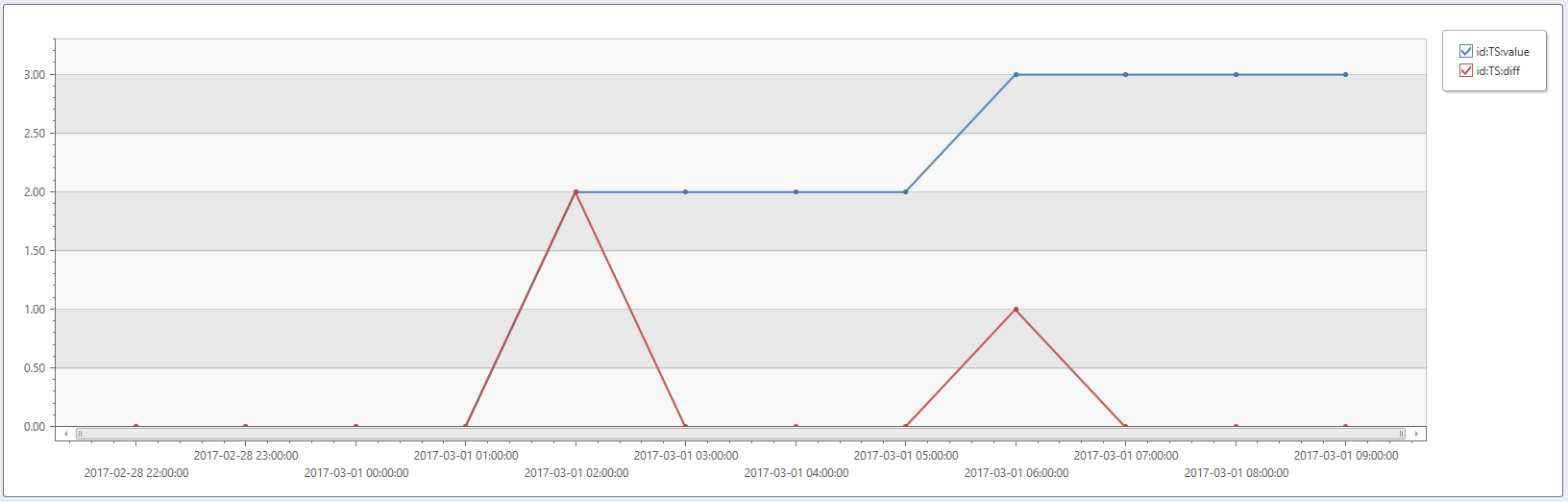
- Wenn Sie die Differenz zwischen einem Punkt und dem vorhergehenden berechnen möchten, legen Sie filter=[1,-1] fest.
range t from bin(now(), 1h) - 11h to bin(now(), 1h) step 1h
| summarize t=make_list(t)
| project id='TS', t, value=dynamic([0, 0, 0, 0, 2, 2, 2, 2, 3, 3, 3, 3])
| extend diff=series_fir(value, dynamic([1, -1]), false, false)
| render timechart