OCR für mehrsprachige Dokumente durchführen
Optische Zeichenerkennung (OCR) ermöglicht Ihnen das Auffinden und Extrahieren von Text aus Bildern oder dem Bildschirm.
Obwohl die meisten Szenarien erfordern, dass Sie Text in einer bestimmten Sprache verarbeiten, gibt es Fälle, in denen die Quellen mehrsprachig sind.
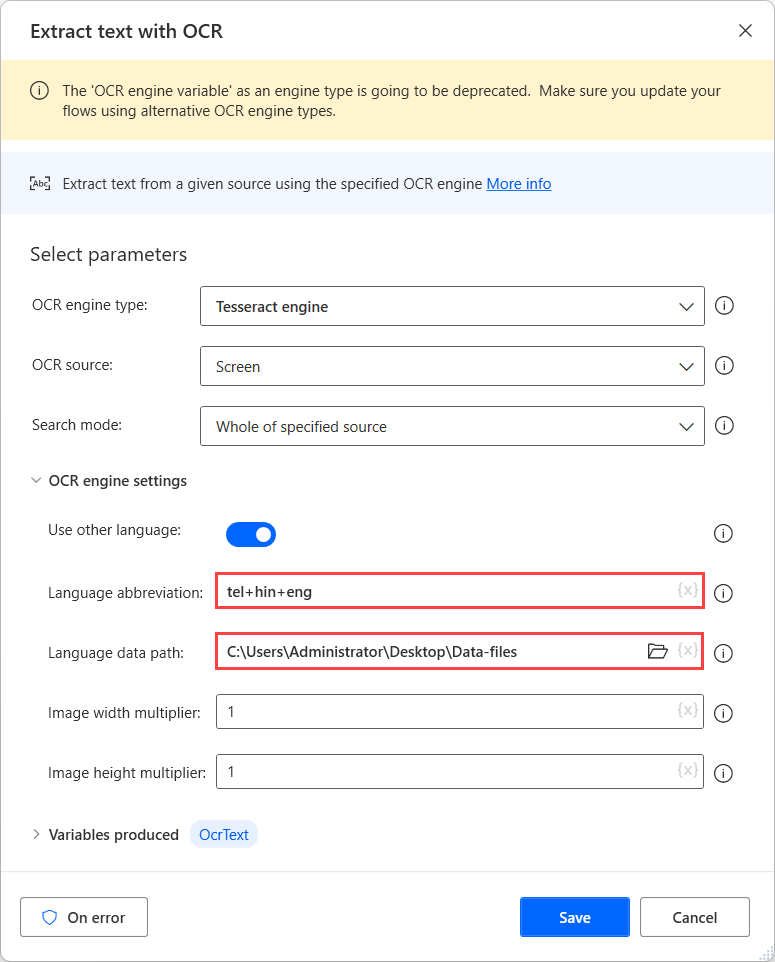
Um OCR an diesen Quellen durchzuführen, verwenden Sie ein Tesseract-Modul in der entsprechenden OCR-Aktion und aktivieren Sie die Option Andere Sprachen verwenden in den Moduleinstellungen.
Wenn die Option Andere Sprachen verwenden aktiviert ist, zeigt die Aktion zwei zusätzliche Einstellungen an: die Felder Sprachkürzel und Sprachdatenpfad.
Das Feld Sprachkürzel zeigt den Modul an, nach welcher Sprache während OCR gesucht werden soll. Das Feld Sprachdatenpfad enthält die Sprachdatendateien (.traineddata) zum Trainieren des OCR-Moduls.
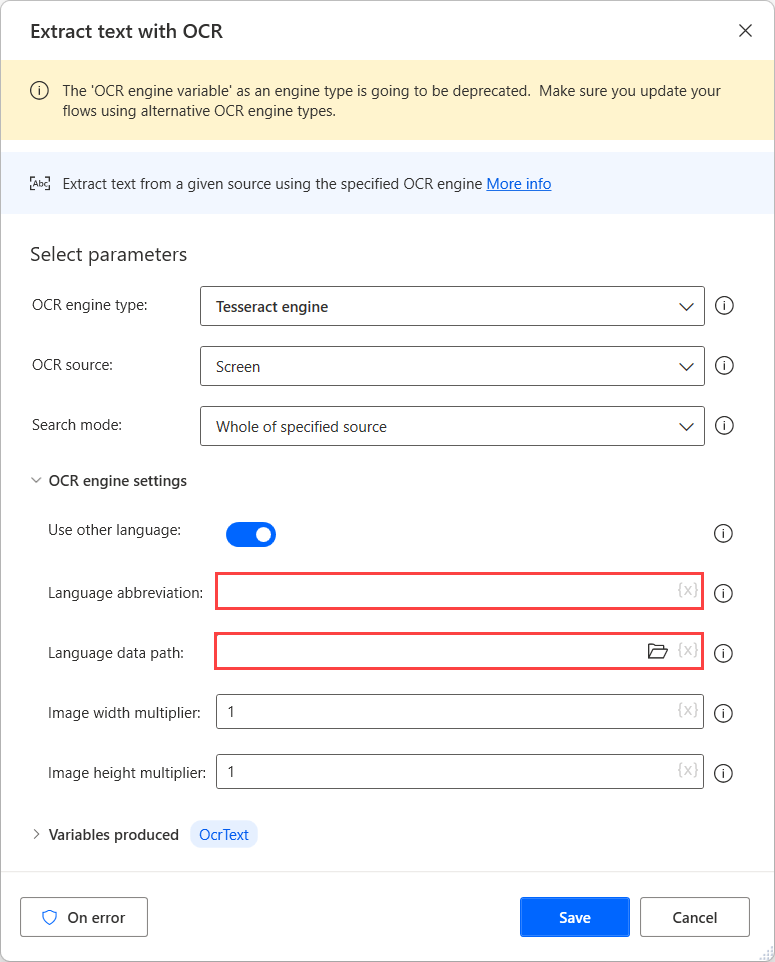
Nachdem Sie die Datendateien für die benötigten Sprachen heruntergeladen haben, verschieben Sie sie in einen gemeinsamen Ordner, um sie unter demselben Pfad verfügbar zu machen.
Wählen Sie als Nächstes den erstellten Ordner im Feld Sprachdatenpfad und tragen Sie die entsprechenden Sprachcodes in das Feld Sprachkürzel ein. Um die Sprachcodes zu trennen, verwenden Sie das Pluszeichen (+).
Notiz
Alle verfügbaren Sprachcodes finden Sie in der Quelle der Sprachdateien. Im folgenden Beispiel stehen die verwendeten Codes für Telugu, Hindi und Englisch.