Grundlegendes zu den Unterschieden zwischen Dataflowtypen
Mithilfe von Dataflows werden Daten extrahiert, transformiert und in ein Speicherziel geladen, wo sie für verschiedene Szenarien genutzt werden können. Da nicht alle Speicherziele dieselben Merkmale aufweisen, unterscheiden sich einige Dataflowfunktionen und Verhaltensweisen je nach dem Speicherziel, in das der Dataflow Daten lädt. Bevor Sie einen Dataflow erstellen, müssen Sie sich darüber im Klaren sein, wie die Daten verwendet werden sollen, und das Speicherziel entsprechend den Anforderungen Ihrer Lösung auswählen.
Die Auswahl eines Speicherziels für einen Dataflow bestimmt den Typ des Dataflows. Ein Dataflow, der Daten in Dataverse-Tabellen lädt, wird als Standard-Dataflowkategorisiert. Dataflows, die Daten in analytische Tabellen laden, werden als analytischer Dataflow kategorisiert.
In Power BI erstellte Dataflows sind immer analytische Dataflows. In Power Apps erstellte Dataflows können entweder standardmäßig oder analytisch sein, je nachdem, was Sie beim Erstellen des Dataflows ausgewählt haben.
Standard-Dataflows
Ein Standard-Dataflow lädt Daten in Dataverse-Tabellen. Standard-Dataflows können nur in Power Apps erstellt werden. Ein Vorteil dieser Art von Dataflow ist, dass jede Anwendung, die von Daten in Dataverse abhängt, mit den Daten arbeiten kann, die durch Standard-Dataflows erstellt wurden. Typische Anwendungen, die Dataverse-Tabellen nutzen, sind Power Apps, Power Automate, AI Builder und Power Virtual Agents.
So erstellen Sie einen Dataflow in Power Apps:
Wählen Sie auf den Registerkarten von Power Apps die Option Mehr aus.
Wählen Sie Dataflows.
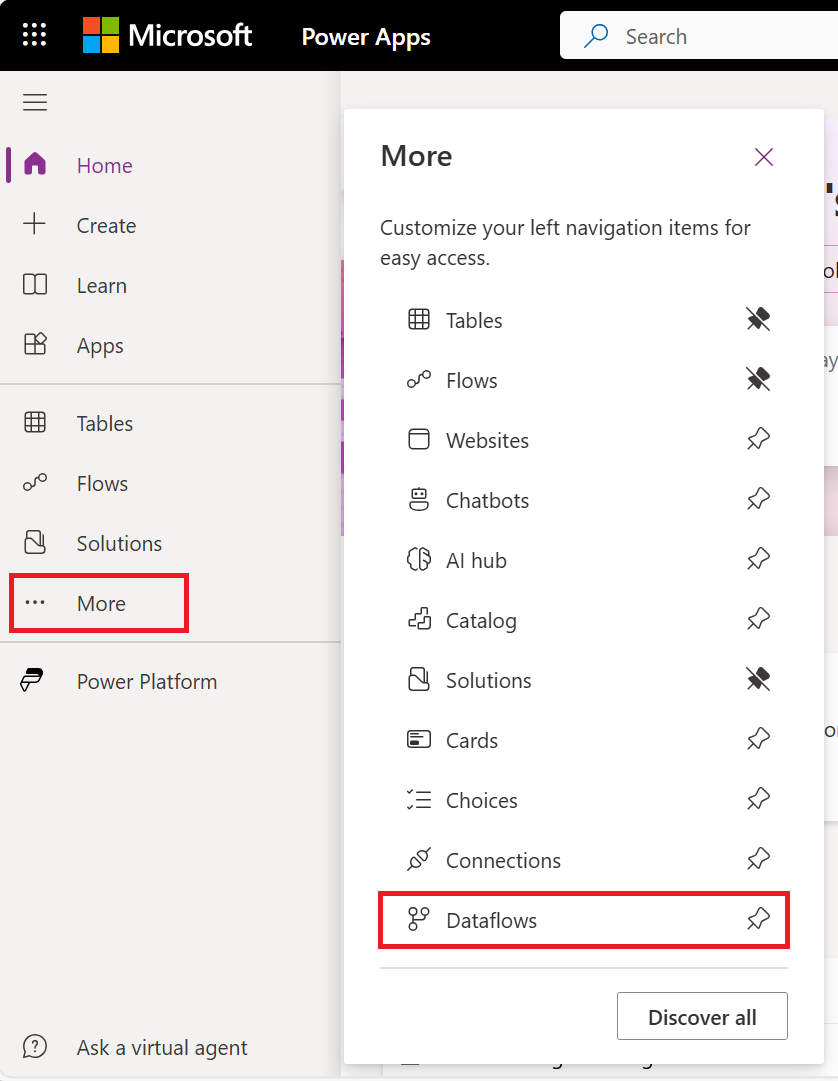
Wählen Sie Neuer Datenfluss.
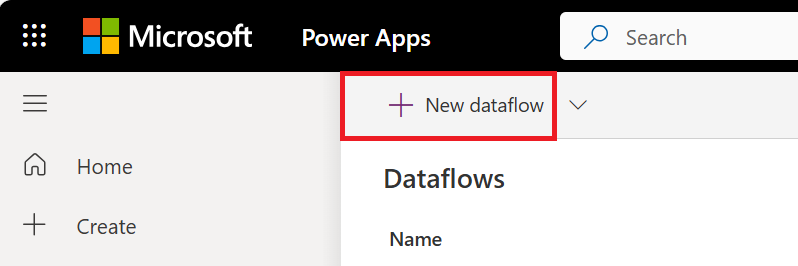
Beim Erstellen des ersten Dataflows können Sie auch die Schaltfläche Dataflow erstellen auswählen.
Versionen der Standard-Dataflows
Hinweis
Wir empfehlen Power Platform-Datenflowbenutzern, von standardmäßigen V1-Datenflüssen zu standardmäßigen V2-Datenflüssen zu migrieren. Standardmäßige V1-Datenflüsse befinden sich in naher Zukunft auf einem Weg, die Unterstützung nicht mehr zu unterstützen. Weitere Informationen zum Migrieren zu standardmäßigen V2-Datenflüssen wechseln Sie zu "Migrieren eines V1-Standarddatenflusses" zu einem V2-Standarddatenfluss.
Wir haben an umfangreichen Aktualisierungen der Standarddatenströme gearbeitet, um ihre Leistung und Zuverlässigkeit zu verbessern. Diese Verbesserungen werden schließlich für alle Standard-Dataflows verfügbar sein. In der Zwischenzeit werden wir zwischen bestehenden Standard-Dataflows (Version 1) und neuen Standard-Dataflows (Version 2) unterscheiden, indem wir einen Versionsindikator in Power Apps hinzufügen.

Vergleich der Merkmale der Standard-Dataflowversionen
In der folgenden Tabelle sind die wichtigsten Unterschiede zwischen den Standard-Dataflows V1 und V2 aufgeführt, und sie enthält Informationen über das Verhalten der einzelnen Funktionen in jeder Version.
| Feature | V1 Standard | Standard V2 |
|---|---|---|
| Maximale Anzahl von Dataflows, die mit automatischem Zeitplan pro Kundenmieter gespeichert werden können | 50 | Unbegrenzt |
| Maximale Anzahl von Datensätzen, die pro Abfrage/Tabelle aufgenommen werden | 500.000 | Unbegrenzt. Die maximale Anzahl der Datensätze, die pro Abfrage oder Tabelle importiert werden können, hängt nun von den Dataverse-Service-Schutzgrenzen zum Zeitpunkt des Ingestion ab. |
| Geschwindigkeit der Aufnahme in das Dataverse | Baselineleistung | Die Leistung wurde um einige Faktoren verbessert. Die tatsächlichen Ergebnisse können variieren und hängen von den Eigenschaften der erfassten Daten und der Auslastung des Dataverse-Dienstes zum Zeitpunkt der Erfassung ab. |
| Inkrementelle Aktualisierungspolitik | Nicht unterstützt | Unterstützt |
| Resilienz | Wenn die Schutzgrenzen des Dataverse-Dienstes erreicht sind, wird ein Datensatz bis zu drei Mal wiederholt. | Wenn die Schutzgrenzen des Dataverse-Dienstes erreicht sind, wird ein Datensatz bis zu drei Mal wiederholt. |
| Integration von Power Automate | Nicht unterstützt | Unterstützt |
Analytische Dataflows
Ein analytischer Dataflow lädt Daten in Speichertypen, die für Analysen optimiert sind - Azure Data Lake Storage. Microsoft Power Platform-Umgebungen und Power BI-Arbeitsbereiche bieten einen verwalteten analytischen Speicherort, der mit den betreffenden Produktlizenzen gebündelt ist. Darüber hinaus können Kunden das Azure Data Lake-Speicherkonto ihres Unternehmens als Ziel für Dataflows verknüpfen.
Analytische Dataflows bieten zusätzliche analytische Funktionen. Zum Beispiel die Integration mit den KI-Features von Power BI oder die Verwendung von berechneten Tabelle, auf die wir später eingehen.
Sie können in Power BI analytische Dataflows erstellen. Standardmäßig werden die Daten in den verwalteten Speicher von Power BI geladen. Sie können Power BI aber auch so konfigurieren, dass die Daten im Azure Data Lake Storage des Unternehmens gespeichert werden.
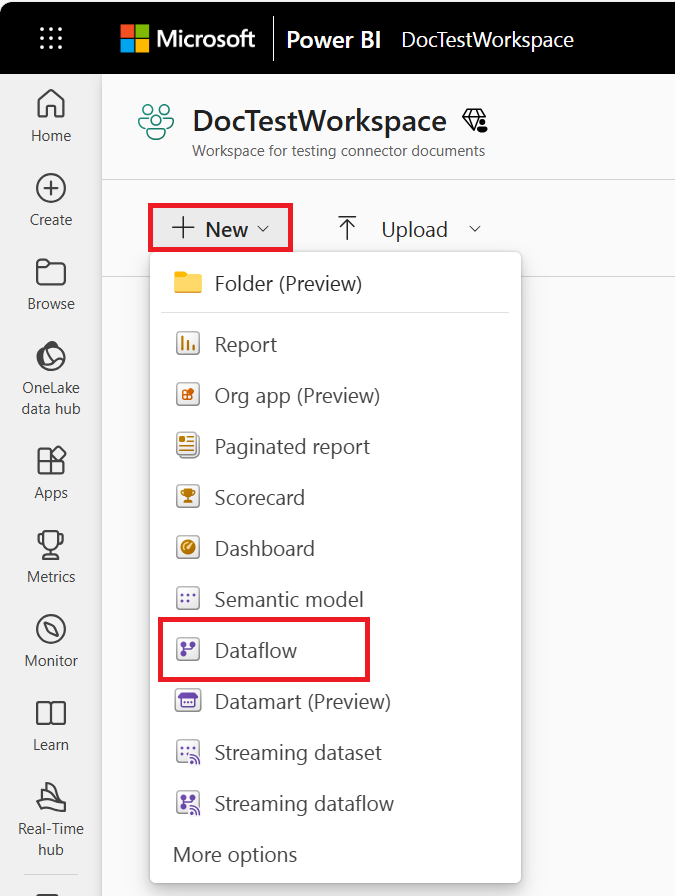
Sie können auch analytische Dataflows in Power Apps und Dynamics 365 Customer Insights Portalen erstellen. Wenn Sie einen Dataflow im Power Apps-Portal erstellen, können Sie zwischen dem von Dataverse verwalteten analytischen Speicher oder dem Azure Data Lake Storage-Konto Ihres Unternehmens wählen.
KI-Integration
Je nach Anforderung kann es erforderlich sein, einige KI- und maschinelle Lernfunktionen über den Dataflow auf die Daten anzuwenden. Diese Funktionalitäten sind in Power BI-Dataflows verfügbar und erfordern einen Premium-Arbeitsbereich.

In den folgenden Artikeln wird erörtert, wie AI-Funktionen in einem Dataflow verwendet werden:
- Azure Machine Learning integration in Power BI (Azure Machine Learning-Integration in Power BI)
- Cognitive Services in Power BI
- Automatisiertes maschinelles Lernen in Power BI
Die in den beiden vorherigen Abschnitten aufgeführten Features sind spezifisch für Power BI und nicht verfügbar, wenn Sie einen Dataflow in den Portalen von Power Apps oder Dynamics 365 Customer Insights erstellen.
Berechnete Tabellen
Einer der Gründe für die Verwendung einer berechneten Tabelle ist die Fähigkeit, große Datenmengen zu verarbeiten. Die berechnete Tabelle hilft in diesen Szenarien. Wenn Sie eine Tabelle in einem Dataflow haben und eine andere Tabelle in demselben Dataflow die Ausgabe der ersten Tabelle verwendet, wird mit dieser Aktion eine berechnete Tabelle erstellt.
Die berechnete Tabelle hilft bei der Durchführung der Datentransformationen. Anstatt die in der ersten Tabelle erforderlichen Transformationen mehrfach zu wiederholen, wird die Transformation nur einmal in der berechneten Tabelle durchgeführt. Dann wird das Ergebnis mehrfach in anderen Tabellen verwendet.
Weitere Informationen über berechnete Tabellen finden Sie unter Erstellen von berechneten Tabellen in Dataflows.
Berechnete Tabellen sind nur in einem analytischen Dataflow verfügbar.
Standard- vs. analytische Dataflows
In der folgenden Tabelle sind einige Unterschiede zwischen einer Standardtabelle und einer analytischen Tabelle aufgeführt.
| Vorgang | Standard | Analytisch |
|---|---|---|
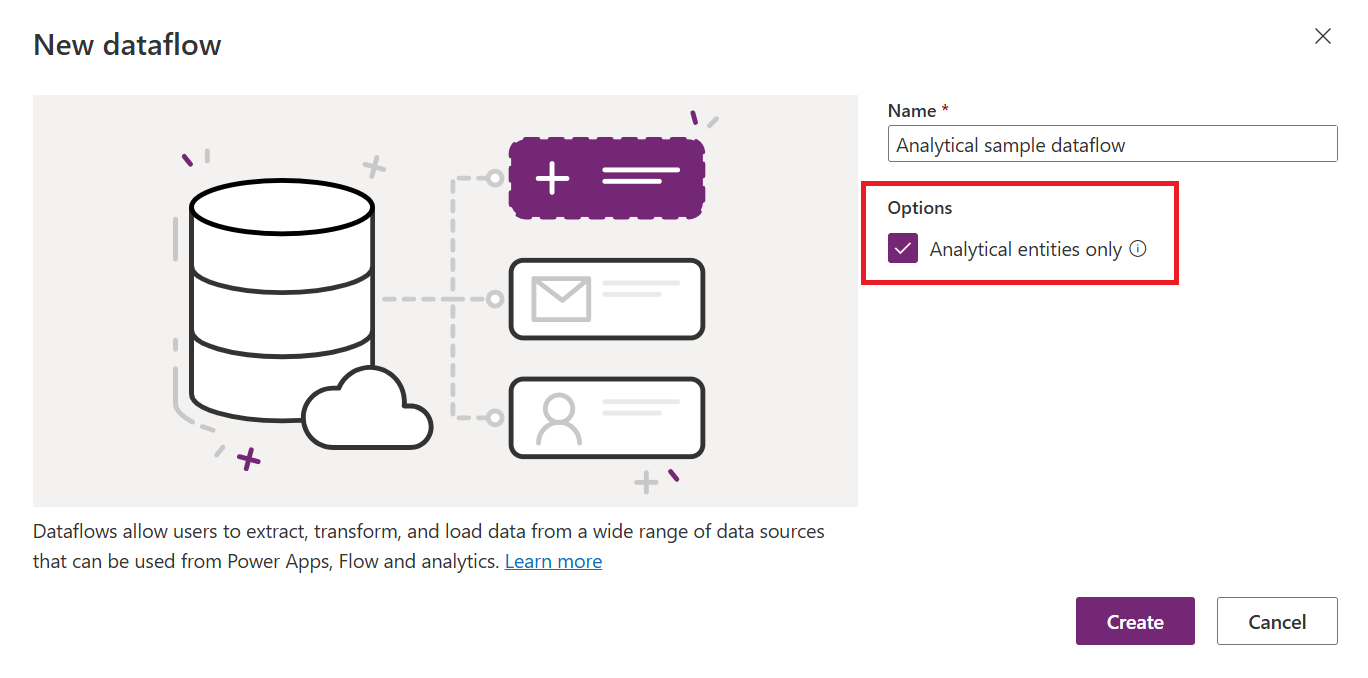
| Vorgehensweise: Erstellen | Power Platform-Dataflows | Power BI-Dataflows Power Platform-Dataflows durch Auswahl des Kontrollkästchens Analytical Entities only beim Erstellen des Dataflows |
| Speicheroptionen | Dataverse | Von Power BI bereitgestellter Azure Data Lake-Speicher für Power BI-Dataflows, von Dataverse bereitgestellter Azure Data Lake-Speicher für Power Platform-Dataflows oder vom Kunden bereitgestellter Azure Data Lake-Speicher |
| Power Query-Umwandlungen | Ja | Ja |
| KI-Funktionen | No | Ja |
| Berechnete Tabelle | No | Ja |
| Kann in anderen Anwendungen verwendet werden | Ja, durch Dataverse | Power BI-Dataflows: Nur in Power BI Power Platform-Dataflows oder externe Power BI-Dataflows: Ja, über Azure Data Lake Storage |
| Zuordnung zur Standardtabelle | Ja | Ja |
| Inkrementelles Laden | Standardmäßige inkrementelle Belastung Kann über das Kontrollkästchen Zeilen löschen, die in der Abfrageausgabe nicht mehr vorhanden sind bei den Ladeeinstellungen geändert werden |
Standard-Volllast Es ist möglich, eine inkrementelle Aktualisierung einzurichten, indem die inkrementelle Aktualisierung in den Datafloweinstellungen eingerichtet wird |
| Geplante Aktualisierung | Ja | Ja, die Möglichkeit, die Datafloweigentümer bei einem Ausfall zu benachrichtigen |
Szenarien für die Verwendung der einzelnen Dataflowtypen
Im Folgenden finden Sie einige Beispielszenarien und Empfehlungen für bewährte Verfahren für jede Art von Dataflow.
Plattformübergreifende Nutzung - Standard-Dataflow
Wenn Ihr Plan für die Erstellung von Dataflows darin besteht, gespeicherte Daten in mehreren Plattformen zu verwenden (nicht nur Power BI, sondern auch andere Microsoft Power Platform-Dienste, Dynamics 365 usw.), ist ein Standard-Dataflow eine gute Wahl. Standard-Dataflows speichern die Daten in Dataverse, auf das Sie über viele andere Plattformen und Dienste zugreifen können.
Umfangreiche Datentransformationen bei großen Datentabellen - analytischer Dataflow
Analytische Dataflows sind eine hervorragende Option für die Verarbeitung großer Datenmengen. Analytische Dataflows erhöhen auch die Rechenleistung hinter der Transformation. Wenn die Daten in Azure Data Lake Storage gespeichert werden, erhöht sich die Schreibgeschwindigkeit an einem Zielort. Im Vergleich zu Dataverse (bei dem zum Zeitpunkt der Datenspeicherung viele Regeln überprüft werden müssen) ist Azure Data Lake Storage schneller für Lese-/Schreibtransaktionen bei großen Datenmengen.
AI-Funktionen - analytischer Dataflow
Wenn Sie in der Phase der Datentransformation KI-Funktionen nutzen möchten, ist es hilfreich, einen analytischen Dataflow zu verwenden, da Sie bei dieser Art von Dataflow alle unterstützten KI-Funktionen nutzen können.